 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-criteria Rank-based Aggregation for Explainable AI
May 30, 2025



Explainability is crucial for improving the transparency of black-box machine learning models. With the advancement of explanation methods such as LIME and SHAP, various XAI performance metrics have been developed to evaluate the quality of explanations. However, different explainers can provide contrasting explanations for the same prediction, introducing trade-offs across conflicting quality metrics. Although available aggregation approaches improve robustness, reducing explanations' variability, very limited research employed a multi-criteria decision-making approach. To address this gap, this paper introduces a multi-criteria rank-based weighted aggregation method that balances multiple quality metrics simultaneously to produce an ensemble of explanation models. Furthermore, we propose rank-based versions of existing XAI metrics (complexity, faithfulness and stability) to better evaluate ranked feature importance explanations. Extensive experiments on publicly available datasets demonstrate the robustness of the proposed model across these metrics. Comparative analyses of various multi-criteria decision-making and rank aggregation algorithms showed that TOPSIS and WSUM are the best candidates for this use case.
Multi-objective Consensus Clustering Framework for Flight Search Recommendation
Feb 26, 2020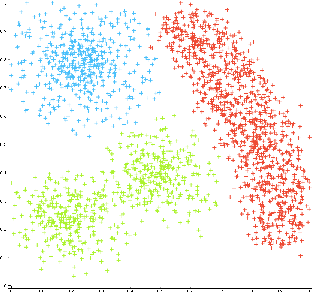
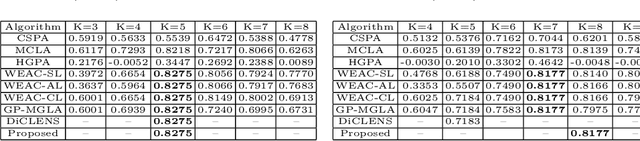
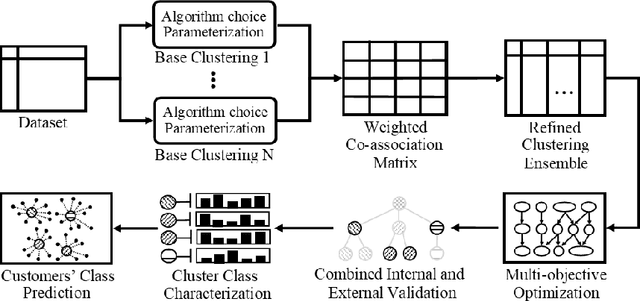
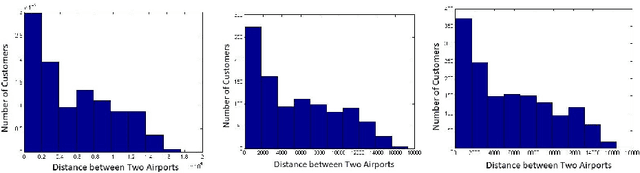
In the travel industry, online customers book their travel itinerary according to several features, like cost and duration of the travel or the quality of amenities. To provide personalized recommendations for travel searches, an appropriate segmentation of customers is required. Clustering ensemble approaches were developed to overcome well-known problems of classical clustering approaches, that each rely on a different theoretical model and can thus identify in the data space only clusters corresponding to this model. Clustering ensemble approaches combine multiple clustering results, each from a different algorithmic configuration, for generating more robust consensus clusters corresponding to agreements between initial clusters. We present a new clustering ensemble multi-objective optimization-based framework developed for analyzing Amadeus customer search data and improve personalized recommendations. This framework optimizes diversity in the clustering ensemble search space and automatically determines an appropriate number of clusters without requiring user's input. Experimental results compare the efficiency of this approach with other existing approaches on Amadeus customer search data in terms of internal (Adjusted Rand Index) and external (Amadeus business metric) validations.
Image Clustering without Ground Truth
Oct 25, 2016
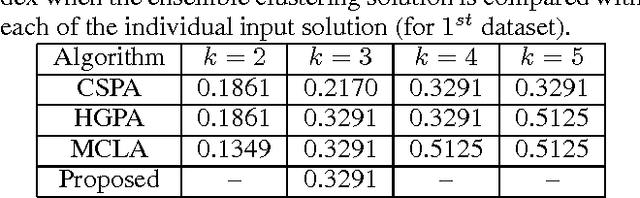
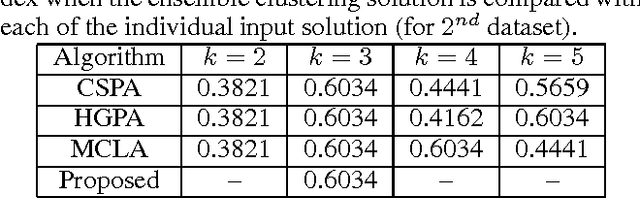
Cluster analysis has become one of the most exercised research areas over the past few decades in computer science. As a consequence, numerous clustering algorithms have already been developed to find appropriate partitions of a set of objects. Given multiple such clustering solutions, it is a challenging task to obtain an ensemble of these solutions. This becomes more challenging when the ground truth about the number of clusters is unavailable. In this paper, we introduce a crowd-powered model to collect solutions of image clustering from the general crowd and pose it as a clustering ensemble problem with variable number of clusters. The varying number of clusters basically reflects the crowd workers' perspective toward a particular set of objects. We allow a set of crowd workers to independently cluster the images as per their perceptions. We address the problem by finding out centroid of the clusters using an appropriate distance measure and prioritize the likelihood of similarity of the individual cluster sets. The effectiveness of the proposed method is demonstrated by applying it on multiple artificial datasets obtained from crowd.