 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Meta-Learning without Memorization
Dec 24, 2019
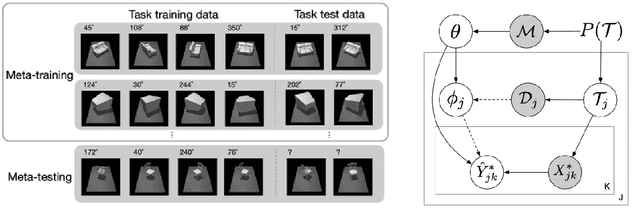

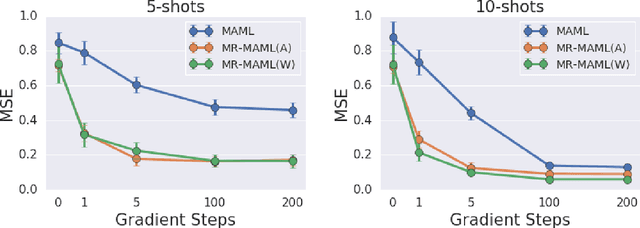

The ability to learn new concepts with small amounts of data is a critical aspect of intelligence that has proven challenging for deep learning methods. Meta-learning has emerged as a promising technique for leveraging data from previous tasks to enable efficient learning of new tasks. However, most meta-learning algorithms implicitly require that the meta-training tasks be mutually-exclusive, such that no single model can solve all of the tasks at once. For example, when creating tasks for few-shot image classification, prior work uses a per-task random assignment of image classes to N-way classification labels. If this is not done, the meta-learner can ignore the task training data and learn a single model that performs all of the meta-training tasks zero-shot, but does not adapt effectively to new image classes. This requirement means that the user must take great care in designing the tasks, for example by shuffling labels or removing task identifying information from the inputs. In some domains, this makes meta-learning entirely inapplicable. In this paper, we address this challenge by designing a meta-regularization objective using information theory that places precedence on data-driven adaptation. This causes the meta-learner to decide what must be learned from the task training data and what should be inferred from the task testing input. By doing so, our algorithm can successfully use data from non-mutually-exclusive tasks to efficiently adapt to novel tasks. We demonstrate its applicability to both contextual and gradient-based meta-learning algorithms, and apply it in practical settings where applying standard meta-learning has been difficult. Our approach substantially outperforms standard meta-learning algorithms in these settings.
Multi-scale Cloud Detection in Remote Sensing Images using a Dual Convolutional Neural Network
Jun 01, 2020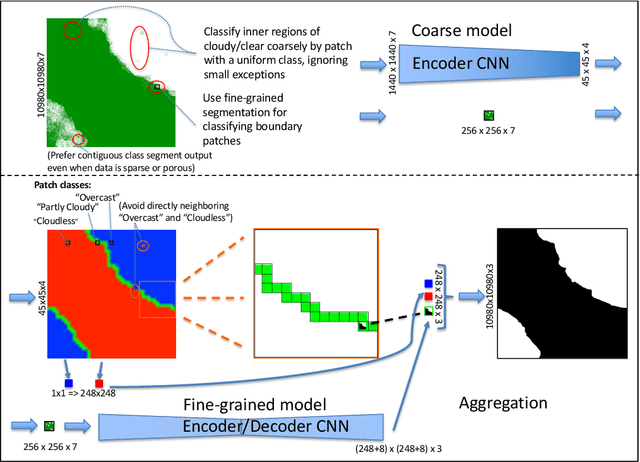
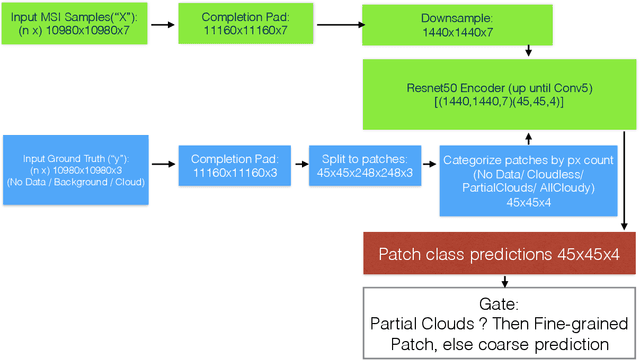
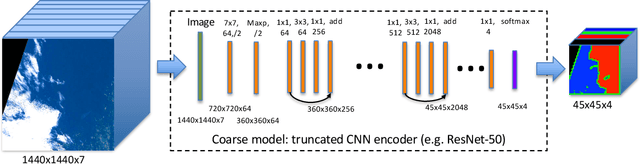
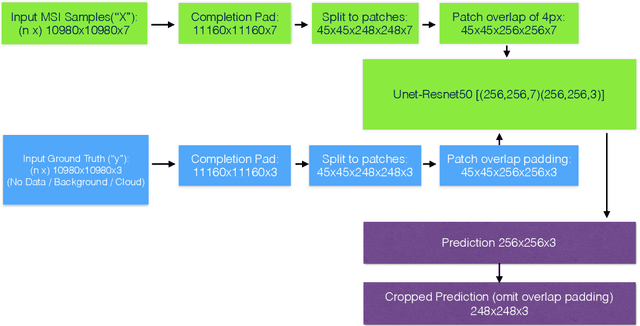
Semantic segmentation by convolutional neural networks (CNN) has advanced the state of the art in pixel-level classification of remote sensing images. However, processing large images typically requires analyzing the image in small patches, and hence features that have large spatial extent still cause challenges in tasks such as cloud masking. To support a wider scale of spatial features while simultaneously reducing computational requirements for large satellite images, we propose an architecture of two cascaded CNN model components successively processing undersampled and full resolution images. The first component distinguishes between patches in the inner cloud area from patches at the cloud's boundary region. For the cloud-ambiguous edge patches requiring further segmentation, the framework then delegates computation to a fine-grained model component. We apply the architecture to a cloud detection dataset of complete Sentinel-2 multispectral images, approximately annotated for minimal false negatives in a land use application. On this specific task and data, we achieve a 16\% relative improvement in pixel accuracy over a CNN baseline based on patching.
Do ideas have shape? Plato's theory of forms as the continuous limit of artificial neural networks
Aug 10, 2020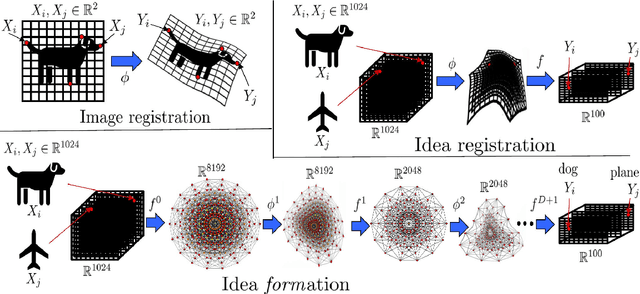
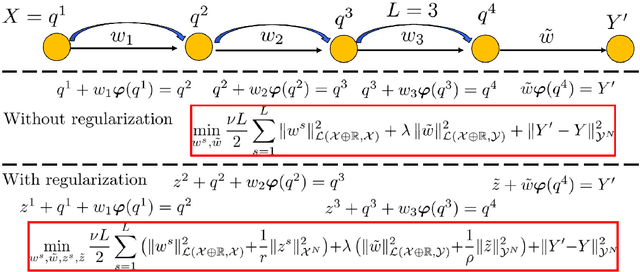

We show that ResNets converge, in the infinite depth limit, to a generalization of computational anatomy/image registration algorithms. In this generalization (idea registration), images are replaced by abstractions (ideas) living in high dimensional RKHS spaces, and material points are replaced by data points. Whereas computational anatomy compares images by creating alignments via deformations of their coordinate systems (the material space), idea registration compares ideas by creating alignments via transformations of their (abstract RKHS) feature spaces. This identification of ResNets as idea registration algorithms has several remarkable consequences. The search for good architectures can be reduced to that of good kernels, and we show that the composition of idea registration blocks (idea formation) with reduced equivariant multi-channel kernels (introduced here) recovers and generalizes CNNs to arbitrary spaces and groups of transformations. Minimizers of $L_2$ regularized ResNets satisfy a discrete least action principle implying the near preservation of the norm of weights and biases across layers. The parameters of trained ResNets can be identified as solutions of an autonomous Hamiltonian system defined by the activation function and the architecture of the ANN. Momenta variables provide a sparse representation of the parameters of a ResNet. Minimizers of the $L_2$ regularized ResNets and ANNs (1) exist (2) are unique up to the value of the initial momentum, and (3) converge to minimizers of continuous idea formation variational problems. The registration regularization strategy provides a principled alternative to Dropout for ANNs. Pointwise RKHS error estimates lead to deterministic error estimates for ANNs, and the identification of ResNets as MAP estimators of deep residual Gaussian processes (introduced here) provides probabilistic error estimates.
LANCE: efficient low-precision quantized Winograd convolution for neural networks based on graphics processing units
Mar 19, 2020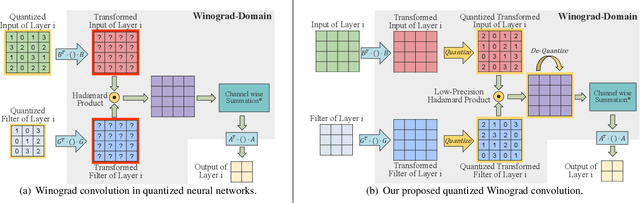
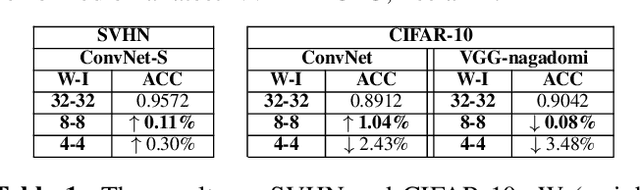
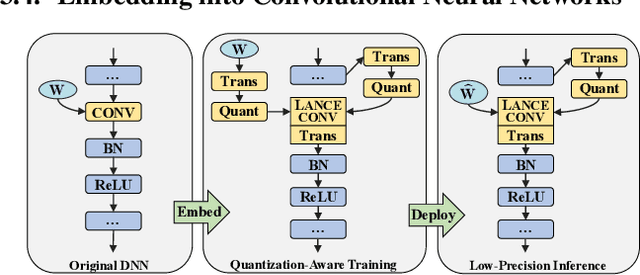

Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.
Extreme Low-Light Imaging with Multi-granulation Cooperative Networks
May 16, 2020
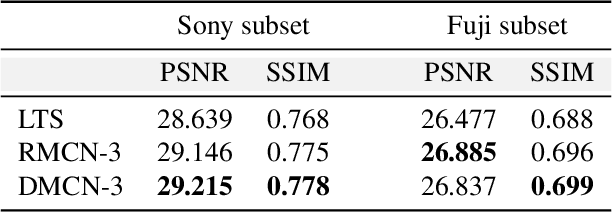
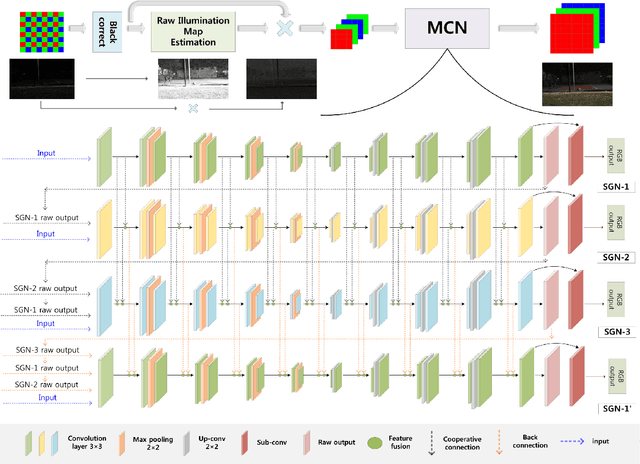

Low-light imaging is challenging since images may appear to be dark and noised due to low signal-to-noise ratio, complex image content, and the variety in shooting scenes in extreme low-light condition. Many methods have been proposed to enhance the imaging quality under extreme low-light conditions, but it remains difficult to obtain satisfactory results, especially when they attempt to retain high dynamic range (HDR). In this paper, we propose a novel method of multi-granulation cooperative networks (MCN) with bidirectional information flow to enhance extreme low-light images, and design an illumination map estimation function (IMEF) to preserve high dynamic range (HDR). To facilitate this research, we also contribute to create a new benchmark dataset of real-world Dark High Dynamic Range (DHDR) images to evaluate the performance of high dynamic preservation in low light environment. Experimental results show that the proposed method outperforms the state-of-the-art approaches in terms of both visual effects and quantitative analysis.
Unicoder-VL: A Universal Encoder for Vision and Language by Cross-modal Pre-training
Aug 16, 2019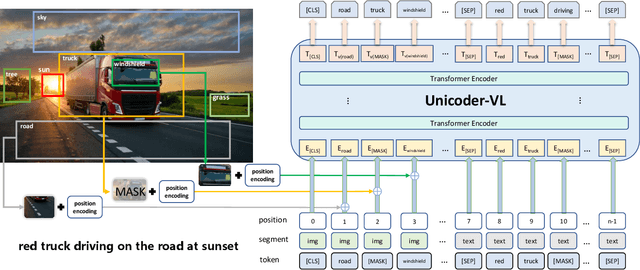
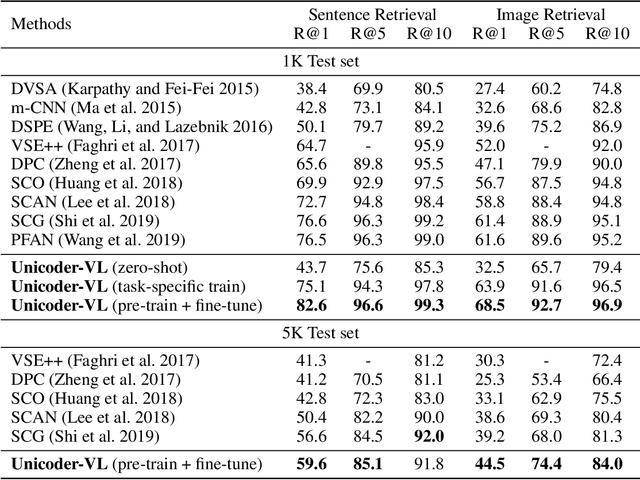
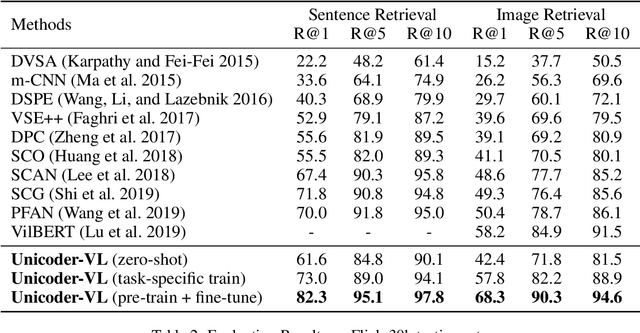
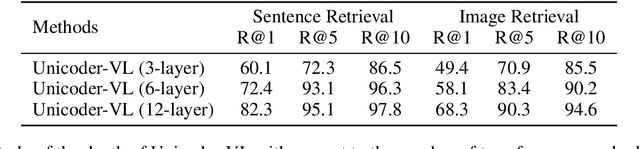
We propose Unicoder-VL, a universal encoder that aims to learn joint representations of vision and language in a pre-training manner. Borrow ideas from cross-lingual pre-trained models, such as XLM and Unicoder, both visual and linguistic contents are fed into a multi-layer transformer for the cross-modal pre-training, where three pre-trained tasks are employed, including masked language model, masked object label prediction and visual-linguistic matching. The first two tasks learn context-aware representations for input tokens based on linguistic and visual contents jointly. The last task tries to predict whether an image and a text describe each other. After pretraining on large amounts of image-caption pairs, we transfer Unicoder-VL to image-text retrieval tasks with just one additional output layer, and achieve state-of-the-art performances on both MSCOCO and Flicker30K.
A kernel Principal Component Analysis (kPCA) digest with a new backward mapping (pre-image reconstruction) strategy
Jan 07, 2020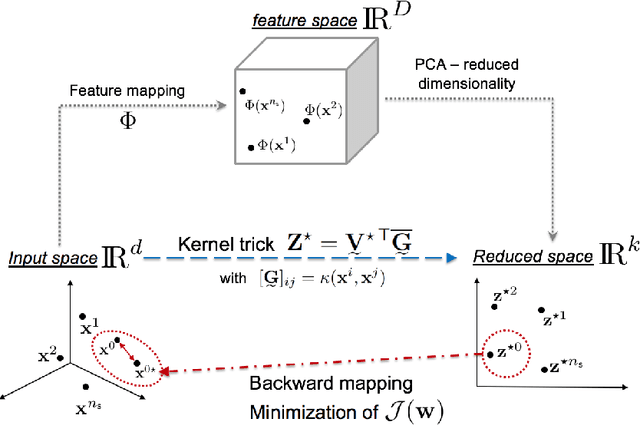

Methodologies for multidimensionality reduction aim at discovering low-dimensional manifolds where data ranges. Principal Component Analysis (PCA) is very effective if data have linear structure. But fails in identifying a possible dimensionality reduction if data belong to a nonlinear low-dimensional manifold. For nonlinear dimensionality reduction, kernel Principal Component Analysis (kPCA) is appreciated because of its simplicity and ease implementation. The paper provides a concise review of PCA and kPCA main ideas, trying to collect in a single document aspects that are often dispersed. Moreover, a strategy to map back the reduced dimension into the original high dimensional space is also devised, based on the minimization of a discrepancy functional.
Scene recognition based on DNN and game theory with its applications in human-robot interaction
Dec 07, 2019


Scene recognition model based on the DNN and game theory with its applications in human-robot interaction is proposed in this paper. The use of deep learning methods in the field of image scene recognition is still in its infancy, but has become an important trend in the future. As the innovative idea of the paper, we propose the following novelties. (1) In this paper, the discrete displacement field is used to represent deformation. The registration problem is transformed into a problem of minimum energy in random field to finalize the image pre-processing task. (2) We select neighboring homogeneous sample features and the neighboring heterogeneous sample features for the extracted sample features to build a triple and modify the traditional neural network to propose the novel DNN for scene understanding. (3) The robot control is well combined to guide the robot vision for multiple tasks. The experiment is then conducted to validate the overall performance.
Mitigating Gender Bias in Captioning Systems
Jun 15, 2020
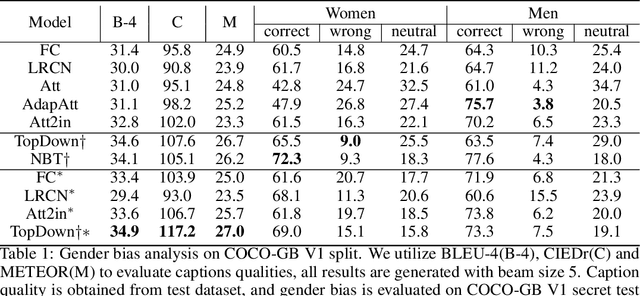
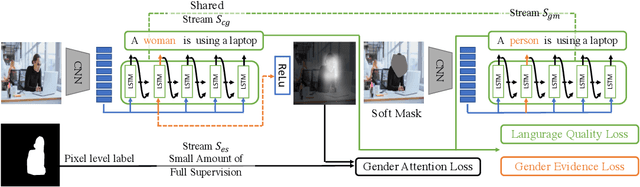
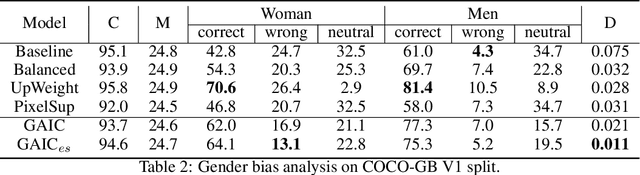
Recent studies have shown that captioning datasets, such as the COCO dataset, may contain severe social bias which could potentially lead to unintentional discrimination in learning models. In this work, we specifically focus on the gender bias problem. The existing dataset fails to quantify bias because models that intrinsically memorize gender bias from training data could still achieve a competitive performance on the biased test dataset. To bridge the gap, we create two new splits: COCO-GB v1 and v2 to quantify the inherent gender bias which could be learned by models. Several widely used baselines are evaluated on our new settings, and experimental results indicate that most models learn gender bias from the training data, leading to an undesirable gender prediction error towards women. To overcome the unwanted bias, we propose a novel Guided Attention Image Captioning model (GAIC) which provides self-guidance on visual attention to encourage the model to explore correct gender visual evidence. Experimental results validate that GAIC can significantly reduce gender prediction error, with a competitive caption quality. Our codes and the designed benchmark datasets are available at https://github.com/CaptionGenderBias2020.
FCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning
Nov 04, 2019
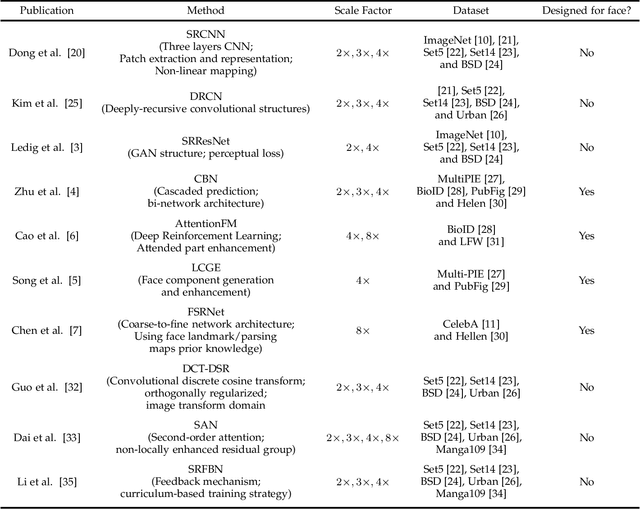
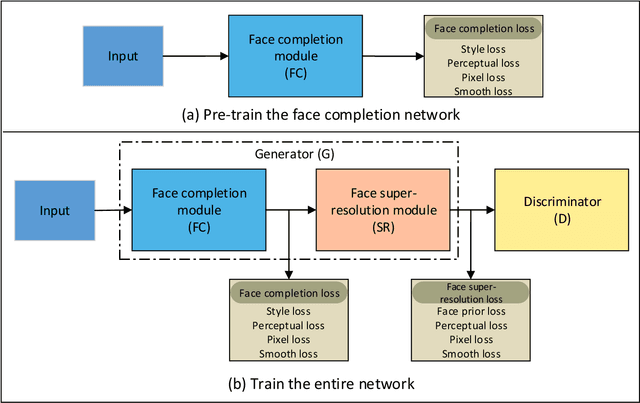
Combined variations containing low-resolution and occlusion often present in face images in the wild, e.g., under the scenario of video surveillance. While most of the existing face image recovery approaches can handle only one type of variation per model, in this work, we propose a deep generative adversarial network (FCSR-GAN) for performing joint face completion and face super-resolution via multi-task learning. The generator of FCSR-GAN aims to recover a high-resolution face image without occlusion given an input low-resolution face image with occlusion. The discriminator of FCSR-GAN uses a set of carefully designed losses (an adversarial loss, a perceptual loss, a pixel loss, a smooth loss, a style loss, and a face prior loss) to assure the high quality of the recovered high-resolution face images without occlusion. The whole network of FCSR-GAN can be trained end-to-end using our two-stage training strategy. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms the state-of-the-art methods in jointly performing face super-resolution (up to 8 $\times$) and face completion, and shows good generalization ability in cross-database testing. Our FCSR-GAN is also useful for improving face identification performance when there are low-resolution and occlusion in face images.