 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Baseline and Triangulation Geometry in a Standard Plenoptic Camera
Oct 09, 2020
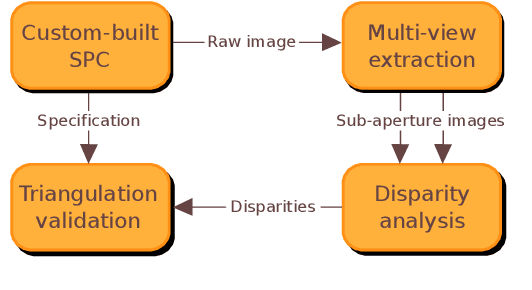

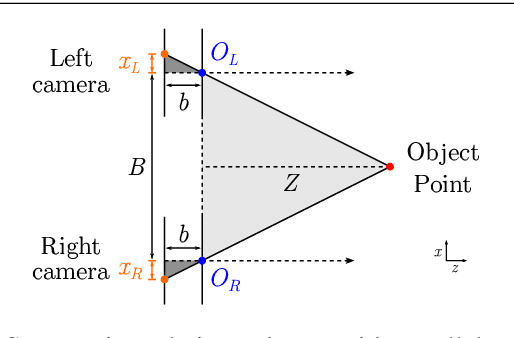
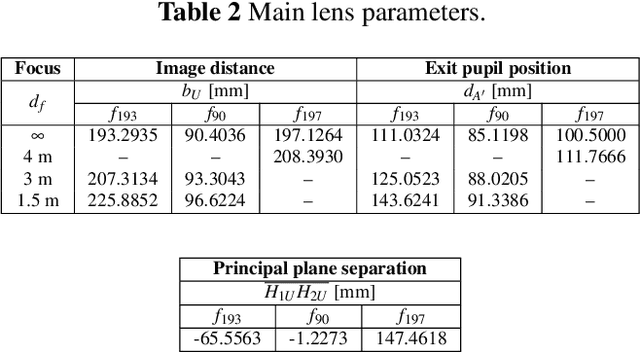
In this paper, we demonstrate light field triangulation to determine depth distances and baselines in a plenoptic camera. Advances in micro lenses and image sensors have enabled plenoptic cameras to capture a scene from different viewpoints with sufficient spatial resolution. While object distances can be inferred from disparities in a stereo viewpoint pair using triangulation, this concept remains ambiguous when applied in the case of plenoptic cameras. We present a geometrical light field model allowing the triangulation to be applied to a plenoptic camera in order to predict object distances or specify baselines as desired. It is shown that distance estimates from our novel method match those of real objects placed in front of the camera. Additional benchmark tests with an optical design software further validate the model's accuracy with deviations of less than +-0.33 % for several main lens types and focus settings. A variety of applications in the automotive and robotics field can benefit from this estimation model.
Augmentor: An Image Augmentation Library for Machine Learning
Aug 11, 2017

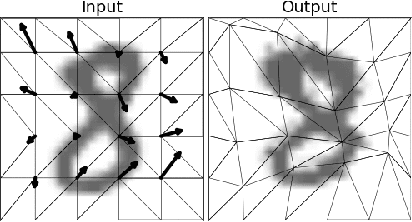

The generation of artificial data based on existing observations, known as data augmentation, is a technique used in machine learning to improve model accuracy, generalisation, and to control overfitting. Augmentor is a software package, available in both Python and Julia versions, that provides a high level API for the expansion of image data using a stochastic, pipeline-based approach which effectively allows for images to be sampled from a distribution of augmented images at runtime. Augmentor provides methods for most standard augmentation practices as well as several advanced features such as label-preserving, randomised elastic distortions, and provides many helper functions for typical augmentation tasks used in machine learning.
Attribute-Guided Adversarial Training for Robustness to Natural Perturbations
Dec 03, 2020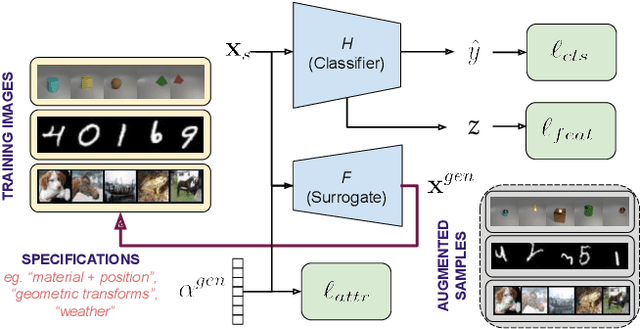
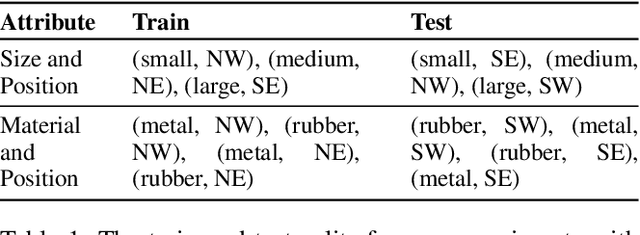

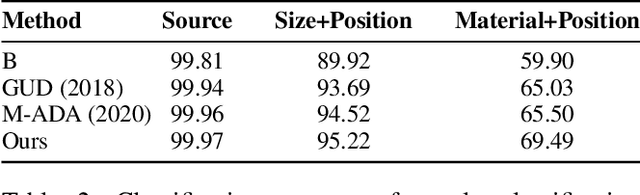
While existing work in robust deep learning has focused on small pixel-level $\ell_p$ norm-based perturbations, this may not account for perturbations encountered in several real world settings. In many such cases although test data might not be available, broad specifications about the types of perturbations (such as an unknown degree of rotation) may be known. We consider a setup where robustness is expected over an unseen test domain that is not i.i.d. but deviates from the training domain. While this deviation may not be exactly known, its broad characterization is specified a priori, in terms of attributes. We propose an adversarial training approach which learns to generate new samples so as to maximize exposure of the classifier to the attributes-space, without having access to the data from the test domain. Our adversarial training solves a min-max optimization problem, with the inner maximization generating adversarial perturbations, and the outer minimization finding model parameters by optimizing the loss on adversarial perturbations generated from the inner maximization. We demonstrate the applicability of our approach on three types of naturally occurring perturbations -- object-related shifts, geometric transformations, and common image corruptions. Our approach enables deep neural networks to be robust against a wide range of naturally occurring perturbations. We demonstrate the usefulness of the proposed approach by showing the robustness gains of deep neural networks trained using our adversarial training on MNIST, CIFAR-10, and a new variant of the CLEVR dataset.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 22, 2020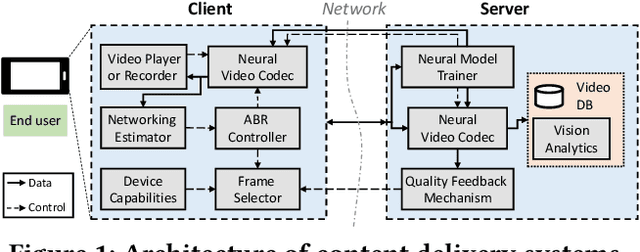


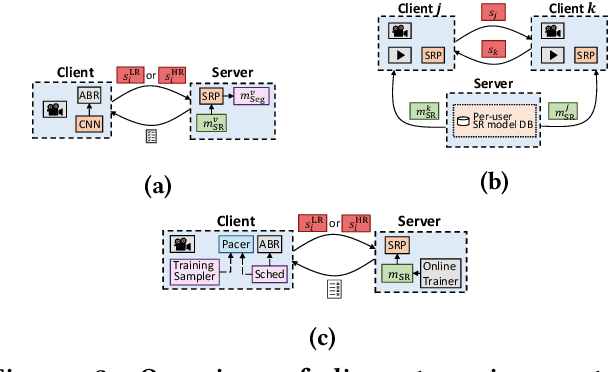
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Comparative Deep Learning of Hybrid Representations for Image Recommendations
Apr 05, 2016
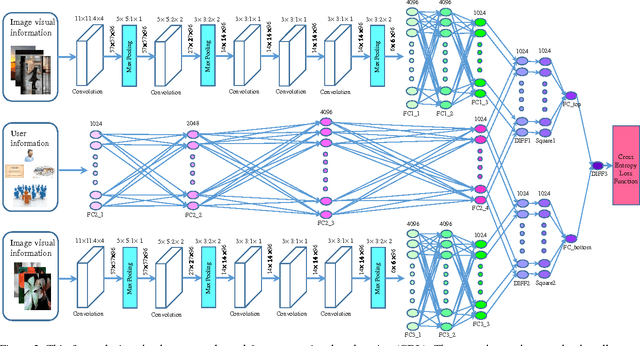
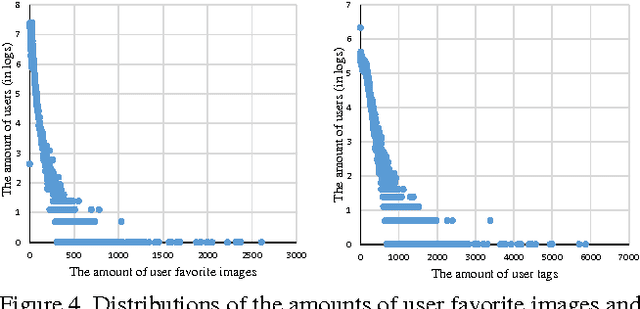
In many image-related tasks, learning expressive and discriminative representations of images is essential, and deep learning has been studied for automating the learning of such representations. Some user-centric tasks, such as image recommendations, call for effective representations of not only images but also preferences and intents of users over images. Such representations are termed \emph{hybrid} and addressed via a deep learning approach in this paper. We design a dual-net deep network, in which the two sub-networks map input images and preferences of users into a same latent semantic space, and then the distances between images and users in the latent space are calculated to make decisions. We further propose a comparative deep learning (CDL) method to train the deep network, using a pair of images compared against one user to learn the pattern of their relative distances. The CDL embraces much more training data than naive deep learning, and thus achieves superior performance than the latter, with no cost of increasing network complexity. Experimental results with real-world data sets for image recommendations have shown the proposed dual-net network and CDL greatly outperform other state-of-the-art image recommendation solutions.
Meta3D: Single-View 3D Object Reconstruction from Shape Priors in Memory
Mar 14, 2020
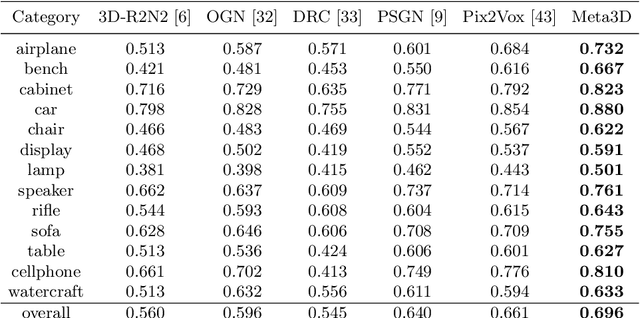
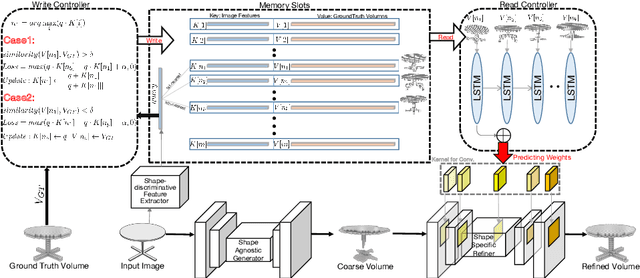
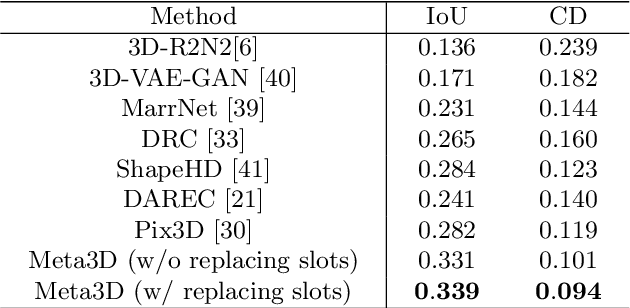
3D shape reconstruction from a single-view RGB image is an ill-posed problem due to the invisible parts of the object to be reconstructed. Most of the existing methods rely on large-scale data to obtain shape priors through tuning parameters of reconstruction models. These methods might not be able to deal with the cases with heavy object occlusions and noisy background since prior information can not be retained completely or applied efficiently. In this paper, we are the first to develop a memory-based meta-learning framework for single-view 3D reconstruction. A write controller is designed to extract shape-discriminative features from images and store image features and their corresponding volumes into external memory. A read controller is proposed to sequentially encode shape priors related to the input image and predict a shape-specific refiner. Experimental results demonstrate that our Meta3D outperforms state-of-the-art methods with a large margin through retaining shape priors explicitly, especially for the extremely difficult cases.
View-consistent 4D Light Field Depth Estimation
Sep 09, 2020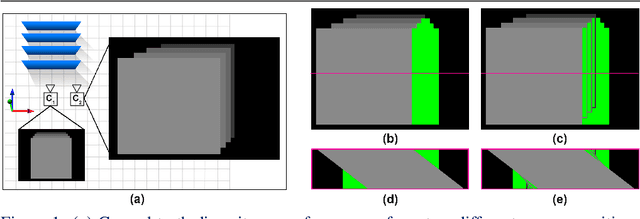
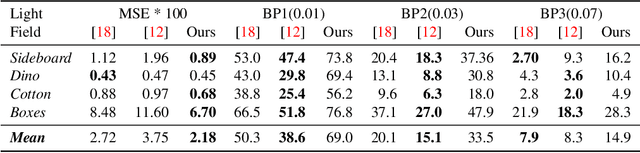
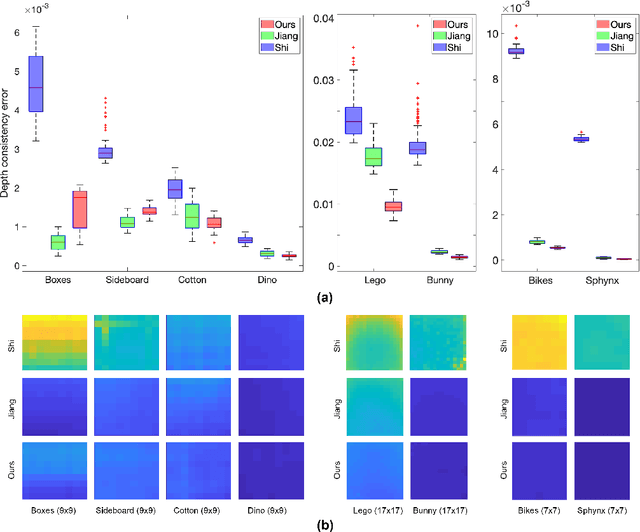

We propose a method to compute depth maps for every sub-aperture image in a light field in a view consistent way. Previous light field depth estimation methods typically estimate a depth map only for the central sub-aperture view, and struggle with view consistent estimation. Our method precisely defines depth edges via EPIs, then we diffuse these edges spatially within the central view. These depth estimates are then propagated to all other views in an occlusion-aware way. Finally, disoccluded regions are completed by diffusion in EPI space. Our method runs efficiently with respect to both other classical and deep learning-based approaches, and achieves competitive quantitative metrics and qualitative performance on both synthetic and real-world light fields
MultAV: Multiplicative Adversarial Videos
Sep 17, 2020
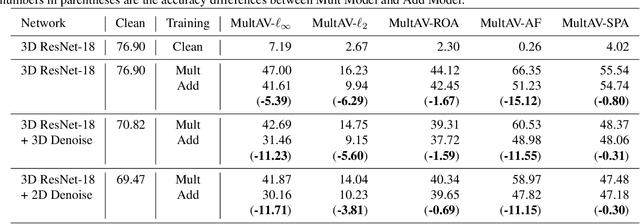
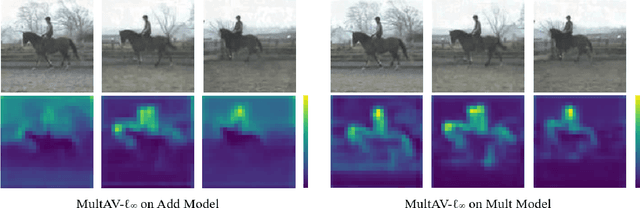
The majority of adversarial machine learning research focuses on additive threat models, which add adversarial perturbation to input data. On the other hand, unlike image recognition problems, only a handful of threat models have been explored in the video domain. In this paper, we propose a novel adversarial attack against video recognition models, Multiplicative Adversarial Videos (MultAV), which imposes perturbation on video data by multiplication. MultAV has different noise distributions to the additive counterparts and thus challenges the defense methods tailored to resisting additive attacks. Moreover, it can be generalized to not only Lp-norm attacks with a new adversary constraint called ratio bound, but also different types of physically realizable attacks. Experimental results show that the model adversarially trained against additive attack is less robust to MultAV.
Visual Question Answering on 360° Images
Jan 10, 2020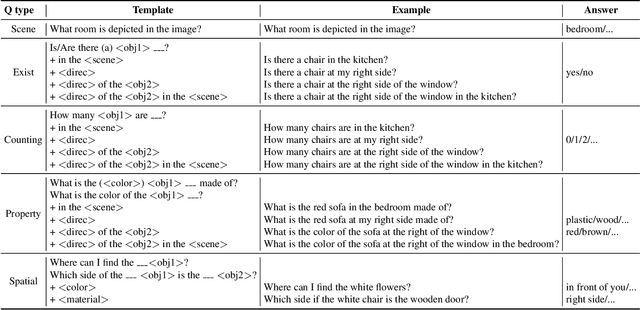
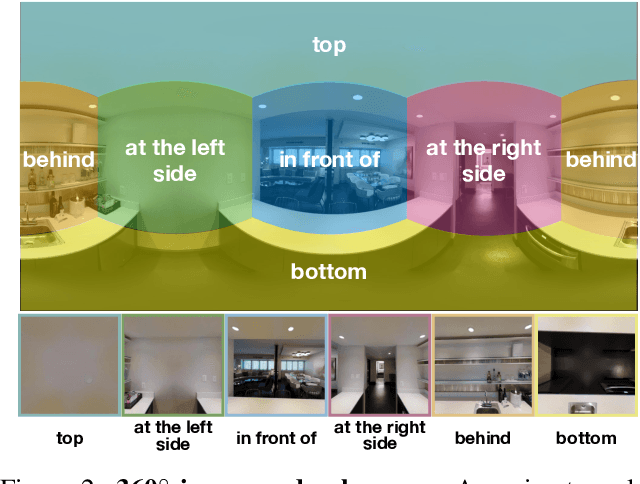
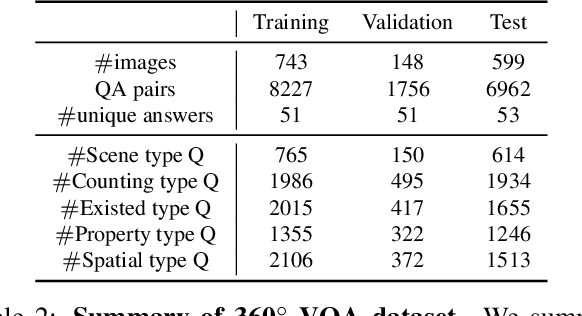
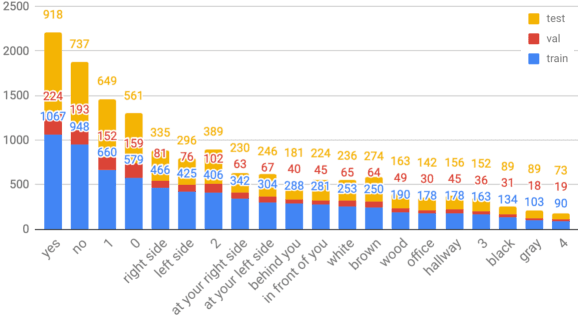
In this work, we introduce VQA 360, a novel task of visual question answering on 360 images. Unlike a normal field-of-view image, a 360 image captures the entire visual content around the optical center of a camera, demanding more sophisticated spatial understanding and reasoning. To address this problem, we collect the first VQA 360 dataset, containing around 17,000 real-world image-question-answer triplets for a variety of question types. We then study two different VQA models on VQA 360, including one conventional model that takes an equirectangular image (with intrinsic distortion) as input and one dedicated model that first projects a 360 image onto cubemaps and subsequently aggregates the information from multiple spatial resolutions. We demonstrate that the cubemap-based model with multi-level fusion and attention diffusion performs favorably against other variants and the equirectangular-based models. Nevertheless, the gap between the humans' and machines' performance reveals the need for more advanced VQA 360 algorithms. We, therefore, expect our dataset and studies to serve as the benchmark for future development in this challenging task. Dataset, code, and pre-trained models are available online.
Learning Monocular Dense Depth from Events
Oct 22, 2020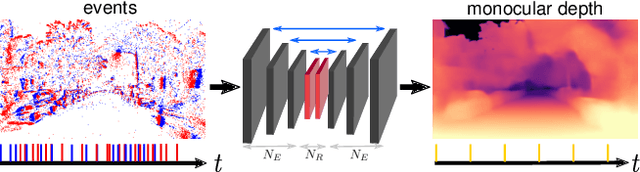
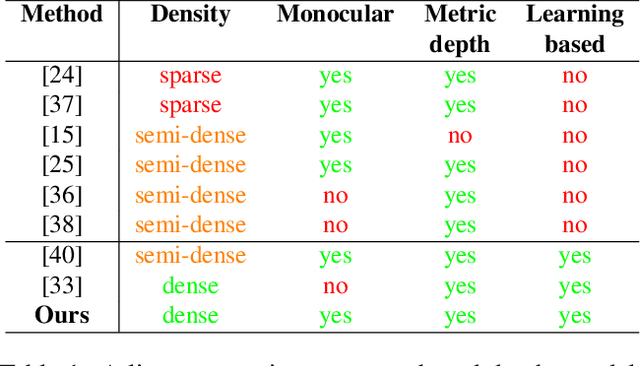
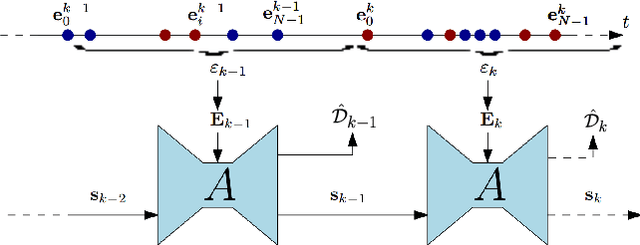
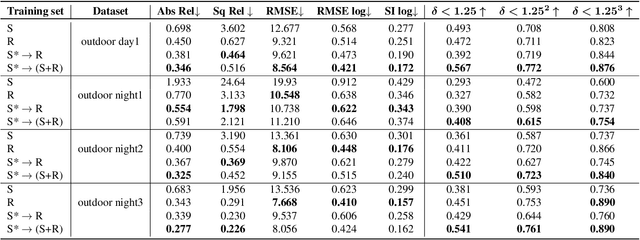
Event cameras are novel sensors that output brightness changes in the form of a stream of asynchronous events instead of intensity frames. Compared to conventional image sensors, they offer significant advantages: high temporal resolution, high dynamic range, no motion blur, and much lower bandwidth. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. Most existing approaches use standard feed-forward architectures to generate network predictions, which do not leverage the temporal consistency presents in the event stream. We propose a recurrent architecture to solve this task and show significant improvement over standard feed-forward methods. In particular, our method generates dense depth predictions using a monocular setup, which has not been shown previously. We pretrain our model using a new dataset containing events and depth maps recorded in the CARLA simulator. We test our method on the Multi Vehicle Stereo Event Camera Dataset (MVSEC). Quantitative experiments show up to 50% improvement in average depth error with respect to previous event-based methods.