 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly-Supervised Segmentation for Disease Localization in Chest X-Ray Images
Jul 01, 2020
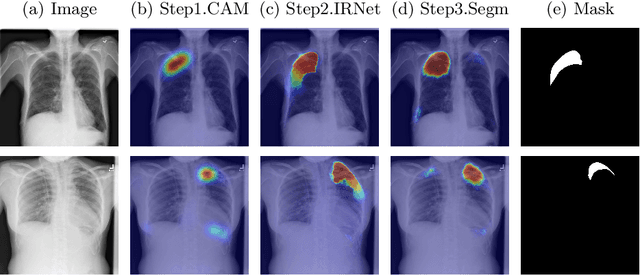

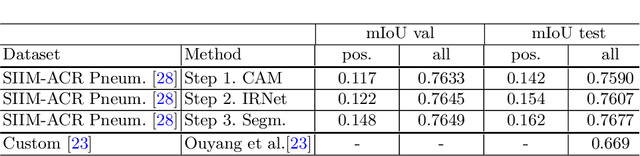
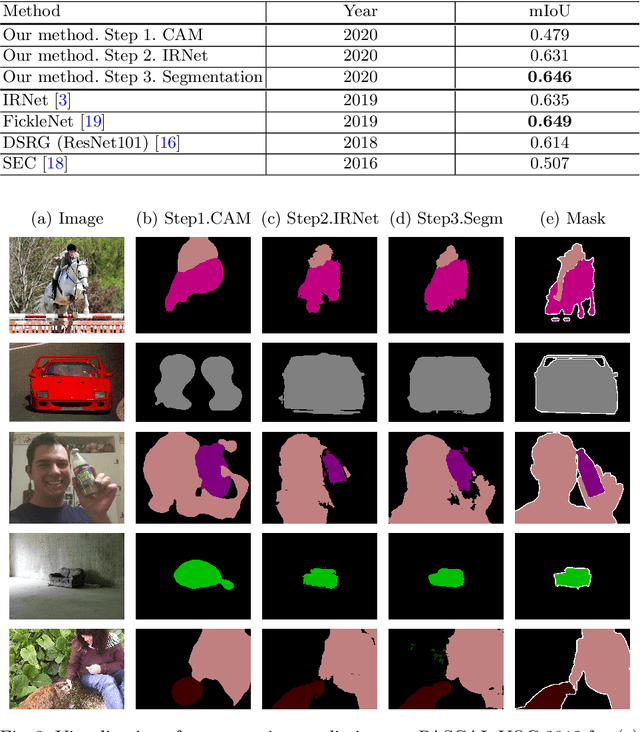
Deep Convolutional Neural Networks have proven effective in solving the task of semantic segmentation. However, their efficiency heavily relies on the pixel-level annotations that are expensive to get and often require domain expertise, especially in medical imaging. Weakly supervised semantic segmentation helps to overcome these issues and also provides explainable deep learning models. In this paper, we propose a novel approach to the semantic segmentation of medical chest X-ray images with only image-level class labels as supervision. We improve the disease localization accuracy by combining three approaches as consecutive steps. First, we generate pseudo segmentation labels of abnormal regions in the training images through a supervised classification model enhanced with a regularization procedure. The obtained activation maps are then post-processed and propagated into a second classification model-Inter-pixel Relation Network, which improves the boundaries between different object classes. Finally, the resulting pseudo-labels are used to train a proposed fully supervised segmentation model. We analyze the robustness of the presented method and test its performance on two distinct datasets: PASCAL VOC 2012 and SIIM-ACR Pneumothorax. We achieve significant results in the segmentation on both datasets using only image-level annotations. We show that this approach is applicable to chest X-rays for detecting an anomalous volume of air in the pleural space between the lung and the chest wall. Our code has been made publicly available.
Automatic phantom test pattern classification through transfer learning with deep neural networks
Jan 22, 2020
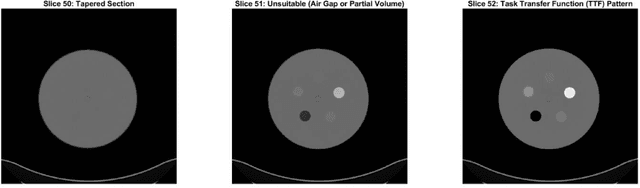

Imaging phantoms are test patterns used to measure image quality in computer tomography (CT) systems. A new phantom platform (Mercury Phantom, Gammex) provides test patterns for estimating the task transfer function (TTF) or noise power spectrum (NPF) and simulates different patient sizes. Determining which image slices are suitable for analysis currently requires manual annotation of these patterns by an expert, as subtle defects may make an image unsuitable for measurement. We propose a method of automatically classifying these test patterns in a series of phantom images using deep learning techniques. By adapting a convolutional neural network based on the VGG19 architecture with weights trained on ImageNet, we use transfer learning to produce a classifier for this domain. The classifier is trained and evaluated with over 3,500 phantom images acquired at a university medical center. Input channels for color images are successfully adapted to convey contextual information for phantom images. A series of ablation studies are employed to verify design aspects of the classifier and evaluate its performance under varying training conditions. Our solution makes extensive use of image augmentation to produce a classifier that accurately classifies typical phantom images with 98% accuracy, while maintaining as much as 86% accuracy when the phantom is improperly imaged.
Understanding and Correcting Low-quality Retinal Fundus Images for Clinical Analysis
May 12, 2020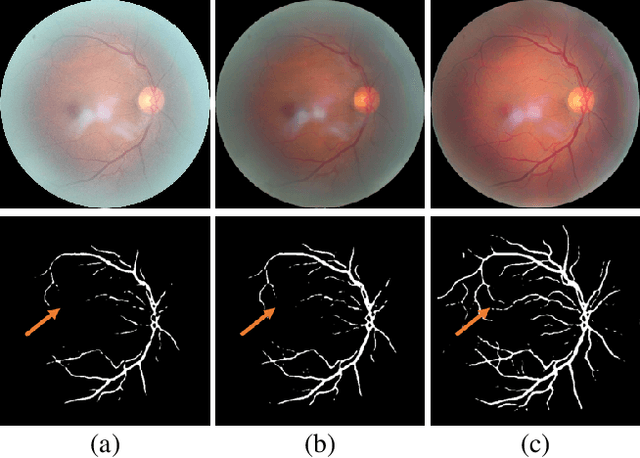
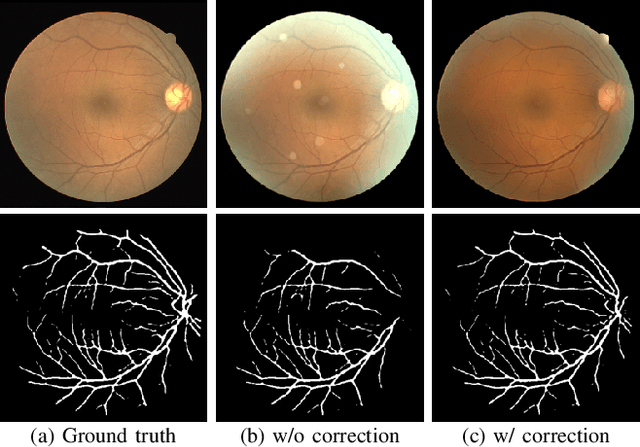
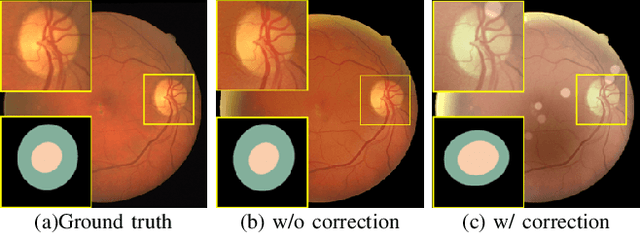
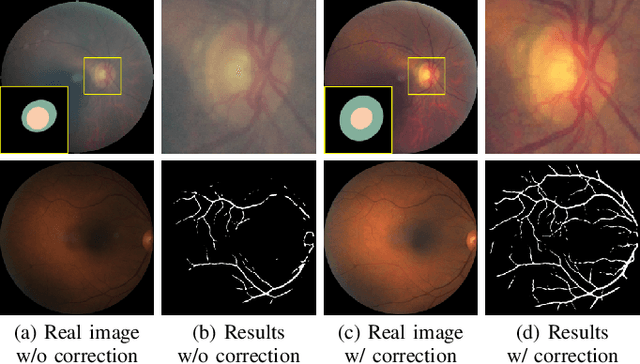
Retinal fundus images are widely used for clinical screening and diagnosis of eye diseases. However, fundus images captured by operators with various levels of experiences have a large variation in quality. Low-quality fundus images increase the uncertainty in clinical observation and lead to a risk of misdiagnosis. Due to the special optical beam of fundus imaging and retinal structure, the natural image enhancement methods cannot be utilized directly. In this paper, we first analyze the ophthalmoscope imaging system and model the reliable degradation of major inferior-quality factors, including uneven illumination, blur, and artifacts. Then, based on the degradation model, a clinical-oriented fundus enhancement network~(cofe-Net)~is proposed to suppress the global degradation factors, and simultaneously preserve anatomical retinal structures and pathological characteristics for clinical observation and analysis. Experiments on both synthetic and real fundus images demonstrate that our algorithm effectively corrects low-quality fundus images without losing retinal details. Moreover, we also show that the fundus correction method can benefit medical image analysis applications, e.g, retinal vessel segmentation and optic disc/cup detection.
Generation of High Dynamic Range Illumination from a Single Image for the Enhancement of Undesirably Illuminated Images
Aug 02, 2017



This paper presents an algorithm that enhances undesirably illuminated images by generating and fusing multi-level illuminations from a single image.The input image is first decomposed into illumination and reflectance components by using an edge-preserving smoothing filter. Then the reflectance component is scaled up to improve the image details in bright areas. The illumination component is scaled up and down to generate several illumination images that correspond to certain camera exposure values different from the original. The virtual multi-exposure illuminations are blended into an enhanced illumination, where we also propose a method to generate appropriate weight maps for the tone fusion. Finally, an enhanced image is obtained by multiplying the equalized illumination and enhanced reflectance. Experiments show that the proposed algorithm produces visually pleasing output and also yields comparable objective results to the conventional enhancement methods, while requiring modest computational loads.
Freehand Ultrasound Image Simulation with Spatially-Conditioned Generative Adversarial Networks
Jul 17, 2017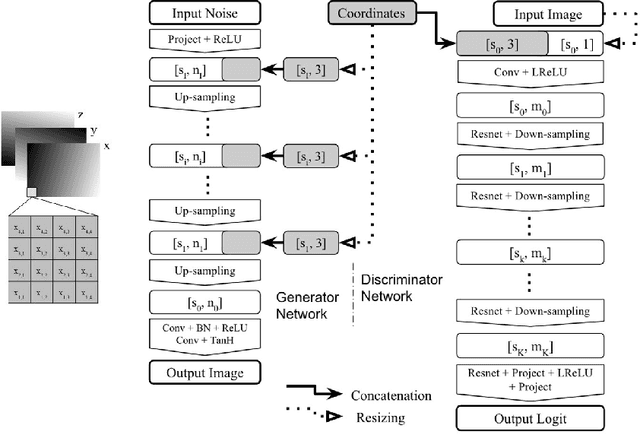
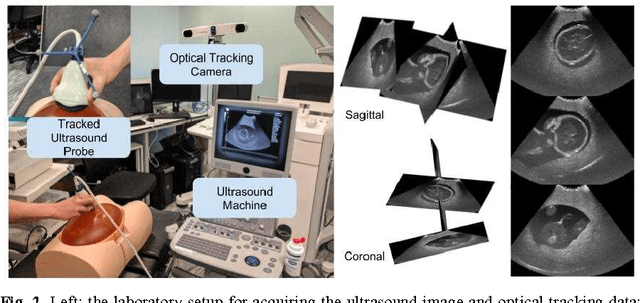
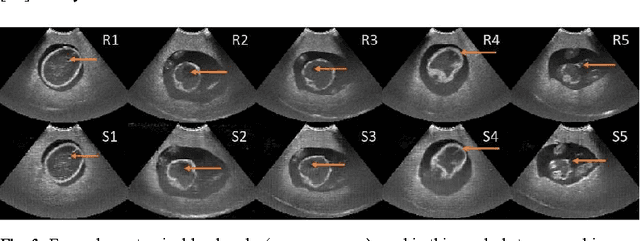
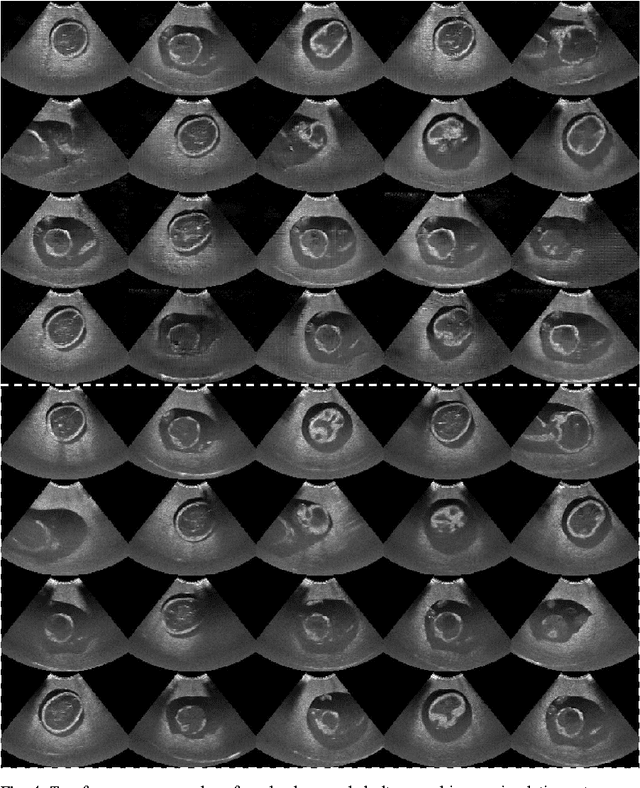
Sonography synthesis has a wide range of applications, including medical procedure simulation, clinical training and multimodality image registration. In this paper, we propose a machine learning approach to simulate ultrasound images at given 3D spatial locations (relative to the patient anatomy), based on conditional generative adversarial networks (GANs). In particular, we introduce a novel neural network architecture that can sample anatomically accurate images conditionally on spatial position of the (real or mock) freehand ultrasound probe. To ensure an effective and efficient spatial information assimilation, the proposed spatially-conditioned GANs take calibrated pixel coordinates in global physical space as conditioning input, and utilise residual network units and shortcuts of conditioning data in the GANs' discriminator and generator, respectively. Using optically tracked B-mode ultrasound images, acquired by an experienced sonographer on a fetus phantom, we demonstrate the feasibility of the proposed method by two sets of quantitative results: distances were calculated between corresponding anatomical landmarks identified in the held-out ultrasound images and the simulated data at the same locations unseen to the networks; a usability study was carried out to distinguish the simulated data from the real images. In summary, we present what we believe are state-of-the-art visually realistic ultrasound images, simulated by the proposed GAN architecture that is stable to train and capable of generating plausibly diverse image samples.
An Improved Relevance Feedback in CBIR
Jun 21, 2020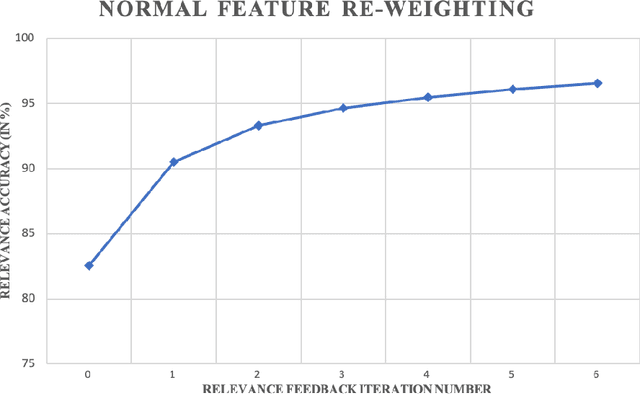
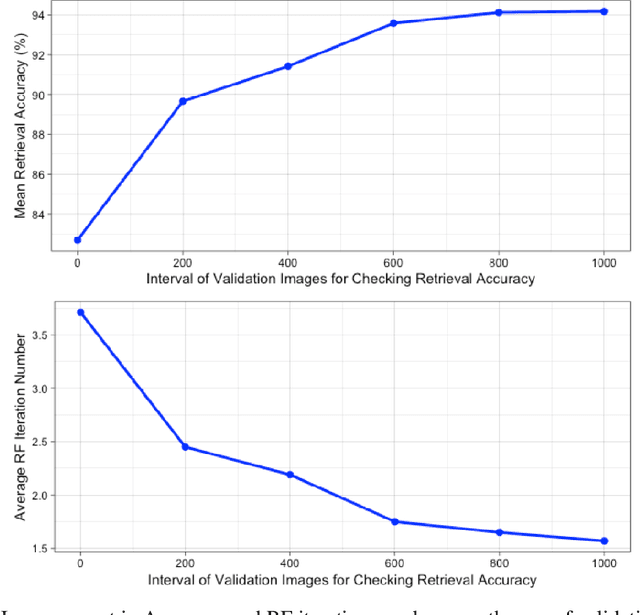
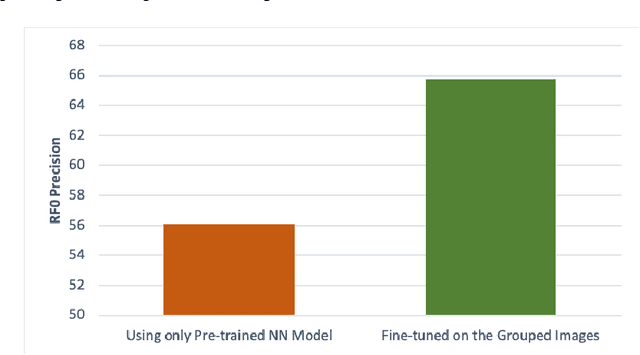
Relevance Feedback in Content-Based Image Retrieval is a method where the feedback of the performance is being used to improve itself. Prior works use feature re-weighting and classification techniques as the Relevance Feedback methods. This paper shows a novel addition to the prior methods to further improve the retrieval accuracy. In addition to all of these, the paper also shows a novel idea to even improve the 0-th iteration retrieval accuracy from the information of Relevance Feedback.
Contour Primitive of Interest Extraction Network Based on One-shot Learning for Object-Agnostic Vision Measurement
Oct 07, 2020
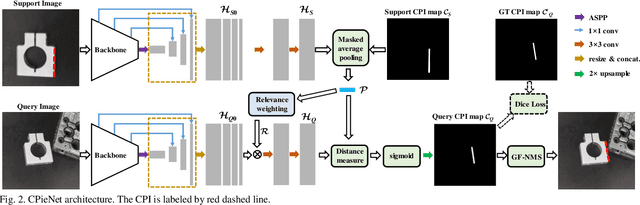
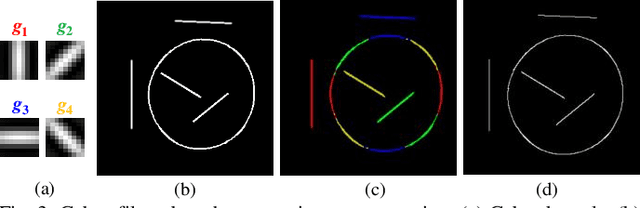

Image contour based vision measurement is widely applied in robot manipulation and industrial automation. It is appealing to realize object-agnostic vision system, which can be conveniently reused for various types of objects. We propose the contour primitive of interest extraction network (CPieNet) based on the one-shot learning framework. First, CPieNet is featured by that its contour primitive of interest (CPI) output, a designated regular contour part lying on a specified object, provides the essential geometric information for vision measurement. Second, CPieNet has the one-shot learning ability, utilizing a support sample to assist the perception of the novel object. To realize lower-cost training, we generate support-query sample pairs from unpaired online public images, which cover a wide range of object categories. To obtain single-pixel wide contour for precise measurement, the Gabor-filters based non-maximum suppression is designed to thin the raw contour. For the novel CPI extraction task, we built the Object Contour Primitives dataset using online public images, and the Robotic Object Contour Measurement dataset using a camera mounted on a robot. The effectiveness of the proposed methods is validated by a series of experiments.
DVERGE: Diversifying Vulnerabilities for Enhanced Robust Generation of Ensembles
Oct 18, 2020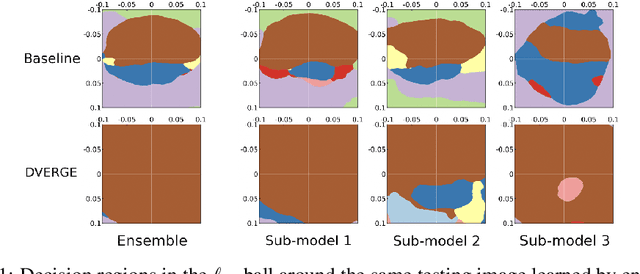

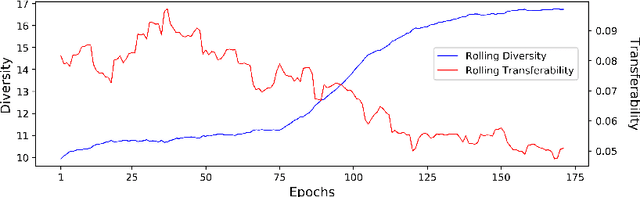

Recent research finds CNN models for image classification demonstrate overlapped adversarial vulnerabilities: adversarial attacks can mislead CNN models with small perturbations, which can effectively transfer between different models trained on the same dataset. Adversarial training, as a general robustness improvement technique, eliminates the vulnerability in a single model by forcing it to learn robust features. The process is hard, often requires models with large capacity, and suffers from significant loss on clean data accuracy. Alternatively, ensemble methods are proposed to induce sub-models with diverse outputs against a transfer adversarial example, making the ensemble robust against transfer attacks even if each sub-model is individually non-robust. Only small clean accuracy drop is observed in the process. However, previous ensemble training methods are not efficacious in inducing such diversity and thus ineffective on reaching robust ensemble. We propose DVERGE, which isolates the adversarial vulnerability in each sub-model by distilling non-robust features, and diversifies the adversarial vulnerability to induce diverse outputs against a transfer attack. The novel diversity metric and training procedure enables DVERGE to achieve higher robustness against transfer attacks comparing to previous ensemble methods, and enables the improved robustness when more sub-models are added to the ensemble. The code of this work is available at https://github.com/zjysteven/DVERGE
CaDIS: Cataract Dataset for Image Segmentation
Jul 19, 2019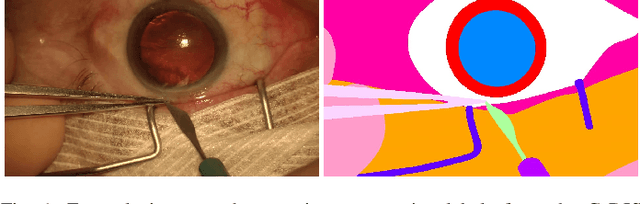
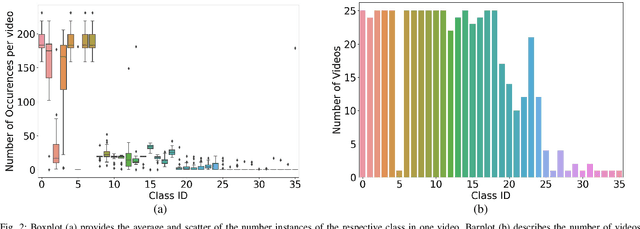
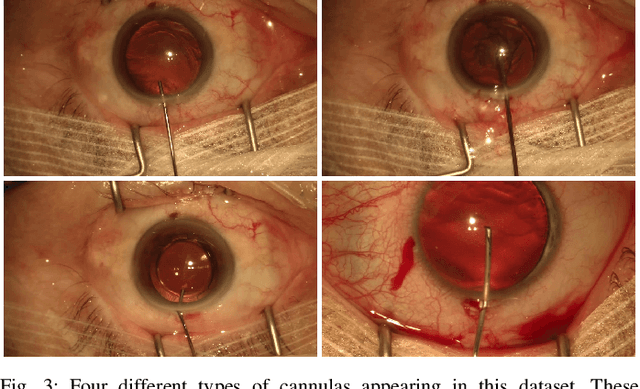

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.
ZEST: Zero-shot Learning from Text Descriptions using Textual Similarity and Visual Summarization
Oct 07, 2020
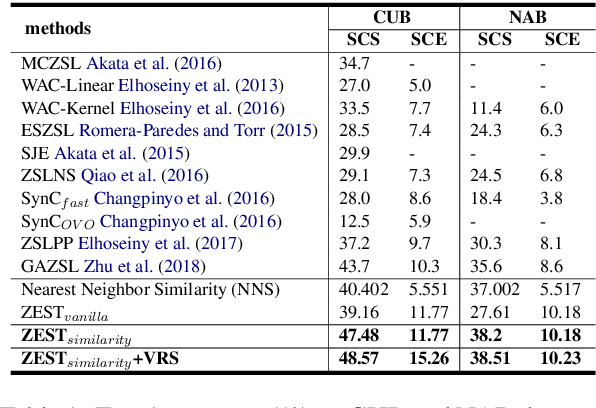
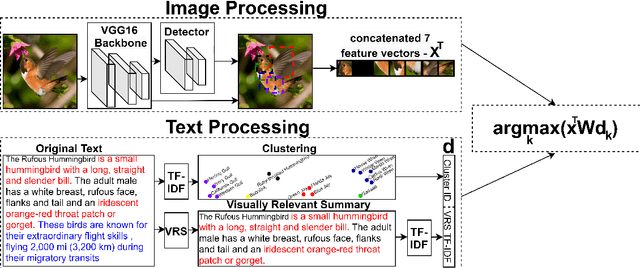
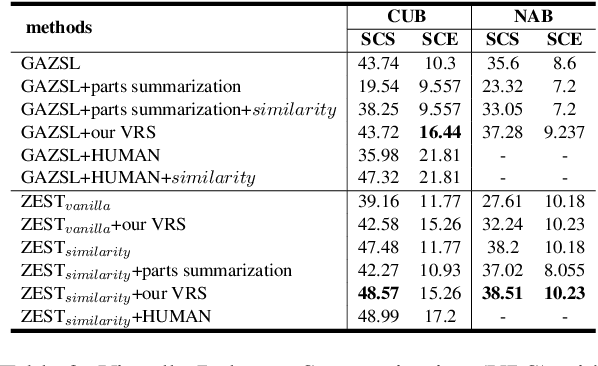
We study the problem of recognizing visual entities from the textual descriptions of their classes. Specifically, given birds' images with free-text descriptions of their species, we learn to classify images of previously-unseen species based on specie descriptions. This setup has been studied in the vision community under the name zero-shot learning from text, focusing on learning to transfer knowledge about visual aspects of birds from seen classes to previously-unseen ones. Here, we suggest focusing on the textual description and distilling from the description the most relevant information to effectively match visual features to the parts of the text that discuss them. Specifically, (1) we propose to leverage the similarity between species, reflected in the similarity between text descriptions of the species. (2) we derive visual summaries of the texts, i.e., extractive summaries that focus on the visual features that tend to be reflected in images. We propose a simple attention-based model augmented with the similarity and visual summaries components. Our empirical results consistently and significantly outperform the state-of-the-art on the largest benchmarks for text-based zero-shot learning, illustrating the critical importance of texts for zero-shot image-recognition.