 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaDIS: Cataract Dataset for Image Segmentation
Paper and Code
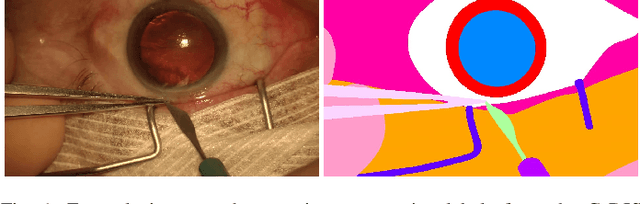
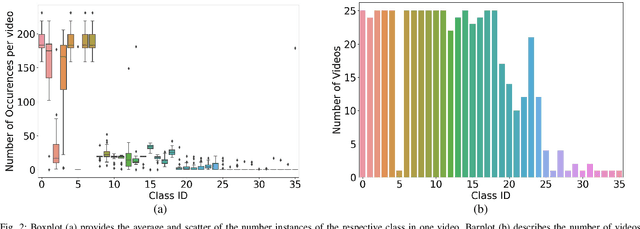
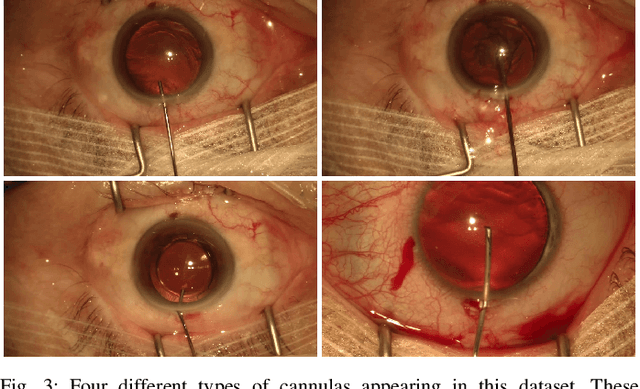

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.