 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATE3D: Generalized Attention-based Task-synergized Estimation in 3D*
Apr 16, 2025The emerging trend in computer vision emphasizes developing universal models capable of simultaneously addressing multiple diverse tasks. Such universality typically requires joint training across multi-domain datasets to ensure effective generalization. However, monocular 3D object detection presents unique challenges in multi-domain training due to the scarcity of datasets annotated with accurate 3D ground-truth labels, especially beyond typical road-based autonomous driving contexts. To address this challenge, we introduce a novel weakly supervised framework leveraging pseudo-labels. Current pretrained models often struggle to accurately detect pedestrians in non-road environments due to inherent dataset biases. Unlike generalized image-based 2D object detection models, achieving similar generalization in monocular 3D detection remains largely unexplored. In this paper, we propose GATE3D, a novel framework designed specifically for generalized monocular 3D object detection via weak supervision. GATE3D effectively bridges domain gaps by employing consistency losses between 2D and 3D predictions. Remarkably, our model achieves competitive performance on the KITTI benchmark as well as on an indoor-office dataset collected by us to evaluate the generalization capabilities of our framework. Our results demonstrate that GATE3D significantly accelerates learning from limited annotated data through effective pre-training strategies, highlighting substantial potential for broader impacts in robotics, augmented reality, and virtual reality applications. Project page: https://ies0411.github.io/GATE3D/
Spb3DTracker: A Robust LiDAR-Based Person Tracker for Noisy Environment
Aug 13, 2024Person detection and tracking (PDT) has seen significant advancements with 2D camera-based systems in the autonomous vehicle field, leading to widespread adoption of these algorithms. However, growing privacy concerns have recently emerged as a major issue, prompting a shift towards LiDAR-based PDT as a viable alternative. Within this domain, "Tracking-by-Detection" (TBD) has become a prominent methodology. Despite its effectiveness, LiDAR-based PDT has not yet achieved the same level of performance as camera-based PDT. This paper examines key components of the LiDAR-based PDT framework, including detection post-processing, data association, motion modeling, and lifecycle management. Building upon these insights, we introduce SpbTrack, a robust person tracker designed for diverse environments. Our method achieves superior performance on noisy datasets and state-of-the-art results on KITTI Dataset benchmarks and custom office indoor dataset among LiDAR-based trackers.
Auto-Meta: Automated Gradient Based Meta Learner Search
Jun 11, 2018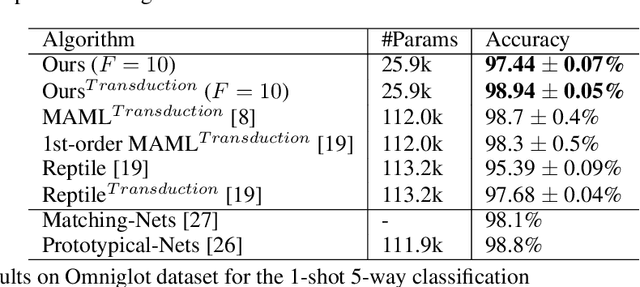
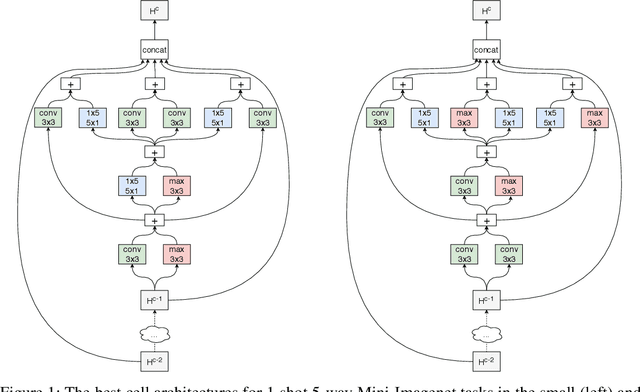
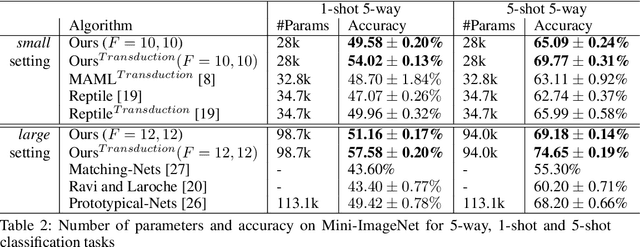
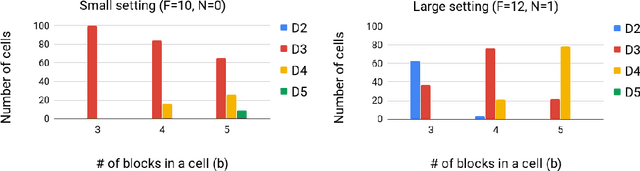
Fully automating machine learning pipeline is one of the outstanding challenges of general artificial intelligence, as practical machine learning often requires costly human driven process, such as hyper-parameter tuning, algorithmic selection, and model selection. In this work, we consider the problem of executing automated, yet scalable search for finding optimal gradient based meta-learners in practice. As a solution, we apply progressive neural architecture search to proto-architectures by appealing to the model agnostic nature of general gradient based meta learners. In the presence of recent universality result of Finn \textit{et al.}\cite{finn:universality_maml:DBLP:/journals/corr/abs-1710-11622}, our search is a priori motivated in that neural network architecture search dynamics---automated or not---may be quite different from that of the classical setting with the same target tasks, due to the presence of the gradient update operator. A posteriori, our search algorithm, given appropriately designed search spaces, finds gradient based meta learners with non-intuitive proto-architectures that are narrowly deep, unlike the inception-like structures previously observed in the resulting architectures of traditional NAS algorithms. Along with these notable findings, the searched gradient based meta-learner achieves state-of-the-art results on the few shot classification problem on Mini-ImageNet with $76.29\%$ accuracy, which is an $13.18\%$ improvement over results reported in the original MAML paper. To our best knowledge, this work is the first successful AutoML implementation in the context of meta learning.
Continual Learning with Deep Generative Replay
Dec 12, 2017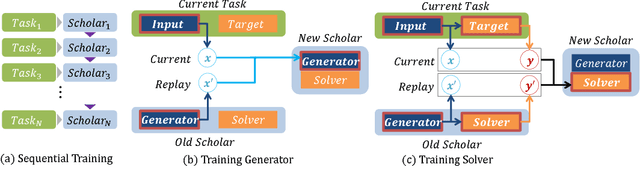
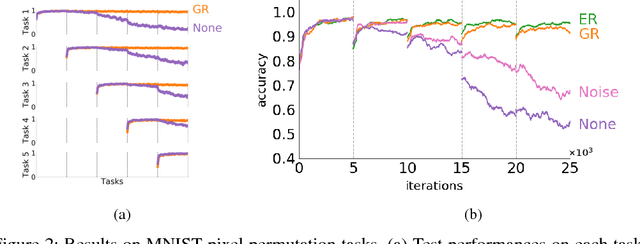
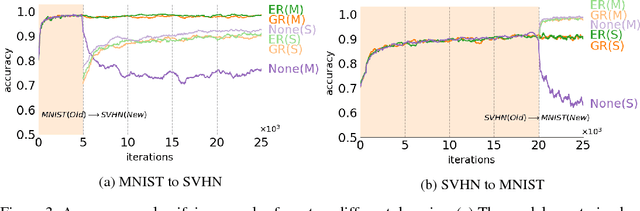
Attempts to train a comprehensive artificial intelligence capable of solving multiple tasks have been impeded by a chronic problem called catastrophic forgetting. Although simply replaying all previous data alleviates the problem, it requires large memory and even worse, often infeasible in real world applications where the access to past data is limited. Inspired by the generative nature of hippocampus as a short-term memory system in primate brain, we propose the Deep Generative Replay, a novel framework with a cooperative dual model architecture consisting of a deep generative model ("generator") and a task solving model ("solver"). With only these two models, training data for previous tasks can easily be sampled and interleaved with those for a new task. We test our methods in several sequential learning settings involving image classification tasks.
Learning to Discover Cross-Domain Relations with Generative Adversarial Networks
May 15, 2017
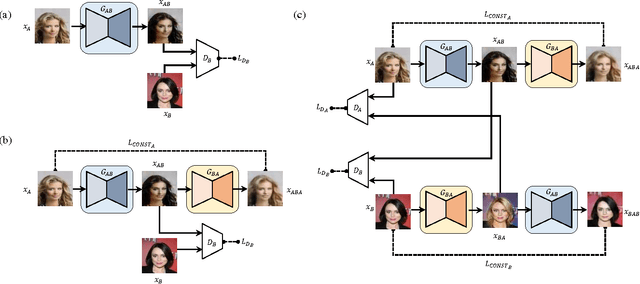
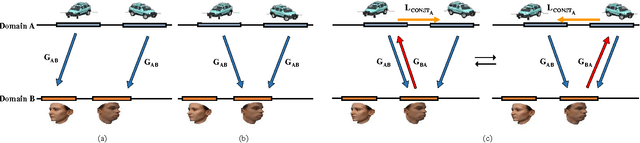
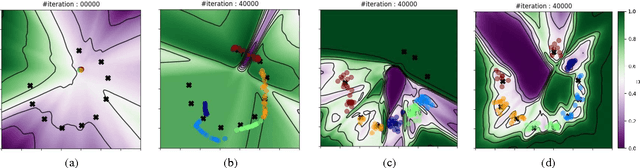
While humans easily recognize relations between data from different domains without any supervision, learning to automatically discover them is in general very challenging and needs many ground-truth pairs that illustrate the relations. To avoid costly pairing, we address the task of discovering cross-domain relations given unpaired data. We propose a method based on generative adversarial networks that learns to discover relations between different domains (DiscoGAN). Using the discovered relations, our proposed network successfully transfers style from one domain to another while preserving key attributes such as orientation and face identity. Source code for official implementation is publicly available https://github.com/SKTBrain/DiscoGAN
Deeply-Recursive Convolutional Network for Image Super-Resolution
Nov 11, 2016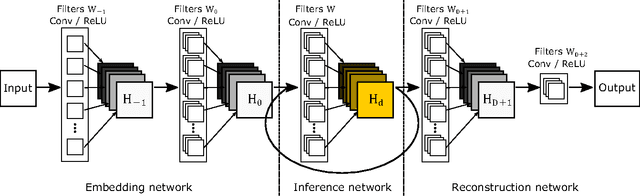
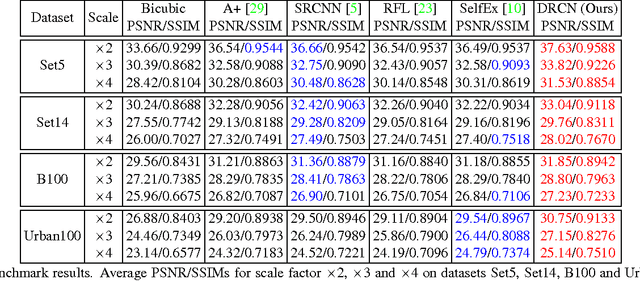
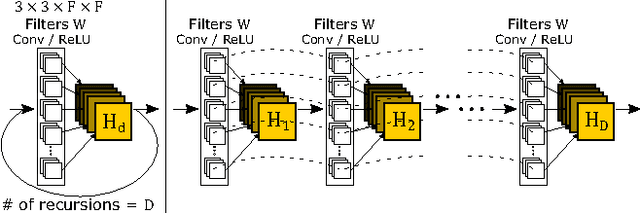
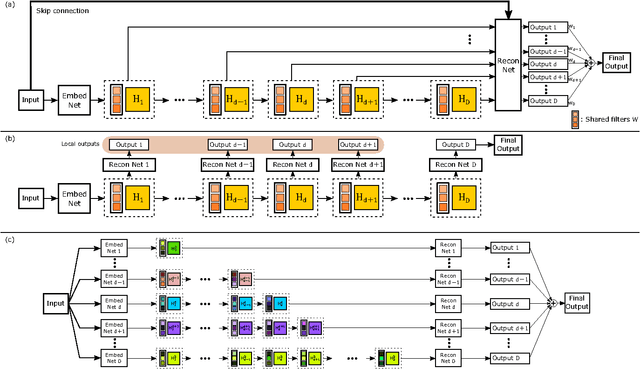
We propose an image super-resolution method (SR) using a deeply-recursive convolutional network (DRCN). Our network has a very deep recursive layer (up to 16 recursions). Increasing recursion depth can improve performance without introducing new parameters for additional convolutions. Albeit advantages, learning a DRCN is very hard with a standard gradient descent method due to exploding/vanishing gradients. To ease the difficulty of training, we propose two extensions: recursive-supervision and skip-connection. Our method outperforms previous methods by a large margin.
Accurate Image Super-Resolution Using Very Deep Convolutional Networks
Nov 11, 2016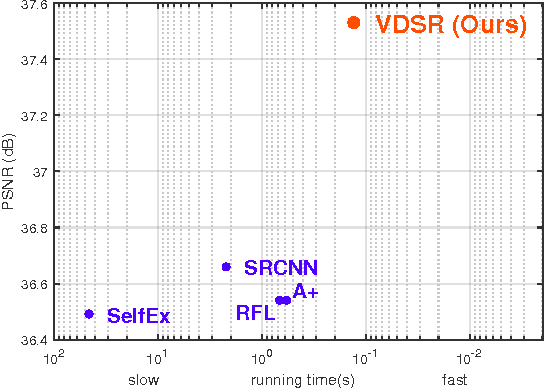
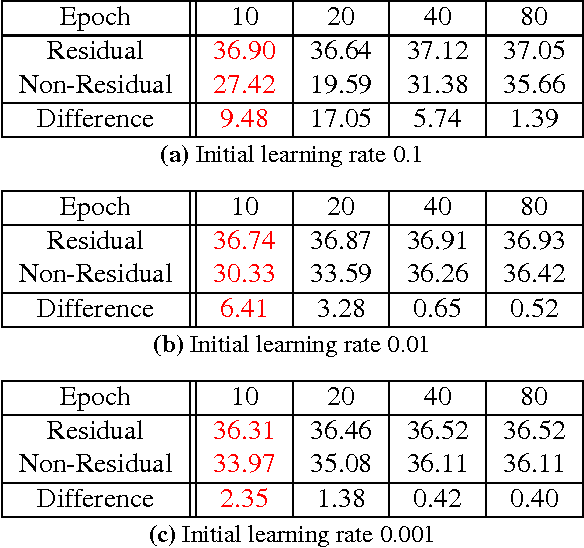
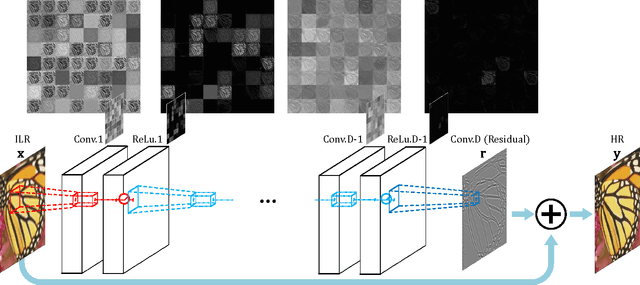

We present a highly accurate single-image super-resolution (SR) method. Our method uses a very deep convolutional network inspired by VGG-net used for ImageNet classification \cite{simonyan2015very}. We find increasing our network depth shows a significant improvement in accuracy. Our final model uses 20 weight layers. By cascading small filters many times in a deep network structure, contextual information over large image regions is exploited in an efficient way. With very deep networks, however, convergence speed becomes a critical issue during training. We propose a simple yet effective training procedure. We learn residuals only and use extremely high learning rates ($10^4$ times higher than SRCNN \cite{dong2015image}) enabled by adjustable gradient clipping. Our proposed method performs better than existing methods in accuracy and visual improvements in our results are easily noticeable.