 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Completely Self-Supervised Crowd Counting via Distribution Matching
Sep 14, 2020
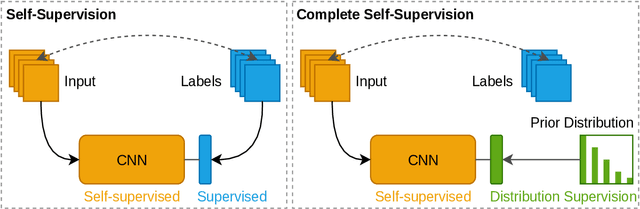
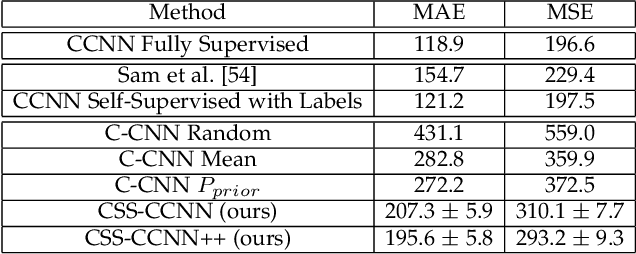
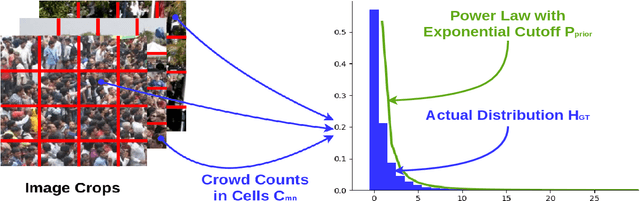
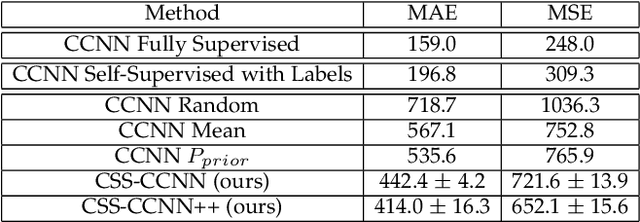
Dense crowd counting is a challenging task that demands millions of head annotations for training models. Though existing self-supervised approaches could learn good representations, they require some labeled data to map these features to the end task of density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. The only input required to train, apart from a large set of unlabeled crowd images, is the approximate upper limit of the crowd count for the given dataset. Our method dwells on the idea that natural crowds follow a power law distribution, which could be leveraged to yield error signals for backpropagation. A density regressor is first pretrained with self-supervision and then the distribution of predictions is matched to the prior by optimizing Sinkhorn distance between the two. Experiments show that this results in effective learning of crowd features and delivers significant counting performance. Furthermore, we establish the superiority of our method in less data setting as well. The code and models for our approach is available at https://github.com/val-iisc/css-ccnn.
Image Clustering without Ground Truth
Oct 25, 2016
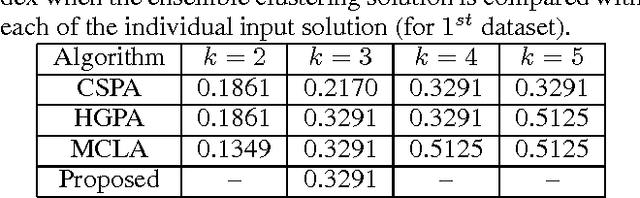
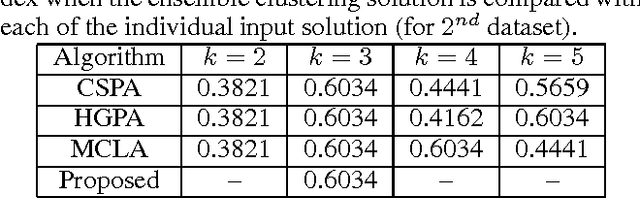
Cluster analysis has become one of the most exercised research areas over the past few decades in computer science. As a consequence, numerous clustering algorithms have already been developed to find appropriate partitions of a set of objects. Given multiple such clustering solutions, it is a challenging task to obtain an ensemble of these solutions. This becomes more challenging when the ground truth about the number of clusters is unavailable. In this paper, we introduce a crowd-powered model to collect solutions of image clustering from the general crowd and pose it as a clustering ensemble problem with variable number of clusters. The varying number of clusters basically reflects the crowd workers' perspective toward a particular set of objects. We allow a set of crowd workers to independently cluster the images as per their perceptions. We address the problem by finding out centroid of the clusters using an appropriate distance measure and prioritize the likelihood of similarity of the individual cluster sets. The effectiveness of the proposed method is demonstrated by applying it on multiple artificial datasets obtained from crowd.
Deeply-Recursive Convolutional Network for Image Super-Resolution
Nov 11, 2016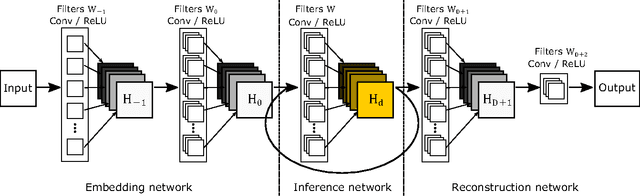
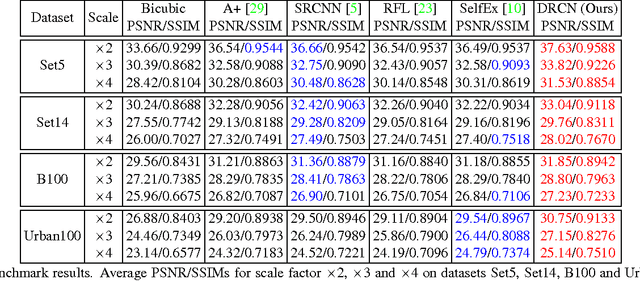
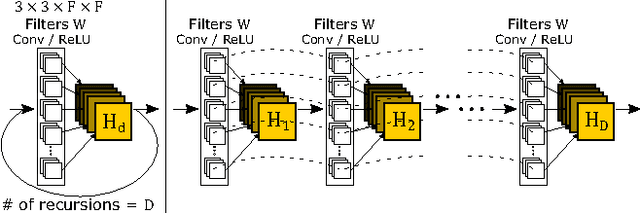
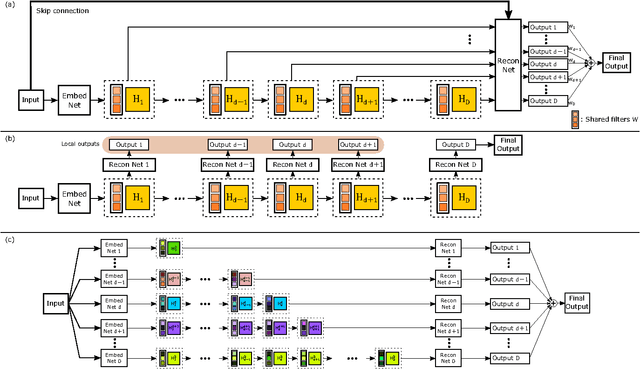
We propose an image super-resolution method (SR) using a deeply-recursive convolutional network (DRCN). Our network has a very deep recursive layer (up to 16 recursions). Increasing recursion depth can improve performance without introducing new parameters for additional convolutions. Albeit advantages, learning a DRCN is very hard with a standard gradient descent method due to exploding/vanishing gradients. To ease the difficulty of training, we propose two extensions: recursive-supervision and skip-connection. Our method outperforms previous methods by a large margin.
Fusion of Camera Model and Source Device Specific Forensic Methods for Improved Tamper Detection
Feb 24, 2020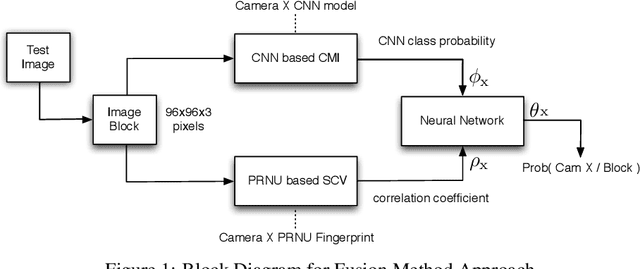


PRNU based camera recognition method is widely studied in the image forensic literature. In recent years, CNN based camera model recognition methods have been developed. These two methods also provide solutions to tamper localization problem. In this paper, we propose their combination via a Neural Network to achieve better small-scale tamper detection performance. According to the results, the fusion method performs better than underlying methods even under high JPEG compression. For forgeries as small as 100$\times$100 pixel size, the proposed method outperforms the state-of-the-art, which validates the usefulness of fusion for localization of small-size image forgeries. We believe the proposed approach is feasible for any tamper-detection pipeline using the PRNU based methodology.
RL-CycleGAN: Reinforcement Learning Aware Simulation-To-Real
Jun 16, 2020
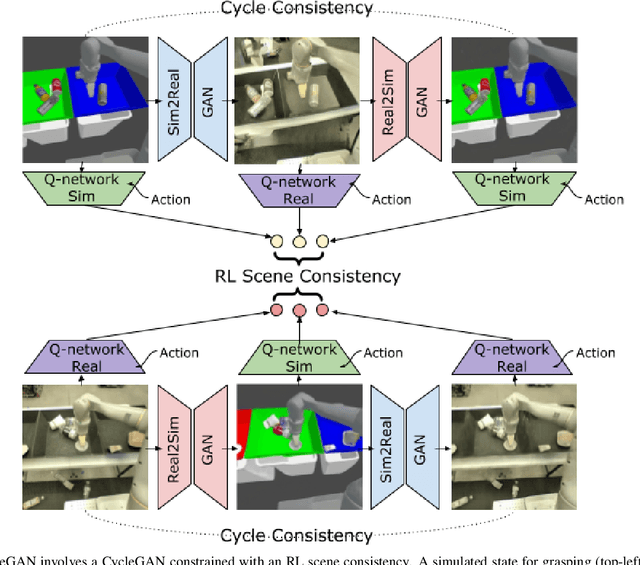


Deep neural network based reinforcement learning (RL) can learn appropriate visual representations for complex tasks like vision-based robotic grasping without the need for manually engineering or prior learning a perception system. However, data for RL is collected via running an agent in the desired environment, and for applications like robotics, running a robot in the real world may be extremely costly and time consuming. Simulated training offers an appealing alternative, but ensuring that policies trained in simulation can transfer effectively into the real world requires additional machinery. Simulations may not match reality, and typically bridging the simulation-to-reality gap requires domain knowledge and task-specific engineering. We can automate this process by employing generative models to translate simulated images into realistic ones. However, this sort of translation is typically task-agnostic, in that the translated images may not preserve all features that are relevant to the task. In this paper, we introduce the RL-scene consistency loss for image translation, which ensures that the translation operation is invariant with respect to the Q-values associated with the image. This allows us to learn a task-aware translation. Incorporating this loss into unsupervised domain translation, we obtain RL-CycleGAN, a new approach for simulation-to-real-world transfer for reinforcement learning. In evaluations of RL-CycleGAN on two vision-based robotics grasping tasks, we show that RL-CycleGAN offers a substantial improvement over a number of prior methods for sim-to-real transfer, attaining excellent real-world performance with only a modest number of real-world observations.
Visually Grounded Compound PCFGs
Sep 25, 2020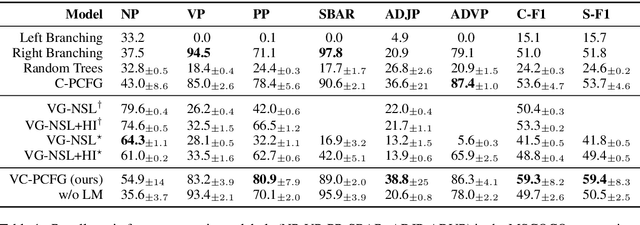
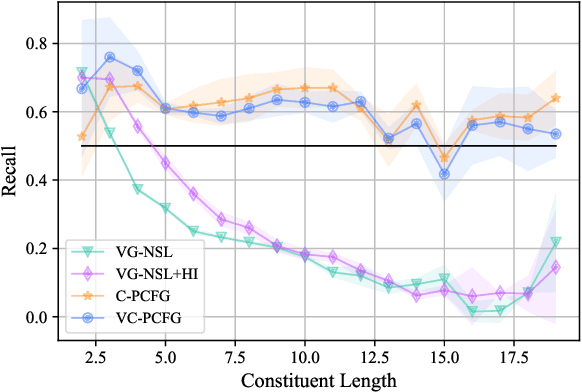
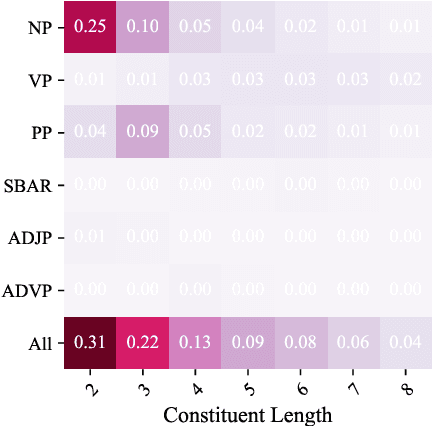
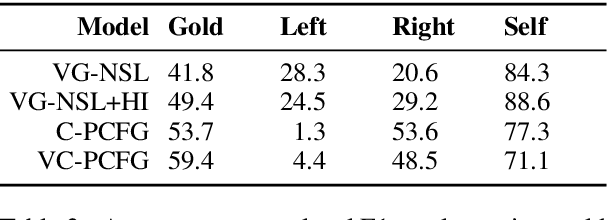
Exploiting visual groundings for language understanding has recently been drawing much attention. In this work, we study visually grounded grammar induction and learn a constituency parser from both unlabeled text and its visual groundings. Existing work on this task (Shi et al., 2019) optimizes a parser via Reinforce and derives the learning signal only from the alignment of images and sentences. While their model is relatively accurate overall, its error distribution is very uneven, with low performance on certain constituents types (e.g., 26.2% recall on verb phrases, VPs) and high on others (e.g., 79.6% recall on noun phrases, NPs). This is not surprising as the learning signal is likely insufficient for deriving all aspects of phrase-structure syntax and gradient estimates are noisy. We show that using an extension of probabilistic context-free grammar model we can do fully-differentiable end-to-end visually grounded learning. Additionally, this enables us to complement the image-text alignment loss with a language modeling objective. On the MSCOCO test captions, our model establishes a new state of the art, outperforming its non-grounded version and, thus, confirming the effectiveness of visual groundings in constituency grammar induction. It also substantially outperforms the previous grounded model, with largest improvements on more `abstract' categories (e.g., +55.1% recall on VPs).
Training Set Affect on Super Resolution for Automated Target Recognition
Oct 29, 2019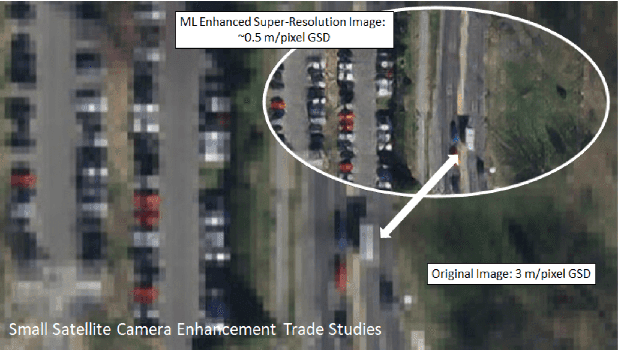
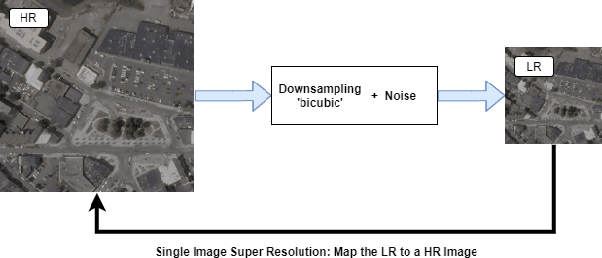
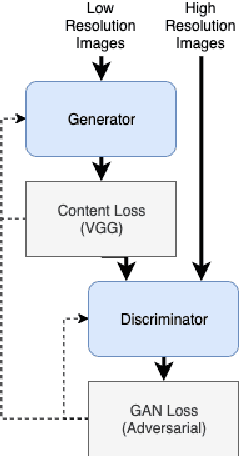
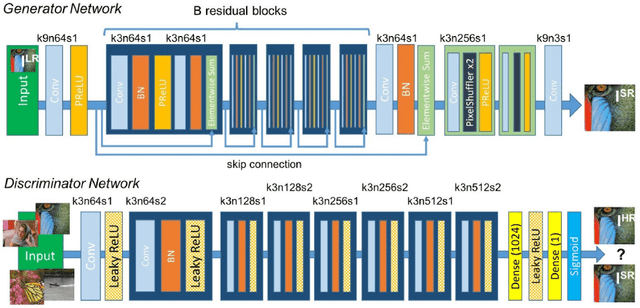
Do we need to have more expensive remote sensing satellites when we could use single image super-resolution (SISR) to get the spatial resolution that we want? By using a Super Resolution Generative Adversarial Network, (SRGAN) we can get higher resolution images. Previous work by Shermeyer et al. [1] have used SISR as a preprocessing step describe an increase in mAP of 10-36 % in object detection for native 30cm to 15cm satellite imagery. This suggests a possible improvement to automated target recognition in image classification and object detection. The SRGAN takes a low-resolution image and maps it to a high-resolution image creating the super resolution product. We train 5 SRGANs on different land-use classes (e.g. agriculture, cities) and find the qualitative and quantitative differences in SISR, binary classification, and object detection performance.
Semantic Bottleneck Scene Generation
Nov 26, 2019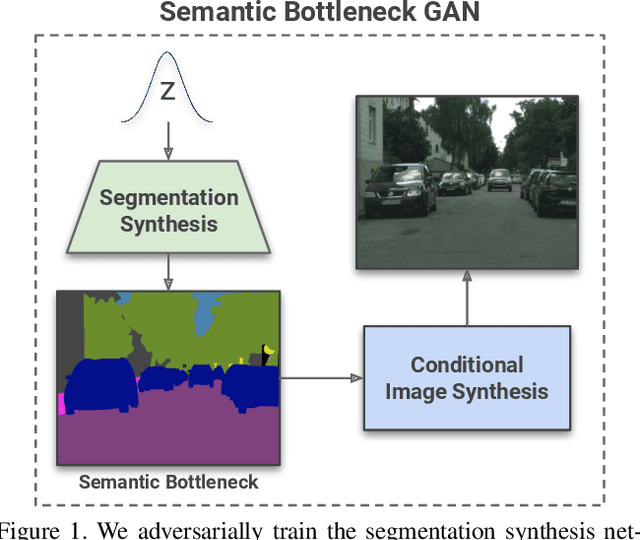
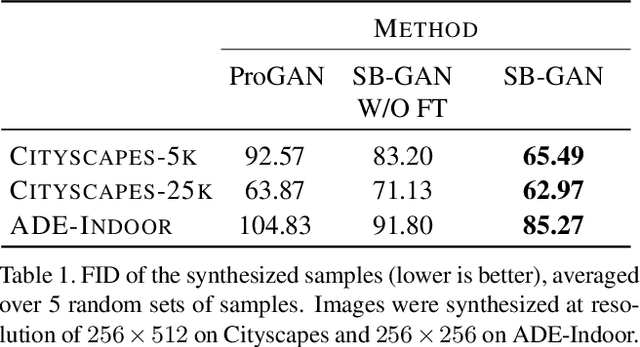
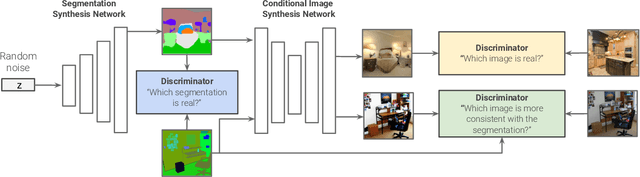
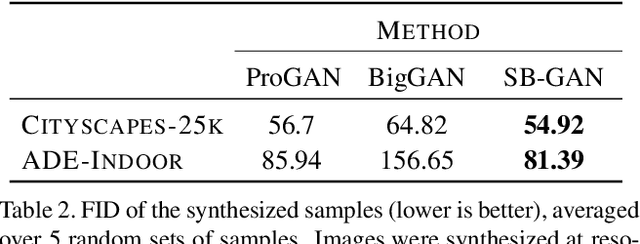
Coupling the high-fidelity generation capabilities of label-conditional image synthesis methods with the flexibility of unconditional generative models, we propose a semantic bottleneck GAN model for unconditional synthesis of complex scenes. We assume pixel-wise segmentation labels are available during training and use them to learn the scene structure. During inference, our model first synthesizes a realistic segmentation layout from scratch, then synthesizes a realistic scene conditioned on that layout. For the former, we use an unconditional progressive segmentation generation network that captures the distribution of realistic semantic scene layouts. For the latter, we use a conditional segmentation-to-image synthesis network that captures the distribution of photo-realistic images conditioned on the semantic layout. When trained end-to-end, the resulting model outperforms state-of-the-art generative models in unsupervised image synthesis on two challenging domains in terms of the Frechet Inception Distance and user-study evaluations. Moreover, we demonstrate the generated segmentation maps can be used as additional training data to strongly improve recent segmentation-to-image synthesis networks.
Future Localization from an Egocentric Depth Image
Sep 07, 2015

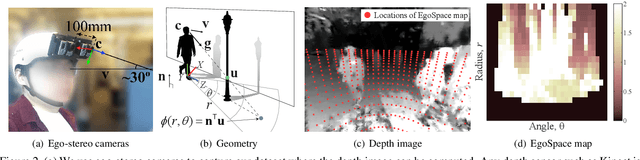
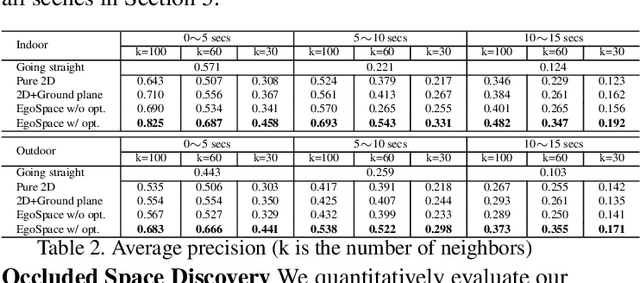
This paper presents a method for future localization: to predict a set of plausible trajectories of ego-motion given a depth image. We predict paths avoiding obstacles, between objects, even paths turning around a corner into space behind objects. As a byproduct of the predicted trajectories of ego-motion, we discover in the image the empty space occluded by foreground objects. We use no image based features such as semantic labeling/segmentation or object detection/recognition for this algorithm. Inspired by proxemics, we represent the space around a person using an EgoSpace map, akin to an illustrated tourist map, that measures a likelihood of occlusion at the egocentric coordinate system. A future trajectory of ego-motion is modeled by a linear combination of compact trajectory bases allowing us to constrain the predicted trajectory. We learn the relationship between the EgoSpace map and trajectory from the EgoMotion dataset providing in-situ measurements of the future trajectory. A cost function that takes into account partial occlusion due to foreground objects is minimized to predict a trajectory. This cost function generates a trajectory that passes through the occluded space, which allows us to discover the empty space behind the foreground objects. We quantitatively evaluate our method to show predictive validity and apply to various real world scenes including walking, shopping, and social interactions.
A Dual-Source Approach for 3D Human Pose Estimation from a Single Image
Sep 06, 2017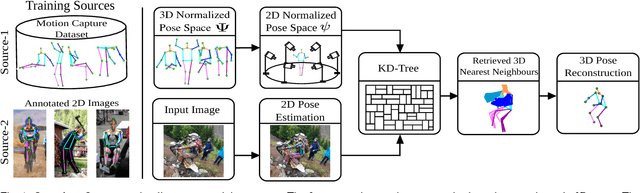
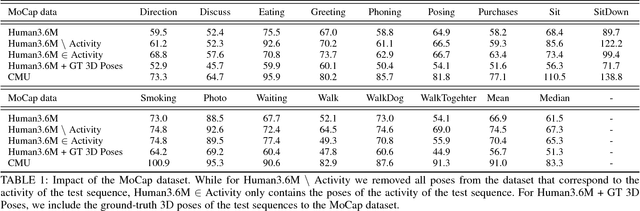
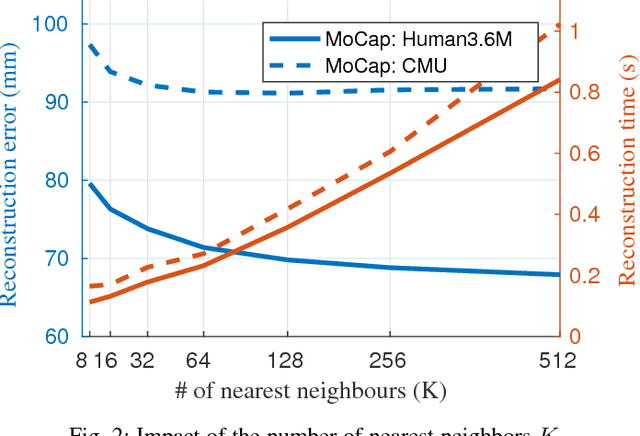
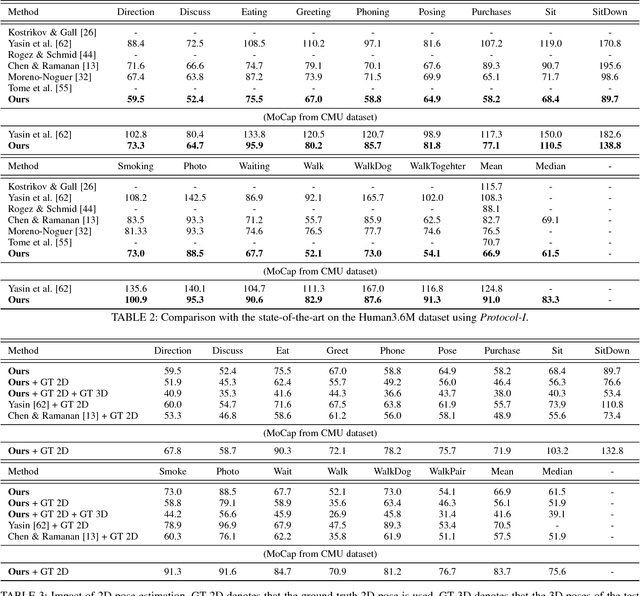
In this work we address the challenging problem of 3D human pose estimation from single images. Recent approaches learn deep neural networks to regress 3D pose directly from images. One major challenge for such methods, however, is the collection of training data. Specifically, collecting large amounts of training data containing unconstrained images annotated with accurate 3D poses is infeasible. We therefore propose to use two independent training sources. The first source consists of accurate 3D motion capture data, and the second source consists of unconstrained images with annotated 2D poses. To integrate both sources, we propose a dual-source approach that combines 2D pose estimation with efficient 3D pose retrieval. To this end, we first convert the motion capture data into a normalized 2D pose space, and separately learn a 2D pose estimation model from the image data. During inference, we estimate the 2D pose and efficiently retrieve the nearest 3D poses. We then jointly estimate a mapping from the 3D pose space to the image and reconstruct the 3D pose. We provide a comprehensive evaluation of the proposed method and experimentally demonstrate the effectiveness of our approach, even when the skeleton structures of the two sources differ substantially.