 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive convolutional neural networks for k-space data interpolation in fast magnetic resonance imaging
Jun 02, 2020
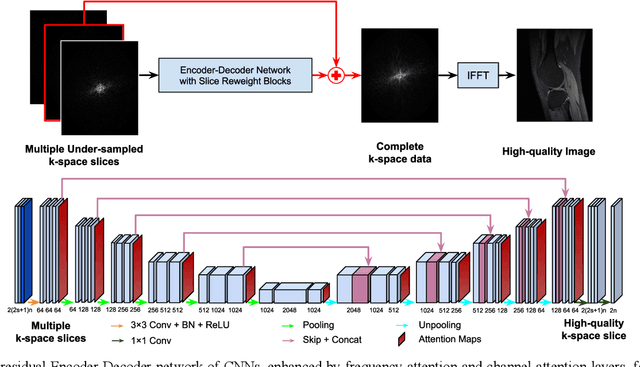
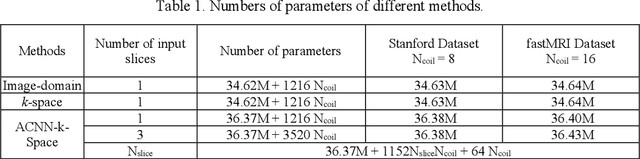
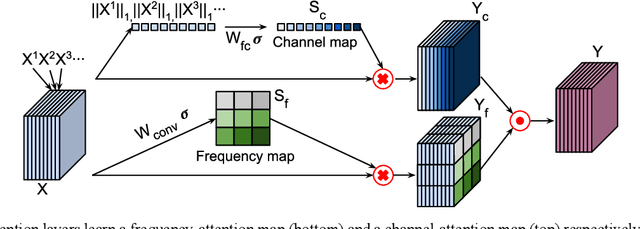
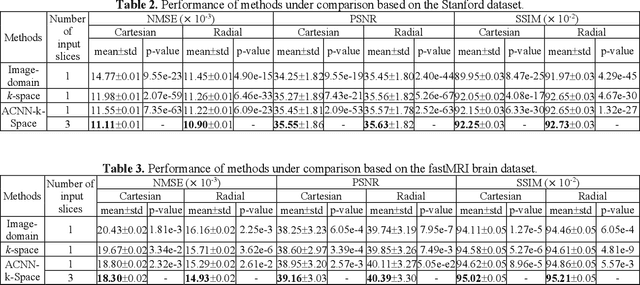
Deep learning in k-space has demonstrated great potential for image reconstruction from undersampled k-space data in fast magnetic resonance imaging (MRI). However, existing deep learning-based image reconstruction methods typically apply weight-sharing convolutional neural networks (CNNs) to k-space data without taking into consideration the k-space data's spatial frequency properties, leading to ineffective learning of the image reconstruction models. Moreover, complementary information of spatially adjacent slices is often ignored in existing deep learning methods. To overcome such limitations, we develop a deep learning algorithm, referred to as adaptive convolutional neural networks for k-space data interpolation (ACNN-k-Space), which adopts a residual Encoder-Decoder network architecture to interpolate the undersampled k-space data by integrating spatially contiguous slices as multi-channel input, along with k-space data from multiple coils if available. The network is enhanced by self-attention layers to adaptively focus on k-space data at different spatial frequencies and channels. We have evaluated our method on two public datasets and compared it with state-of-the-art existing methods. Ablation studies and experimental results demonstrate that our method effectively reconstructs images from undersampled k-space data and achieves significantly better image reconstruction performance than current state-of-the-art techniques.
Generative Adversarial Stacked Autoencoders
Nov 22, 2020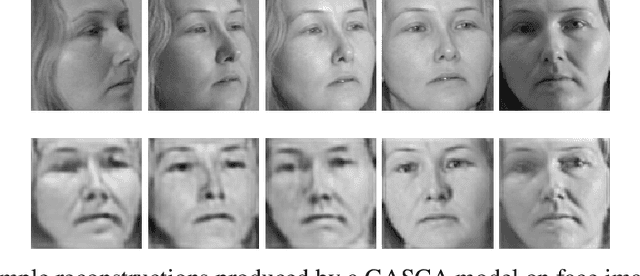
Generative Adversarial Networks (GANs) have become predominant in image generation tasks. Their success is attributed to the training regime which employs two models: a generator G and discriminator D that compete in a minimax zero sum game. Nonetheless, GANs are difficult to train due to their sensitivity to hyperparameter and parameter initialisation, which often leads to vanishing gradients, non-convergence, or mode collapse, where the generator is unable to create samples with different variations. In this work, we propose a novel Generative Adversarial Stacked Convolutional Autoencoder(GASCA) model and a generative adversarial gradual greedy layer-wise learning algorithm de-signed to train Adversarial Autoencoders in an efficient and incremental manner. Our training approach produces images with significantly lower reconstruction error than vanilla joint training.
* arXiv admin note: text overlap with arXiv:2007.09790
Mining Objects: Fully Unsupervised Object Discovery and Localization From a Single Image
Feb 26, 2019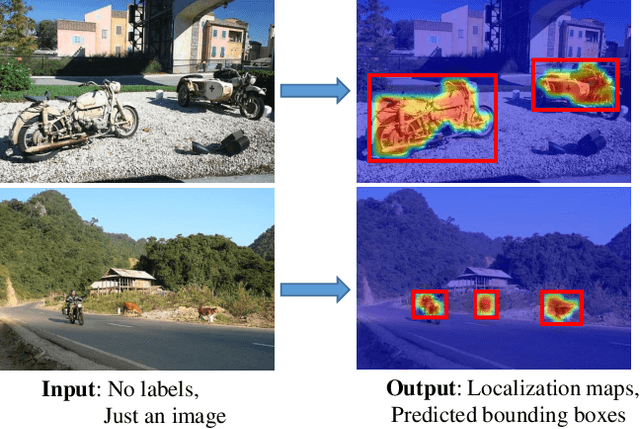
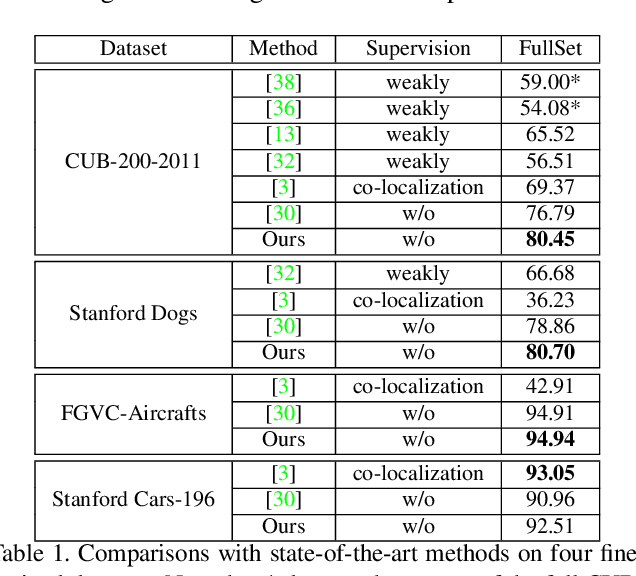
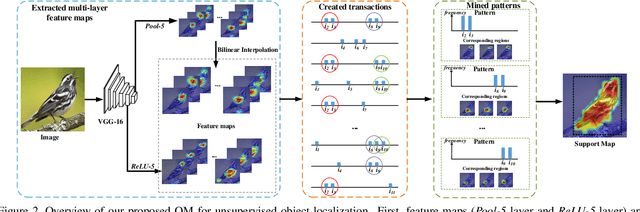
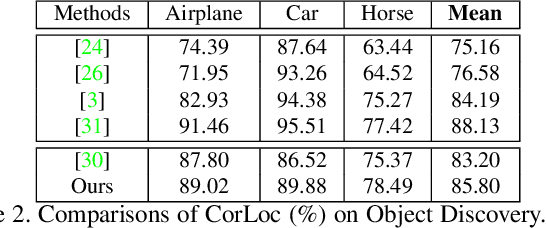
The goal of our work is to discover dominant objects without using any annotations. We focus on performing unsupervised object discovery and localization in a strictly general setting where only a single image is given. This is far more challenge than typical co-localization or weakly-supervised localization tasks. To tackle this problem, we propose a simple but effective pattern mining-based method, called Object Mining (OM), which exploits the ad-vantages of data mining and feature representation of pre-trained convolutional neural networks (CNNs). Specifically,Object Mining first converts the feature maps from a pre-trained CNN model into a set of transactions, and then frequent patterns are discovered from transaction data base through pattern mining techniques. We observe that those discovered patterns, i.e., co-occurrence highlighted regions,typically hold appearance and spatial consistency. Motivated by this observation, we can easily discover and localize possible objects by merging relevant meaningful pat-terns in an unsupervised manner. Extensive experiments on a variety of benchmarks demonstrate that Object Mining achieves competitive performance compared with the state-of-the-art methods.
Concatenated image completion via tensor augmentation and completion
Jul 14, 2016
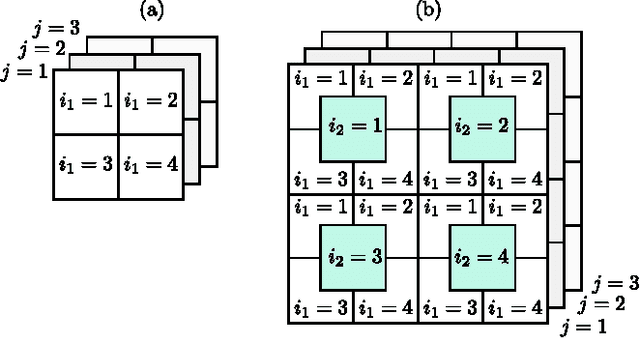


This paper proposes a novel framework called concatenated image completion via tensor augmentation and completion (ICTAC), which recovers missing entries of color images with high accuracy. Typical images are second- or third-order tensors (2D/3D) depending if they are grayscale or color, hence tensor completion algorithms are ideal for their recovery. The proposed framework performs image completion by concatenating copies of a single image that has missing entries into a third-order tensor, applying a dimensionality augmentation technique to the tensor, utilizing a tensor completion algorithm for recovering its missing entries, and finally extracting the recovered image from the tensor. The solution relies on two key components that have been recently proposed to take advantage of the tensor train (TT) rank: A tensor augmentation tool called ket augmentation (KA) that represents a low-order tensor by a higher-order tensor, and the algorithm tensor completion by parallel matrix factorization via tensor train (TMac-TT), which has been demonstrated to outperform state-of-the-art tensor completion algorithms. Simulation results for color image recovery show the clear advantage of our framework against current state-of-the-art tensor completion algorithms.
Guided Fine-Tuning for Large-Scale Material Transfer
Jul 08, 2020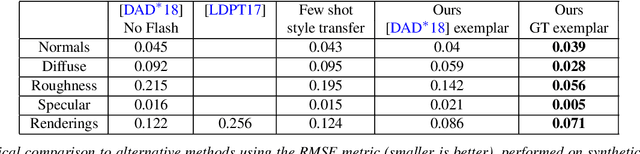
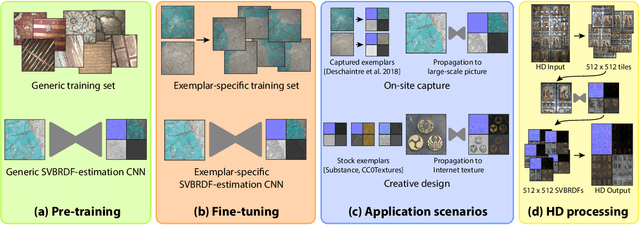
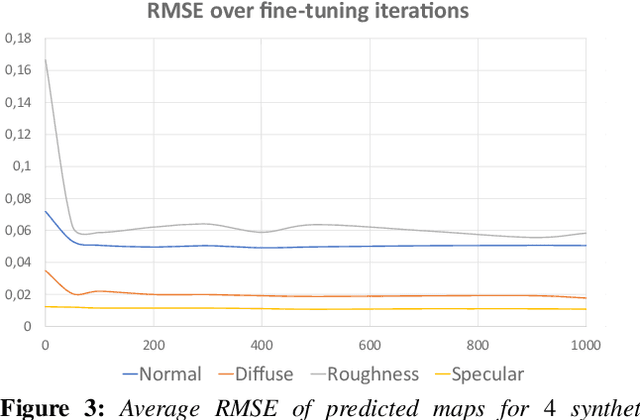

We present a method to transfer the appearance of one or a few exemplar SVBRDFs to a target image representing similar materials. Our solution is extremely simple: we fine-tune a deep appearance-capture network on the provided exemplars, such that it learns to extract similar SVBRDF values from the target image. We introduce two novel material capture and design workflows that demonstrate the strength of this simple approach. Our first workflow allows to produce plausible SVBRDFs of large-scale objects from only a few pictures. Specifically, users only need take a single picture of a large surface and a few close-up flash pictures of some of its details. We use existing methods to extract SVBRDF parameters from the close-ups, and our method to transfer these parameters to the entire surface, enabling the lightweight capture of surfaces several meters wide such as murals, floors and furniture. In our second workflow, we provide a powerful way for users to create large SVBRDFs from internet pictures by transferring the appearance of existing, pre-designed SVBRDFs. By selecting different exemplars, users can control the materials assigned to the target image, greatly enhancing the creative possibilities offered by deep appearance capture.
Polarimetric Convolutional Network for PolSAR Image Classification
Jul 09, 2018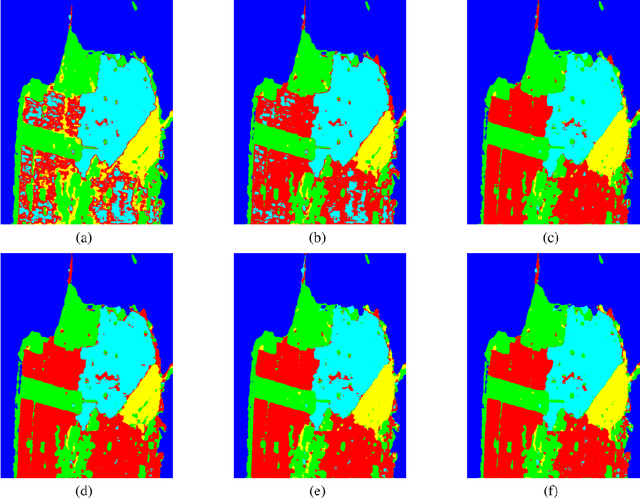
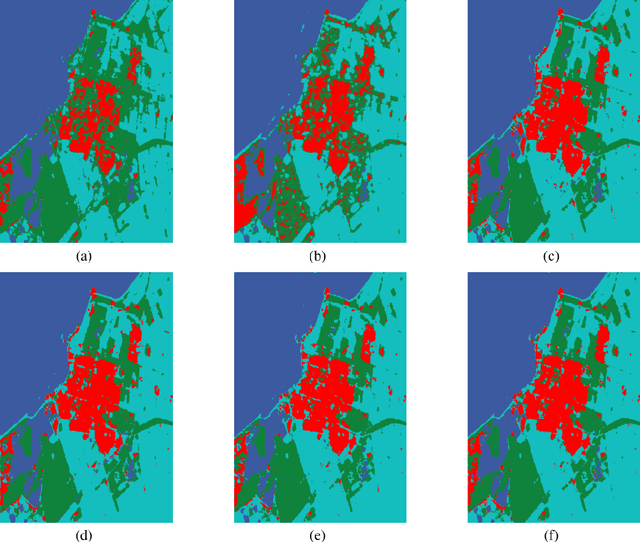
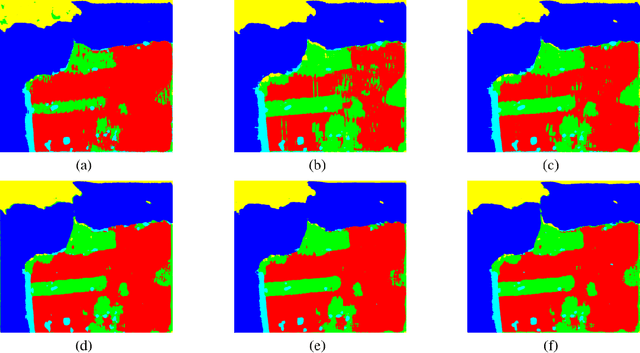
The approaches for analyzing the polarimetric scattering matrix of polarimetric synthetic aperture radar (PolSAR) data have always been the focus of PolSAR image classification. Generally, the polarization coherent matrix and the covariance matrix obtained by the polarimetric scattering matrix only show a limited number of polarimetric information. In order to solve this problem, we propose a sparse scattering coding way to deal with polarimetric scattering matrix and obtain a close complete feature. This encoding mode can also maintain polarimetric information of scattering matrix completely. At the same time, in view of this encoding way, we design a corresponding classification algorithm based on convolution network to combine this feature. Based on sparse scattering coding and convolution neural network, the polarimetric convolutional network is proposed to classify PolSAR images by making full use of polarimetric information. We perform the experiments on the PolSAR images acquired by AIRSAR and RADARSAT-2 to verify the proposed method. The experimental results demonstrate that the proposed method get better results and has huge potential for PolSAR data classification. Source code for sparse scattering coding is available at https://github.com/liuxuvip/Polarimetric-Scattering-Coding.
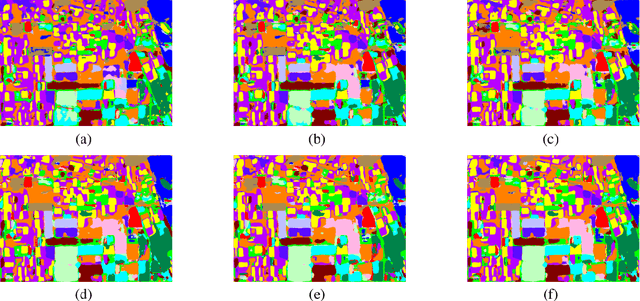
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Dec 31, 2020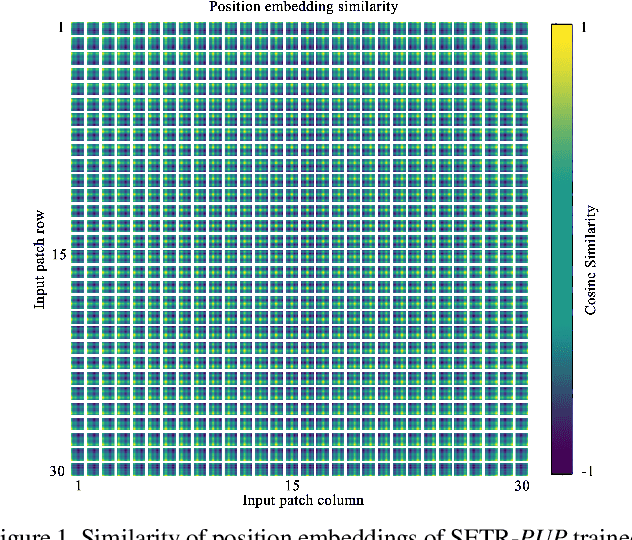



Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.
DOOBNet: Deep Object Occlusion Boundary Detection from an Image
Sep 13, 2018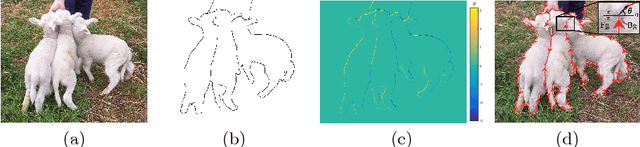

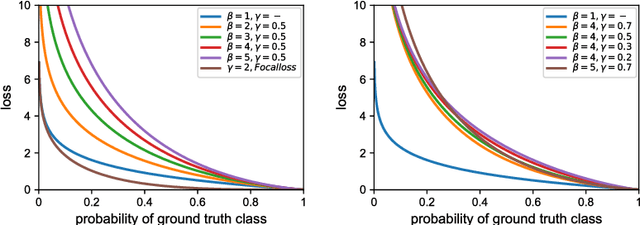

Object occlusion boundary detection is a fundamental and crucial research problem in computer vision. This is challenging to solve as encountering the extreme boundary/non-boundary class imbalance during training an object occlusion boundary detector. In this paper, we propose to address this class imbalance by up-weighting the loss contribution of false negative and false positive examples with our novel Attention Loss function. We also propose a unified end-to-end multi-task deep object occlusion boundary detection network (DOOBNet) by sharing convolutional features to simultaneously predict object boundary and occlusion orientation. DOOBNet adopts an encoder-decoder structure with skip connection in order to automatically learn multi-scale and multi-level features. We significantly surpass the state-of-the-art on the PIOD dataset (ODS F-score of .702) and the BSDS ownership dataset (ODS F-score of .555), as well as improving the detecting speed to as 0.037s per image on the PIOD dataset.
Porosity Amount Estimation in Stones Based on Combination of One Dimensional Local Binary Patterns and Image Normalization Technique
Oct 13, 2018Since now, many approaches has been proposed for surface defect detection based on image texture analysis techniques. One of the efficient texture analysis operations is local binary patterns which provides good accuracy.
High-resolution medical image synthesis using progressively grown generative adversarial networks
May 09, 2018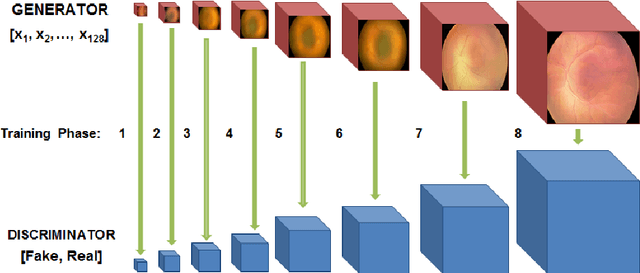
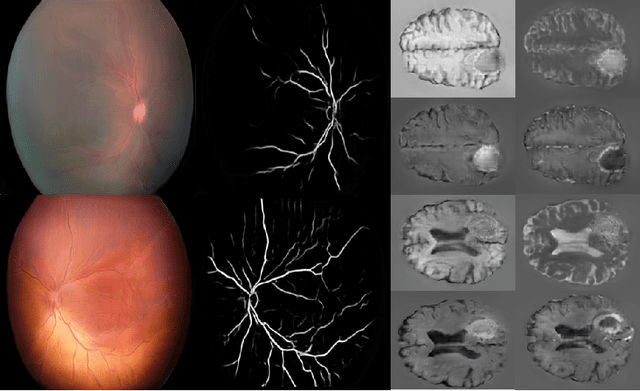
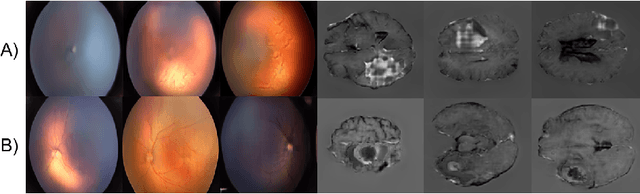
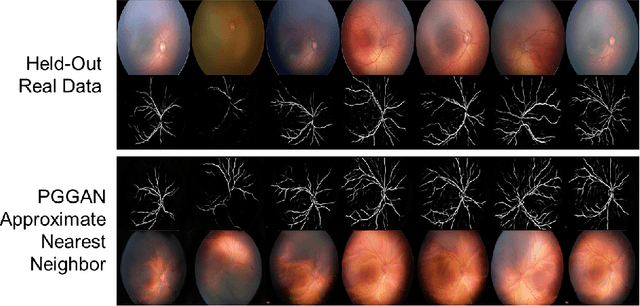
Generative adversarial networks (GANs) are a class of unsupervised machine learning algorithms that can produce realistic images from randomly-sampled vectors in a multi-dimensional space. Until recently, it was not possible to generate realistic high-resolution images using GANs, which has limited their applicability to medical images that contain biomarkers only detectable at native resolution. Progressive growing of GANs is an approach wherein an image generator is trained to initially synthesize low resolution synthetic images (8x8 pixels), which are then fed to a discriminator that distinguishes these synthetic images from real downsampled images. Additional convolutional layers are then iteratively introduced to produce images at twice the previous resolution until the desired resolution is reached. In this work, we demonstrate that this approach can produce realistic medical images in two different domains; fundus photographs exhibiting vascular pathology associated with retinopathy of prematurity (ROP), and multi-modal magnetic resonance images of glioma. We also show that fine-grained details associated with pathology, such as retinal vessels or tumor heterogeneity, can be preserved and enhanced by including segmentation maps as additional channels. We envisage several applications of the approach, including image augmentation and unsupervised classification of pathology.