 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchröMind: Mitigating Hallucinations in Multimodal Large Language Models via Solving the Schrödinger Bridge Problem
Feb 10, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have achieved significant success across various domains. However, their use in high-stakes fields like healthcare remains limited due to persistent hallucinations, where generated text contradicts or ignores visual input. We contend that MLLMs can comprehend images but struggle to produce accurate token sequences. Minor perturbations can shift attention from truthful to untruthful states, and the autoregressive nature of text generation often prevents error correction. To address this, we propose SchröMind-a novel framework reducing hallucinations via solving the Schrödinger bridge problem. It establishes a token-level mapping between hallucinatory and truthful activations with minimal transport cost through lightweight training, while preserving the model's original capabilities. Extensive experiments on the POPE and MME benchmarks demonstrate the superiority of Schrödinger, which achieves state-of-the-art performance while introducing only minimal computational overhead.
Attention to details, logits to truth: visual-aware attention and logits enhancement to mitigate hallucinations in LVLMs
Feb 10, 2026Existing Large Vision-Language Models (LVLMs) exhibit insufficient visual attention, leading to hallucinations. To alleviate this problem, some previous studies adjust and amplify visual attention. These methods present a limitation that boosting attention for all visual tokens inevitably increases attention to task irrelevant tokens. To tackle this challenge, we propose a training free attentional intervention algorithm to enhance the attention of task-relevant tokens based on the argument that task-relevant tokens generally demonstrate high visual-textual similarities. Specifically, the vision-text cross-attention submatrices, which represent visual-textual correlations, are extracted to construct the reweighting matrices to reallocate attention. Besides, to enhance the contribution of visual tokens, we inject visual attention values into the beam search decoding to identify solutions with higher visual attention. Extensive experiments demonstrate that this method significantly reduces hallucinations across mainstream LVLMs, while preserving the accuracy and coherence of generated content.
Scalpel: Fine-Grained Alignment of Attention Activation Manifolds via Mixture Gaussian Bridges to Mitigate Multimodal Hallucination
Feb 10, 2026Rapid progress in large vision-language models (LVLMs) has achieved unprecedented performance in vision-language tasks. However, due to the strong prior of large language models (LLMs) and misaligned attention across modalities, LVLMs often generate outputs inconsistent with visual content - termed hallucination. To address this, we propose \textbf{Scalpel}, a method that reduces hallucination by refining attention activation distributions toward more credible regions. Scalpel predicts trusted attention directions for each head in Transformer layers during inference and adjusts activations accordingly. It employs a Gaussian mixture model to capture multi-peak distributions of attention in trust and hallucination manifolds, and uses entropic optimal transport (equivalent to Schrödinger bridge problem) to map Gaussian components precisely. During mitigation, Scalpel dynamically adjusts intervention strength and direction based on component membership and mapping relationships between hallucination and trust activations. Extensive experiments across multiple datasets and benchmarks demonstrate that Scalpel effectively mitigates hallucinations, outperforming previous methods and achieving state-of-the-art performance. Moreover, Scalpel is model- and data-agnostic, requiring no additional computation, only a single decoding step.
Human Identification at a Distance: Challenges, Methods and Results on the Competition HID 2025
Feb 07, 2026Human identification at a distance (HID) is challenging because traditional biometric modalities such as face and fingerprints are often difficult to acquire in real-world scenarios. Gait recognition provides a practical alternative, as it can be captured reliably at a distance. To promote progress in gait recognition and provide a fair evaluation platform, the International Competition on Human Identification at a Distance (HID) has been organized annually since 2020. Since 2023, the competition has adopted the challenging SUSTech-Competition dataset, which features substantial variations in clothing, carried objects, and view angles. No dedicated training data are provided, requiring participants to train their models using external datasets. Each year, the competition applies a different random seed to generate distinct evaluation splits, which reduces the risk of overfitting and supports a fair assessment of cross-domain generalization. While HID 2023 and HID 2024 already used this dataset, HID 2025 explicitly examined whether algorithmic advances could surpass the accuracy limits observed previously. Despite the heightened difficulty, participants achieved further improvements, and the best-performing method reached 94.2% accuracy, setting a new benchmark on this dataset. We also analyze key technical trends and outline potential directions for future research in gait recognition.
RTAT: A Robust Two-stage Association Tracker for Multi-Object Tracking
Aug 14, 2024



Data association is an essential part in the tracking-by-detection based Multi-Object Tracking (MOT). Most trackers focus on how to design a better data association strategy to improve the tracking performance. The rule-based handcrafted association methods are simple and highly efficient but lack generalization capability to deal with complex scenes. While the learnt association methods can learn high-order contextual information to deal with various complex scenes, but they have the limitations of higher complexity and cost. To address these limitations, we propose a Robust Two-stage Association Tracker, named RTAT. The first-stage association is performed between tracklets and detections to generate tracklets with high purity, and the second-stage association is performed between tracklets to form complete trajectories. For the first-stage association, we use a simple data association strategy to generate tracklets with high purity by setting a low threshold for the matching cost in the assignment process. We conduct the tracklet association in the second-stage based on the framework of message-passing GNN. Our method models the tracklet association as a series of edge classification problem in hierarchical graphs, which can recursively merge short tracklets into longer ones. Our tracker RTAT ranks first on the test set of MOT17 and MOT20 benchmarks in most of the main MOT metrics: HOTA, IDF1, and AssA. We achieve 67.2 HOTA, 84.7 IDF1, and 69.7 AssA on MOT17, and 66.2 HOTA, 82.5 IDF1, and 68.1 AssA on MOT20.
Generative Modelling with High-Order Langevin Dynamics
Apr 19, 2024Diffusion generative modelling (DGM) based on stochastic differential equations (SDEs) with score matching has achieved unprecedented results in data generation. In this paper, we propose a novel fast high-quality generative modelling method based on high-order Langevin dynamics (HOLD) with score matching. This motive is proved by third-order Langevin dynamics. By augmenting the previous SDEs, e.g. variance exploding or variance preserving SDEs for single-data variable processes, HOLD can simultaneously model position, velocity, and acceleration, thereby improving the quality and speed of the data generation at the same time. HOLD is composed of one Ornstein-Uhlenbeck process and two Hamiltonians, which reduce the mixing time by two orders of magnitude. Empirical experiments for unconditional image generation on the public data set CIFAR-10 and CelebA-HQ show that the effect is significant in both Frechet inception distance (FID) and negative log-likelihood, and achieves the state-of-the-art FID of 1.85 on CIFAR-10.
LoRRaL: Facial Action Unit Detection Based on Local Region Relation Learning
Sep 23, 2020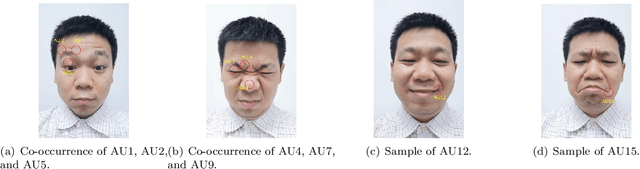
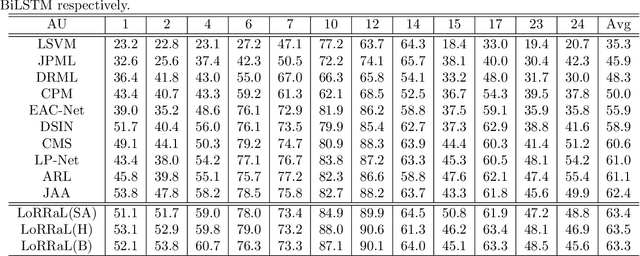
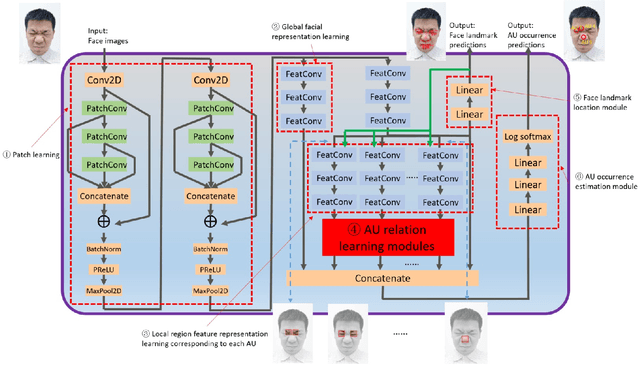
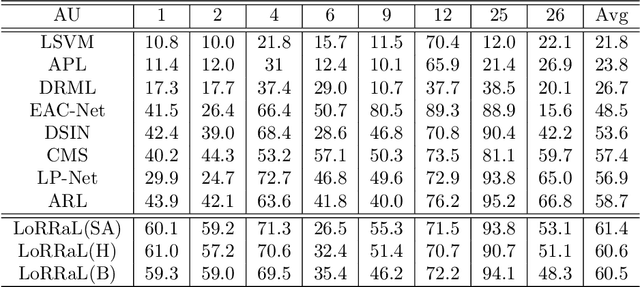
End-to-end convolution representation learning has been proved to be very effective in facial action unit (AU) detection. Considering the co-occurrence and mutual exclusion between facial AUs, in this paper, we propose convolution neural networks with Local Region Relation Learning (LoRRaL), which can combine latent relationships among AUs for an end-to-end approach to facial AU occurrence detection. LoRRaL consists of 1) use bi-directional long short-term memory (BiLSTM) to dynamically and sequentially encode local AU feature maps, 2) use self-attention mechanism to dynamically compute correspondences from local facial regions and to re-aggregate AU feature maps considering AU co-occurrences and mutual exclusions, 3) use a continuous-state modern Hopfield network to encode and map local facial features to more discriminative AU feature maps, that all these networks take the facial image as input and map it to AU occurrences. Our experiments on the challenging BP4D and DISFA Benchmarks without any external data or pre-trained models results in F1-scores of 63.5% and 61.4% respectively, which shows our proposed networks can lead to performance improvement on the AU detection task.
Learning to Find Correlated Features by Maximizing Information Flow in Convolutional Neural Networks
Jun 30, 2019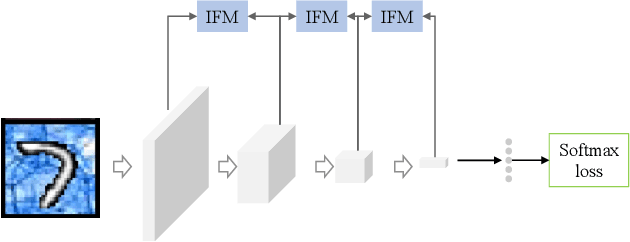

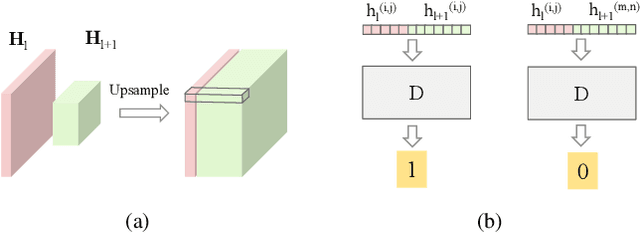

Training convolutional neural networks for image classification tasks usually causes information loss. Although most of the time the information lost is redundant with respect to the target task, there are still cases where discriminative information is also discarded. For example, if the samples that belong to the same category have multiple correlated features, the model may only learn a subset of the features and ignore the rest. This may not be a problem unless the classification in the test set highly depends on the ignored features. We argue that the discard of the correlated discriminative information is partially caused by the fact that the minimization of the classification loss doesn't ensure to learn the overall discriminative information but only the most discriminative information. To address this problem, we propose an information flow maximization (IFM) loss as a regularization term to find the discriminative correlated features. With less information loss the classifier can make predictions based on more informative features. We validate our method on the shiftedMNIST dataset and show the effectiveness of IFM loss in learning representative and discriminative features.
Learning to generate filters for convolutional neural networks
Dec 05, 2018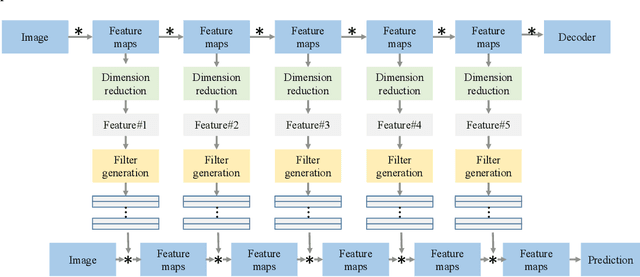

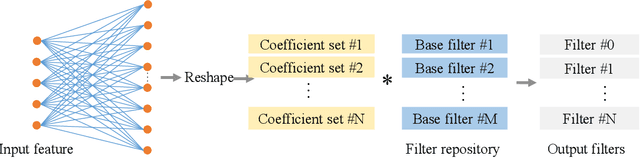

Conventionally, convolutional neural networks (CNNs) process different images with the same set of filters. However, the variations in images pose a challenge to this fashion. In this paper, we propose to generate sample-specific filters for convolutional layers in the forward pass. Since the filters are generated on-the-fly, the model becomes more flexible and can better fit the training data compared to traditional CNNs. In order to obtain sample-specific features, we extract the intermediate feature maps from an autoencoder. As filters are usually high dimensional, we propose to learn a set of coefficients instead of a set of filters. These coefficients are used to linearly combine the base filters from a filter repository to generate the final filters for a CNN. The proposed method is evaluated on MNIST, MTFL and CIFAR10 datasets. Experiment results demonstrate that the classification accuracy of the baseline model can be improved by using the proposed filter generation method.
Tackling Early Sparse Gradients in Softmax Activation Using Leaky Squared Euclidean Distance
Nov 27, 2018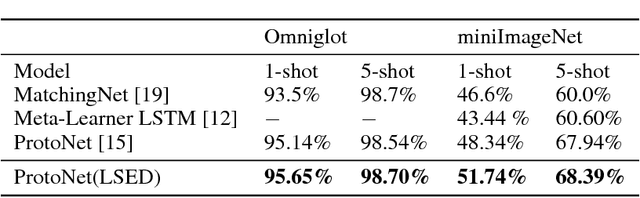
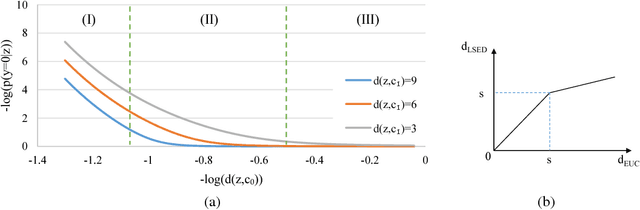

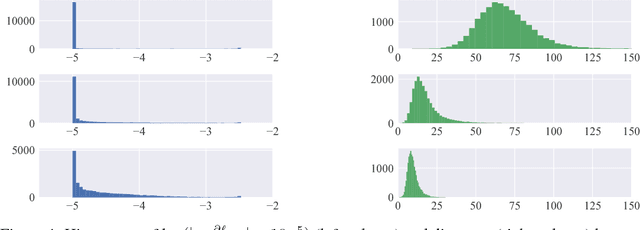
Softmax activation is commonly used to output the probability distribution over categories based on certain distance metric. In scenarios like one-shot learning, the distance metric is often chosen to be squared Euclidean distance between the query sample and the category prototype. This practice works well in most time. However, we find that choosing squared Euclidean distance may cause distance explosion leading gradients to be extremely sparse in the early stage of back propagation. We term this phenomena as the early sparse gradients problem. Though it doesn't deteriorate the convergence of the model, it may set up a barrier to further model improvement. To tackle this problem, we propose to use leaky squared Euclidean distance to impose a restriction on distances. In this way, we can avoid distance explosion and increase the magnitude of gradients. Extensive experiments are conducted on Omniglot and miniImageNet datasets. We show that using leaky squared Euclidean distance can improve one-shot classification accuracy on both datasets.