 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
May 06, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
Lidar Panoptic Segmentation and Tracking without Bells and Whistles
Oct 19, 2023



State-of-the-art lidar panoptic segmentation (LPS) methods follow bottom-up segmentation-centric fashion wherein they build upon semantic segmentation networks by utilizing clustering to obtain object instances. In this paper, we re-think this approach and propose a surprisingly simple yet effective detection-centric network for both LPS and tracking. Our network is modular by design and optimized for all aspects of both the panoptic segmentation and tracking task. One of the core components of our network is the object instance detection branch, which we train using point-level (modal) annotations, as available in segmentation-centric datasets. In the absence of amodal (cuboid) annotations, we regress modal centroids and object extent using trajectory-level supervision that provides information about object size, which cannot be inferred from single scans due to occlusions and the sparse nature of the lidar data. We obtain fine-grained instance segments by learning to associate lidar points with detected centroids. We evaluate our method on several 3D/4D LPS benchmarks and observe that our model establishes a new state-of-the-art among open-sourced models, outperforming recent query-based models.
Completely Self-Supervised Crowd Counting via Distribution Matching
Sep 14, 2020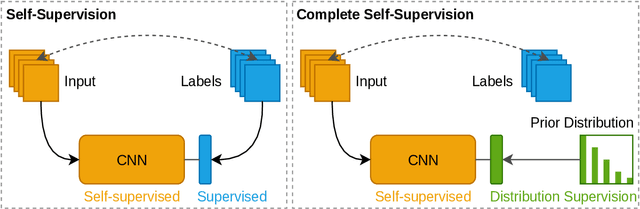
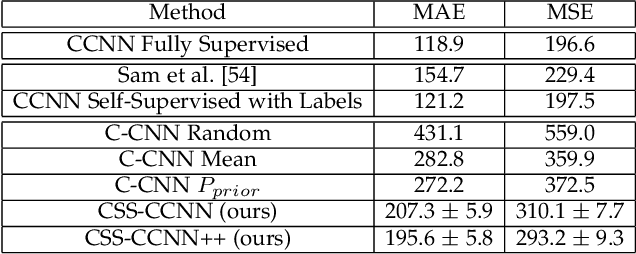
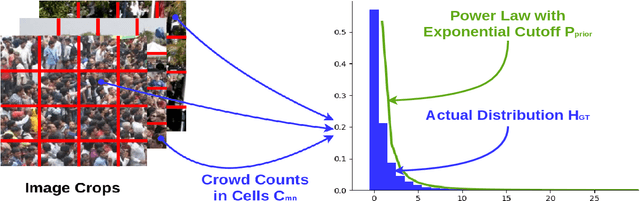
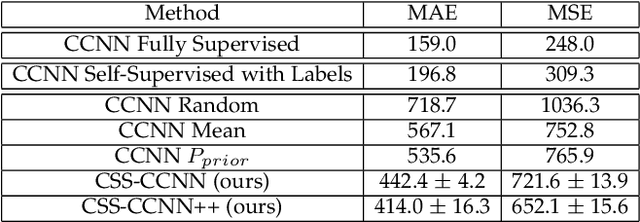
Dense crowd counting is a challenging task that demands millions of head annotations for training models. Though existing self-supervised approaches could learn good representations, they require some labeled data to map these features to the end task of density estimation. We mitigate this issue with the proposed paradigm of complete self-supervision, which does not need even a single labeled image. The only input required to train, apart from a large set of unlabeled crowd images, is the approximate upper limit of the crowd count for the given dataset. Our method dwells on the idea that natural crowds follow a power law distribution, which could be leveraged to yield error signals for backpropagation. A density regressor is first pretrained with self-supervision and then the distribution of predictions is matched to the prior by optimizing Sinkhorn distance between the two. Experiments show that this results in effective learning of crowd features and delivers significant counting performance. Furthermore, we establish the superiority of our method in less data setting as well. The code and models for our approach is available at https://github.com/val-iisc/css-ccnn.
Unsupervised Domain Adaptation for Learning Eye Gaze from a Million Synthetic Images: An Adversarial Approach
Oct 18, 2018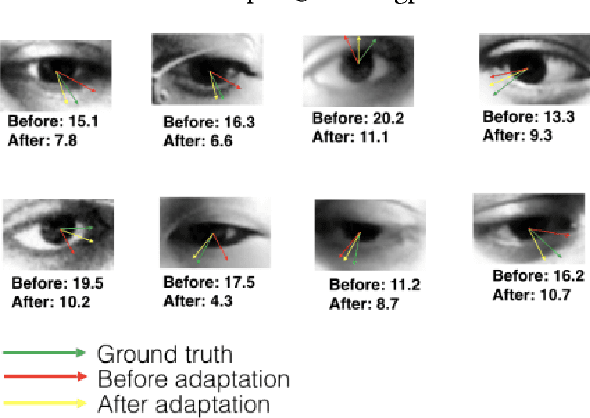
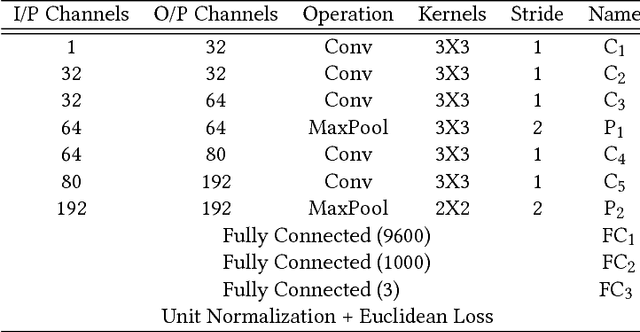


With contemporary advancements of graphics engines, recent trend in deep learning community is to train models on automatically annotated simulated examples and apply on real data during test time. This alleviates the burden of manual annotation. However, there is an inherent difference of distributions between images coming from graphics engine and real world. Such domain difference deteriorates test time performances of models trained on synthetic examples. In this paper we address this issue with unsupervised adversarial feature adaptation across synthetic and real domain for the special use case of eye gaze estimation which is an essential component for various downstream HCI tasks. We initially learn a gaze estimator on annotated synthetic samples rendered from a 3D game engine and then adapt the features of unannotated real samples via a zero-sum minmax adversarial game against a domain discriminator following the recent paradigm of generative adversarial networks. Such adversarial adaptation forces features of both domains to be indistinguishable which enables us to use regression models trained on synthetic domain to be used on real samples. On the challenging MPIIGaze real life dataset, we outperform recent fully supervised methods trained on manually annotated real samples by appreciable margins and also achieve 13\% more relative gain after adaptation compared to the current benchmark method of SimGAN
Bayesian Optimisation with Prior Reuse for Motion Planning in Robot Soccer
Oct 18, 2017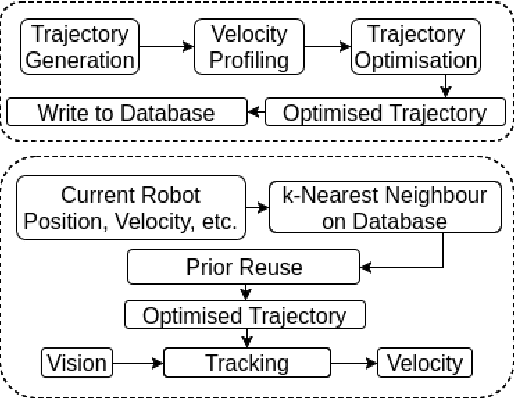

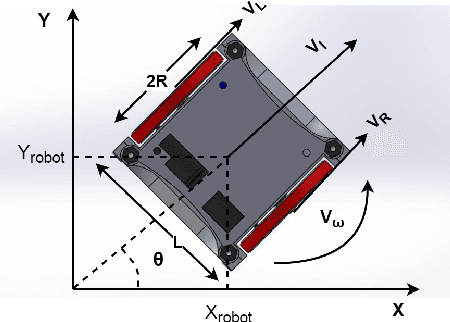
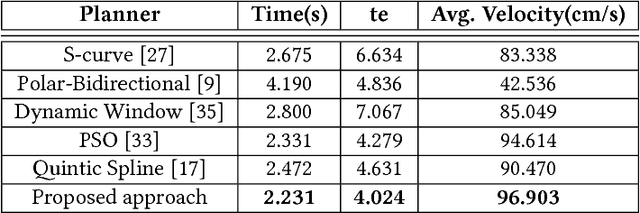
We integrate learning and motion planning for soccer playing differential drive robots using Bayesian optimisation. Trajectories generated using end-slope cubic Bezier splines are first optimised globally through Bayesian optimisation for a set of candidate points with obstacles. The optimised trajectories along with robot and obstacle positions and velocities are stored in a database. The closest planning situation is identified from the database using k-Nearest Neighbour approach. It is further optimised online through reuse of prior information from previously optimised trajectory. Our approach reduces computation time of trajectory optimisation considerably. Velocity profiling generates velocities consistent with robot kinodynamoic constraints, and avoids collision and slipping. Extensive testing is done on developed simulator, as well as on physical differential drive robots. Our method shows marked improvements in mitigating tracking error, and reducing traversal and computational time over competing techniques under the constraints of performing tasks in real time.
Representation-Aggregation Networks for Segmentation of Multi-Gigapixel Histology Images
Jul 27, 2017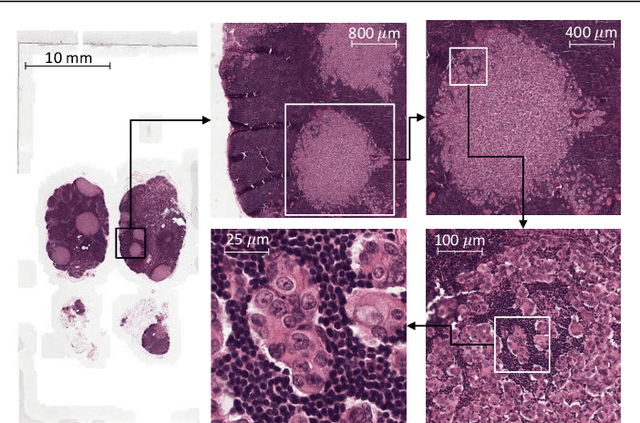
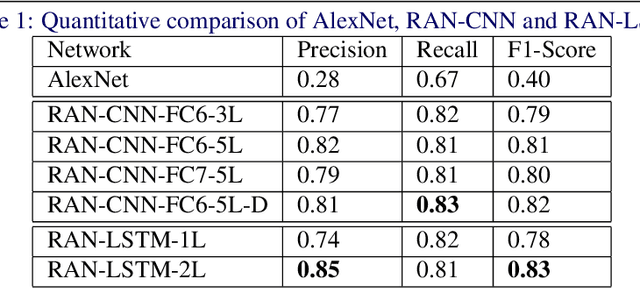
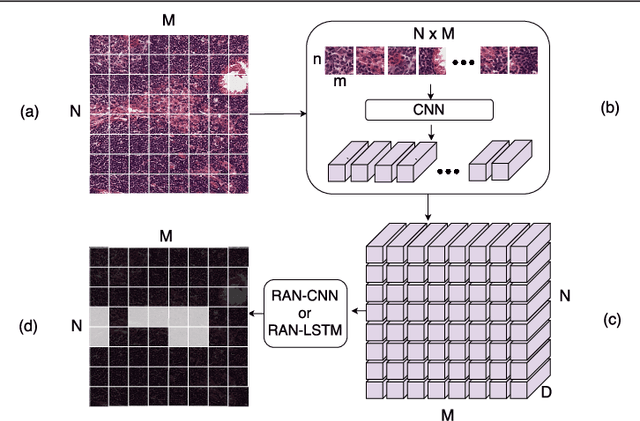
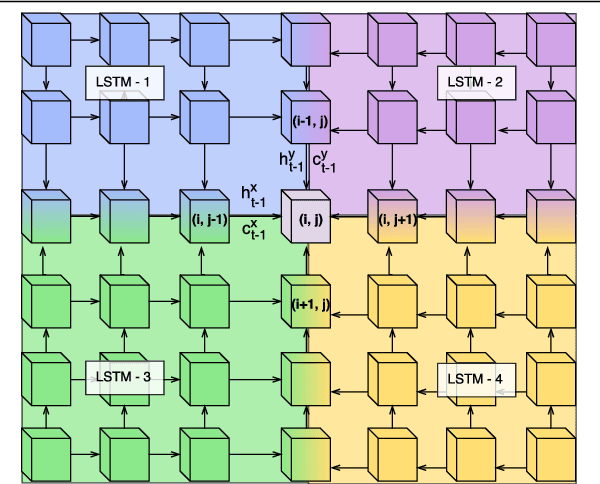
Convolutional Neural Network (CNN) models have become the state-of-the-art for most computer vision tasks with natural images. However, these are not best suited for multi-gigapixel resolution Whole Slide Images (WSIs) of histology slides due to large size of these images. Current approaches construct smaller patches from WSIs which results in the loss of contextual information. We propose to capture the spatial context using novel Representation-Aggregation Network (RAN) for segmentation purposes, wherein the first network learns patch-level representation and the second network aggregates context from a grid of neighbouring patches. We can use any CNN for representation learning, and can utilize CNN or 2D-Long Short Term Memory (2D-LSTM) for context-aggregation. Our method significantly outperformed conventional patch-based CNN approaches on segmentation of tumour in WSIs of breast cancer tissue sections.
Recurrent Memory Addressing for describing videos
Mar 23, 2017
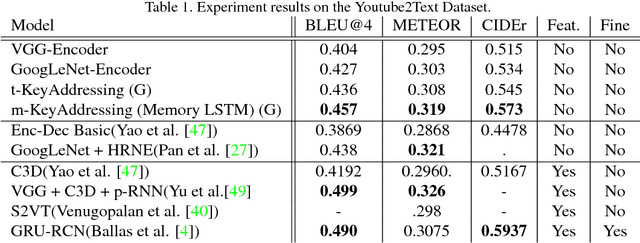
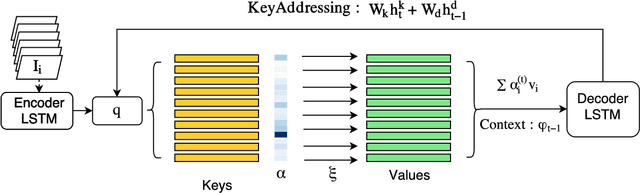
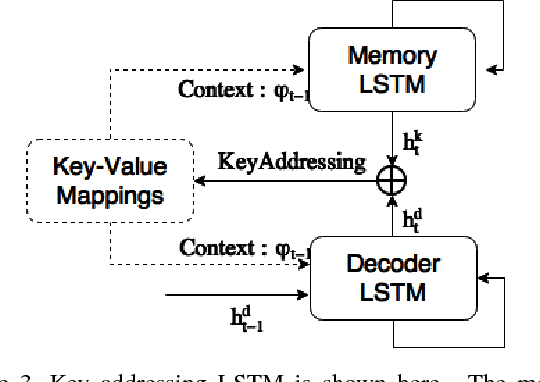
In this paper, we introduce Key-Value Memory Networks to a multimodal setting and a novel key-addressing mechanism to deal with sequence-to-sequence models. The proposed model naturally decomposes the problem of video captioning into vision and language segments, dealing with them as key-value pairs. More specifically, we learn a semantic embedding (v) corresponding to each frame (k) in the video, thereby creating (k, v) memory slots. We propose to find the next step attention weights conditioned on the previous attention distributions for the key-value memory slots in the memory addressing schema. Exploiting this flexibility of the framework, we additionally capture spatial dependencies while mapping from the visual to semantic embedding. Experiments done on the Youtube2Text dataset demonstrate usefulness of recurrent key-addressing, while achieving competitive scores on BLEU@4, METEOR metrics against state-of-the-art models.