 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
May 25, 2025We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
Benchmarking Burst Super-Resolution for Polarization Images: Noise Dataset and Analysis
Mar 24, 2025



Snapshot polarization imaging calculates polarization states from linearly polarized subimages. To achieve this, a polarization camera employs a double Bayer-patterned sensor to capture both color and polarization. It demonstrates low light efficiency and low spatial resolution, resulting in increased noise and compromised polarization measurements. Although burst super-resolution effectively reduces noise and enhances spatial resolution, applying it to polarization imaging poses challenges due to the lack of tailored datasets and reliable ground truth noise statistics. To address these issues, we introduce PolarNS and PolarBurstSR, two innovative datasets developed specifically for polarization imaging. PolarNS provides characterization of polarization noise statistics, facilitating thorough analysis, while PolarBurstSR functions as a benchmark for burst super-resolution in polarization images. These datasets, collected under various real-world conditions, enable comprehensive evaluation. Additionally, we present a model for analyzing polarization noise to quantify noise propagation, tested on a large dataset captured in a darkroom environment. As part of our application, we compare the latest burst super-resolution models, highlighting the advantages of training tailored to polarization compared to RGB-based methods. This work establishes a benchmark for polarization burst super-resolution and offers critical insights into noise propagation, thereby enhancing polarization image reconstruction.
Polarimetric BSSRDF Acquisition of Dynamic Faces
Dec 29, 2024



Acquisition and modeling of polarized light reflection and scattering help reveal the shape, structure, and physical characteristics of an object, which is increasingly important in computer graphics. However, current polarimetric acquisition systems are limited to static and opaque objects. Human faces, on the other hand, present a particularly difficult challenge, given their complex structure and reflectance properties, the strong presence of spatially-varying subsurface scattering, and their dynamic nature. We present a new polarimetric acquisition method for dynamic human faces, which focuses on capturing spatially varying appearance and precise geometry, across a wide spectrum of skin tones and facial expressions. It includes both single and heterogeneous subsurface scattering, index of refraction, and specular roughness and intensity, among other parameters, while revealing biophysically-based components such as inner- and outer-layer hemoglobin, eumelanin and pheomelanin. Our method leverages such components' unique multispectral absorption profiles to quantify their concentrations, which in turn inform our model about the complex interactions occurring within the skin layers. To our knowledge, our work is the first to simultaneously acquire polarimetric and spectral reflectance information alongside biophysically-based skin parameters and geometry of dynamic human faces. Moreover, our polarimetric skin model integrates seamlessly into various rendering pipelines.
OmniSDF: Scene Reconstruction using Omnidirectional Signed Distance Functions and Adaptive Binoctrees
Mar 31, 2024We present a method to reconstruct indoor and outdoor static scene geometry and appearance from an omnidirectional video moving in a small circular sweep. This setting is challenging because of the small baseline and large depth ranges, making it difficult to find ray crossings. To better constrain the optimization, we estimate geometry as a signed distance field within a spherical binoctree data structure and use a complementary efficient tree traversal strategy based on a breadth-first search for sampling. Unlike regular grids or trees, the shape of this structure well-matches the camera setting, creating a better memory-quality trade-off. From an initial depth estimate, the binoctree is adaptively subdivided throughout the optimization; previous methods use a fixed depth that leaves the scene undersampled. In comparison with three neural optimization methods and two non-neural methods, ours shows decreased geometry error on average, especially in a detailed scene, while significantly reducing the required number of voxels to represent such details.
OmniLocalRF: Omnidirectional Local Radiance Fields from Dynamic Videos
Mar 31, 2024



Omnidirectional cameras are extensively used in various applications to provide a wide field of vision. However, they face a challenge in synthesizing novel views due to the inevitable presence of dynamic objects, including the photographer, in their wide field of view. In this paper, we introduce a new approach called Omnidirectional Local Radiance Fields (OmniLocalRF) that can render static-only scene views, removing and inpainting dynamic objects simultaneously. Our approach combines the principles of local radiance fields with the bidirectional optimization of omnidirectional rays. Our input is an omnidirectional video, and we evaluate the mutual observations of the entire angle between the previous and current frames. To reduce ghosting artifacts of dynamic objects and inpaint occlusions, we devise a multi-resolution motion mask prediction module. Unlike existing methods that primarily separate dynamic components through the temporal domain, our method uses multi-resolution neural feature planes for precise segmentation, which is more suitable for long 360-degree videos. Our experiments validate that OmniLocalRF outperforms existing methods in both qualitative and quantitative metrics, especially in scenarios with complex real-world scenes. In particular, our approach eliminates the need for manual interaction, such as drawing motion masks by hand and additional pose estimation, making it a highly effective and efficient solution.
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Sep 26, 2023



Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
Polarimetric iToF: Measuring High-Fidelity Depth through Scattering Media
Jun 30, 2023



Indirect time-of-flight (iToF) imaging allows us to capture dense depth information at a low cost. However, iToF imaging often suffers from multipath interference (MPI) artifacts in the presence of scattering media, resulting in severe depth-accuracy degradation. For instance, iToF cameras cannot measure depth accurately through fog because ToF active illumination scatters back to the sensor before reaching the farther target surface. In this work, we propose a polarimetric iToF imaging method that can capture depth information robustly through scattering media. Our observations on the principle of indirect ToF imaging and polarization of light allow us to formulate a novel computational model of scattering-aware polarimetric phase measurements that enables us to correct MPI errors. We first devise a scattering-aware polarimetric iToF model that can estimate the phase of unpolarized backscattered light. We then combine the optical filtering of polarization and our computational modeling of unpolarized backscattered light via scattering analysis of phase and amplitude. This allows us to tackle the MPI problem by estimating the scattering energy through the participating media. We validate our method on an experimental setup using a customized off-the-shelf iToF camera. Our method outperforms baseline methods by a significant margin by means of our scattering model and polarimetric phase measurements.
Progressively Optimized Local Radiance Fields for Robust View Synthesis
Mar 24, 2023



We present an algorithm for reconstructing the radiance field of a large-scale scene from a single casually captured video. The task poses two core challenges. First, most existing radiance field reconstruction approaches rely on accurate pre-estimated camera poses from Structure-from-Motion algorithms, which frequently fail on in-the-wild videos. Second, using a single, global radiance field with finite representational capacity does not scale to longer trajectories in an unbounded scene. For handling unknown poses, we jointly estimate the camera poses with radiance field in a progressive manner. We show that progressive optimization significantly improves the robustness of the reconstruction. For handling large unbounded scenes, we dynamically allocate new local radiance fields trained with frames within a temporal window. This further improves robustness (e.g., performs well even under moderate pose drifts) and allows us to scale to large scenes. Our extensive evaluation on the Tanks and Temples dataset and our collected outdoor dataset, Static Hikes, show that our approach compares favorably with the state-of-the-art.
* Project page: https://localrf.github.io/
FloatingFusion: Depth from ToF and Image-stabilized Stereo Cameras
Oct 06, 2022High-accuracy per-pixel depth is vital for computational photography, so smartphones now have multimodal camera systems with time-of-flight (ToF) depth sensors and multiple color cameras. However, producing accurate high-resolution depth is still challenging due to the low resolution and limited active illumination power of ToF sensors. Fusing RGB stereo and ToF information is a promising direction to overcome these issues, but a key problem remains: to provide high-quality 2D RGB images, the main color sensor's lens is optically stabilized, resulting in an unknown pose for the floating lens that breaks the geometric relationships between the multimodal image sensors. Leveraging ToF depth estimates and a wide-angle RGB camera, we design an automatic calibration technique based on dense 2D/3D matching that can estimate camera extrinsic, intrinsic, and distortion parameters of a stabilized main RGB sensor from a single snapshot. This lets us fuse stereo and ToF cues via a correlation volume. For fusion, we apply deep learning via a real-world training dataset with depth supervision estimated by a neural reconstruction method. For evaluation, we acquire a test dataset using a commercial high-power depth camera and show that our approach achieves higher accuracy than existing baselines.
Sparse Ellipsometry: Portable Acquisition of Polarimetric SVBRDF and Shape with Unstructured Flash Photography
Jul 09, 2022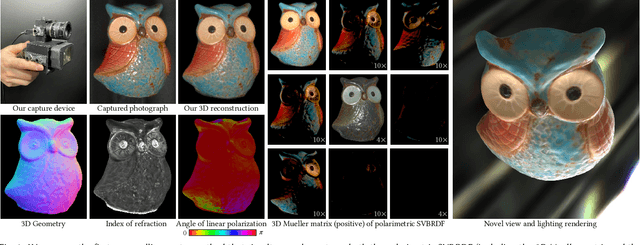
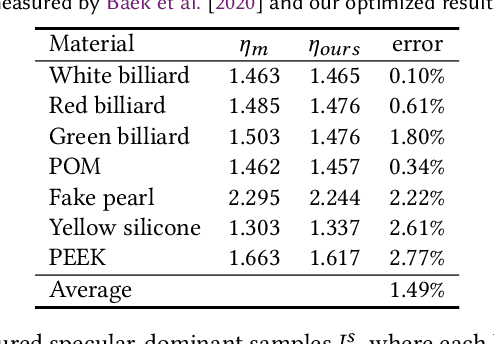
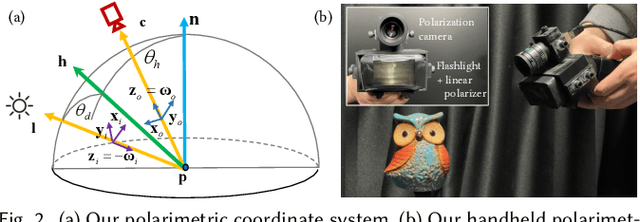
Ellipsometry techniques allow to measure polarization information of materials, requiring precise rotations of optical components with different configurations of lights and sensors. This results in cumbersome capture devices, carefully calibrated in lab conditions, and in very long acquisition times, usually in the order of a few days per object. Recent techniques allow to capture polarimetric spatially-varying reflectance information, but limited to a single view, or to cover all view directions, but limited to spherical objects made of a single homogeneous material. We present sparse ellipsometry, a portable polarimetric acquisition method that captures both polarimetric SVBRDF and 3D shape simultaneously. Our handheld device consists of off-the-shelf, fixed optical components. Instead of days, the total acquisition time varies between twenty and thirty minutes per object. We develop a complete polarimetric SVBRDF model that includes diffuse and specular components, as well as single scattering, and devise a novel polarimetric inverse rendering algorithm with data augmentation of specular reflection samples via generative modeling. Our results show a strong agreement with a recent ground-truth dataset of captured polarimetric BRDFs of real-world objects.