 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Apr 20, 2026Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
PriVi: Towards A General-Purpose Video Model For Primate Behavior In The Wild
Nov 15, 2025Non-human primates are our closest living relatives, and analyzing their behavior is central to research in cognition, evolution, and conservation. Computer vision could greatly aid this research, but existing methods often rely on human-centric pretrained models and focus on single datasets, which limits generalization. We address this limitation by shifting from a model-centric to a data-centric approach and introduce PriVi, a large-scale primate-centric video pretraining dataset. PriVi contains 424 hours of curated video, combining 174 hours from behavioral research across 11 settings with 250 hours of diverse web-sourced footage, assembled through a scalable data curation pipeline. We pretrain V-JEPA, a large-scale video model, on PriVi to learn primate-specific representations and evaluate it using a lightweight frozen classifier. Across four benchmark datasets, ChimpACT, BaboonLand, PanAf500, and ChimpBehave, our approach consistently outperforms prior work, including fully finetuned baselines, and scales favorably with fewer labels. These results demonstrate that primate-centric pretraining substantially improves data efficiency and generalization, making it a promising approach for low-label applications. Code, models, and the majority of the dataset will be made available.
Do traveling waves make good positional encodings?
Nov 11, 2025
Transformers rely on positional encoding to compensate for the inherent permutation invariance of self-attention. Traditional approaches use absolute sinusoidal embeddings or learned positional vectors, while more recent methods emphasize relative encodings to better capture translation equivariances. In this work, we propose RollPE, a novel positional encoding mechanism based on traveling waves, implemented by applying a circular roll operation to the query and key tensors in self-attention. This operation induces a relative shift in phase across positions, allowing the model to compute attention as a function of positional differences rather than absolute indices. We show this simple method significantly outperforms traditional absolute positional embeddings and is comparable to RoPE. We derive a continuous case of RollPE which implicitly imposes a topographic structure on the query and key space. We further derive a mathematical equivalence of RollPE to a particular configuration of RoPE. Viewing RollPE through the lens of traveling waves may allow us to simplify RoPE and relate it to processes of information flow in the brain.
A Circular Argument : Does RoPE need to be Equivariant for Vision?
Nov 11, 2025Rotary Positional Encodings (RoPE) have emerged as a highly effective technique for one-dimensional sequences in Natural Language Processing spurring recent progress towards generalizing RoPE to higher-dimensional data such as images and videos. The success of RoPE has been thought to be due to its positional equivariance, i.e. its status as a relative positional encoding. In this paper, we mathematically show RoPE to be one of the most general solutions for equivariant positional embedding in one-dimensional data. Moreover, we show Mixed RoPE to be the analogously general solution for M-dimensional data, if we require commutative generators -- a property necessary for RoPE's equivariance. However, we question whether strict equivariance plays a large role in RoPE's performance. We propose Spherical RoPE, a method analogous to Mixed RoPE, but assumes non-commutative generators. Empirically, we find Spherical RoPE to have the equivalent or better learning behavior compared to its equivariant analogues. This suggests that relative positional embeddings are not as important as is commonly believed, at least within computer vision. We expect this discovery to facilitate future work in positional encodings for vision that can be faster and generalize better by removing the preconception that they must be relative.
Clifford Algebraic Rotor Embeddings : Maybe embeddings should start to CARE
Nov 11, 2025

Rotary Positional Embeddings (RoPE) have demonstrated exceptional performance as a positional encoding method, consistently outperforming their baselines. While recent work has sought to extend RoPE to higher-dimensional inputs, many such extensions are non-commutative, thereby forfeiting RoPE's shift-equivariance property. Spherical RoPE is one such non-commutative variant, motivated by the idea of rotating embedding vectors on spheres rather than circles. However, spherical rotations are inherently non-commutative, making the choice of rotation sequence ambiguous. In this work, we explore a quaternion-based approach -- Quaternion Rotary Embeddings (QuatRo) -- in place of Euler angles, leveraging quaternions' ability to represent 3D rotations to parameterize the axes of rotation. We show Mixed RoPE and Spherical RoPE to be special cases of QuatRo. Further, we propose a generalization of QuatRo to Clifford Algebraic Rotary Embeddings (CARE) using geometric algebra. Viewing quaternions as the even subalgebra of Cl(3,0,0), we extend the notion of rotary embeddings from quaternions to Clifford rotors acting on multivectors. This formulation enables two key generalizations: (1) extending rotary embeddings to arbitrary dimensions, and (2) encoding positional information in multivectors of multiple grades, not just vectors. We present preliminary experiments comparing spherical, quaternion, and Clifford-based rotary embeddings.
SILVI: Simple Interface for Labeling Video Interactions
Nov 05, 2025


Computer vision methods are increasingly used for the automated analysis of large volumes of video data collected through camera traps, drones, or direct observations of animals in the wild. While recent advances have focused primarily on detecting individual actions, much less work has addressed the detection and annotation of interactions -- a crucial aspect for understanding social and individualized animal behavior. Existing open-source annotation tools support either behavioral labeling without localization of individuals, or localization without the capacity to capture interactions. To bridge this gap, we present SILVI, an open-source labeling software that integrates both functionalities. SILVI enables researchers to annotate behaviors and interactions directly within video data, generating structured outputs suitable for training and validating computer vision models. By linking behavioral ecology with computer vision, SILVI facilitates the development of automated approaches for fine-grained behavioral analyses. Although developed primarily in the context of animal behavior, SILVI could be useful more broadly to annotate human interactions in other videos that require extracting dynamic scene graphs. The software, along with documentation and download instructions, is available at: https://gitlab.gwdg.de/kanbertay/interaction-labelling-app.
What should a neuron aim for? Designing local objective functions based on information theory
Dec 03, 2024



In modern deep neural networks, the learning dynamics of the individual neurons is often obscure, as the networks are trained via global optimization. Conversely, biological systems build on self-organized, local learning, achieving robustness and efficiency with limited global information. We here show how self-organization between individual artificial neurons can be achieved by designing abstract bio-inspired local learning goals. These goals are parameterized using a recent extension of information theory, Partial Information Decomposition (PID), which decomposes the information that a set of information sources holds about an outcome into unique, redundant and synergistic contributions. Our framework enables neurons to locally shape the integration of information from various input classes, i.e. feedforward, feedback, and lateral, by selecting which of the three inputs should contribute uniquely, redundantly or synergistically to the output. This selection is expressed as a weighted sum of PID terms, which, for a given problem, can be directly derived from intuitive reasoning or via numerical optimization, offering a window into understanding task-relevant local information processing. Achieving neuron-level interpretability while enabling strong performance using local learning, our work advances a principled information-theoretic foundation for local learning strategies.
MNIST-Nd: a set of naturalistic datasets to benchmark clustering across dimensions
Oct 21, 2024Driven by advances in recording technology, large-scale high-dimensional datasets have emerged across many scientific disciplines. Especially in biology, clustering is often used to gain insights into the structure of such datasets, for instance to understand the organization of different cell types. However, clustering is known to scale poorly to high dimensions, even though the exact impact of dimensionality is unclear as current benchmark datasets are mostly two-dimensional. Here we propose MNIST-Nd, a set of synthetic datasets that share a key property of real-world datasets, namely that individual samples are noisy and clusters do not perfectly separate. MNIST-Nd is obtained by training mixture variational autoencoders with 2 to 64 latent dimensions on MNIST, resulting in six datasets with comparable structure but varying dimensionality. It thus offers the chance to disentangle the impact of dimensionality on clustering. Preliminary common clustering algorithm benchmarks on MNIST-Nd suggest that Leiden is the most robust for growing dimensions.
Computer Vision for Primate Behavior Analysis in the Wild
Jan 29, 2024Advances in computer vision as well as increasingly widespread video-based behavioral monitoring have great potential for transforming how we study animal cognition and behavior. However, there is still a fairly large gap between the exciting prospects and what can actually be achieved in practice today, especially in videos from the wild. With this perspective paper, we want to contribute towards closing this gap, by guiding behavioral scientists in what can be expected from current methods and steering computer vision researchers towards problems that are relevant to advance research in animal behavior. We start with a survey of the state-of-the-art methods for computer vision problems that are directly relevant to the video-based study of animal behavior, including object detection, multi-individual tracking, (inter)action recognition and individual identification. We then review methods for effort-efficient learning, which is one of the biggest challenges from a practical perspective. Finally, we close with an outlook into the future of the emerging field of computer vision for animal behavior, where we argue that the field should move fast beyond the common frame-by-frame processing and treat video as a first-class citizen.
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
Jun 17, 2022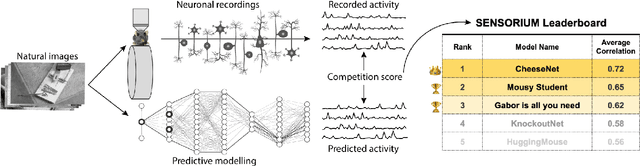
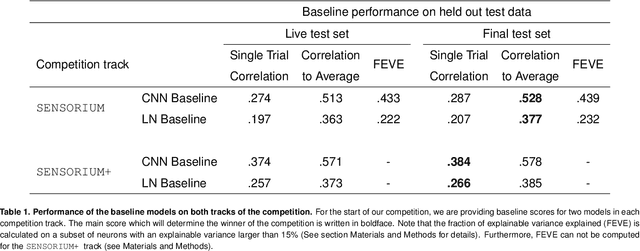
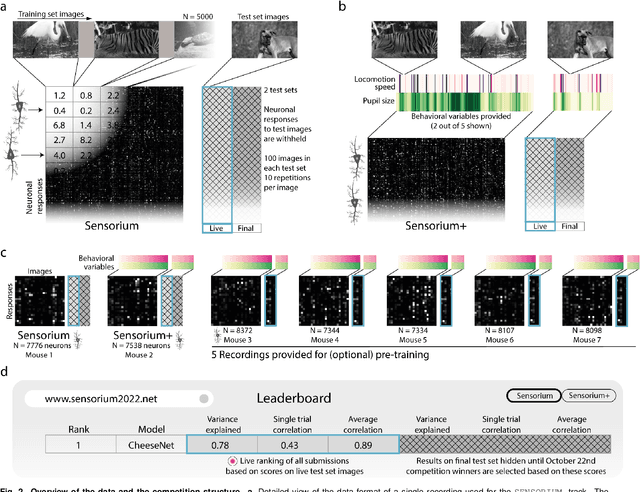
The neural underpinning of the biological visual system is challenging to study experimentally, in particular as the neuronal activity becomes increasingly nonlinear with respect to visual input. Artificial neural networks (ANNs) can serve a variety of goals for improving our understanding of this complex system, not only serving as predictive digital twins of sensory cortex for novel hypothesis generation in silico, but also incorporating bio-inspired architectural motifs to progressively bridge the gap between biological and machine vision. The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the Sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images, together with simultaneous behavioral measurements that include running speed, pupil dilation, and eye movements. The benchmark challenge will rank models based on predictive performance for neuronal responses on a held-out test set, and includes two tracks for model input limited to either stimulus only (Sensorium) or stimulus plus behavior (Sensorium+). We provide a starting kit to lower the barrier for entry, including tutorials, pre-trained baseline models, and APIs with one line commands for data loading and submission. We would like to see this as a starting point for regular challenges and data releases, and as a standard tool for measuring progress in large-scale neural system identification models of the mouse visual system and beyond.