 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OccInpFlow: Occlusion-Inpainting Optical Flow Estimation by Unsupervised Learning
Jun 30, 2020
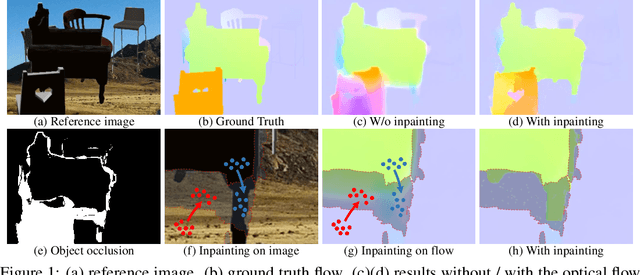
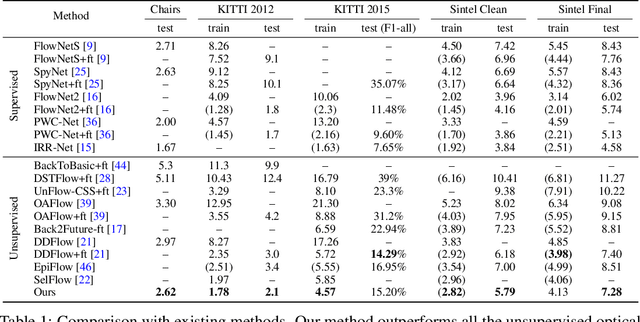
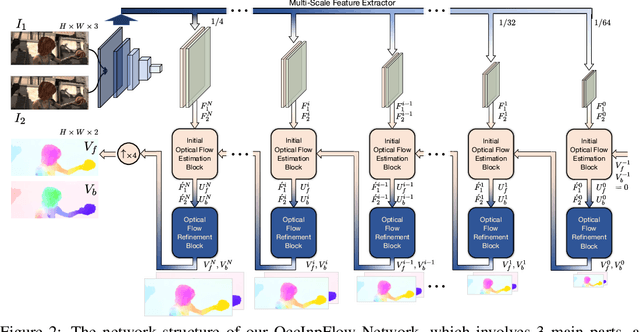
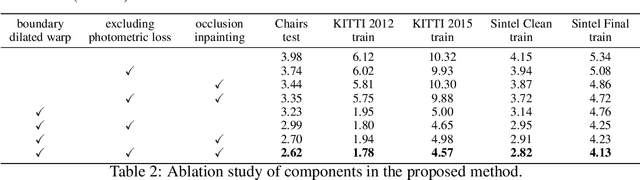
Occlusion is an inevitable and critical problem in unsupervised optical flow learning. Existing methods either treat occlusions equally as non-occluded regions or simply remove them to avoid incorrectness. However, the occlusion regions can provide effective information for optical flow learning. In this paper, we present OccInpFlow, an occlusion-inpainting framework to make full use of occlusion regions. Specifically, a new appearance-flow network is proposed to inpaint occluded flows based on the image content. Moreover, a boundary warp is proposed to deal with occlusions caused by displacement beyond image border. We conduct experiments on multiple leading flow benchmark data sets such as Flying Chairs, KITTI and MPI-Sintel, which demonstrate that the performance is significantly improved by our proposed occlusion handling framework.
RGBD-Net: Predicting color and depth images for novel views synthesis
Nov 29, 2020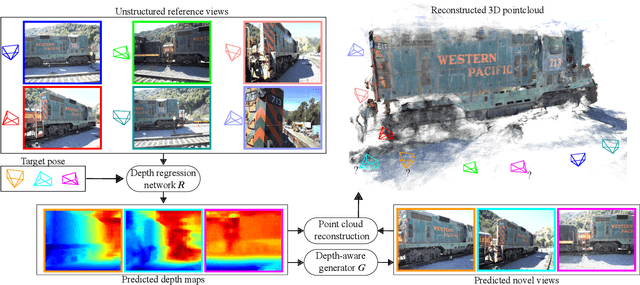
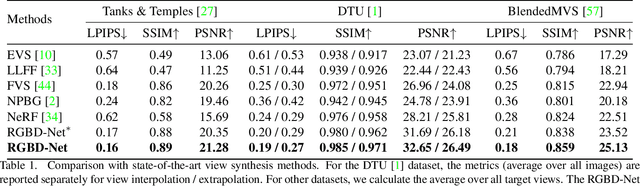
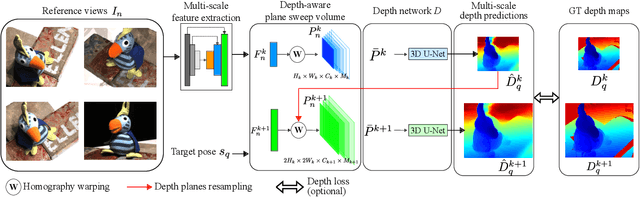
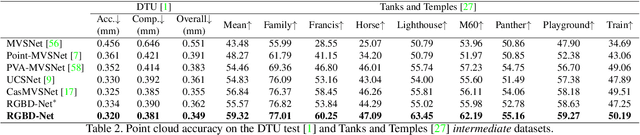
We address the problem of novel view synthesis from an unstructured set of reference images. A new method called RGBD-Net is proposed to predict the depth map and the color images at the target pose in a multi-scale manner. The reference views are warped to the target pose to obtain multi-scale plane sweep volumes, which are then passed to our first module, a hierarchical depth regression network which predicts the depth map of the novel view. Second, a depth-aware generator network refines the warped novel views and renders the final target image. These two networks can be trained with or without depth supervision. In experimental evaluation, RGBD-Net not only produces novel views with higher quality than the previous state-of-the-art methods, but also the obtained depth maps enable reconstruction of more accurate 3D point clouds than the existing multi-view stereo methods. The results indicate that RGBD-Net generalizes well to previously unseen data.
AudioViewer: Learning to Visualize Sound
Dec 22, 2020



Sensory substitution can help persons with perceptual deficits. In this work, we attempt to visualize audio with video. Our long-term goal is to create sound perception for hearing impaired people, for instance, to facilitate feedback for training deaf speech. Different from existing models that translate between speech and text or text and images, we target an immediate and low-level translation that applies to generic environment sounds and human speech without delay. No canonical mapping is known for this artificial translation task. Our design is to translate from audio to video by compressing both into a common latent space with shared structure. Our core contribution is the development and evaluation of learned mappings that respect human perception limits and maximize user comfort by enforcing priors and combining strategies from unpaired image translation and disentanglement. We demonstrate qualitatively and quantitatively that our AudioViewer model maintains important audio features in the generated video and that generated videos of faces and numbers are well suited for visualizing high-dimensional audio features since they can easily be parsed by humans to match and distinguish between sounds, words, and speakers.
CoDeNet: Algorithm-hardware Co-design for Deformable Convolution
Jun 12, 2020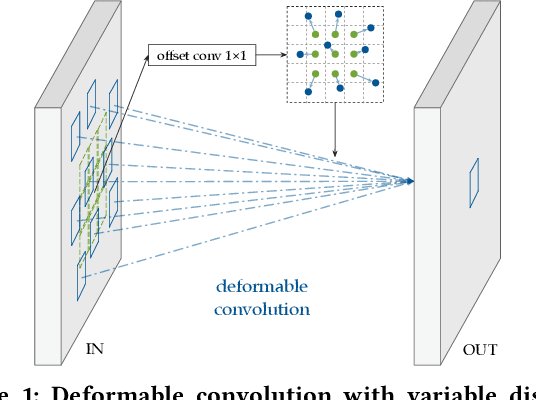
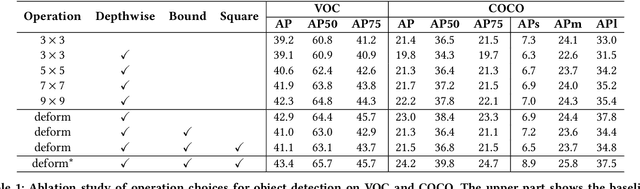
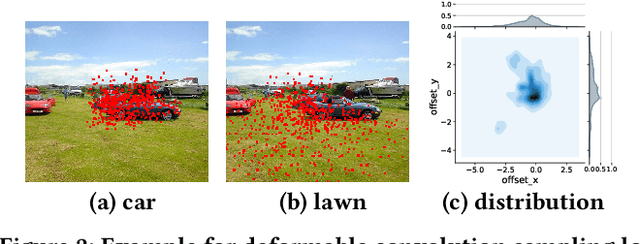
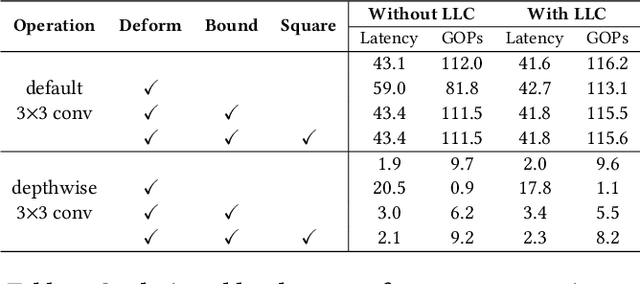
Deploying deep learning models on embedded systems for computer vision tasks has been challenging due to limited compute resources and strict energy budgets. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, such as object detection, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolution may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and introduce a depthwise deformable convolution to reduce the total number of operations required. We then show the speed-accuracy tradeoffs for a set of algorithm modifications including irregular-access versus limited-range and fixed-shape. We evaluate these algorithmic changes with corresponding hardware optimizations. Results show a 1.36x and 9.76x speedup respectively for the full and depthwise deformable convolution on the embedded FPGA accelerator with minor accuracy loss on the object detection task. We then co-design an efficient network CoDeNet with the modified deformable convolution for object detection and quantize the network to 4-bit weights and 8-bit activations. Results show that our designs lie on the pareto-optimal front of the latency-accuracy tradeoff for the object detection task on embedded FPGAs
There and Back Again: Learning to Simulate Radar Data for Real-World Applications
Nov 29, 2020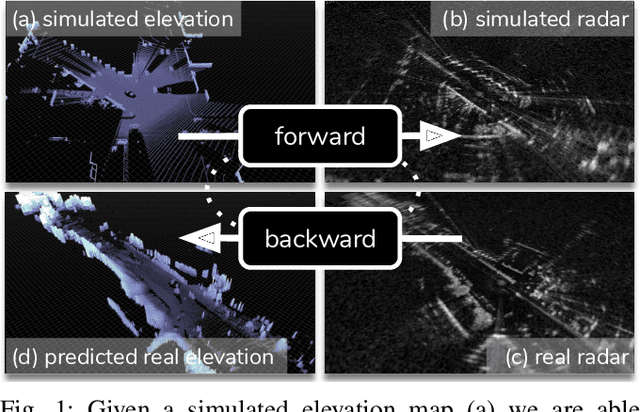

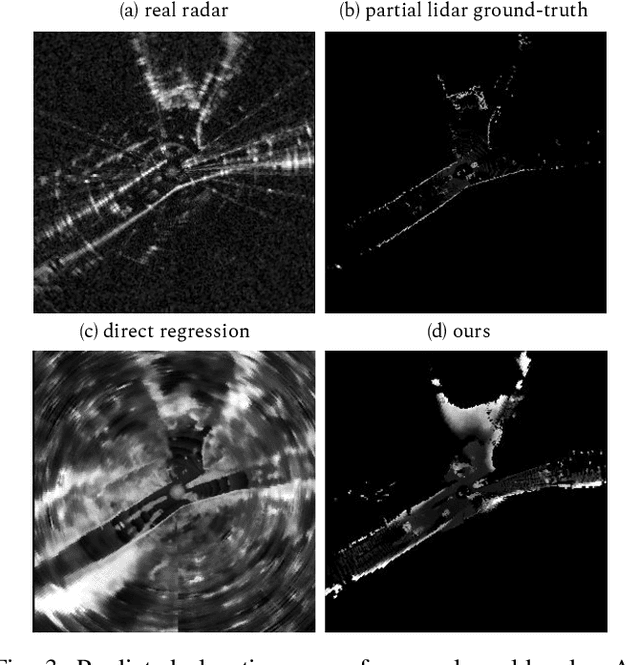
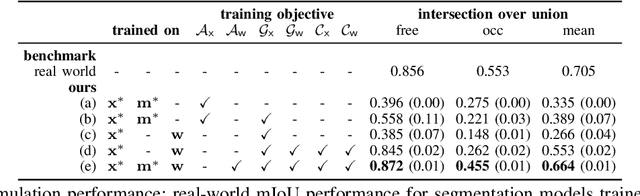
Simulating realistic radar data has the potential to significantly accelerate the development of data-driven approaches to radar processing. However, it is fraught with difficulty due to the notoriously complex image formation process. Here we propose to learn a radar sensor model capable of synthesising faithful radar observations based on simulated elevation maps. In particular, we adopt an adversarial approach to learning a forward sensor model from unaligned radar examples. In addition, modelling the backward model encourages the output to remain aligned to the world state through a cyclical consistency criterion. The backward model is further constrained to predict elevation maps from real radar data that are grounded by partial measurements obtained from corresponding lidar scans. Both models are trained in a joint optimisation. We demonstrate the efficacy of our approach by evaluating a down-stream segmentation model trained purely on simulated data in a real-world deployment. This achieves performance within four percentage points of the same model trained entirely on real data.
Dynamic radiomics: a new methodology to extract quantitative time-related features from tomographic images
Nov 01, 2020
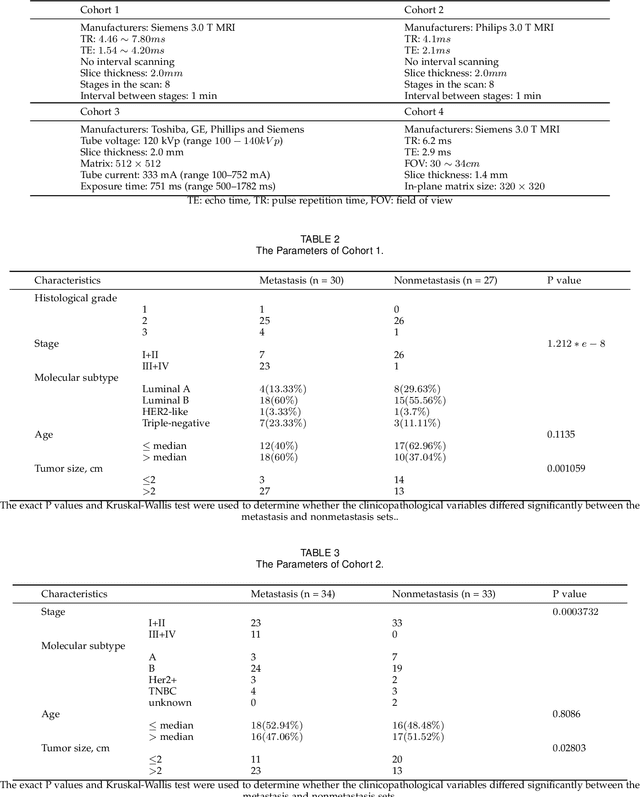
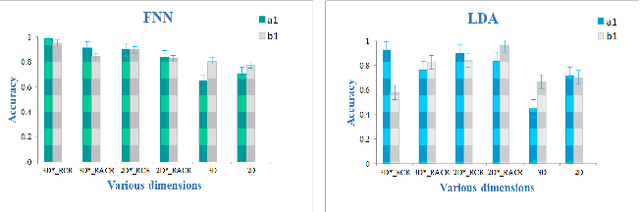
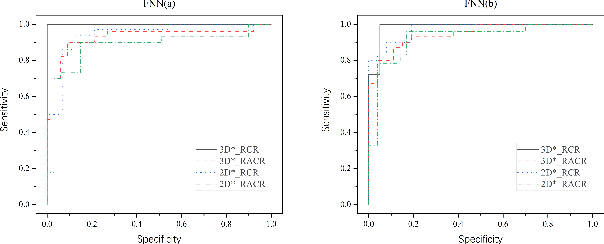
The feature extraction methods of radiomics are mainly based on static tomographic images at a certain moment, while the occurrence and development of disease is a dynamic process that cannot be fully reflected by only static characteristics. This study proposes a new dynamic radiomics feature extraction workflow that uses time-dependent tomographic images of the same patient, focuses on the changes in image features over time, and then quantifies them as new dynamic features for diagnostic or prognostic evaluation. We first define the mathematical paradigm of dynamic radiomics and introduce three specific methods that can describe the transformation process of features over time. Three different clinical problems are used to validate the performance of the proposed dynamic feature with conventional 2D and 3D static features.
Compressed Sensing with Deep Image Prior and Learned Regularization
Jun 17, 2018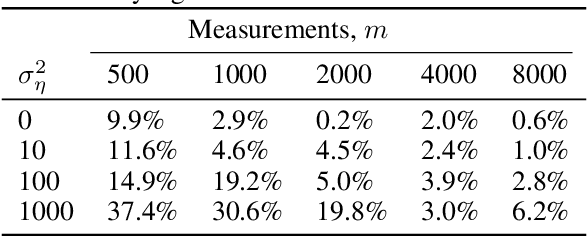
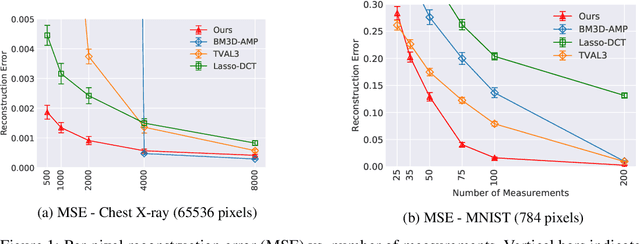

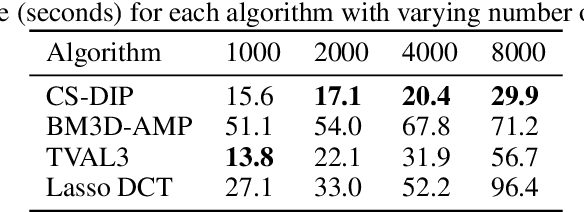
We propose a novel method for compressed sensing recovery using untrained deep generative models. Our method is based on the recently proposed Deep Image Prior (DIP), wherein the convolutional weights of the network are optimized to match the observed measurements. We show that this approach can be applied to solve any differentiable inverse problem. We also introduce a novel learned regularization technique which incorporates a small amount of prior information, further reducing the number of measurements required for a given reconstruction error. Our algorithm requires approximately 4-6x fewer measurements than classical Lasso methods. Unlike previous approaches based on generative models, our method does not require the model to be pre-trained. As such, we can apply our method to various medical imaging datasets for which data acquisition is expensive and no known generative models exist.
Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts
Jan 11, 2021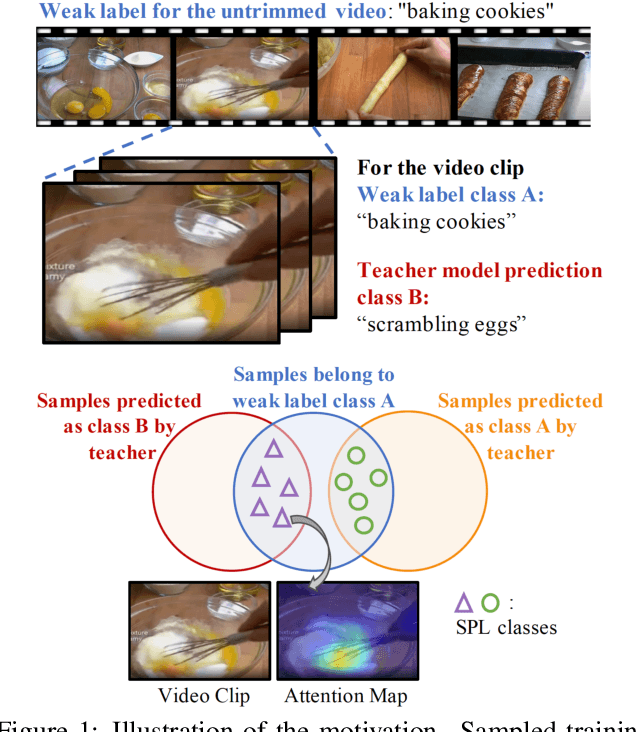
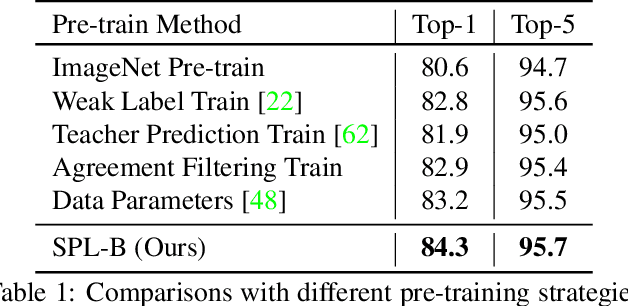
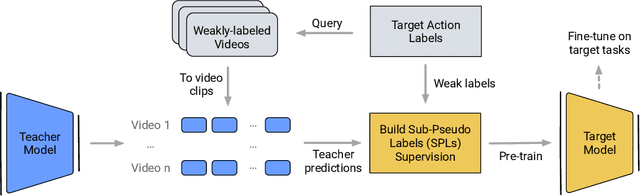
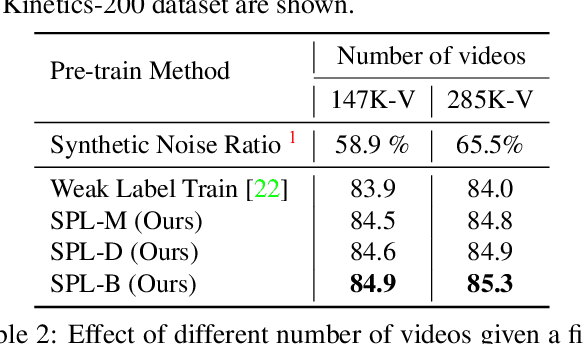
Learning visual knowledge from massive weakly-labeled web videos has attracted growing research interests thanks to the large corpus of easily accessible video data on the Internet. However, for video action recognition, the action of interest might only exist in arbitrary clips of untrimmed web videos, resulting in high label noises in the temporal space. To address this issue, we introduce a new method for pre-training video action recognition models using queried web videos. Instead of trying to filter out, we propose to convert the potential noises in these queried videos to useful supervision signals by defining the concept of Sub-Pseudo Label (SPL). Specifically, SPL spans out a new set of meaningful "middle ground" label space constructed by extrapolating the original weak labels during video querying and the prior knowledge distilled from a teacher model. Consequently, SPL provides enriched supervision for video models to learn better representations. SPL is fairly simple and orthogonal to popular teacher-student self-training frameworks without extra training cost. We validate the effectiveness of our method on four video action recognition datasets and a weakly-labeled image dataset to study the generalization ability. Experiments show that SPL outperforms several existing pre-training strategies using pseudo-labels and the learned representations lead to competitive results when fine-tuning on HMDB-51 and UCF-101 compared with recent pre-training methods.
RENATA: REpreseNtation And Training Alteration for Bias Mitigation
Dec 11, 2020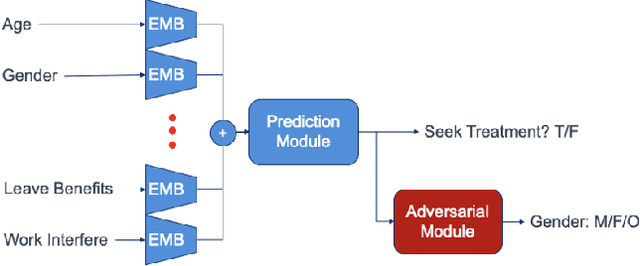
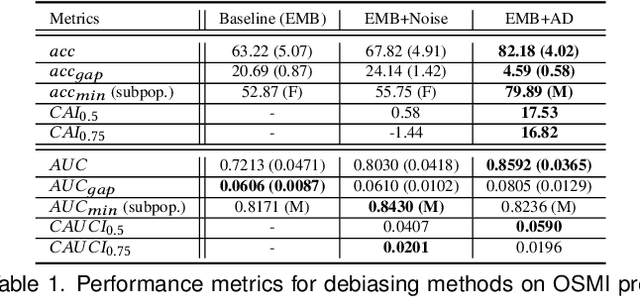
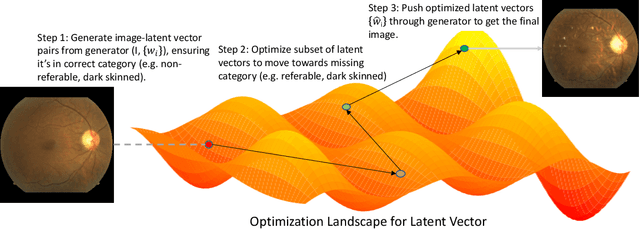
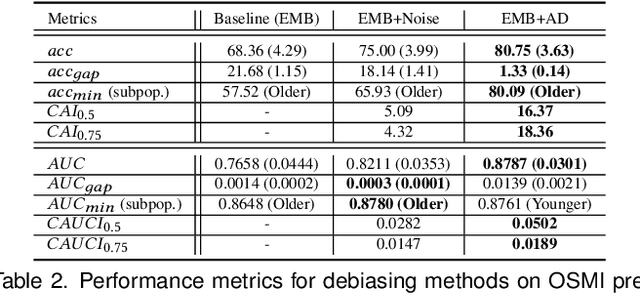
We propose a novel method for enforcing AI fairness with respect to protected or sensitive factors. This method uses a dual strategy performing Training And Representation Alteration (RENATA) for mitigation of two of the most prominent causes of AI bias, including: a) the use of representation learning alteration via adversarial independence, to suppress the bias-inducing dependence of the data representation from protected factors; and b) training set alteration via intelligent augmentation, to address bias-causing data imbalance, by using generative models that allow fine control of sensitive factors related to underrepresented populations. When testing our methods on image analytics, experiments demonstrate that RENATA significantly or fully debiases baseline models while outperforming competing debiasing methods, e.g., with (% overall accuracy, % accuracy gap) of (78.75, 0.5) vs. baseline method's (71.75, 10.5) for EyePACS, and (73.71, 11.82) vs. the (69.08, 21.65) baseline for CelebA. As an additional contribution, recognizing certain limitations in current metrics used for assessing debiasing performance, this study proposes novel conjunctive debiasing metrics. Our experiments also demonstrate the ability of these novel metrics in assessing the Pareto efficiency of the proposed methods.
Fast Shadow Detection from a Single Image Using a Patched Convolutional Neural Network
Mar 16, 2018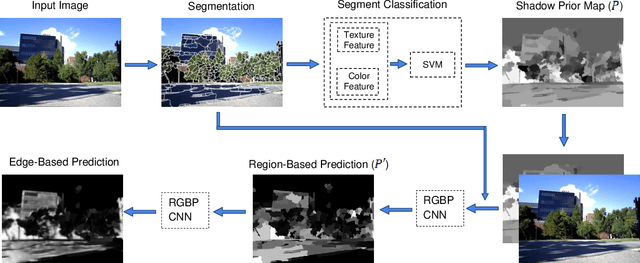



In recent years, various shadow detection methods from a single image have been proposed and used in vision systems; however, most of them are not appropriate for the robotic applications due to the expensive time complexity. This paper introduces a fast shadow detection method using a deep learning framework, with a time cost that is appropriate for robotic applications. In our solution, we first obtain a shadow prior map with the help of multi-class support vector machine using statistical features. Then, we use a semantic- aware patch-level Convolutional Neural Network that efficiently trains on shadow examples by combining the original image and the shadow prior map. Experiments on benchmark datasets demonstrate the proposed method significantly decreases the time complexity of shadow detection, by one or two orders of magnitude compared with state-of-the-art methods, without losing accuracy.