 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers
Nov 27, 2020
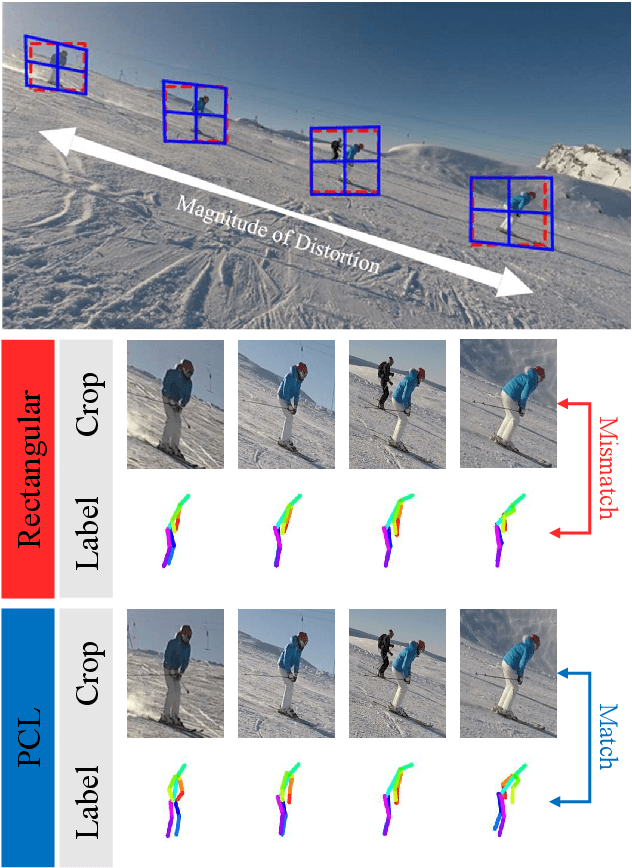
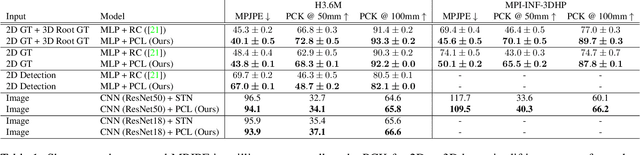
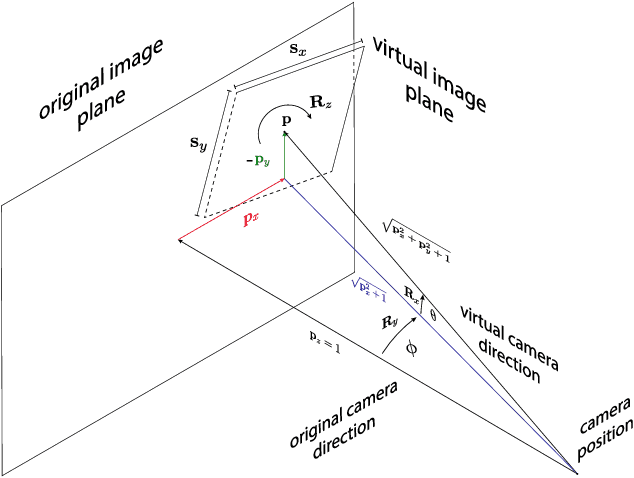

Local processing is an essential feature of CNNs and other neural network architectures - it is one of the reasons why they work so well on images where relevant information is, to a large extent, local. However, perspective effects stemming from the projection in a conventional camera vary for different global positions in the image. We introduce Perspective Crop Layers (PCLs) - a form of perspective crop of the region of interest based on the camera geometry - and show that accounting for the perspective consistently improves the accuracy of state-of-the-art 3D pose reconstruction methods. PCLs are modular neural network layers, which, when inserted into existing CNN and MLP architectures, deterministically remove the location-dependent perspective effects while leaving end-to-end training and the number of parameters of the underlying neural network unchanged. We demonstrate that PCL leads to improved 3D human pose reconstruction accuracy for CNN architectures that use cropping operations, such as spatial transformer networks (STN), and, somewhat surprisingly, MLPs used for 2D-to-3D keypoint lifting. Our conclusion is that it is important to utilize camera calibration information when available, for classical and deep-learning-based computer vision alike. PCL offers an easy way to improve the accuracy of existing 3D reconstruction networks by making them geometry-aware.
The Heterogeneity Hypothesis: Finding Layer-Wise Dissimilated Network Architecture
Jun 29, 2020
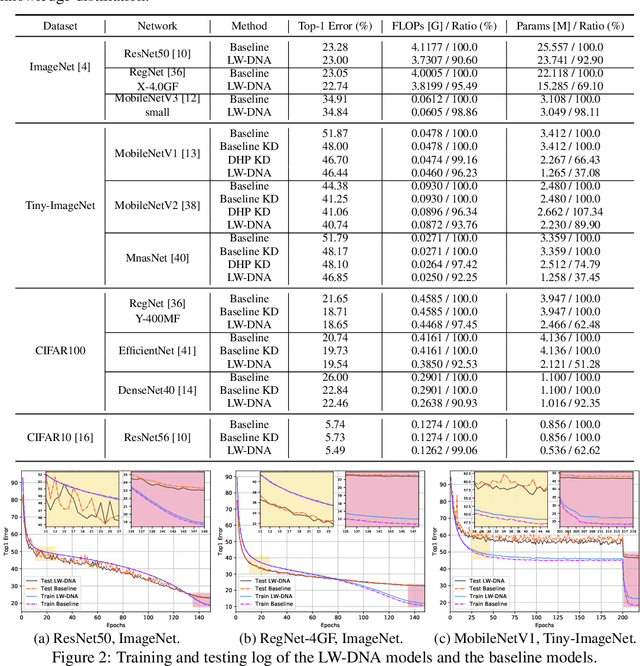
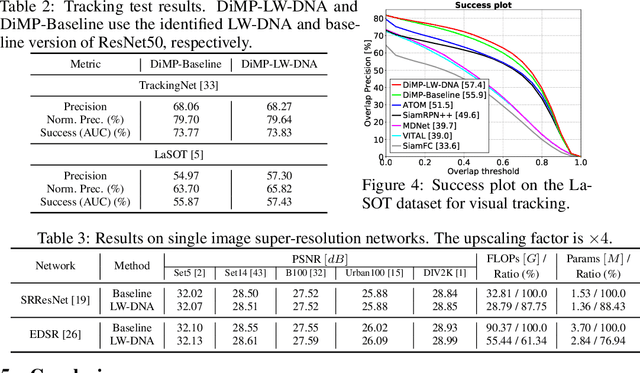
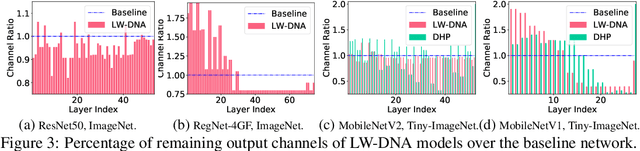
In this paper, we tackle the problem of convolutional neural network design. Instead of focusing on the overall architecture design, we investigate a design space that is usually overlooked, \ie adjusting the channel configurations of predefined networks. We find that this adjustment can be achieved by pruning widened baseline networks and leads to superior performance. Base on that, we articulate the ``heterogeneity hypothesis'': with the same training protocol, there exists a layer-wise dissimilated network architecture (LW-DNA) that can outperform the original network with regular channel configurations under lower level of model complexity. The LW-DNA models are identified without added computational cost and training time compared with the original network. This constraint leads to controlled experiment which directs the focus to the importance of layer-wise specific channel configurations. Multiple sources of hints relate the benefits of LW-DNA models to overfitting, \ie the relative relationship between model complexity and dataset size. Experiments are conducted on various networks and datasets for image classification, visual tracking and image restoration. The resultant LW-DNA models consistently outperform the compared baseline models.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020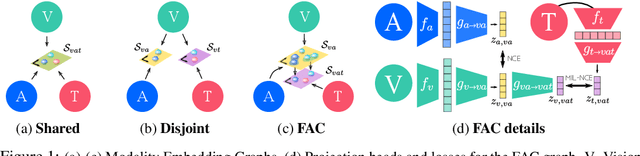
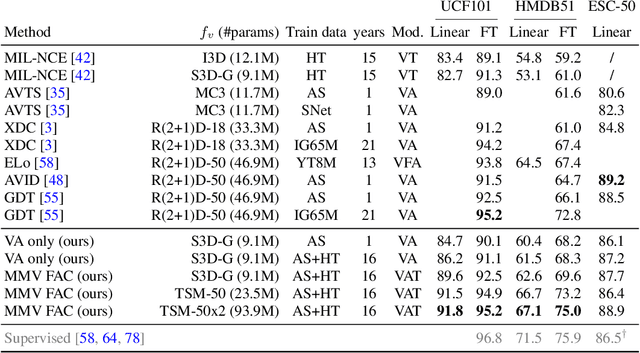
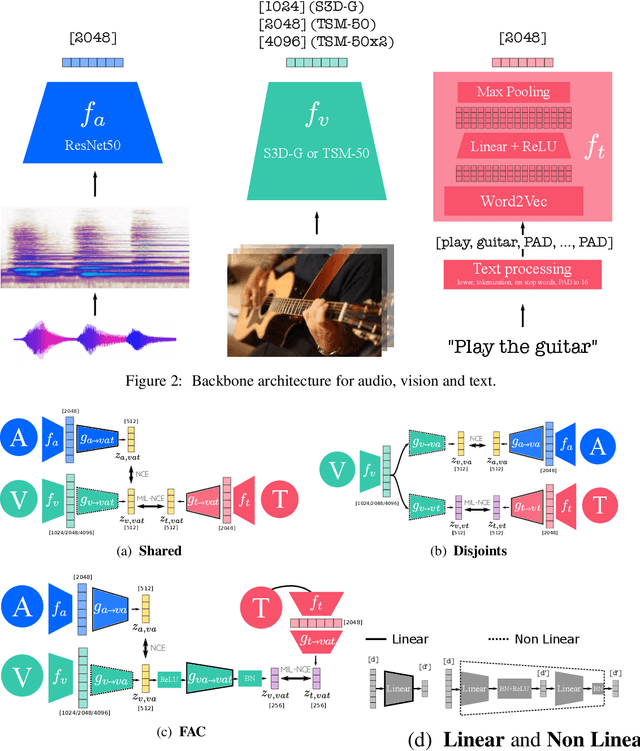
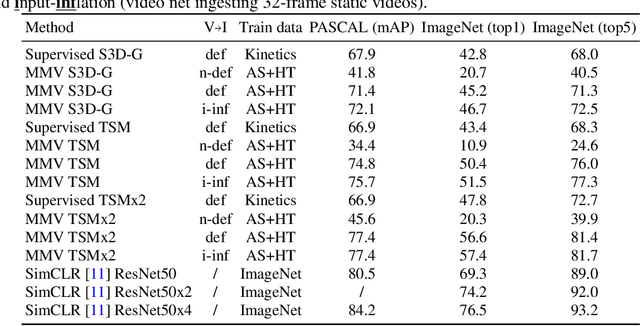
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
Improved Image Deblurring based on Salient-region Segmentation
Feb 28, 2015



Image deblurring techniques play important roles in many image processing applications. As the blur varies spatially across the image plane, it calls for robust and effective methods to deal with the spatially-variant blur problem. In this paper, a Saliency-based Deblurring (SD) approach is proposed based on the saliency detection for salient-region segmentation and a corresponding compensate method for image deblurring. We also propose a PDE-based deblurring method which introduces an anisotropic Partial Differential Equation (PDE) model for latent image prediction and employs an adaptive optimization model in the kernel estimation and deconvolution steps. Experimental results demonstrate the effectiveness of the proposed algorithm.
* This manuscript is the accepted version for Image Comm (Signal Processing: Image Communication)
comp-syn: Perceptually Grounded Word Embeddings with Color
Oct 08, 2020
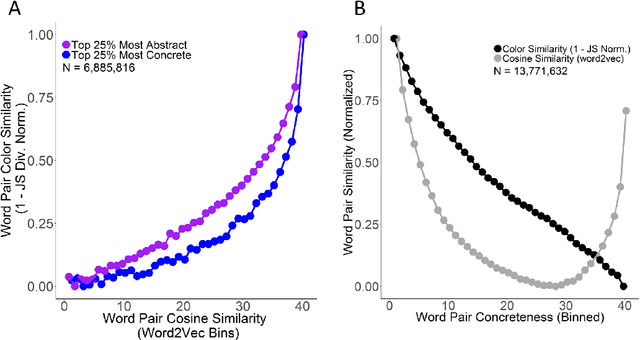
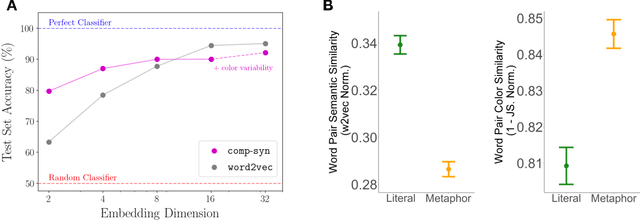

Popular approaches to natural language processing create word embeddings based on textual co-occurrence patterns, but often ignore embodied, sensory aspects of language. Here, we introduce the Python package comp-syn, which provides grounded word embeddings based on the perceptually uniform color distributions of Google Image search results. We demonstrate that comp-syn significantly enriches models of distributional semantics. In particular, we show that (1) comp-syn predicts human judgments of word concreteness with greater accuracy and in a more interpretable fashion than word2vec using low-dimensional word-color embeddings, and (2) comp-syn performs comparably to word2vec on a metaphorical vs. literal word-pair classification task. comp-syn is open-source on PyPi and is compatible with mainstream machine-learning Python packages. Our package release includes word-color embeddings for over 40,000 English words, each associated with crowd-sourced word concreteness judgments.
Zero-Shot Learning from scratch (ZFS): leveraging local compositional representations
Oct 22, 2020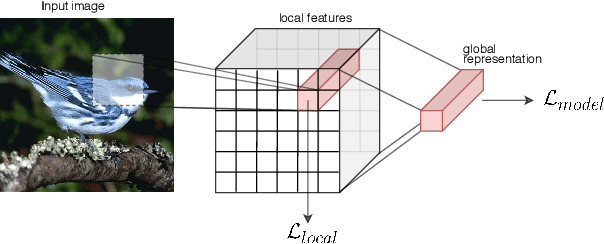
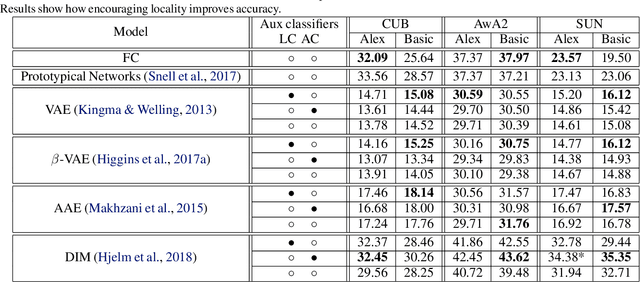
Zero-shot classification is a generalization task where no instance from the target classes is seen during training. To allow for test-time transfer, each class is annotated with semantic information, commonly in the form of attributes or text descriptions. While classical zero-shot learning does not explicitly forbid using information from other datasets, the approaches that achieve the best absolute performance on image benchmarks rely on features extracted from encoders pretrained on Imagenet. This approach relies on hyper-optimized Imagenet-relevant parameters from the supervised classification setting, entangling important questions about the suitability of those parameters and how they were learned with more fundamental questions about representation learning and generalization. To remove these distractors, we propose a more challenging setting: Zero-Shot Learning from scratch (ZFS), which explicitly forbids the use of encoders fine-tuned on other datasets. Our analysis on this setting highlights the importance of local information, and compositional representations.
Image denoising through bivariate shrinkage function in framelet domain
Jan 02, 2018

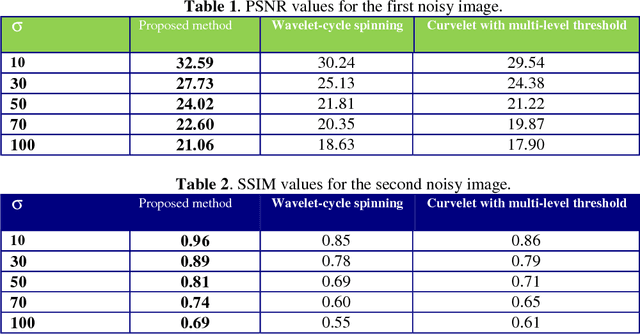
Denoising of coefficients in a sparse domain (e.g. wavelet) has been researched extensively because of its simplicity and effectiveness. Literature mainly has focused on designing the best global threshold. However, this paper proposes a new denoising method using bivariate shrinkage function in framelet domain. In the proposed method, maximum aposteriori probability is used for estimate of the denoised coefficient and non-Gaussian bivariate function is applied to model the statistics of framelet coefficients. For every framelet coefficient, there is a corresponding threshold depending on the local statistics of framelet coefficients. Experimental results show that using bivariate shrinkage function in framelet domain yields significantly superior image quality and higher PSNR than some well-known denoising methods.
Evidential Sparsification of Multimodal Latent Spaces in Conditional Variational Autoencoders
Oct 22, 2020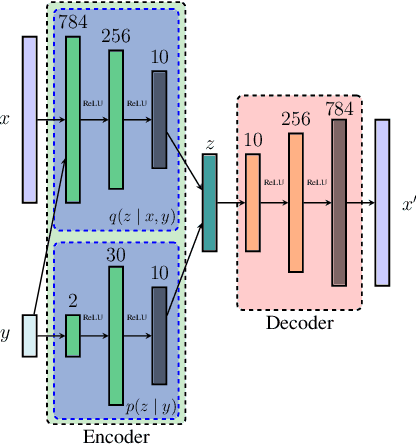
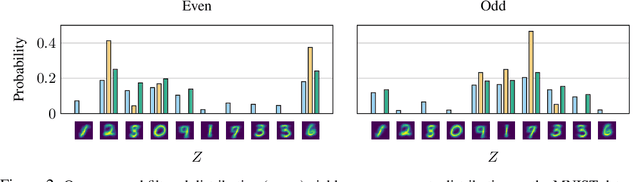
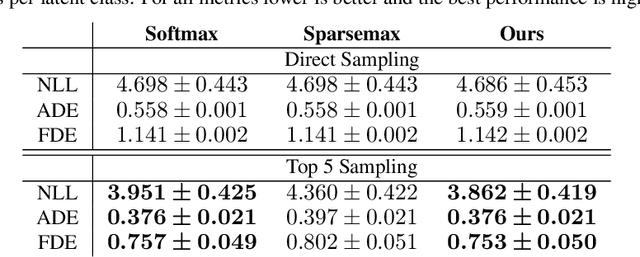
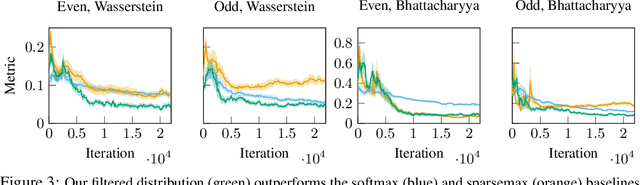
Discrete latent spaces in variational autoencoders have been shown to effectively capture the data distribution for many real-world problems such as natural language understanding, human intent prediction, and visual scene representation. However, discrete latent spaces need to be sufficiently large to capture the complexities of real-world data, rendering downstream tasks computationally challenging. For instance, performing motion planning in a high-dimensional latent representation of the environment could be intractable. We consider the problem of sparsifying the discrete latent space of a trained conditional variational autoencoder, while preserving its learned multimodality. As a post hoc latent space reduction technique, we use evidential theory to identify the latent classes that receive direct evidence from a particular input condition and filter out those that do not. Experiments on diverse tasks, such as image generation and human behavior prediction, demonstrate the effectiveness of our proposed technique at reducing the discrete latent sample space size of a model while maintaining its learned multimodality.
Learning Visual Representations for Transfer Learning by Suppressing Texture
Nov 04, 2020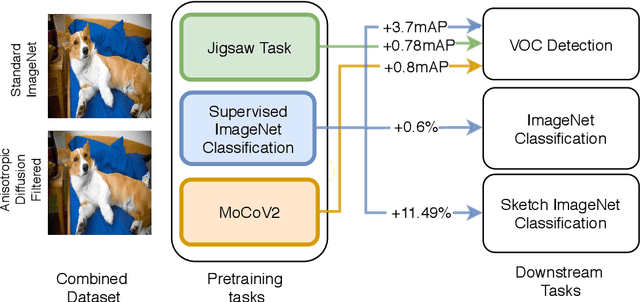
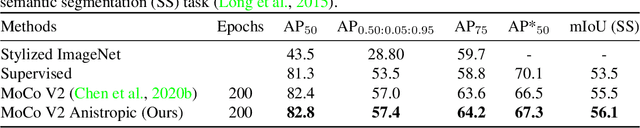

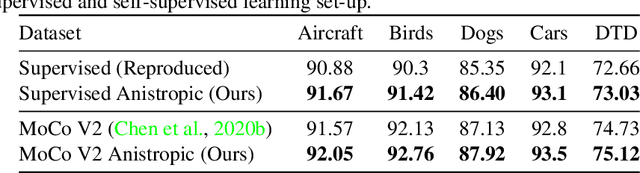
Recent literature has shown that features obtained from supervised training of CNNs may over-emphasize texture rather than encoding high-level information. In self-supervised learning in particular, texture as a low-level cue may provide shortcuts that prevent the network from learning higher level representations. To address these problems we propose to use classic methods based on anisotropic diffusion to augment training using images with suppressed texture. This simple method helps retain important edge information and suppress texture at the same time. We empirically show that our method achieves state-of-the-art results on object detection and image classification with eight diverse datasets in either supervised or self-supervised learning tasks such as MoCoV2 and Jigsaw. Our method is particularly effective for transfer learning tasks and we observed improved performance on five standard transfer learning datasets. The large improvements (up to 11.49\%) on the Sketch-ImageNet dataset, DTD dataset and additional visual analyses with saliency maps suggest that our approach helps in learning better representations that better transfer.
Text Recognition in Scene Image and Video Frame using Color Channel Selection
Jul 27, 2017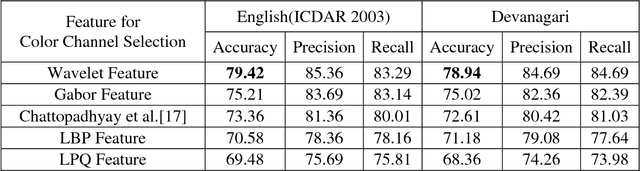
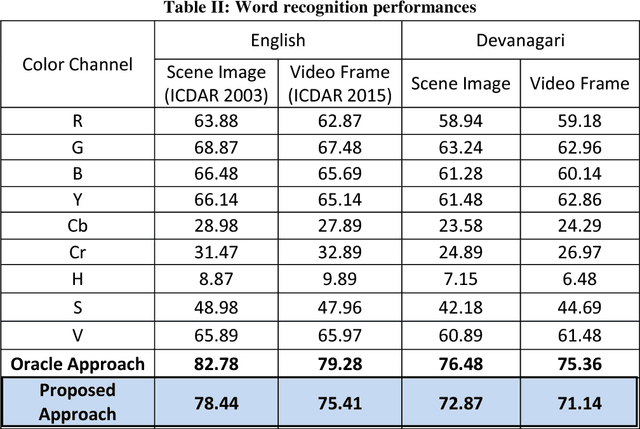
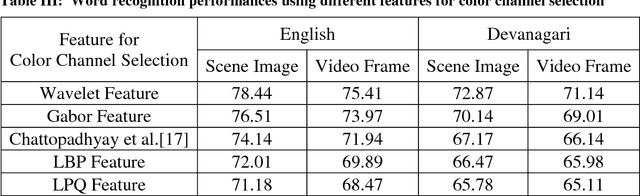
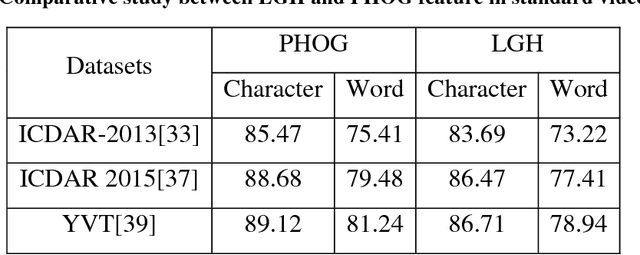
In recent years, recognition of text from natural scene image and video frame has got increased attention among the researchers due to its various complexities and challenges. Because of low resolution, blurring effect, complex background, different fonts, color and variant alignment of text within images and video frames, etc., text recognition in such scenario is difficult. Most of the current approaches usually apply a binarization algorithm to convert them into binary images and next OCR is applied to get the recognition result. In this paper, we present a novel approach based on color channel selection for text recognition from scene images and video frames. In the approach, at first, a color channel is automatically selected and then selected color channel is considered for text recognition. Our text recognition framework is based on Hidden Markov Model (HMM) which uses Pyramidal Histogram of Oriented Gradient features extracted from selected color channel. From each sliding window of a color channel our color-channel selection approach analyzes the image properties from the sliding window and then a multi-label Support Vector Machine (SVM) classifier is applied to select the color channel that will provide the best recognition results in the sliding window. This color channel selection for each sliding window has been found to be more fruitful than considering a single color channel for the whole word image. Five different features have been analyzed for multi-label SVM based color channel selection where wavelet transform based feature outperforms others. Our framework has been tested on different publicly available scene/video text image datasets. For Devanagari script, we collected our own data dataset. The performances obtained from experimental results are encouraging and show the advantage of the proposed method.