 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Pass Filtering Improves Behavioral Alignment of Vision Models
Feb 14, 2026Despite their impressive performance on computer vision benchmarks, Deep Neural Networks (DNNs) still fall short of adequately modeling human visual behavior, as measured by error consistency and shape bias. Recent work hypothesized that behavioral alignment can be drastically improved through \emph{generative} -- rather than \emph{discriminative} -- classifiers, with far-reaching implications for models of human vision. Here, we instead show that the increased alignment of generative models can be largely explained by a seemingly innocuous resizing operation in the generative model which effectively acts as a low-pass filter. In a series of controlled experiments, we show that removing high-frequency spatial information from discriminative models like CLIP drastically increases their behavioral alignment. Simply blurring images at test-time -- rather than training on blurred images -- achieves a new state-of-the-art score on the model-vs-human benchmark, halving the current alignment gap between DNNs and human observers. Furthermore, low-pass filters are likely optimal, which we demonstrate by directly optimizing filters for alignment. To contextualize the performance of optimal filters, we compute the frontier of all possible pareto-optimal solutions to the benchmark, which was formerly unknown. We explain our findings by observing that the frequency spectrum of optimal Gaussian filters roughly matches the spectrum of band-pass filters implemented by the human visual system. We show that the contrast sensitivity function, describing the inverse of the contrast threshold required for humans to detect a sinusoidal grating as a function of spatiotemporal frequency, is approximated well by Gaussian filters of the specific width that also maximizes error consistency.
In Search of Forgotten Domain Generalization
Oct 10, 2024Out-of-Domain (OOD) generalization is the ability of a model trained on one or more domains to generalize to unseen domains. In the ImageNet era of computer vision, evaluation sets for measuring a model's OOD performance were designed to be strictly OOD with respect to style. However, the emergence of foundation models and expansive web-scale datasets has obfuscated this evaluation process, as datasets cover a broad range of domains and risk test domain contamination. In search of the forgotten domain generalization, we create large-scale datasets subsampled from LAION -- LAION-Natural and LAION-Rendition -- that are strictly OOD to corresponding ImageNet and DomainNet test sets in terms of style. Training CLIP models on these datasets reveals that a significant portion of their performance is explained by in-domain examples. This indicates that the OOD generalization challenges from the ImageNet era still prevail and that training on web-scale data merely creates the illusion of OOD generalization. Furthermore, through a systematic exploration of combining natural and rendition datasets in varying proportions, we identify optimal mixing ratios for model generalization across these domains. Our datasets and results re-enable meaningful assessment of OOD robustness at scale -- a crucial prerequisite for improving model robustness.
Focal Depth Estimation: A Calibration-Free, Subject- and Daytime Invariant Approach
Aug 07, 2024



In an era where personalized technology is increasingly intertwined with daily life, traditional eye-tracking systems and autofocal glasses face a significant challenge: the need for frequent, user-specific calibration, which impedes their practicality. This study introduces a groundbreaking calibration-free method for estimating focal depth, leveraging machine learning techniques to analyze eye movement features within short sequences. Our approach, distinguished by its innovative use of LSTM networks and domain-specific feature engineering, achieves a mean absolute error (MAE) of less than 10 cm, setting a new focal depth estimation accuracy standard. This advancement promises to enhance the usability of autofocal glasses and pave the way for their seamless integration into extended reality environments, marking a significant leap forward in personalized visual technology.
InfoNCE: Identifying the Gap Between Theory and Practice
Jun 28, 2024Previous theoretical work on contrastive learning (CL) with InfoNCE showed that, under certain assumptions, the learned representations uncover the ground-truth latent factors. We argue these theories overlook crucial aspects of how CL is deployed in practice. Specifically, they assume that within a positive pair, all latent factors either vary to a similar extent, or that some do not vary at all. However, in practice, positive pairs are often generated using augmentations such as strong cropping to just a few pixels. Hence, a more realistic assumption is that all latent factors change, with a continuum of variability across these factors. We introduce AnInfoNCE, a generalization of InfoNCE that can provably uncover the latent factors in this anisotropic setting, broadly generalizing previous identifiability results in CL. We validate our identifiability results in controlled experiments and show that AnInfoNCE increases the recovery of previously collapsed information in CIFAR10 and ImageNet, albeit at the cost of downstream accuracy. Additionally, we explore and discuss further mismatches between theoretical assumptions and practical implementations, including extensions to hard negative mining and loss ensembles.
Effective pruning of web-scale datasets based on complexity of concept clusters
Jan 09, 2024



Utilizing massive web-scale datasets has led to unprecedented performance gains in machine learning models, but also imposes outlandish compute requirements for their training. In order to improve training and data efficiency, we here push the limits of pruning large-scale multimodal datasets for training CLIP-style models. Today's most effective pruning method on ImageNet clusters data samples into separate concepts according to their embedding and prunes away the most prototypical samples. We scale this approach to LAION and improve it by noting that the pruning rate should be concept-specific and adapted to the complexity of the concept. Using a simple and intuitive complexity measure, we are able to reduce the training cost to a quarter of regular training. By filtering from the LAION dataset, we find that training on a smaller set of high-quality data can lead to higher performance with significantly lower training costs. More specifically, we are able to outperform the LAION-trained OpenCLIP-ViT-B32 model on ImageNet zero-shot accuracy by 1.1p.p. while only using 27.7% of the data and training compute. Despite a strong reduction in training cost, we also see improvements on ImageNet dist. shifts, retrieval tasks and VTAB. On the DataComp Medium benchmark, we achieve a new state-of-the-art ImageNet zero-shot accuracy and a competitive average zero-shot accuracy on 38 evaluation tasks.
Does CLIP's Generalization Performance Mainly Stem from High Train-Test Similarity?
Oct 14, 2023



Foundation models like CLIP are trained on hundreds of millions of samples and effortlessly generalize to new tasks and inputs. Out of the box, CLIP shows stellar zero-shot and few-shot capabilities on a wide range of out-of-distribution (OOD) benchmarks, which prior works attribute mainly to today's large and comprehensive training dataset (like LAION). However, it is questionable how meaningful terms like out-of-distribution generalization are for CLIP as it seems likely that web-scale datasets like LAION simply contain many samples that are similar to common OOD benchmarks originally designed for ImageNet. To test this hypothesis, we retrain CLIP on pruned LAION splits that replicate ImageNet's train-test similarity with respect to common OOD benchmarks. While we observe a performance drop on some benchmarks, surprisingly, CLIP's overall performance remains high. This shows that high train-test similarity is insufficient to explain CLIP's OOD performance, and other properties of the training data must drive CLIP to learn more generalizable representations. Additionally, by pruning data points that are dissimilar to the OOD benchmarks, we uncover a 100M split of LAION ($\frac{1}{4}$th of its original size) on which CLIP can be trained to match its original OOD performance.
Adapting ImageNet-scale models to complex distribution shifts with self-learning
Apr 28, 2021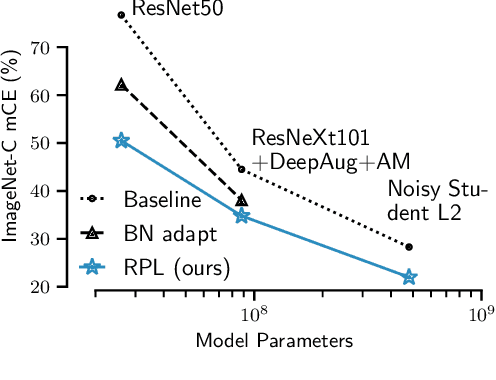

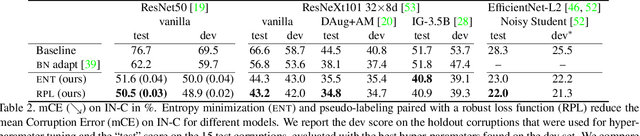
While self-learning methods are an important component in many recent domain adaptation techniques, they are not yet comprehensively evaluated on ImageNet-scale datasets common in robustness research. In extensive experiments on ResNet and EfficientNet models, we find that three components are crucial for increasing performance with self-learning: (i) using short update times between the teacher and the student network, (ii) fine-tuning only few affine parameters distributed across the network, and (iii) leveraging methods from robust classification to counteract the effect of label noise. We use these insights to obtain drastically improved state-of-the-art results on ImageNet-C (22.0% mCE), ImageNet-R (17.4% error) and ImageNet-A (14.8% error). Our techniques yield further improvements in combination with previously proposed robustification methods. Self-learning is able to reduce the top-1 error to a point where no substantial further progress can be expected. We therefore re-purpose the dataset from the Visual Domain Adaptation Challenge 2019 and use a subset of it as a new robustness benchmark (ImageNet-D) which proves to be a more challenging dataset for all current state-of-the-art models (58.2% error) to guide future research efforts at the intersection of robustness and domain adaptation on ImageNet scale.
Improving robustness against common corruptions by covariate shift adaptation
Jun 30, 2020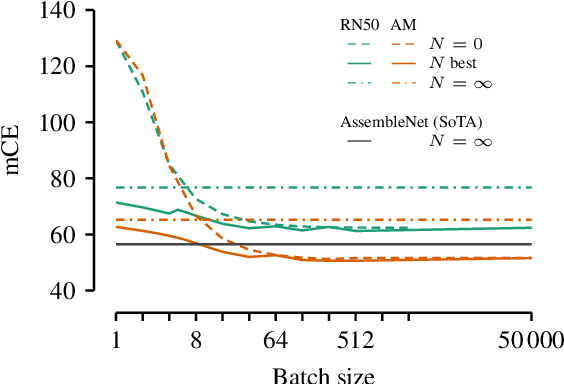
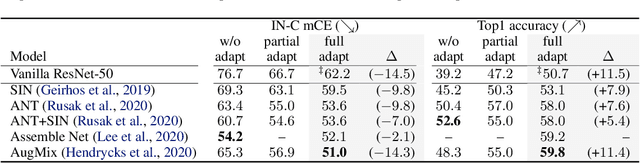
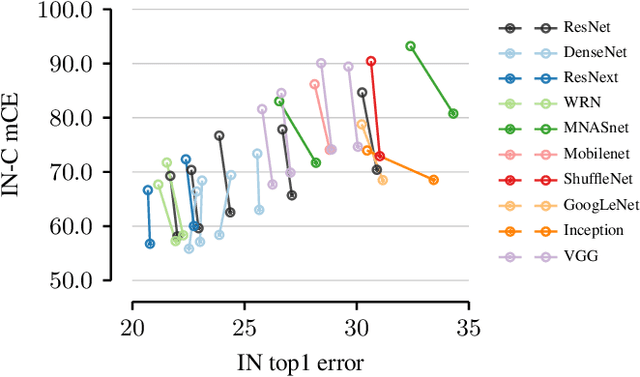
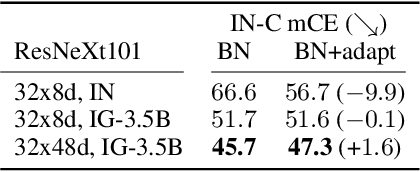
Today's state-of-the-art machine vision models are vulnerable to image corruptions like blurring or compression artefacts, limiting their performance in many real-world applications. We here argue that popular benchmarks to measure model robustness against common corruptions (like ImageNet-C) underestimate model robustness in many (but not all) application scenarios. The key insight is that in many scenarios, multiple unlabeled examples of the corruptions are available and can be used for unsupervised online adaptation. Replacing the activation statistics estimated by batch normalization on the training set with the statistics of the corrupted images consistently improves the robustness across 25 different popular computer vision models. Using the corrected statistics, ResNet-50 reaches 62.2% mCE on ImageNet-C compared to 76.7% without adaptation. With the more robust AugMix model, we improve the state of the art from 56.5% mCE to 51.0% mCE. Even adapting to a single sample improves robustness for the ResNet-50 and AugMix models, and 32 samples are sufficient to improve the current state of the art for a ResNet-50 architecture. We argue that results with adapted statistics should be included whenever reporting scores in corruption benchmarks and other out-of-distribution generalization settings.
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Feb 26, 2020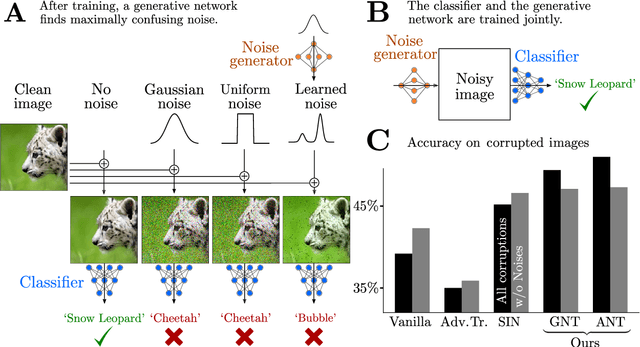
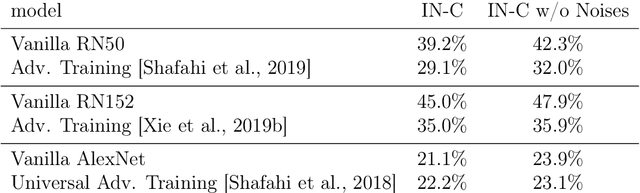
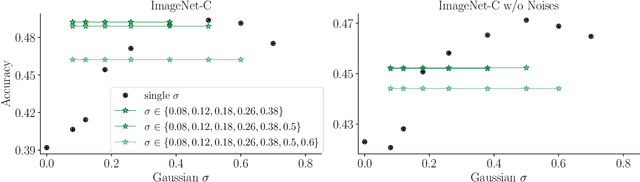
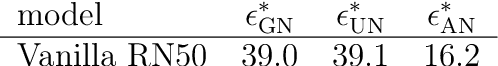
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.
Benchmarking Robustness in Object Detection: Autonomous Driving when Winter is Coming
Jul 17, 2019
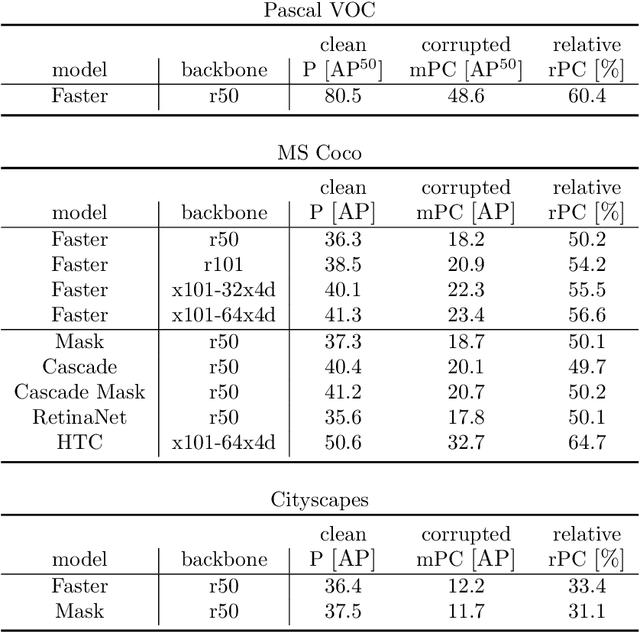


The ability to detect objects regardless of image distortions or weather conditions is crucial for real-world applications of deep learning like autonomous driving. We here provide an easy-to-use benchmark to assess how object detection models perform when image quality degrades. The three resulting benchmark datasets, termed Pascal-C, Coco-C and Cityscapes-C, contain a large variety of image corruptions. We show that a range of standard object detection models suffer a severe performance loss on corrupted images (down to 30-60% of the original performance). However, a simple data augmentation trick - stylizing the training images - leads to a substantial increase in robustness across corruption type, severity and dataset. We envision our comprehensive benchmark to track future progress towards building robust object detection models. Benchmark, code and data are available at: http://github.com/bethgelab/robust-detection-benchmark