 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Decide Early and Explain Later
Apr 24, 2026Large Language Models often achieve strong performance by generating long intermediate chain-of-thought reasoning. However, it remains unclear when a model's final answer is actually determined during generation. If the answer is already fixed at an intermediate stage, subsequent reasoning tokens may constitute post-decision explanation, increasing inference cost and latency without improving correctness. We study the evolution of predicted answers over reasoning steps using forced answer completion, which elicits the model's intermediate predictions at partial reasoning prefixes. Focusing on Qwen3-4B and averaging results across all datasets considered, we find that predicted answers change in only 32% of queries. Moreover, once the final answer switch occurs, the model generates an average of 760 additional reasoning tokens per query, accounting for a substantial fraction of the total reasoning budget. Motivated by these findings, we investigate early stopping strategies that halt generation once the answer has stabilized. We show that simple heuristics, including probe-based stopping, can reduce reasoning token usage by 500 tokens per query while incurring only a 2% drop in accuracy. Together, our results indicate that a large portion of chain-of-thought generation is redundant and can be reduced with minimal impact on performance.
From Early Encoding to Late Suppression: Interpreting LLMs on Character Counting Tasks
Apr 01, 2026Large language models (LLMs) exhibit failures on elementary symbolic tasks such as character counting in a word, despite excelling on complex benchmarks. Although this limitation has been noted, the internal reasons remain unclear. We use character counting (e.g., "How many p's are in apple?") as a minimal, controlled probe that isolates token-level reasoning from higher-level confounds. Using this setting, we uncover a consistent phenomenon across modern architectures, including LLaMA, Qwen, and Gemma: models often compute the correct answer internally yet fail to express it at the output layer. Through mechanistic analysis combining probing classifiers, activation patching, logit lens analysis, and attention head tracing, we show that character-level information is encoded in early and mid-layer representations. However, this information is attenuated by a small set of components in later layers, especially the penultimate and final layer MLP. We identify these components as negative circuits: subnetworks that downweight correct signals in favor of higher-probability but incorrect outputs. Our results lead to two contributions. First, we show that symbolic reasoning failures in LLMs are not due to missing representations or insufficient scale, but arise from structured interference within the model's computation graph. This explains why such errors persist and can worsen under scaling and instruction tuning. Second, we provide evidence that LLM forward passes implement a form of competitive decoding, in which correct and incorrect hypotheses coexist and are dynamically reweighted, with final outputs determined by suppression as much as by amplification. These findings carry implications for interpretability and robustness: simple symbolic reasoning exposes weaknesses in modern LLMs, underscoring need for design strategies that ensure information is encoded and reliably used.
Enhancing Hate Speech Detection on Social Media: A Comparative Analysis of Machine Learning Models and Text Transformation Approaches
Feb 24, 2026The proliferation of hate speech on social media platforms has necessitated the development of effective detection and moderation tools. This study evaluates the efficacy of various machine learning models in identifying hate speech and offensive language and investigates the potential of text transformation techniques to neutralize such content. We compare traditional models like CNNs and LSTMs with advanced neural network models such as BERT and its derivatives, alongside exploring hybrid models that combine different architectural features. Our results indicate that while advanced models like BERT show superior accuracy due to their deep contextual understanding, hybrid models exhibit improved capabilities in certain scenarios. Furthermore, we introduce innovative text transformation approaches that convert negative expressions into neutral ones, thereby potentially mitigating the impact of harmful content. The implications of these findings are discussed, highlighting the strengths and limitations of current technologies and proposing future directions for more robust hate speech detection systems.
Confabulations from ACL Publications (CAP): A Dataset for Scientific Hallucination Detection
Oct 25, 2025


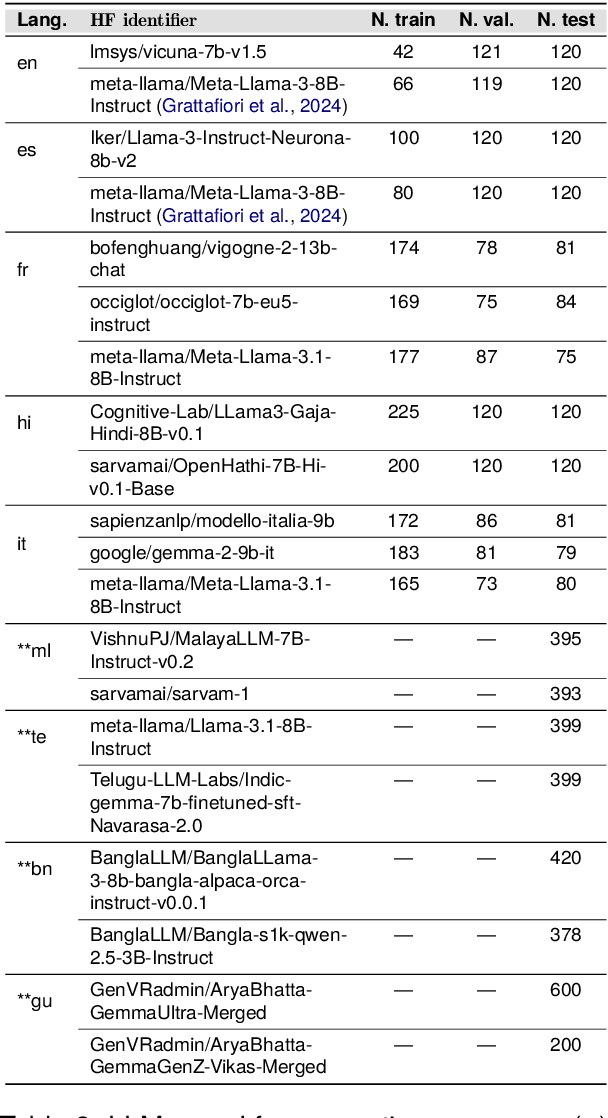
We introduce the CAP (Confabulations from ACL Publications) dataset, a multilingual resource for studying hallucinations in large language models (LLMs) within scientific text generation. CAP focuses on the scientific domain, where hallucinations can distort factual knowledge, as they frequently do. In this domain, however, the presence of specialized terminology, statistical reasoning, and context-dependent interpretations further exacerbates these distortions, particularly given LLMs' lack of true comprehension, limited contextual understanding, and bias toward surface-level generalization. CAP operates in a cross-lingual setting covering five high-resource languages (English, French, Hindi, Italian, and Spanish) and four low-resource languages (Bengali, Gujarati, Malayalam, and Telugu). The dataset comprises 900 curated scientific questions and over 7000 LLM-generated answers from 16 publicly available models, provided as question-answer pairs along with token sequences and corresponding logits. Each instance is annotated with a binary label indicating the presence of a scientific hallucination, denoted as a factuality error, and a fluency label, capturing issues in the linguistic quality or naturalness of the text. CAP is publicly released to facilitate advanced research on hallucination detection, multilingual evaluation of LLMs, and the development of more reliable scientific NLP systems.
Analyzing Biases in Political Dialogue: Tagging U.S. Presidential Debates with an Extended DAMSL Framework
May 27, 2025We present a critical discourse analysis of the 2024 U.S. presidential debates, examining Donald Trump's rhetorical strategies in his interactions with Joe Biden and Kamala Harris. We introduce a novel annotation framework, BEADS (Bias Enriched Annotation for Dialogue Structure), which systematically extends the DAMSL framework to capture bias driven and adversarial discourse features in political communication. BEADS includes a domain and language agnostic set of tags that model ideological framing, emotional appeals, and confrontational tactics. Our methodology compares detailed human annotation with zero shot ChatGPT assisted tagging on verified transcripts from the Trump and Biden (19,219 words) and Trump and Harris (18,123 words) debates. Our analysis shows that Trump consistently dominated in key categories: Challenge and Adversarial Exchanges, Selective Emphasis, Appeal to Fear, Political Bias, and Perceived Dismissiveness. These findings underscore his use of emotionally charged and adversarial rhetoric to control the narrative and influence audience perception. In this work, we establish BEADS as a scalable and reproducible framework for critical discourse analysis across languages, domains, and political contexts.
Bias in Political Dialogue: Tagging U.S. Presidential Debates with an Extended DAMSL Framework
May 26, 2025We present a critical discourse analysis of the 2024 U.S. presidential debates, examining Donald Trump's rhetorical strategies in his interactions with Joe Biden and Kamala Harris. We introduce a novel annotation framework, BEADS (Bias Enriched Annotation for Dialogue Structure), which systematically extends the DAMSL framework to capture bias driven and adversarial discourse features in political communication. BEADS includes a domain and language agnostic set of tags that model ideological framing, emotional appeals, and confrontational tactics. Our methodology compares detailed human annotation with zero shot ChatGPT assisted tagging on verified transcripts from the Trump and Biden (19,219 words) and Trump and Harris (18,123 words) debates. Our analysis shows that Trump consistently dominated in key categories: Challenge and Adversarial Exchanges, Selective Emphasis, Appeal to Fear, Political Bias, and Perceived Dismissiveness. These findings underscore his use of emotionally charged and adversarial rhetoric to control the narrative and influence audience perception. In this work, we establish BEADS as a scalable and reproducible framework for critical discourse analysis across languages, domains, and political contexts.
IndicSentEval: How Effectively do Multilingual Transformer Models encode Linguistic Properties for Indic Languages?
Oct 03, 2024



Transformer-based models have revolutionized the field of natural language processing. To understand why they perform so well and to assess their reliability, several studies have focused on questions such as: Which linguistic properties are encoded by these models, and to what extent? How robust are these models in encoding linguistic properties when faced with perturbations in the input text? However, these studies have mainly focused on BERT and the English language. In this paper, we investigate similar questions regarding encoding capability and robustness for 8 linguistic properties across 13 different perturbations in 6 Indic languages, using 9 multilingual Transformer models (7 universal and 2 Indic-specific). To conduct this study, we introduce a novel multilingual benchmark dataset, IndicSentEval, containing approximately $\sim$47K sentences. Surprisingly, our probing analysis of surface, syntactic, and semantic properties reveals that while almost all multilingual models demonstrate consistent encoding performance for English, they show mixed results for Indic languages. As expected, Indic-specific multilingual models capture linguistic properties in Indic languages better than universal models. Intriguingly, universal models broadly exhibit better robustness compared to Indic-specific models, particularly under perturbations such as dropping both nouns and verbs, dropping only verbs, or keeping only nouns. Overall, this study provides valuable insights into probing and perturbation-specific strengths and weaknesses of popular multilingual Transformer-based models for different Indic languages. We make our code and dataset publicly available [https://tinyurl.com/IndicSentEval}].
Mast Kalandar at SemEval-2024 Task 8: On the Trail of Textual Origins: RoBERTa-BiLSTM Approach to Detect AI-Generated Text
Jul 03, 2024Large Language Models (LLMs) have showcased impressive abilities in generating fluent responses to diverse user queries. However, concerns regarding the potential misuse of such texts in journalism, educational, and academic contexts have surfaced. SemEval 2024 introduces the task of Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection, aiming to develop automated systems for identifying machine-generated text and detecting potential misuse. In this paper, we i) propose a RoBERTa-BiLSTM based classifier designed to classify text into two categories: AI-generated or human ii) conduct a comparative study of our model with baseline approaches to evaluate its effectiveness. This paper contributes to the advancement of automatic text detection systems in addressing the challenges posed by machine-generated text misuse. Our architecture ranked 46th on the official leaderboard with an accuracy of 80.83 among 125.
Significance of Chain of Thought in Gender Bias Mitigation for English-Dravidian Machine Translation
Jun 03, 2024Gender bias in machine translation (MT) sys- tems poses a significant challenge to achieving accurate and inclusive translations. This paper examines gender bias in machine translation systems for languages such as Telugu and Kan- nada from the Dravidian family, analyzing how gender inflections affect translation accuracy and neutrality using Google Translate and Chat- GPT. It finds that while plural forms can reduce bias, individual-centric sentences often main- tain the bias due to historical stereotypes. The study evaluates the Chain of Thought process- ing, noting significant bias mitigation from 80% to 4% in Telugu and from 40% to 0% in Kan- nada. It also compares Telugu and Kannada translations, emphasizing the need for language specific strategies to address these challenges and suggesting directions for future research to enhance fairness in both data preparation and prompts during inference.
Zero-Shot Multi-task Hallucination Detection
Mar 18, 2024In recent studies, the extensive utilization of large language models has underscored the importance of robust evaluation methodologies for assessing text generation quality and relevance to specific tasks. This has revealed a prevalent issue known as hallucination, an emergent condition in the model where generated text lacks faithfulness to the source and deviates from the evaluation criteria. In this study, we formally define hallucination and propose a framework for its quantitative detection in a zero-shot setting, leveraging our definition and the assumption that model outputs entail task and sample specific inputs. In detecting hallucinations, our solution achieves an accuracy of 0.78 in a model-aware setting and 0.61 in a model-agnostic setting. Notably, our solution maintains computational efficiency, requiring far less computational resources than other SOTA approaches, aligning with the trend towards lightweight and compressed models.