 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Pictures Say More: Visual Intersection Network for Open Set Object Detection
Aug 26, 2024Open Set Object Detection has seen rapid development recently, but it continues to pose significant challenges. Language-based methods, grappling with the substantial modal disparity between textual and visual modalities, require extensive computational resources to bridge this gap. Although integrating visual prompts into these frameworks shows promise for enhancing performance, it always comes with constraints related to textual semantics. In contrast, viusal-only methods suffer from the low-quality fusion of multiple visual prompts. In response, we introduce a strong DETR-based model, Visual Intersection Network for Open Set Object Detection (VINO), which constructs a multi-image visual bank to preserve the semantic intersections of each category across all time steps. Our innovative multi-image visual updating mechanism learns to identify the semantic intersections from various visual prompts, enabling the flexible incorporation of new information and continuous optimization of feature representations. Our approach guarantees a more precise alignment between target category semantics and region semantics, while significantly reducing pre-training time and resource demands compared to language-based methods. Furthermore, the integration of a segmentation head illustrates the broad applicability of visual intersection in various visual tasks. VINO, which requires only 7 RTX4090 GPU days to complete one epoch on the Objects365v1 dataset, achieves competitive performance on par with vision-language models on benchmarks such as LVIS and ODinW35.
Underwater Variable Zoom: Depth-Guided Perception Network for Underwater Image Enhancement
May 02, 2024



Underwater scenes intrinsically involve degradation problems owing to heterogeneous ocean elements. Prevailing underwater image enhancement (UIE) methods stick to straightforward feature modeling to learn the mapping function, which leads to limited vision gain as it lacks more explicit physical cues (e.g., depth). In this work, we investigate injecting the depth prior into the deep UIE model for more precise scene enhancement capability. To this end, we present a novel depth-guided perception UIE framework, dubbed underwater variable zoom (UVZ). Specifically, UVZ resorts to a two-stage pipeline. First, a depth estimation network is designed to generate critical depth maps, combined with an auxiliary supervision network introduced to suppress estimation differences during training. Second, UVZ parses near-far scenarios by harnessing the predicted depth maps, enabling local and non-local perceiving in different regions. Extensive experiments on five benchmark datasets demonstrate that UVZ achieves superior visual gain and delivers promising quantitative metrics. Besides, UVZ is confirmed to exhibit good generalization in some visual tasks, especially in unusual lighting conditions. The code, models and results are available at: https://github.com/WindySprint/UVZ.
End-to-End Streaming Video Temporal Action Segmentation with Reinforce Learning
Sep 27, 2023Temporal Action Segmentation (TAS) from video is a kind of frame recognition task for long video with multiple action classes. As an video understanding task for long videos, current methods typically combine multi-modality action recognition models with temporal models to convert feature sequences to label sequences. This approach can only be applied to offline scenarios, which severely limits the TAS application. Therefore, this paper proposes an end-to-end Streaming Video Temporal Action Segmentation with Reinforce Learning (SVTAS-RL). The end-to-end SVTAS which regard TAS as an action segment clustering task can expand the application scenarios of TAS; and RL is used to alleviate the problem of inconsistent optimization objective and direction. Through extensive experiments, the SVTAS-RL model achieves a competitive performance to the state-of-the-art model of TAS on multiple datasets, and shows greater advantages on the ultra-long video dataset EGTEA. This indicates that our method can replace all current TAS models end-to-end and SVTAS-RL is more suitable for long video TAS. Code is availabel at https://github.com/Thinksky5124/SVTAS.
Spatial Temporal Graph Attention Network for Skeleton-Based Action Recognition
Aug 18, 2022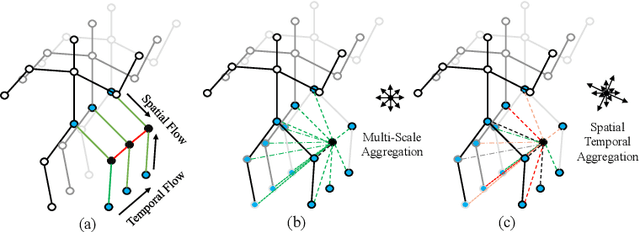
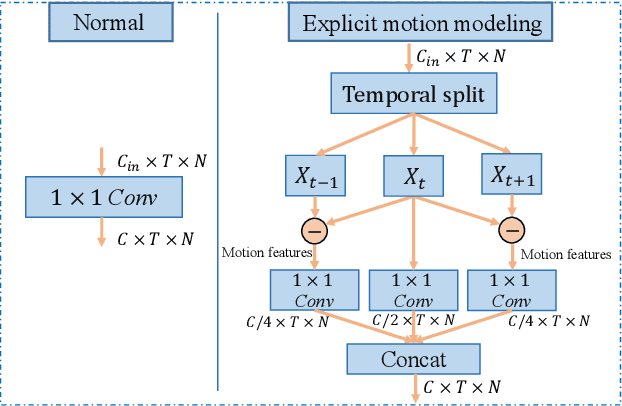
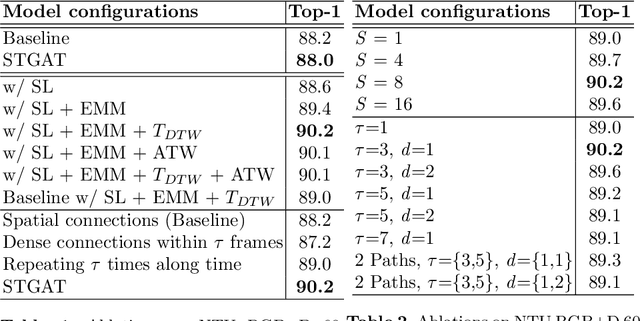
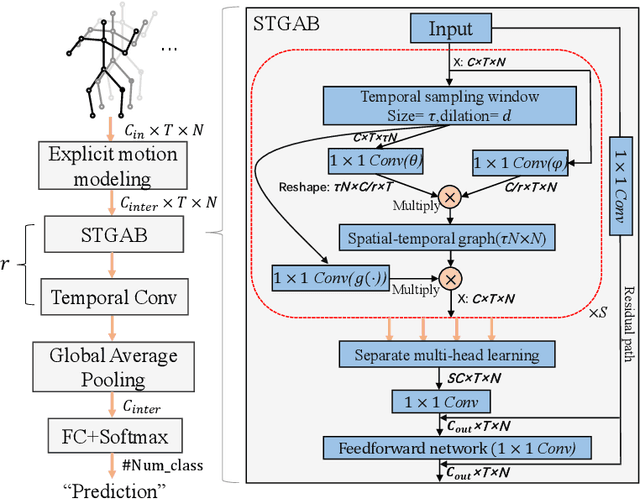
It's common for current methods in skeleton-based action recognition to mainly consider capturing long-term temporal dependencies as skeleton sequences are typically long (>128 frames), which forms a challenging problem for previous approaches. In such conditions, short-term dependencies are few formally considered, which are critical for classifying similar actions. Most current approaches are consisted of interleaving spatial-only modules and temporal-only modules, where direct information flow among joints in adjacent frames are hindered, thus inferior to capture short-term motion and distinguish similar action pairs. To handle this limitation, we propose a general framework, coined as STGAT, to model cross-spacetime information flow. It equips the spatial-only modules with spatial-temporal modeling for regional perception. While STGAT is theoretically effective for spatial-temporal modeling, we propose three simple modules to reduce local spatial-temporal feature redundancy and further release the potential of STGAT, which (1) narrow the scope of self-attention mechanism, (2) dynamically weight joints along temporal dimension, and (3) separate subtle motion from static features, respectively. As a robust feature extractor, STGAT generalizes better upon classifying similar actions than previous methods, witnessed by both qualitative and quantitative results. STGAT achieves state-of-the-art performance on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400. Code is released.
Self-Supervised Deep Graph Embedding with High-Order Information Fusion for Community Discovery
Feb 08, 2021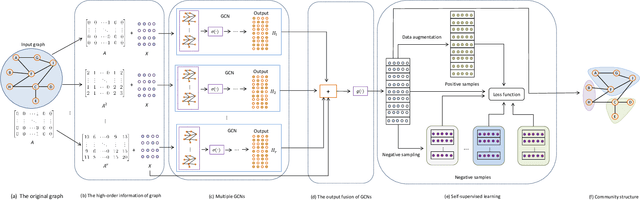
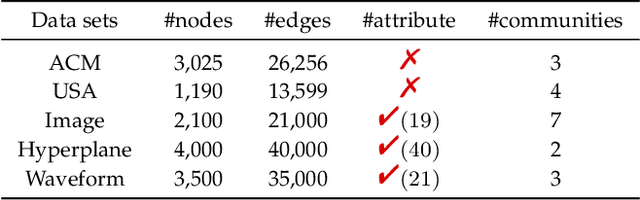

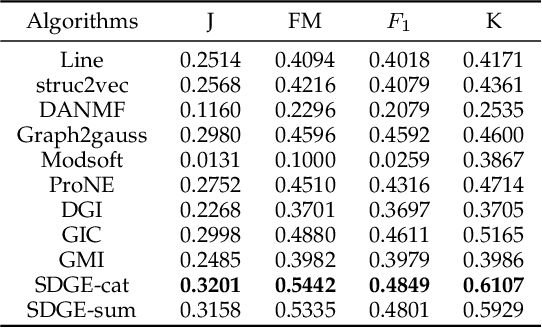
Deep graph embedding is an important approach for community discovery. Deep graph neural network with self-supervised mechanism can obtain the low-dimensional embedding vectors of nodes from unlabeled and unstructured graph data. The high-order information of graph can provide more abundant structure information for the representation learning of nodes. However, most self-supervised graph neural networks only use adjacency matrix as the input topology information of graph and cannot obtain too high-order information since the number of layers of graph neural network is fairly limited. If there are too many layers, the phenomenon of over smoothing will appear. Therefore how to obtain and fuse high-order information of graph by a shallow graph neural network is an important problem. In this paper, a deep graph embedding algorithm with self-supervised mechanism for community discovery is proposed. The proposed algorithm uses self-supervised mechanism and different high-order information of graph to train multiple deep graph convolution neural networks. The outputs of multiple graph convolution neural networks are fused to extract the representations of nodes which include the attribute and structure information of a graph. In addition, data augmentation and negative sampling are introduced into the training process to facilitate the improvement of embedding result. The proposed algorithm and the comparison algorithms are conducted on the five experimental data sets. The experimental results show that the proposed algorithm outperforms the comparison algorithms on the most experimental data sets. The experimental results demonstrate that the proposed algorithm is an effective algorithm for community discovery.
Angular Embedding: A New Angular Robust Principal Component Analysis
Nov 22, 2020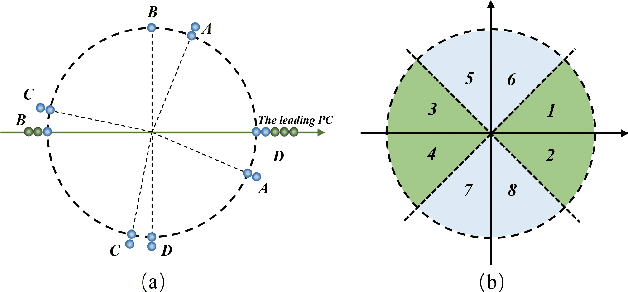
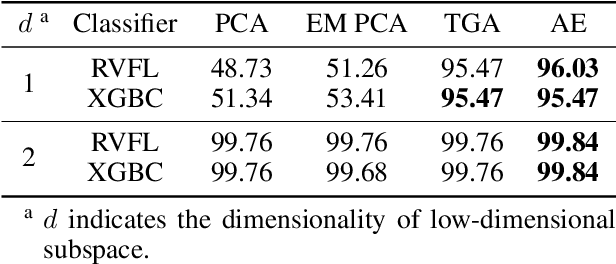
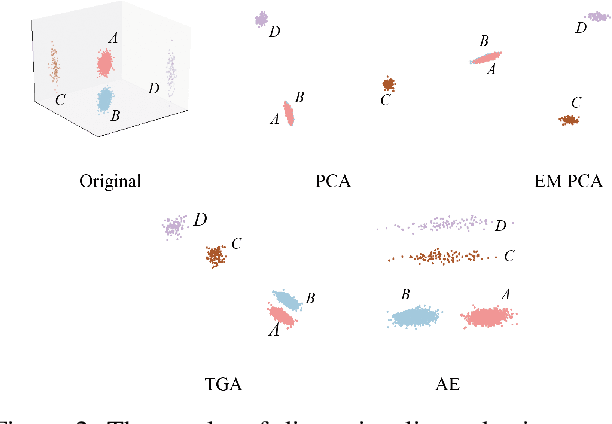
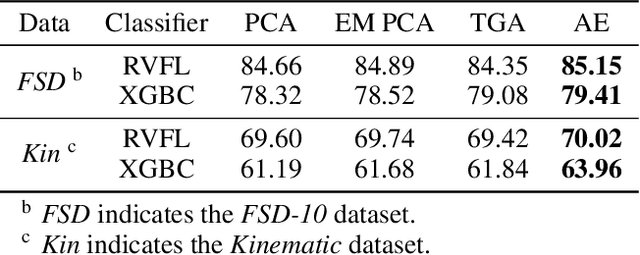
As a widely used method in machine learning, principal component analysis (PCA) shows excellent properties for dimensionality reduction. It is a serious problem that PCA is sensitive to outliers, which has been improved by numerous Robust PCA (RPCA) versions. However, the existing state-of-the-art RPCA approaches cannot easily remove or tolerate outliers by a non-iterative manner. To tackle this issue, this paper proposes Angular Embedding (AE) to formulate a straightforward RPCA approach based on angular density, which is improved for large scale or high-dimensional data. Furthermore, a trimmed AE (TAE) is introduced to deal with data with large scale outliers. Extensive experiments on both synthetic and real-world datasets with vector-level or pixel-level outliers demonstrate that the proposed AE/TAE outperforms the state-of-the-art RPCA based methods.
Local Neighbor Propagation Embedding
Jun 29, 2020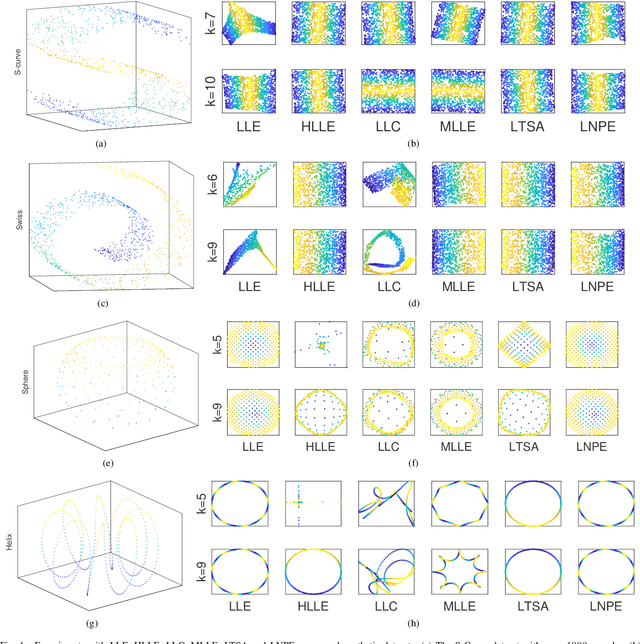
Manifold Learning occupies a vital role in the field of nonlinear dimensionality reduction and its ideas also serve for other relevant methods. Graph-based methods such as Graph Convolutional Networks (GCN) show ideas in common with manifold learning, although they belong to different fields. Inspired by GCN, we introduce neighbor propagation into LLE and propose Local Neighbor Propagation Embedding (LNPE). With linear computational complexity increase compared with LLE, LNPE enhances the local connections and interactions between neighborhoods by extending $1$-hop neighbors into $n$-hop neighbors. The experimental results show that LNPE could obtain more faithful and robust embeddings with better topological and geometrical properties.
Hierarchic Neighbors Embedding
Sep 16, 2019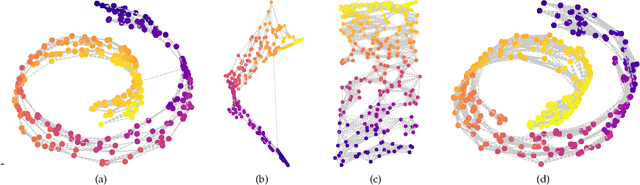
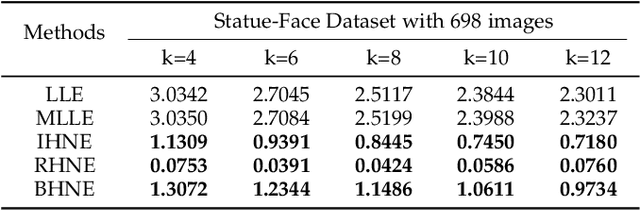
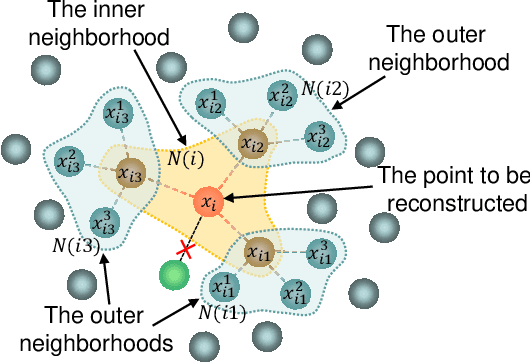
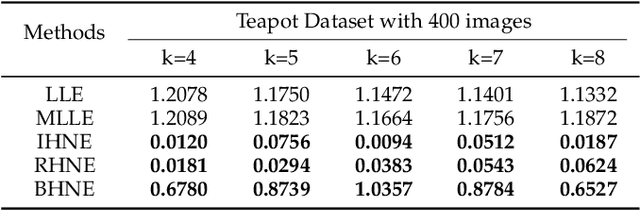
Manifold learning now plays a very important role in machine learning and many relevant applications. Although its superior performance in dealing with nonlinear data distribution, data sparsity is always a thorny knot. There are few researches to well handle it in manifold learning. In this paper, we propose Hierarchic Neighbors Embedding (HNE), which enhance local connection by the hierarchic combination of neighbors. After further analyzing topological connection and reconstruction performance, three different versions of HNE are given. The experimental results show that our methods work well on both synthetic data and high-dimensional real-world tasks. HNE develops the outstanding advantages in dealing with general data. Furthermore, comparing with other popular manifold learning methods, the performance on sparse samples and weak-connected manifolds is better for HNE.
A fast online cascaded regression algorithm for face alignment
May 10, 2019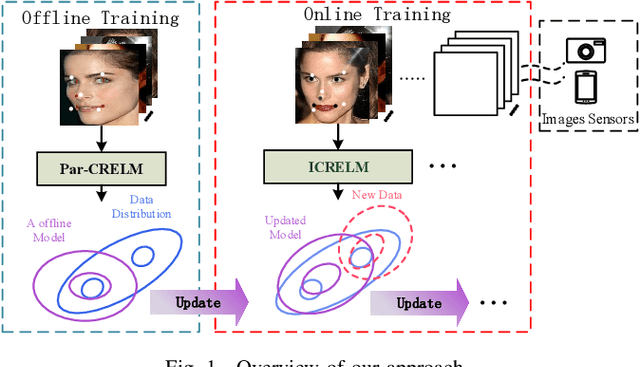
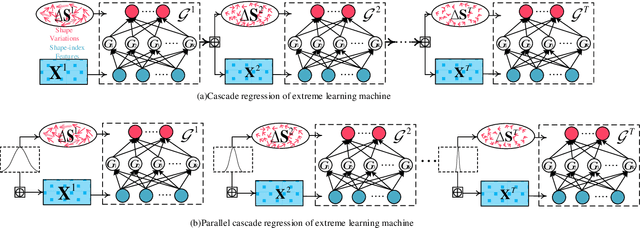
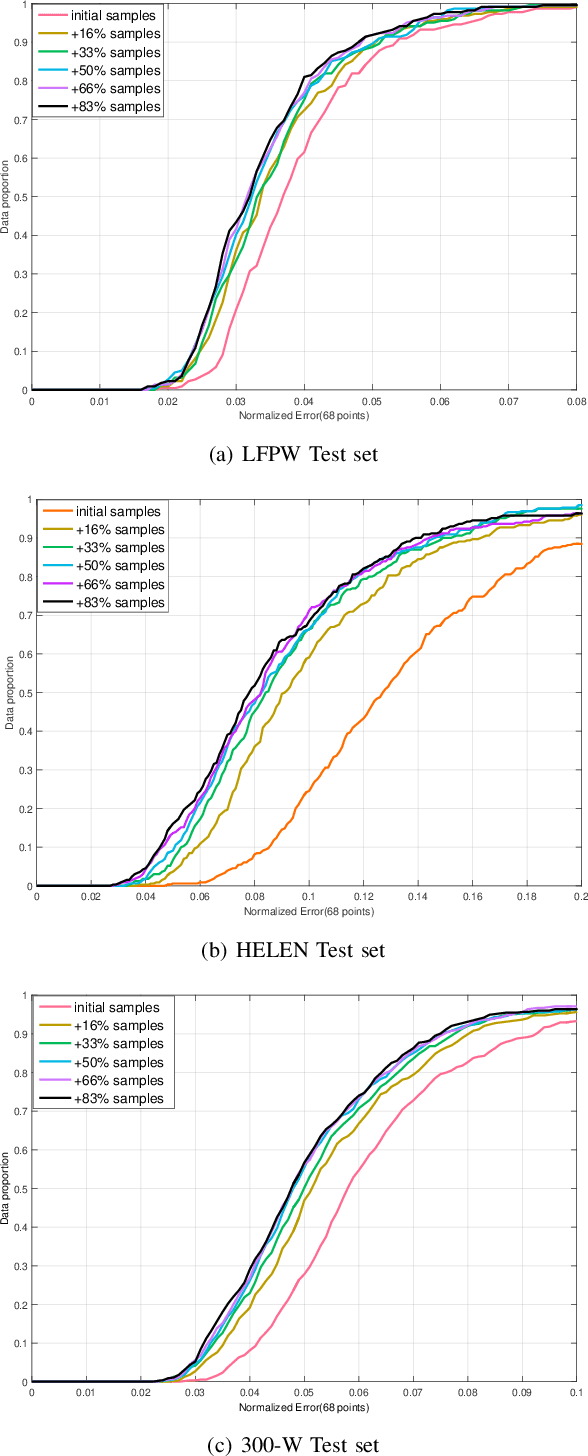
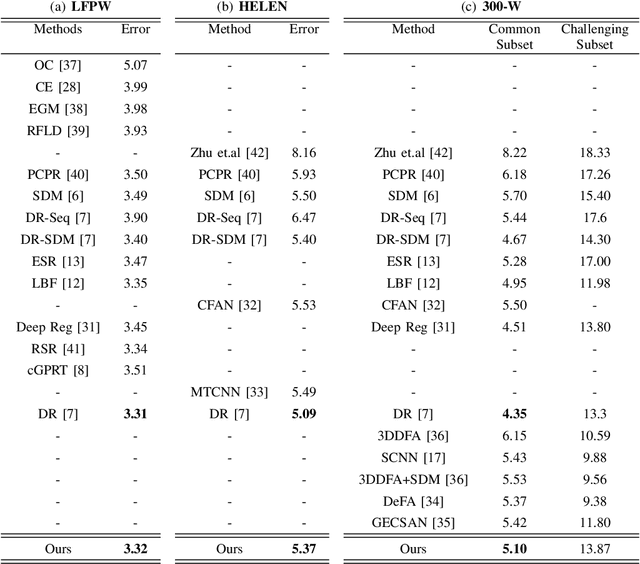
Traditional face alignment based on machine learning usually tracks the localizations of facial landmarks employing a static model trained offline where all of the training data is available in advance. When new training samples arrive, the static model must be retrained from scratch, which is excessively time-consuming and memory-consuming. In many real-time applications, the training data is obtained one by one or batch by batch. It results in that the static model limits its performance on sequential images with extensive variations. Therefore, the most critical and challenging aspect in this field is dynamically updating the tracker's models to enhance predictive and generalization capabilities continuously. In order to address this question, we develop a fast and accurate online learning algorithm for face alignment. Particularly, we incorporate on-line sequential extreme learning machine into a parallel cascaded regression framework, coined incremental cascade regression(ICR). To the best of our knowledge, this is the first incremental cascaded framework with the non-linear regressor. One main advantage of ICR is that the tracker model can be fast updated in an incremental way without the entire retraining process when a new input is incoming. Experimental results demonstrate that the proposed ICR is more accurate and efficient on still or sequential images compared with the recent state-of-the-art cascade approaches. Furthermore, the incremental learning proposed in this paper can update the trained model in real time.
Bottom-up Broadcast Neural Network For Music Genre Classification
Jan 24, 2019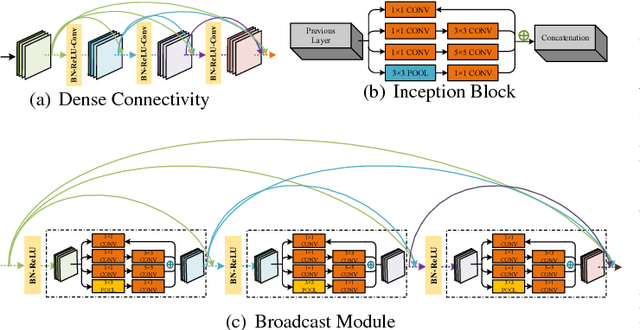

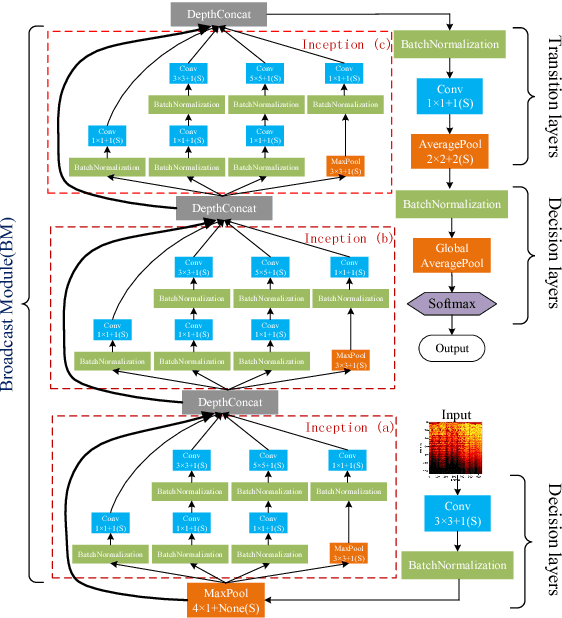
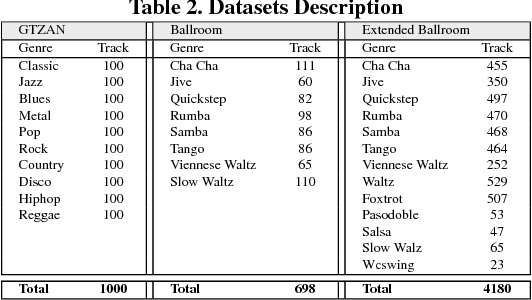
Music genre recognition based on visual representation has been successfully explored over the last years. Recently, there has been increasing interest in attempting convolutional neural networks (CNNs) to achieve the task. However, most of existing methods employ the mature CNN structures proposed in image recognition without any modification, which results in the learning features that are not adequate for music genre classification. Faced with the challenge of this issue, we fully exploit the low-level information from spectrograms of audios and develop a novel CNN architecture in this paper. The proposed CNN architecture takes the long contextual information into considerations, which transfers more suitable information for the decision-making layer. Various experiments on several benchmark datasets, including GTZAN, Ballroom, and Extended Ballroom, have verified the excellent performances of the proposed neural network. Codes and model will be available at "ttps://github.com/CaifengLiu/music-genre-classification".