 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A New Run-based Connected Component Labeling for Efficiently Analyzing and Processing Holes
Jun 16, 2020
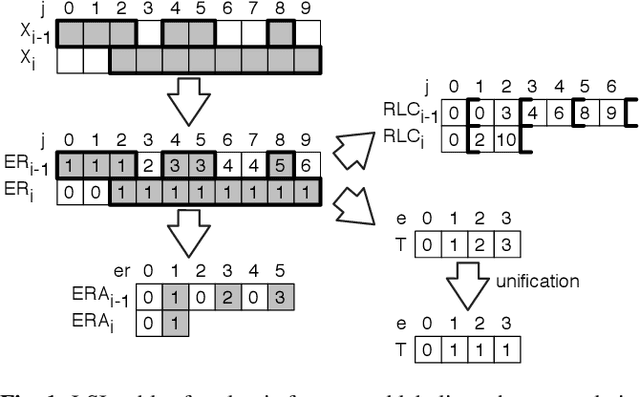
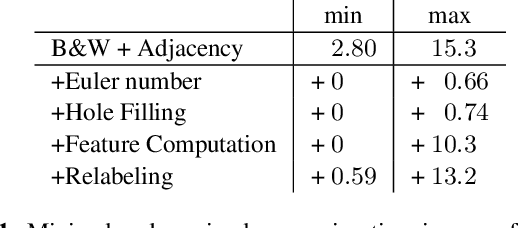
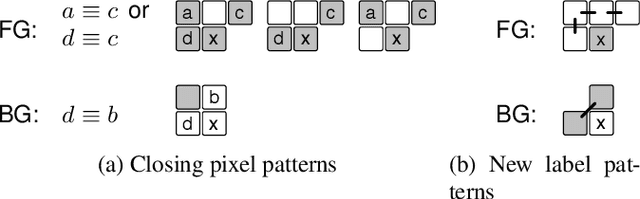
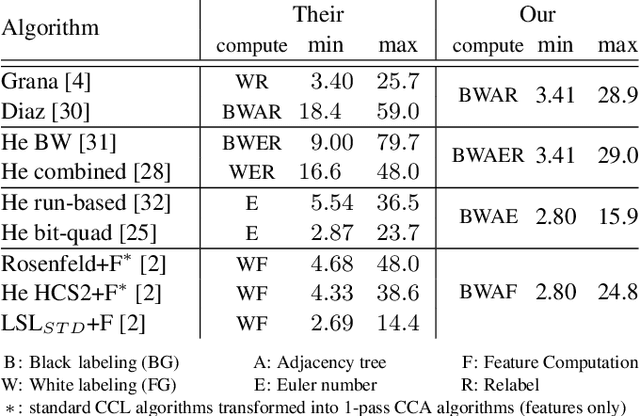
This article introduces a new connected component labeling and analysis algorithm for foreground and background labeling that computes the adjacency tree. The computation of features (bounding boxes, first statistical moments, Euler number) is done on-the-fly. The transitive closure enables an efficient hole processing that can be filled while their features are merged with the surrounding connected component without the need to rescan the image. A comparison with existing algorithms shows that this new algorithm can do all these computations faster than algorithms processing black and white components.
LoRRaL: Facial Action Unit Detection Based on Local Region Relation Learning
Sep 23, 2020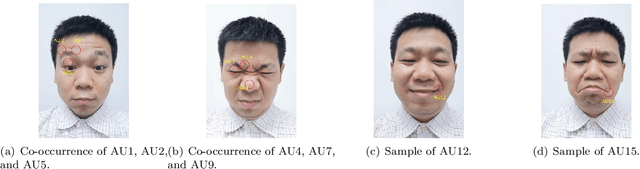
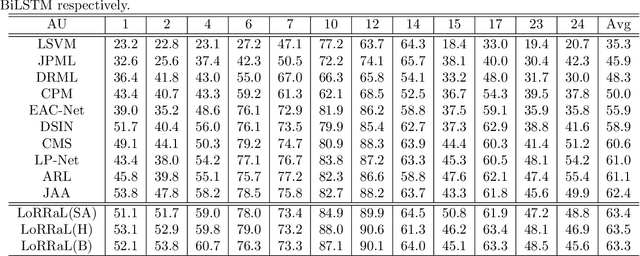
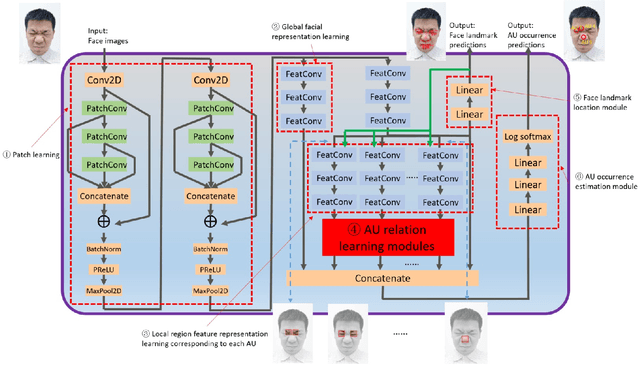
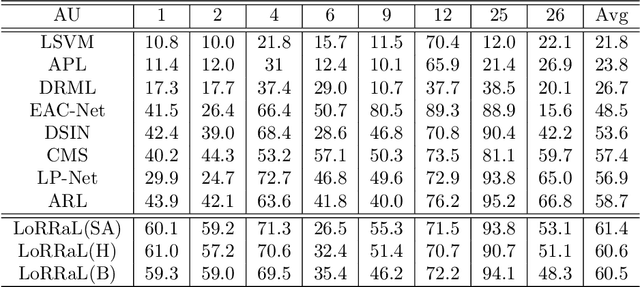
End-to-end convolution representation learning has been proved to be very effective in facial action unit (AU) detection. Considering the co-occurrence and mutual exclusion between facial AUs, in this paper, we propose convolution neural networks with Local Region Relation Learning (LoRRaL), which can combine latent relationships among AUs for an end-to-end approach to facial AU occurrence detection. LoRRaL consists of 1) use bi-directional long short-term memory (BiLSTM) to dynamically and sequentially encode local AU feature maps, 2) use self-attention mechanism to dynamically compute correspondences from local facial regions and to re-aggregate AU feature maps considering AU co-occurrences and mutual exclusions, 3) use a continuous-state modern Hopfield network to encode and map local facial features to more discriminative AU feature maps, that all these networks take the facial image as input and map it to AU occurrences. Our experiments on the challenging BP4D and DISFA Benchmarks without any external data or pre-trained models results in F1-scores of 63.5% and 61.4% respectively, which shows our proposed networks can lead to performance improvement on the AU detection task.
AdaBelief Optimizer: Adapting Stepsizes by the Belief in Observed Gradients
Oct 15, 2020
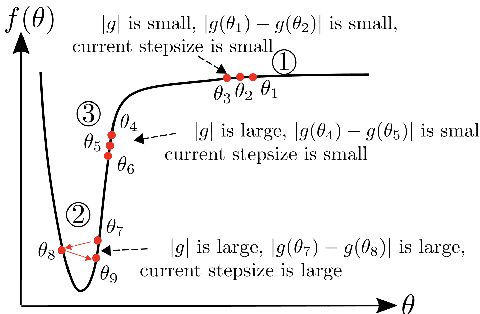
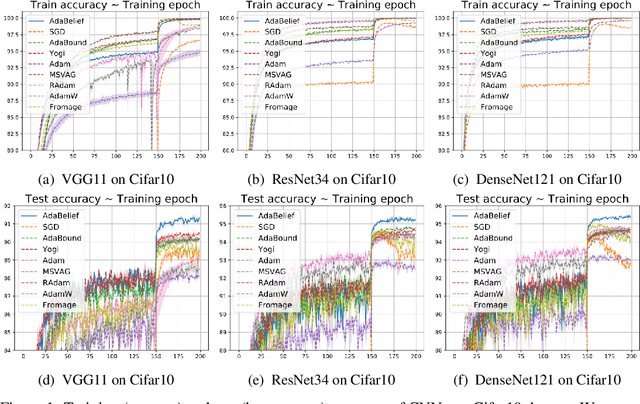

Most popular optimizers for deep learning can be broadly categorized as adaptive methods (e.g. Adam) and accelerated schemes (e.g. stochastic gradient descent (SGD) with momentum). For many models such as convolutional neural networks (CNNs), adaptive methods typically converge faster but generalize worse compared to SGD; for complex settings such as generative adversarial networks (GANs), adaptive methods are typically the default because of their stability.We propose AdaBelief to simultaneously achieve three goals: fast convergence as in adaptive methods, good generalization as in SGD, and training stability. The intuition for AdaBelief is to adapt the stepsize according to the "belief" in the current gradient direction. Viewing the exponential moving average (EMA) of the noisy gradient as the prediction of the gradient at the next time step, if the observed gradient greatly deviates from the prediction, we distrust the current observation and take a small step; if the observed gradient is close to the prediction, we trust it and take a large step. We validate AdaBelief in extensive experiments, showing that it outperforms other methods with fast convergence and high accuracy on image classification and language modeling. Specifically, on ImageNet, AdaBelief achieves comparable accuracy to SGD. Furthermore, in the training of a GAN on Cifar10, AdaBelief demonstrates high stability and improves the quality of generated samples compared to a well-tuned Adam optimizer. Code is available at https://github.com/juntang-zhuang/Adabelief-Optimizer
SimLoss: Class Similarities in Cross Entropy
Mar 06, 2020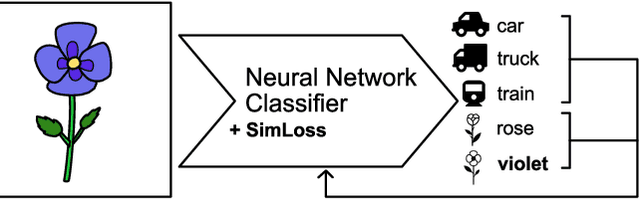
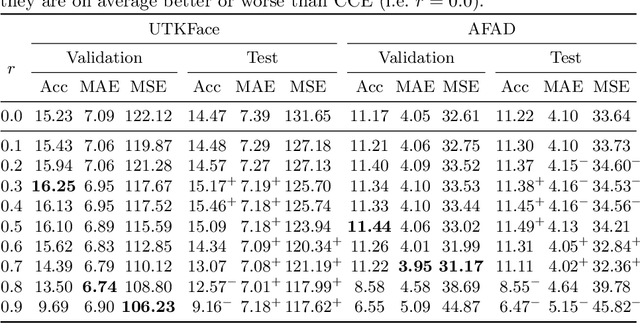
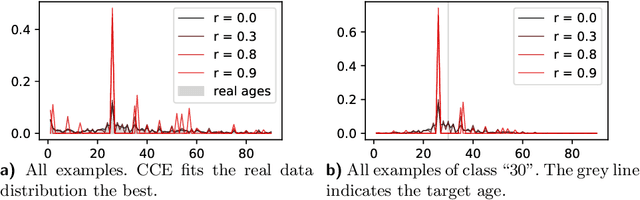
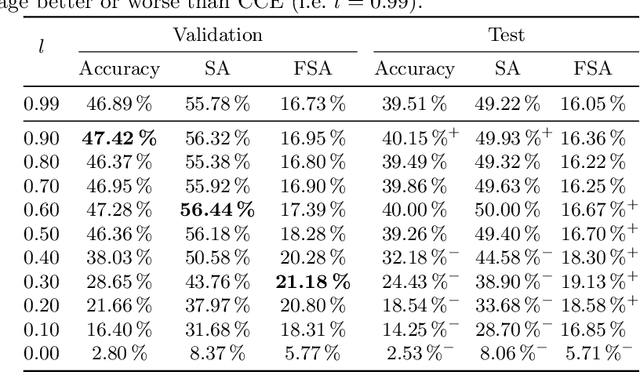
One common loss function in neural network classification tasks is Categorical Cross Entropy (CCE), which punishes all misclassifications equally. However, classes often have an inherent structure. For instance, classifying an image of a rose as "violet" is better than as "truck". We introduce SimLoss, a drop-in replacement for CCE that incorporates class similarities along with two techniques to construct such matrices from task-specific knowledge. We test SimLoss on Age Estimation and Image Classification and find that it brings significant improvements over CCE on several metrics. SimLoss therefore allows for explicit modeling of background knowledge by simply exchanging the loss function, while keeping the neural network architecture the same. Code and additional resources can be found at https://github.com/konstantinkobs/SimLoss.
Structural Similarity based Anatomical and Functional Brain Imaging Fusion
Aug 11, 2019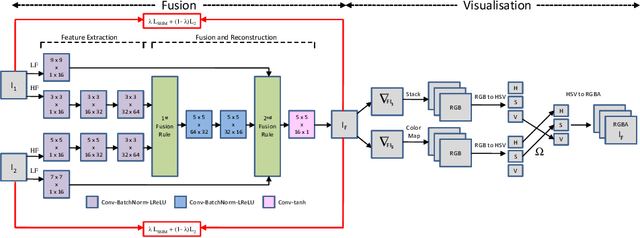
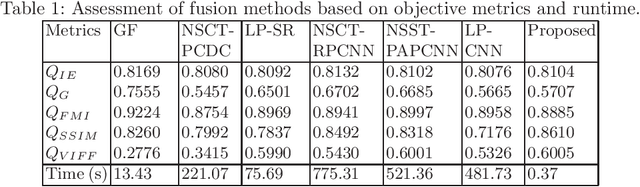
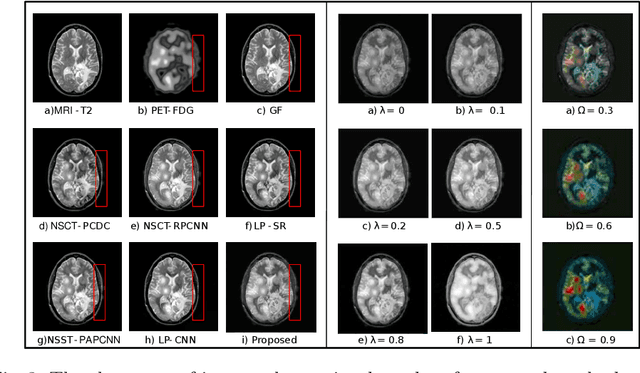
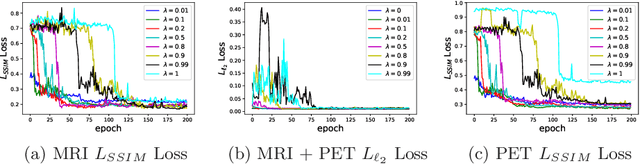
Multimodal medical image fusion helps in combining contrasting features from two or more input imaging modalities to represent fused information in a single image. One of the pivotal clinical applications of medical image fusion is the merging of anatomical and functional modalities for fast diagnosis of malignant tissues. In this paper, we present a novel end-to-end unsupervised learning-based Convolutional Neural Network (CNN) for fusing the high and low frequency components of MRI-PET grayscale image pairs, publicly available at ADNI, by exploiting Structural Similarity Index (SSIM) as the loss function during training. We then apply color coding for the visualization of the fused image by quantifying the contribution of each input image in terms of the partial derivatives of the fused image. We find that our fusion and visualization approach results in better visual perception of the fused image, while also comparing favorably to previous methods when applying various quantitative assessment metrics.
FaceScape: a Large-scale High Quality 3D Face Dataset and Detailed Riggable 3D Face Prediction
Apr 09, 2020
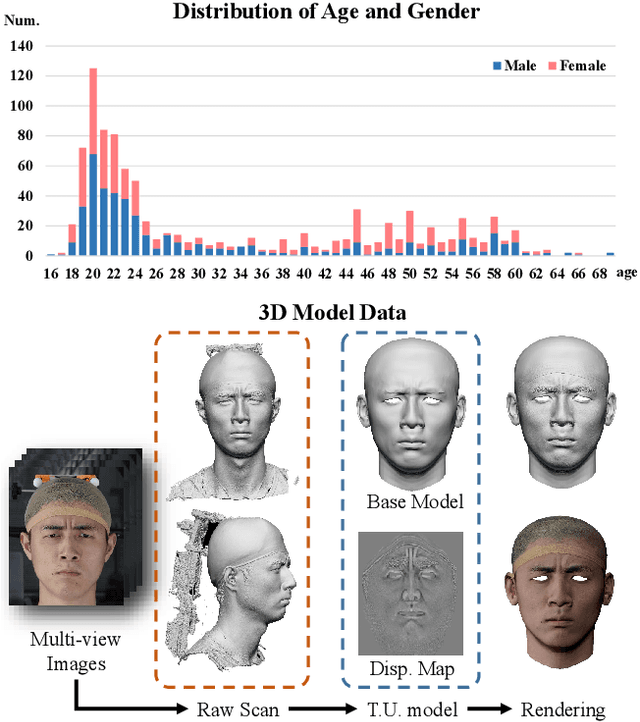
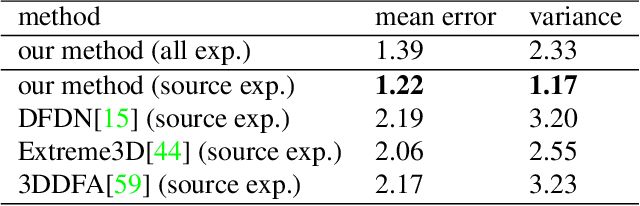
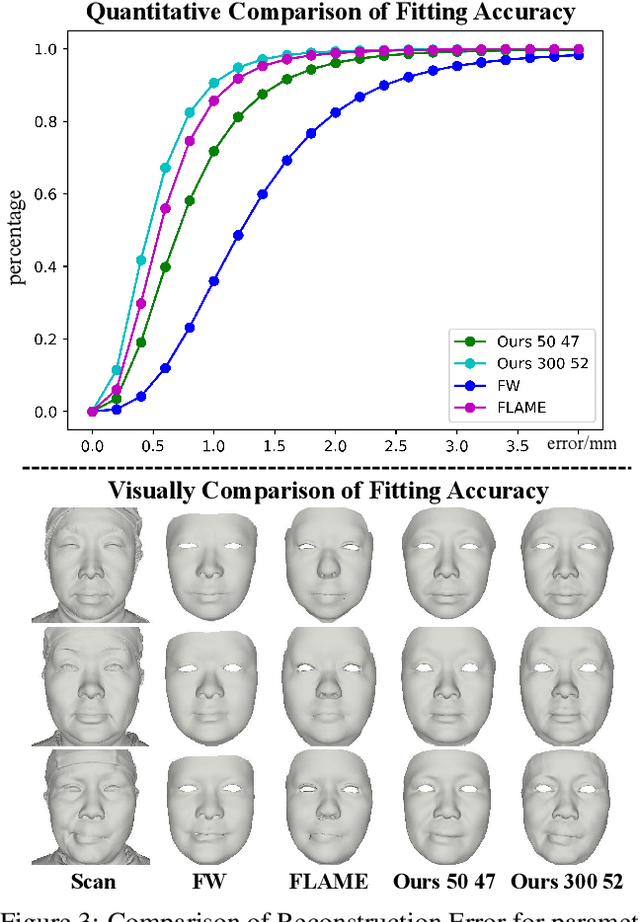
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and propose a novel algorithm that is able to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. The unprecedented dataset and code will be released to public for research purpose.
Bone Segmentation in Contrast Enhanced Whole-Body Computed Tomograph
Aug 12, 2020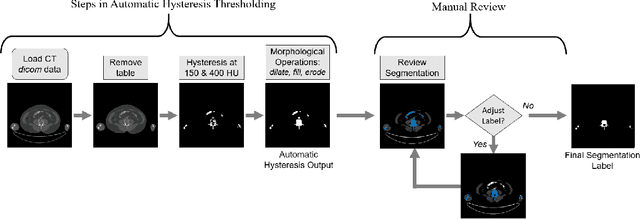
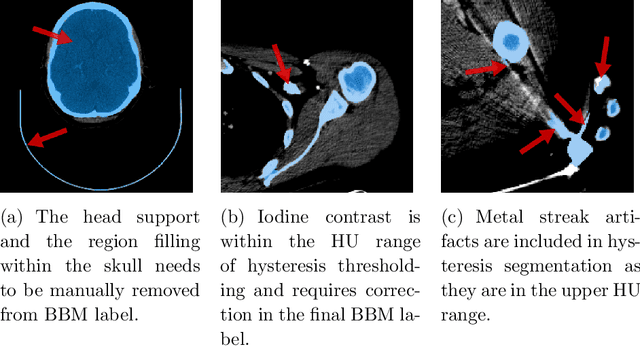
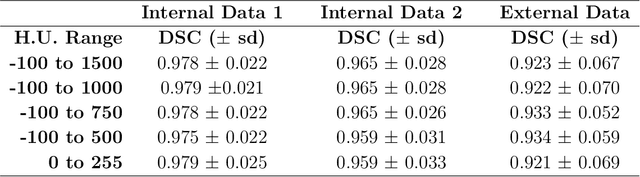
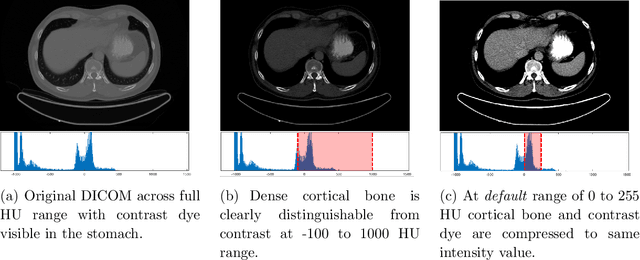
Segmentation of bone regions allows for enhanced diagnostics, disease characterisation and treatment monitoring in CT imaging. In contrast enhanced whole-body scans accurate automatic segmentation is particularly difficult as low dose whole body protocols reduce image quality and make contrast enhanced regions more difficult to separate when relying on differences in pixel intensities. This paper outlines a U-net architecture with novel preprocessing techniques, based on the windowing of training data and the modification of sigmoid activation threshold selection to successfully segment bone-bone marrow regions from low dose contrast enhanced whole-body CT scans. The proposed method achieved mean Dice coefficients of 0.979, 0.965, and 0.934 on two internal datasets and one external test dataset respectively. We have demonstrated that appropriate preprocessing is important for differentiating between bone and contrast dye, and that excellent results can be achieved with limited data.
Learning Condition Invariant Features for Retrieval-Based Localization from 1M Images
Aug 27, 2020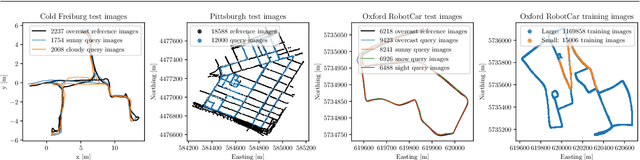

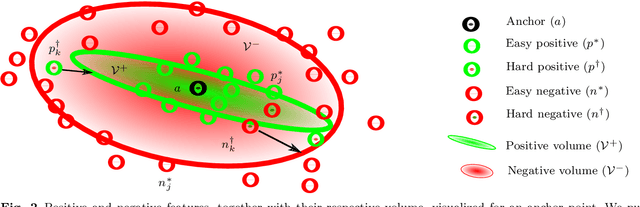
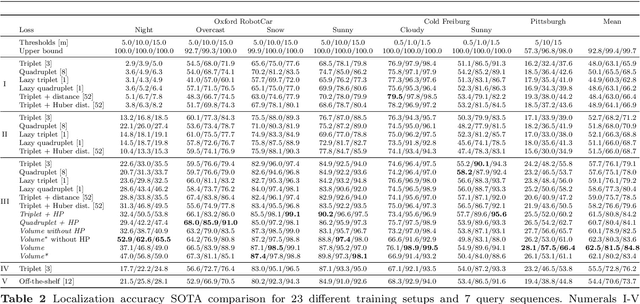
Image features for retrieval-based localization must be invariant to dynamic objects (e.g. cars) as well as seasonal and daytime changes. Such invariances are, up to some extent, learnable with existing methods using triplet-like losses, given a large number of diverse training images. However, due to the high algorithmic training complexity, there exists insufficient comparison between different loss functions on large datasets. In this paper, we train and evaluate several localization methods on three different benchmark datasets, including Oxford RobotCar with over one million images. This large scale evaluation yields valuable insights into the generalizability and performance of retrieval-based localization. Based on our findings, we develop a novel method for learning more accurate and better generalizing localization features. It consists of two main contributions: (i) a feature volume-based loss function, and (ii) hard positive and pairwise negative mining. On the challenging Oxford RobotCar night condition, our method outperforms the well-known triplet loss by 24.4% in localization accuracy within 5m.
Super-Resolving Commercial Satellite Imagery Using Realistic Training Data
Feb 26, 2020
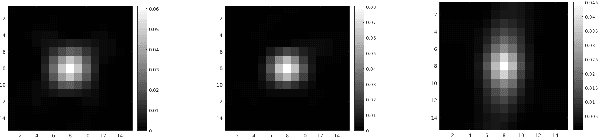

In machine learning based single image super-resolution, the degradation model is embedded in training data generation. However, most existing satellite image super-resolution methods use a simple down-sampling model with a fixed kernel to create training images. These methods work fine on synthetic data, but do not perform well on real satellite images. We propose a realistic training data generation model for commercial satellite imagery products, which includes not only the imaging process on satellites but also the post-process on the ground. We also propose a convolutional neural network optimized for satellite images. Experiments show that the proposed training data generation model is able to improve super-resolution performance on real satellite images.
Neural method for Explicit Mapping of Quasi-curvature Locally Linear Embedding in image retrieval
Mar 11, 2017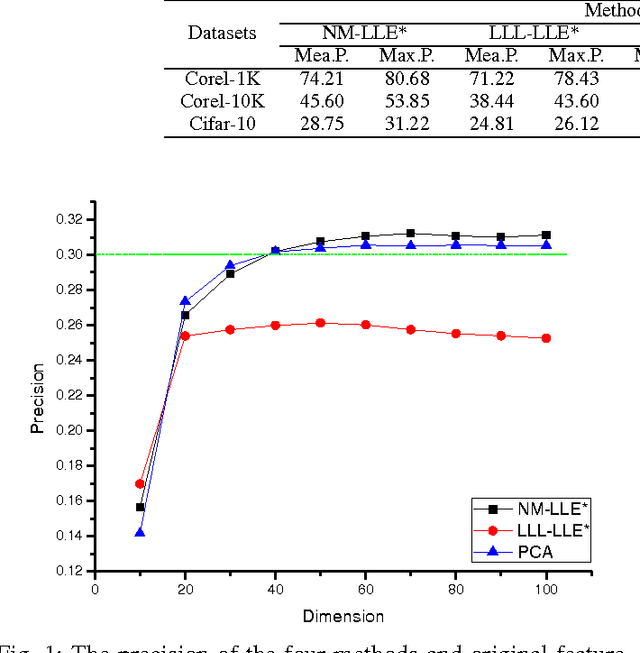
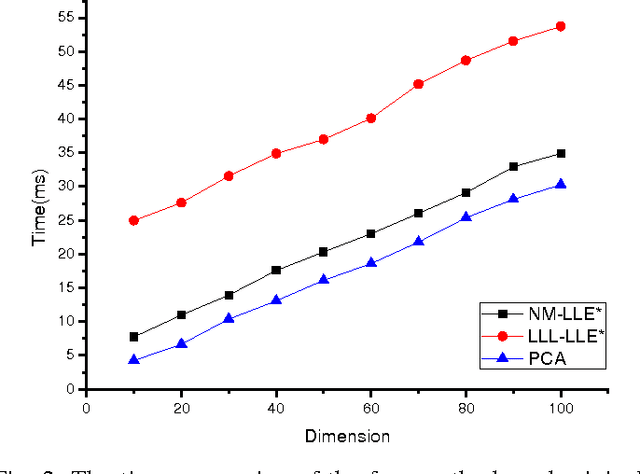
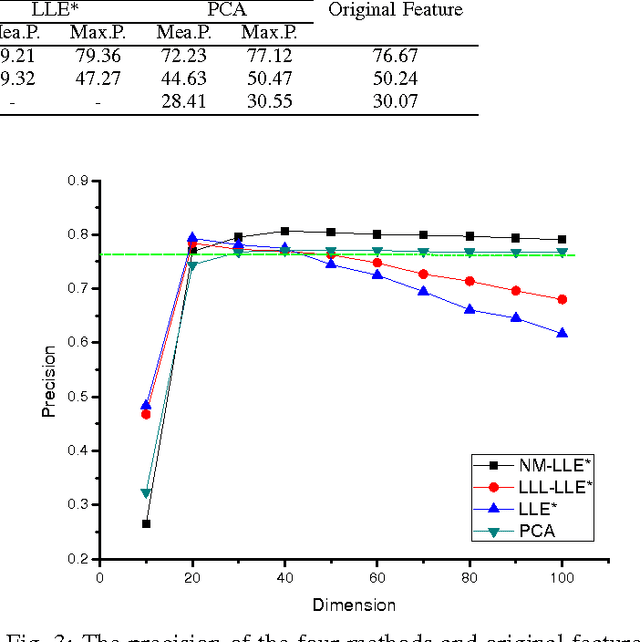
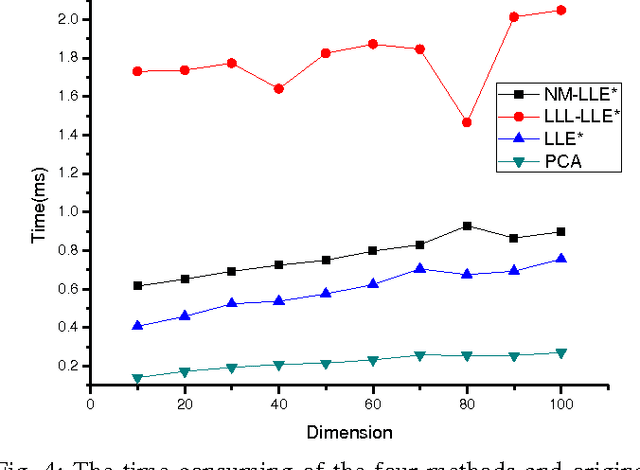
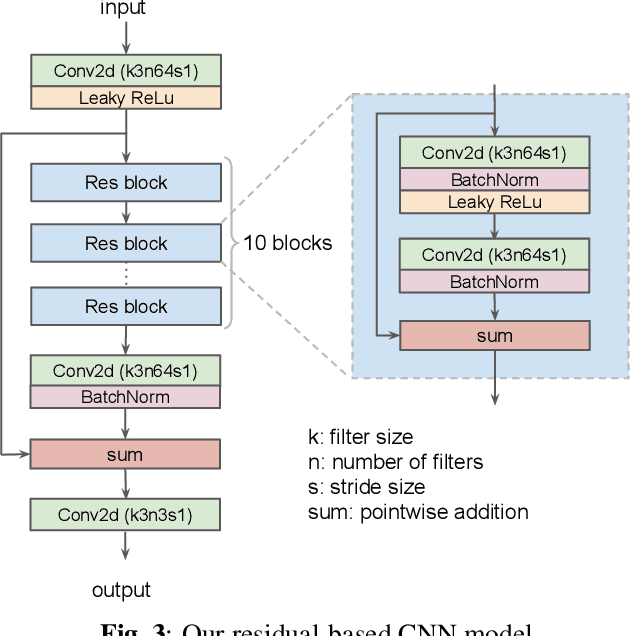
This paper proposed a new explicit nonlinear dimensionality reduction using neural networks for image retrieval tasks. We first proposed a Quasi-curvature Locally Linear Embedding (QLLE) for training set. QLLE guarantees the linear criterion in neighborhood of each sample. Then, a neural method (NM) is proposed for out-of-sample problem. Combining QLLE and NM, we provide a explicit nonlinear dimensionality reduction approach for efficient image retrieval. The experimental results in three benchmark datasets illustrate that our method can get better performance than other state-of-the-art out-of-sample methods.