 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditionally Learn to Pay Attention for Sequential Visual Task
Nov 11, 2019
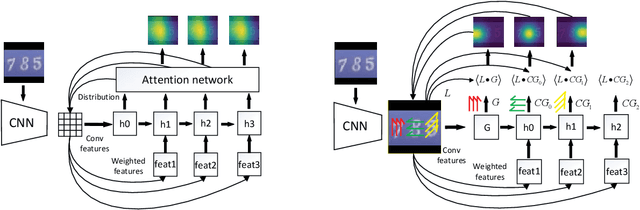
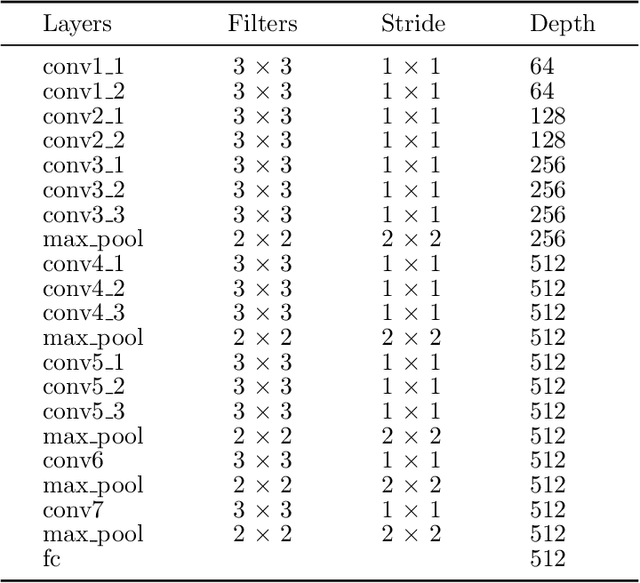
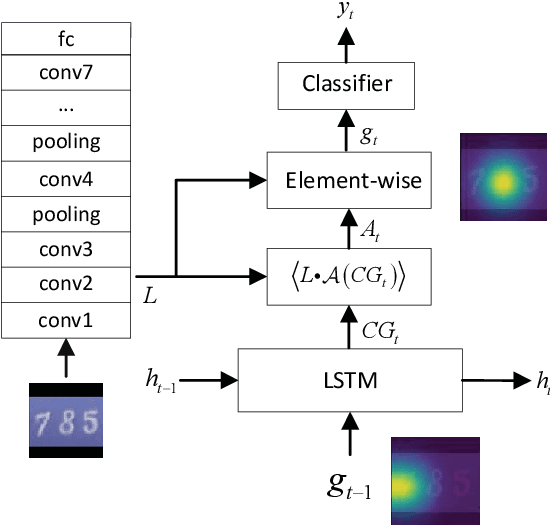
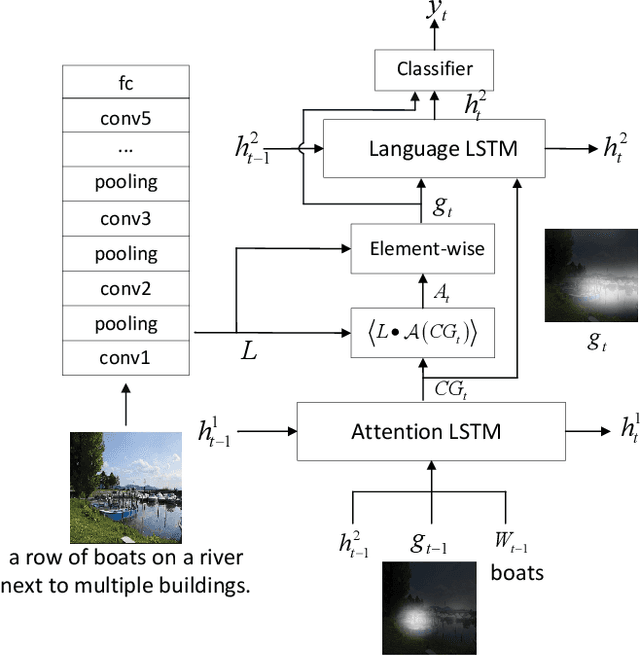
Sequential visual task usually requires to pay attention to its current interested object conditional on its previous observations. Different from popular soft attention mechanism, we propose a new attention framework by introducing a novel conditional global feature which represents the weak feature descriptor of the current focused object. Specifically, for a standard CNN (Convolutional Neural Network) pipeline, the convolutional layers with different receptive fields are used to produce the attention maps by measuring how the convolutional features align to the conditional global feature. The conditional global feature can be generated by different recurrent structure according to different visual tasks, such as a simple recurrent neural network for multiple objects recognition, or a moderate complex language model for image caption. Experiments show that our proposed conditional attention model achieves the best performance on the SVHN (Street View House Numbers) dataset with / without extra bounding box; and for image caption, our attention model generates better scores than the popular soft attention model.
Visual Attention: Deep Rare Features
May 25, 2020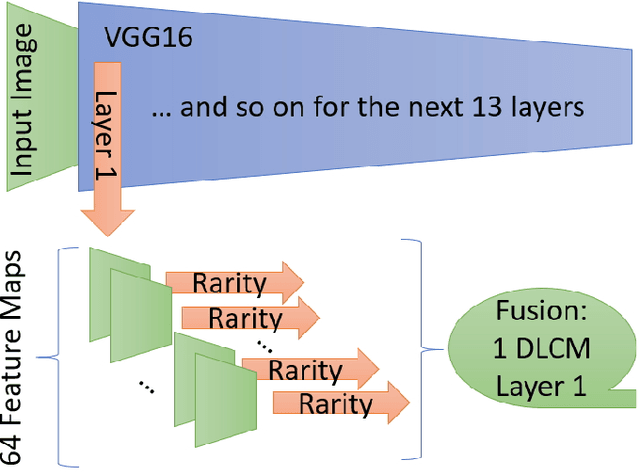



Human visual system is modeled in engineering field providing feature-engineered methods which detect contrasted/surprising/unusual data into images. This data is "interesting" for humans and leads to numerous applications. Deep learning (DNNs) drastically improved the algorithms efficiency on the main benchmark datasets. However, DNN-based models are counter-intuitive: surprising or unusual data is by definition difficult to learn because of its low occurrence probability. In reality, DNNs models mainly learn top-down features such as faces, text, people, or animals which usually attract human attention, but they have low efficiency in extracting surprising or unusual data in the images. In this paper, we propose a model called DeepRare2019 (DR) which uses the power of DNNs feature extraction and the genericity of feature-engineered algorithms. DR 1) does not need any training, 2) it takes less than a second per image on CPU only and 3) our tests on three very different eye-tracking datasets show that DR is generic and is always in the top-3 models on all datasets and metrics while no other model exhibits such a regularity and genericity. DeepRare2019 code can be found at https://github.com/numediart/VisualAttention-RareFamily
Erase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Jan 01, 2020
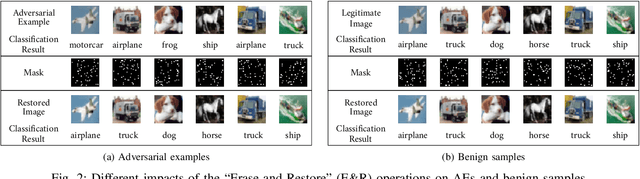
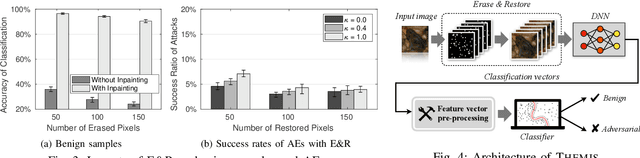
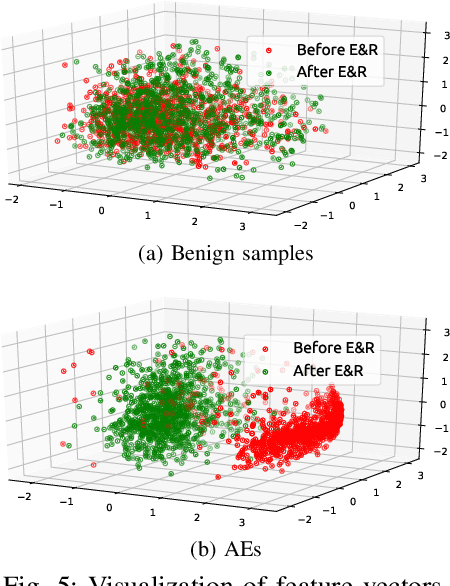
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.
A SentiWordNet Strategy for Curriculum Learning in Sentiment Analysis
May 10, 2020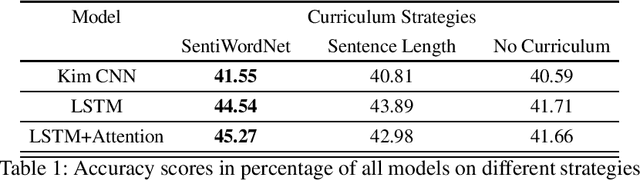
Curriculum Learning (CL) is the idea that learning on a training set sequenced or ordered in a manner where samples range from easy to difficult, results in an increment in performance over otherwise random ordering. The idea parallels cognitive science's theory of how human brains learn, and that learning a difficult task can be made easier by phrasing it as a sequence of easy to difficult tasks. This idea has gained a lot of traction in machine learning and image processing for a while and recently in Natural Language Processing (NLP). In this paper, we apply the ideas of curriculum learning, driven by SentiWordNet in a sentiment analysis setting. In this setting, given a text segment, our aim is to extract its sentiment or polarity. SentiWordNet is a lexical resource with sentiment polarity annotations. By comparing performance with other curriculum strategies and with no curriculum, the effectiveness of the proposed strategy is presented. Convolutional, Recurrence, and Attention-based architectures are employed to assess this improvement. The models are evaluated on a standard sentiment dataset, Stanford Sentiment Treebank.
GAN-based Synthetic Medical Image Augmentation for increased CNN Performance in Liver Lesion Classification
Mar 03, 2018
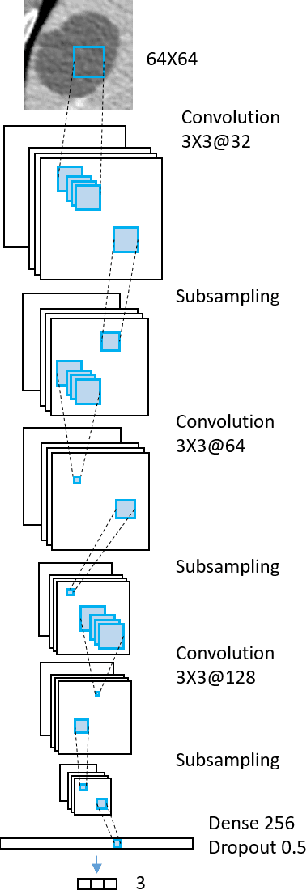
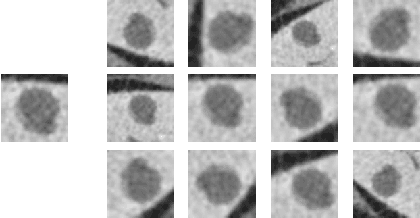
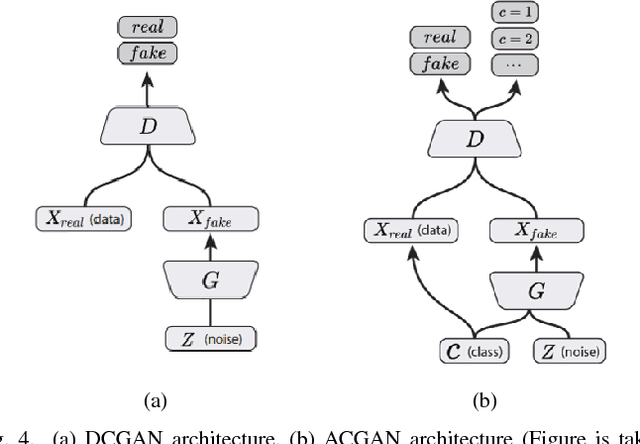
Deep learning methods, and in particular convolutional neural networks (CNNs), have led to an enormous breakthrough in a wide range of computer vision tasks, primarily by using large-scale annotated datasets. However, obtaining such datasets in the medical domain remains a challenge. In this paper, we present methods for generating synthetic medical images using recently presented deep learning Generative Adversarial Networks (GANs). Furthermore, we show that generated medical images can be used for synthetic data augmentation, and improve the performance of CNN for medical image classification. Our novel method is demonstrated on a limited dataset of computed tomography (CT) images of 182 liver lesions (53 cysts, 64 metastases and 65 hemangiomas). We first exploit GAN architectures for synthesizing high quality liver lesion ROIs. Then we present a novel scheme for liver lesion classification using CNN. Finally, we train the CNN using classic data augmentation and our synthetic data augmentation and compare performance. In addition, we explore the quality of our synthesized examples using visualization and expert assessment. The classification performance using only classic data augmentation yielded 78.6% sensitivity and 88.4% specificity. By adding the synthetic data augmentation the results increased to 85.7% sensitivity and 92.4% specificity. We believe that this approach to synthetic data augmentation can generalize to other medical classification applications and thus support radiologists' efforts to improve diagnosis.
Dynamic Sampling for Deep Metric Learning
Apr 24, 2020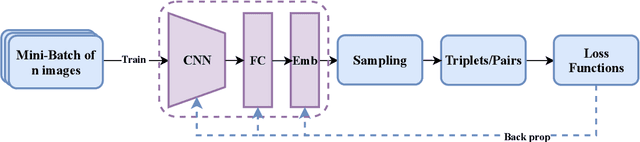
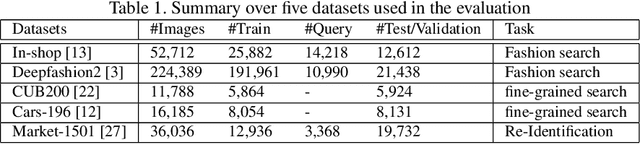
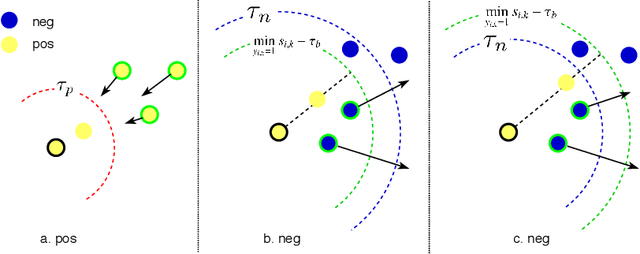
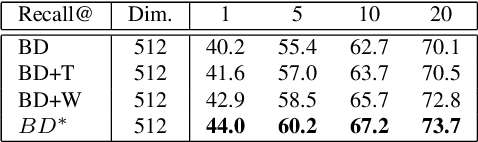
Deep metric learning maps visually similar images onto nearby locations and visually dissimilar images apart from each other in an embedding manifold. The learning process is mainly based on the supplied image negative and positive training pairs. In this paper, a dynamic sampling strategy is proposed to organize the training pairs in an easy-to-hard order to feed into the network. It allows the network to learn general boundaries between categories from the easy training pairs at its early stages and finalize the details of the model mainly relying on the hard training samples in the later. Compared to the existing training sample mining approaches, the hard samples are mined with little harm to the learned general model. This dynamic sampling strategy is formularized as two simple terms that are compatible with various loss functions. Consistent performance boost is observed when it is integrated with several popular loss functions on fashion search, fine-grained classification, and person re-identification tasks.
Semantic-Aware Label Placement for Augmented Reality in Street View
Dec 15, 2019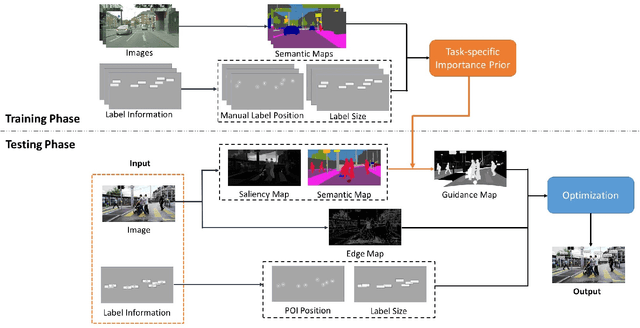
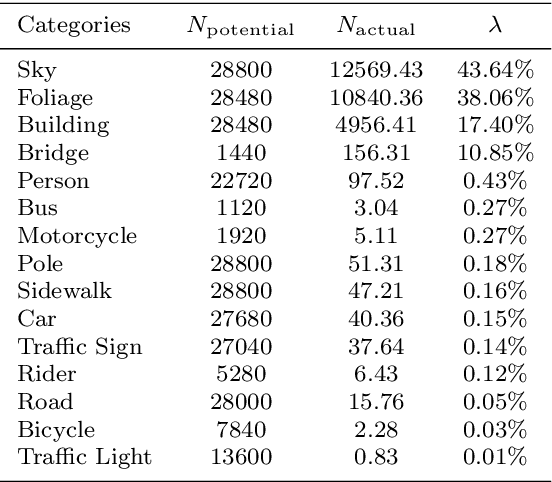
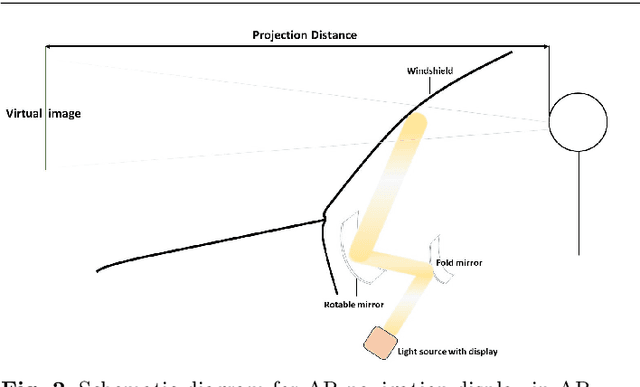
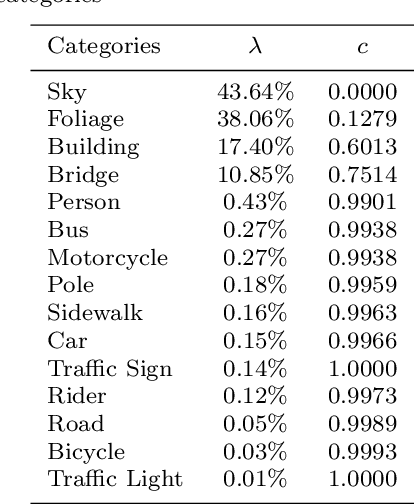
In an augmented reality (AR) application, placing labels in a manner that is clear and readable without occluding the critical information from the real-world can be a challenging problem. This paper introduces a label placement technique for AR used in street view scenarios. We propose a semantic-aware task-specific label placement method by identifying potentially important image regions through a novel feature map, which we refer to as guidance map. Given an input image, its saliency information, semantic information and the task-specific importance prior are integrated into the guidance map for our labeling task. To learn the task prior, we created a label placement dataset with the users' labeling preferences, as well as use it for evaluation. Our solution encodes the constraints for placing labels in an optimization problem to obtain the final label layout, and the labels will be placed in appropriate positions to reduce the chances of overlaying important real-world objects in street view AR scenarios. The experimental validation shows clearly the benefits of our method over previous solutions in the AR street view navigation and similar applications.
Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming
Jul 17, 2019
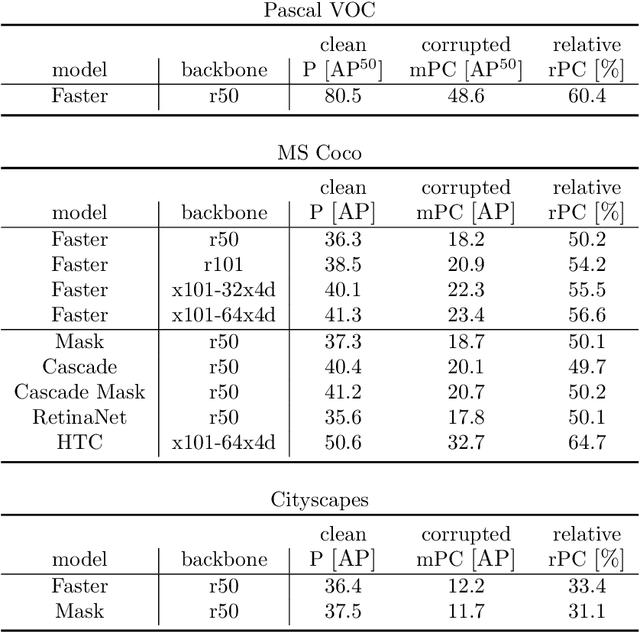


The ability to detect objects regardless of image distortions or weather conditions is crucial for real-world applications of deep learning like autonomous driving. We here provide an easy-to-use benchmark to assess how object detection models perform when image quality degrades. The three resulting benchmark datasets, termed Pascal-C, Coco-C and Cityscapes-C, contain a large variety of image corruptions. We show that a range of standard object detection models suffer a severe performance loss on corrupted images (down to 30-60% of the original performance). However, a simple data augmentation trick - stylizing the training images - leads to a substantial increase in robustness across corruption type, severity and dataset. We envision our comprehensive benchmark to track future progress towards building robust object detection models. Benchmark, code and data are available at: http://github.com/bethgelab/robust-detection-benchmark
Blind Geometric Distortion Correction on Images Through Deep Learning
Sep 08, 2019



We propose the first general framework to automatically correct different types of geometric distortion in a single input image. Our proposed method employs convolutional neural networks (CNNs) trained by using a large synthetic distortion dataset to predict the displacement field between distorted images and corrected images. A model fitting method uses the CNN output to estimate the distortion parameters, achieving a more accurate prediction. The final corrected image is generated based on the predicted flow using an efficient, high-quality resampling method. Experimental results demonstrate that our algorithm outperforms traditional correction methods, and allows for interesting applications such as distortion transfer, distortion exaggeration, and co-occurring distortion correction.
AutoOD: Automated Outlier Detection via Curiosity-guided Search and Self-imitation Learning
Jun 19, 2020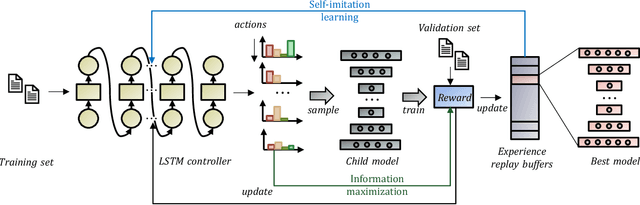
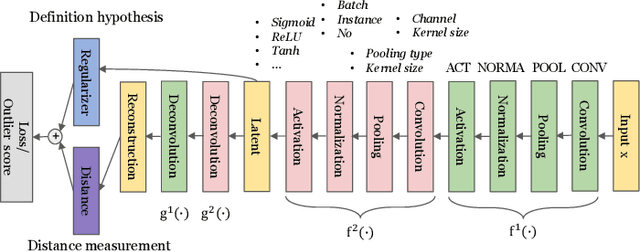
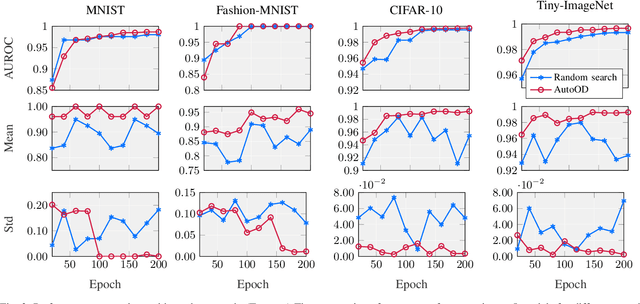
Outlier detection is an important data mining task with numerous practical applications such as intrusion detection, credit card fraud detection, and video surveillance. However, given a specific complicated task with big data, the process of building a powerful deep learning based system for outlier detection still highly relies on human expertise and laboring trials. Although Neural Architecture Search (NAS) has shown its promise in discovering effective deep architectures in various domains, such as image classification, object detection, and semantic segmentation, contemporary NAS methods are not suitable for outlier detection due to the lack of intrinsic search space, unstable search process, and low sample efficiency. To bridge the gap, in this paper, we propose AutoOD, an automated outlier detection framework, which aims to search for an optimal neural network model within a predefined search space. Specifically, we firstly design a curiosity-guided search strategy to overcome the curse of local optimality. A controller, which acts as a search agent, is encouraged to take actions to maximize the information gain about the controller's internal belief. We further introduce an experience replay mechanism based on self-imitation learning to improve the sample efficiency. Experimental results on various real-world benchmark datasets demonstrate that the deep model identified by AutoOD achieves the best performance, comparing with existing handcrafted models and traditional search methods.