 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of SVBRDF Prediction from Generative Image Models for Appearance Modeling of 3D Scenes
Dec 15, 2025Digital content creation is experiencing a profound change with the advent of deep generative models. For texturing, conditional image generators now allow the synthesis of realistic RGB images of a 3D scene that align with the geometry of that scene. For appearance modeling, SVBRDF prediction networks recover material parameters from RGB images. Combining these technologies allows us to quickly generate SVBRDF maps for multiple views of a 3D scene, which can be merged to form a SVBRDF texture atlas of that scene. In this paper, we analyze the challenges and opportunities for SVBRDF prediction in the context of such a fast appearance modeling pipeline. On the one hand, single-view SVBRDF predictions might suffer from multiview incoherence and yield inconsistent texture atlases. On the other hand, generated RGB images, and the different modalities on which they are conditioned, can provide additional information for SVBRDF estimation compared to photographs. We compare neural architectures and conditions to identify designs that achieve high accuracy and coherence. We find that, surprisingly, a standard UNet is competitive with more complex designs. Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation
* Project page: http://repo-sam.inria.fr/nerphys/svbrdf-evaluation Code: http://github.com/graphdeco-inria/svbrdf-evaluation
Splat and Replace: 3D Reconstruction with Repetitive Elements
Jun 06, 2025We leverage repetitive elements in 3D scenes to improve novel view synthesis. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly improved novel view synthesis but renderings of unseen and occluded parts remain low-quality if the training views are not exhaustive enough. Our key observation is that our environment is often full of repetitive elements. We propose to leverage those repetitions to improve the reconstruction of low-quality parts of the scene due to poor coverage and occlusions. We propose a method that segments each repeated instance in a 3DGS reconstruction, registers them together, and allows information to be shared among instances. Our method improves the geometry while also accounting for appearance variations across instances. We demonstrate our method on a variety of synthetic and real scenes with typical repetitive elements, leading to a substantial improvement in the quality of novel view synthesis.
On-the-fly Reconstruction for Large-Scale Novel View Synthesis from Unposed Images
Jun 05, 2025



Radiance field methods such as 3D Gaussian Splatting (3DGS) allow easy reconstruction from photos, enabling free-viewpoint navigation. Nonetheless, pose estimation using Structure from Motion and 3DGS optimization can still each take between minutes and hours of computation after capture is complete. SLAM methods combined with 3DGS are fast but struggle with wide camera baselines and large scenes. We present an on-the-fly method to produce camera poses and a trained 3DGS immediately after capture. Our method can handle dense and wide-baseline captures of ordered photo sequences and large-scale scenes. To do this, we first introduce fast initial pose estimation, exploiting learned features and a GPU-friendly mini bundle adjustment. We then introduce direct sampling of Gaussian primitive positions and shapes, incrementally spawning primitives where required, significantly accelerating training. These two efficient steps allow fast and robust joint optimization of poses and Gaussian primitives. Our incremental approach handles large-scale scenes by introducing scalable radiance field construction, progressively clustering 3DGS primitives, storing them in anchors, and offloading them from the GPU. Clustered primitives are progressively merged, keeping the required scale of 3DGS at any viewpoint. We evaluate our solution on a variety of datasets and show that our solution can provide on-the-fly processing of all the capture scenarios and scene sizes we target while remaining competitive with other methods that only handle specific capture styles or scene sizes in speed, image quality, or both.
Does 3D Gaussian Splatting Need Accurate Volumetric Rendering?
Feb 26, 2025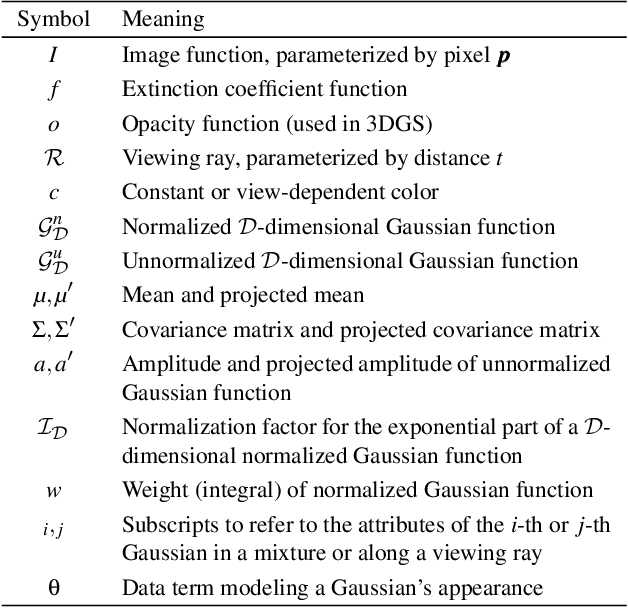
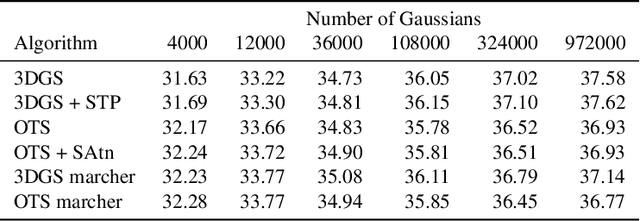
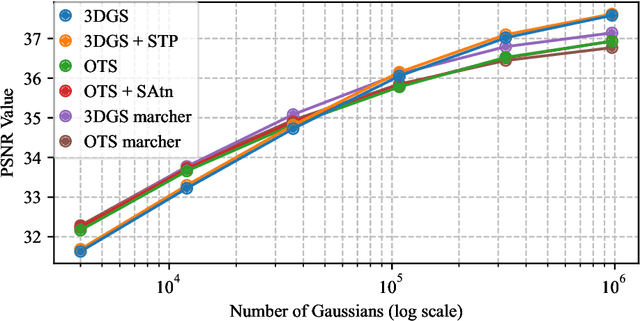
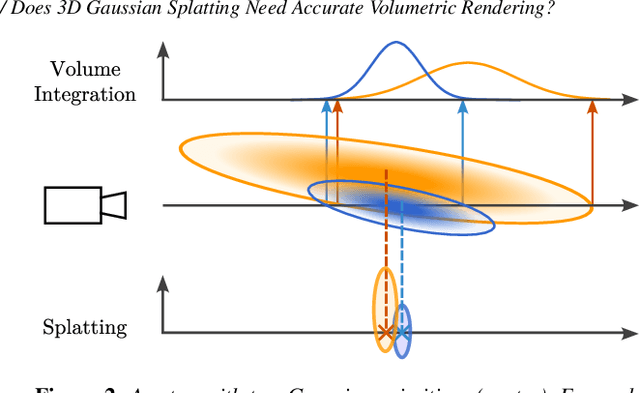
Since its introduction, 3D Gaussian Splatting (3DGS) has become an important reference method for learning 3D representations of a captured scene, allowing real-time novel-view synthesis with high visual quality and fast training times. Neural Radiance Fields (NeRFs), which preceded 3DGS, are based on a principled ray-marching approach for volumetric rendering. In contrast, while sharing a similar image formation model with NeRF, 3DGS uses a hybrid rendering solution that builds on the strengths of volume rendering and primitive rasterization. A crucial benefit of 3DGS is its performance, achieved through a set of approximations, in many cases with respect to volumetric rendering theory. A naturally arising question is whether replacing these approximations with more principled volumetric rendering solutions can improve the quality of 3DGS. In this paper, we present an in-depth analysis of the various approximations and assumptions used by the original 3DGS solution. We demonstrate that, while more accurate volumetric rendering can help for low numbers of primitives, the power of efficient optimization and the large number of Gaussians allows 3DGS to outperform volumetric rendering despite its approximations.
A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis
Sep 17, 2024Relighting radiance fields is severely underconstrained for multi-view data, which is most often captured under a single illumination condition; It is especially hard for full scenes containing multiple objects. We introduce a method to create relightable radiance fields using such single-illumination data by exploiting priors extracted from 2D image diffusion models. We first fine-tune a 2D diffusion model on a multi-illumination dataset conditioned by light direction, allowing us to augment a single-illumination capture into a realistic -- but possibly inconsistent -- multi-illumination dataset from directly defined light directions. We use this augmented data to create a relightable radiance field represented by 3D Gaussian splats. To allow direct control of light direction for low-frequency lighting, we represent appearance with a multi-layer perceptron parameterized on light direction. To enforce multi-view consistency and overcome inaccuracies we optimize a per-image auxiliary feature vector. We show results on synthetic and real multi-view data under single illumination, demonstrating that our method successfully exploits 2D diffusion model priors to allow realistic 3D relighting for complete scenes. Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
* Project site https://repo-sam.inria.fr/fungraph/generative-radiance-field-relighting/
Reducing the Memory Footprint of 3D Gaussian Splatting
Jun 24, 20243D Gaussian splatting provides excellent visual quality for novel view synthesis, with fast training and real-time rendering; unfortunately, the memory requirements of this method for storing and transmission are unreasonably high. We first analyze the reasons for this, identifying three main areas where storage can be reduced: the number of 3D Gaussian primitives used to represent a scene, the number of coefficients for the spherical harmonics used to represent directional radiance, and the precision required to store Gaussian primitive attributes. We present a solution to each of these issues. First, we propose an efficient, resolution-aware primitive pruning approach, reducing the primitive count by half. Second, we introduce an adaptive adjustment method to choose the number of coefficients used to represent directional radiance for each Gaussian primitive, and finally a codebook-based quantization method, together with a half-float representation for further memory reduction. Taken together, these three components result in a 27 reduction in overall size on disk on the standard datasets we tested, along with a 1.7 speedup in rendering speed. We demonstrate our method on standard datasets and show how our solution results in significantly reduced download times when using the method on a mobile device.
* Project website: https://repo-sam.inria.fr/fungraph/reduced_3dgs/
A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets
Jun 17, 2024



Novel view synthesis has seen major advances in recent years, with 3D Gaussian splatting offering an excellent level of visual quality, fast training and real-time rendering. However, the resources needed for training and rendering inevitably limit the size of the captured scenes that can be represented with good visual quality. We introduce a hierarchy of 3D Gaussians that preserves visual quality for very large scenes, while offering an efficient Level-of-Detail (LOD) solution for efficient rendering of distant content with effective level selection and smooth transitions between levels.We introduce a divide-and-conquer approach that allows us to train very large scenes in independent chunks. We consolidate the chunks into a hierarchy that can be optimized to further improve visual quality of Gaussians merged into intermediate nodes. Very large captures typically have sparse coverage of the scene, presenting many challenges to the original 3D Gaussian splatting training method; we adapt and regularize training to account for these issues. We present a complete solution, that enables real-time rendering of very large scenes and can adapt to available resources thanks to our LOD method. We show results for captured scenes with up to tens of thousands of images with a simple and affordable rig, covering trajectories of up to several kilometers and lasting up to one hour. Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
* Project Page: https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/
Learning Images Across Scales Using Adversarial Training
Jun 13, 2024



The real world exhibits rich structure and detail across many scales of observation. It is difficult, however, to capture and represent a broad spectrum of scales using ordinary images. We devise a novel paradigm for learning a representation that captures an orders-of-magnitude variety of scales from an unstructured collection of ordinary images. We treat this collection as a distribution of scale-space slices to be learned using adversarial training, and additionally enforce coherency across slices. Our approach relies on a multiscale generator with carefully injected procedural frequency content, which allows to interactively explore the emerging continuous scale space. Training across vastly different scales poses challenges regarding stability, which we tackle using a supervision scheme that involves careful sampling of scales. We show that our generator can be used as a multiscale generative model, and for reconstructions of scale spaces from unstructured patches. Significantly outperforming the state of the art, we demonstrate zoom-in factors of up to 256x at high quality and scale consistency.
Improving NeRF Quality by Progressive Camera Placement for Unrestricted Navigation in Complex Environments
Sep 04, 2023



Neural Radiance Fields, or NeRFs, have drastically improved novel view synthesis and 3D reconstruction for rendering. NeRFs achieve impressive results on object-centric reconstructions, but the quality of novel view synthesis with free-viewpoint navigation in complex environments (rooms, houses, etc) is often problematic. While algorithmic improvements play an important role in the resulting quality of novel view synthesis, in this work, we show that because optimizing a NeRF is inherently a data-driven process, good quality data play a fundamental role in the final quality of the reconstruction. As a consequence, it is critical to choose the data samples -- in this case the cameras -- in a way that will eventually allow the optimization to converge to a solution that allows free-viewpoint navigation with good quality. Our main contribution is an algorithm that efficiently proposes new camera placements that improve visual quality with minimal assumptions. Our solution can be used with any NeRF model and outperforms baselines and similar work.
3D Gaussian Splatting for Real-Time Radiance Field Rendering
Aug 08, 2023



Radiance Field methods have recently revolutionized novel-view synthesis of scenes captured with multiple photos or videos. However, achieving high visual quality still requires neural networks that are costly to train and render, while recent faster methods inevitably trade off speed for quality. For unbounded and complete scenes (rather than isolated objects) and 1080p resolution rendering, no current method can achieve real-time display rates. We introduce three key elements that allow us to achieve state-of-the-art visual quality while maintaining competitive training times and importantly allow high-quality real-time (>= 30 fps) novel-view synthesis at 1080p resolution. First, starting from sparse points produced during camera calibration, we represent the scene with 3D Gaussians that preserve desirable properties of continuous volumetric radiance fields for scene optimization while avoiding unnecessary computation in empty space; Second, we perform interleaved optimization/density control of the 3D Gaussians, notably optimizing anisotropic covariance to achieve an accurate representation of the scene; Third, we develop a fast visibility-aware rendering algorithm that supports anisotropic splatting and both accelerates training and allows realtime rendering. We demonstrate state-of-the-art visual quality and real-time rendering on several established datasets.
* https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/