 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAR: Session-based Pipeline for Adaptive Retrieval on Legacy File Systems
Dec 15, 2025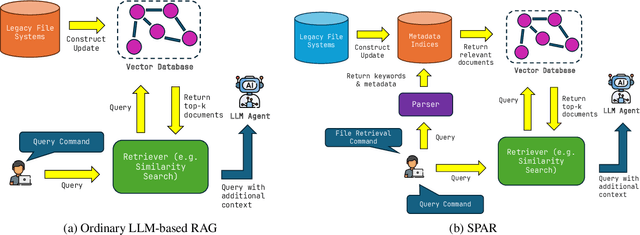

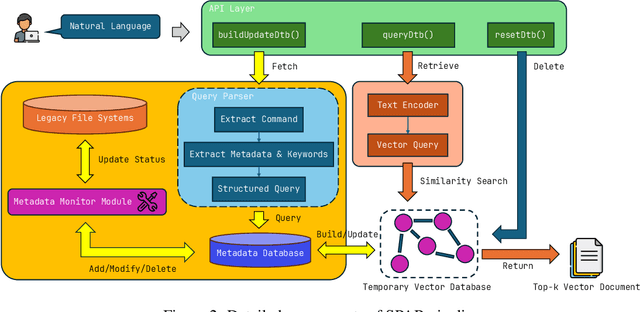

The ability to extract value from historical data is essential for enterprise decision-making. However, much of this information remains inaccessible within large legacy file systems that lack structured organization and semantic indexing, making retrieval and analysis inefficient and error-prone. We introduce SPAR (Session-based Pipeline for Adaptive Retrieval), a conceptual framework that integrates Large Language Models (LLMs) into a Retrieval-Augmented Generation (RAG) architecture specifically designed for legacy enterprise environments. Unlike conventional RAG pipelines, which require costly construction and maintenance of full-scale vector databases that mirror the entire file system, SPAR employs a lightweight two-stage process: a semantic Metadata Index is first created, after which session-specific vector databases are dynamically generated on demand. This design reduces computational overhead while improving transparency, controllability, and relevance in retrieval. We provide a theoretical complexity analysis comparing SPAR with standard LLM-based RAG pipelines, demonstrating its computational advantages. To validate the framework, we apply SPAR to a synthesized enterprise-scale file system containing a large corpus of biomedical literature, showing improvements in both retrieval effectiveness and downstream model accuracy. Finally, we discuss design trade-offs and outline open challenges for deploying SPAR across diverse enterprise settings.
A Unified Theory of Dynamic Programming Algorithms in Small Target Detection
Dec 11, 2025



Small target detection is inherently challenging due to the minimal size, lack of distinctive features, and the presence of complex backgrounds. Heavy noise further complicates the task by both obscuring and imitating the target appearance. Weak target signals require integrating target trajectories over multiple frames, an approach that can be computationally intensive. Dynamic programming offers an efficient solution by decomposing the problem into iterative maximization. This, however, has limited the analytical tools available for their study. In this paper, we present a robust framework for this class of algorithms and establish rigorous convergence results for error rates under mild assumptions. We depart from standard analysis by modeling error probabilities as a function of distance from the target, allowing us to construct a relationship between uncertainty in location and uncertainty in existence. From this framework, we introduce a novel algorithm, Normalized Path Integration (NPI), that utilizes the similarity between sequential observations, enabling target detection with unknown or time varying features.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025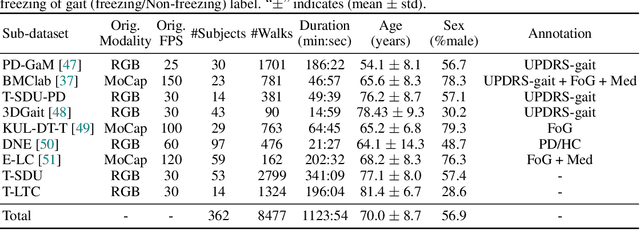
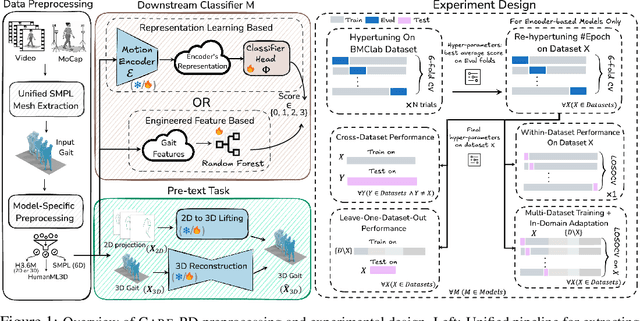
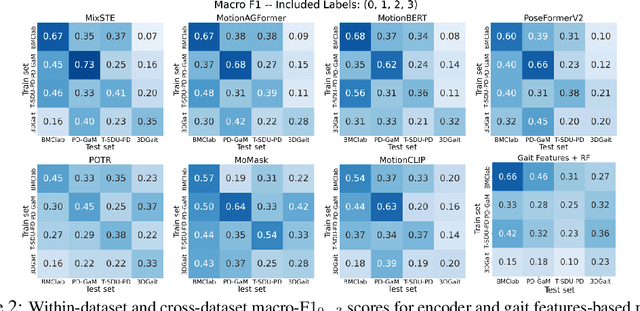
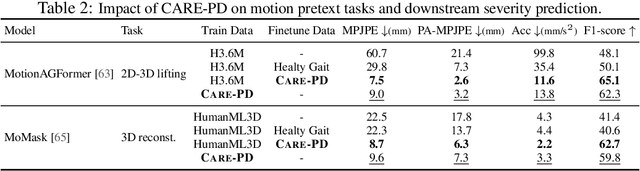
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Robult: Leveraging Redundancy and Modality Specific Features for Robust Multimodal Learning
Sep 03, 2025Addressing missing modalities and limited labeled data is crucial for advancing robust multimodal learning. We propose Robult, a scalable framework designed to mitigate these challenges by preserving modality-specific information and leveraging redundancy through a novel information-theoretic approach. Robult optimizes two core objectives: (1) a soft Positive-Unlabeled (PU) contrastive loss that maximizes task-relevant feature alignment while effectively utilizing limited labeled data in semi-supervised settings, and (2) a latent reconstruction loss that ensures unique modality-specific information is retained. These strategies, embedded within a modular design, enhance performance across various downstream tasks and ensure resilience to incomplete modalities during inference. Experimental results across diverse datasets validate that Robult achieves superior performance over existing approaches in both semi-supervised learning and missing modality contexts. Furthermore, its lightweight design promotes scalability and seamless integration with existing architectures, making it suitable for real-world multimodal applications.
Are you SURE? Enhancing Multimodal Pretraining with Missing Modalities through Uncertainty Estimation
Apr 18, 2025Multimodal learning has demonstrated incredible successes by integrating diverse data sources, yet it often relies on the availability of all modalities - an assumption that rarely holds in real-world applications. Pretrained multimodal models, while effective, struggle when confronted with small-scale and incomplete datasets (i.e., missing modalities), limiting their practical applicability. Previous studies on reconstructing missing modalities have overlooked the reconstruction's potential unreliability, which could compromise the quality of the final outputs. We present SURE (Scalable Uncertainty and Reconstruction Estimation), a novel framework that extends the capabilities of pretrained multimodal models by introducing latent space reconstruction and uncertainty estimation for both reconstructed modalities and downstream tasks. Our method is architecture-agnostic, reconstructs missing modalities, and delivers reliable uncertainty estimates, improving both interpretability and performance. SURE introduces a unique Pearson Correlation-based loss and applies statistical error propagation in deep networks for the first time, allowing precise quantification of uncertainties from missing data and model predictions. Extensive experiments across tasks such as sentiment analysis, genre classification, and action recognition show that SURE consistently achieves state-of-the-art performance, ensuring robust predictions even in the presence of incomplete data.
Leveraging Perfect Multimodal Alignment and Gaussian Assumptions for Cross-modal Transfer
Mar 19, 2025Multimodal alignment aims to construct a joint latent vector space where two modalities representing the same concept map to the same vector. We formulate this as an inverse problem and show that under certain conditions perfect alignment can be achieved. We then address a specific application of alignment referred to as cross-modal transfer. Unsupervised cross-modal transfer aims to leverage a model trained with one modality to perform inference on another modality, without any labeled fine-tuning on the new modality. Assuming that semantic classes are represented as a mixture of Gaussians in the latent space, we show how cross-modal transfer can be performed by projecting the data points from the representation space onto different subspaces representing each modality. Our experiments on synthetic multimodal Gaussian data verify the effectiveness of our perfect alignment and cross-modal transfer method. We hope these findings inspire further exploration of the applications of perfect alignment and the use of Gaussian models for cross-modal learning.
GIST: Towards Photorealistic Style Transfer via Multiscale Geometric Representations
Dec 03, 2024



State-of-the-art Style Transfer methods often leverage pre-trained encoders optimized for discriminative tasks, which may not be ideal for image synthesis. This can result in significant artifacts and loss of photorealism. Motivated by the ability of multiscale geometric image representations to capture fine-grained details and global structure, we propose GIST: Geometric-based Image Style Transfer, a novel Style Transfer technique that exploits the geometric properties of content and style images. GIST replaces the standard Neural Style Transfer autoencoding framework with a multiscale image expansion, preserving scene details without the need for post-processing or training. Our method matches multiresolution and multidirectional representations such as Wavelets and Contourlets by solving an optimal transport problem, leading to an efficient texture transferring. Experiments show that GIST is on-par or outperforms recent photorealistic Style Transfer approaches while significantly reducing the processing time with no model training.
R.I.P.: A Simple Black-box Attack on Continual Test-time Adaptation
Dec 02, 2024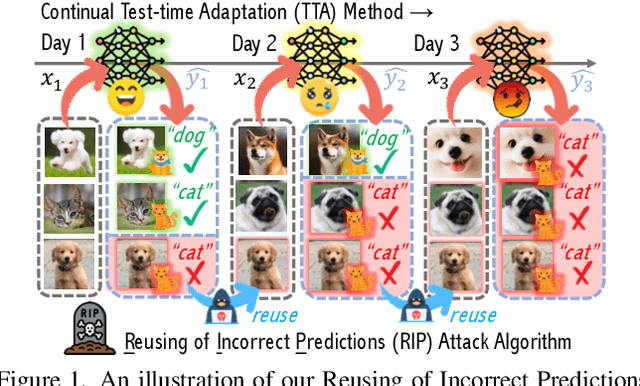

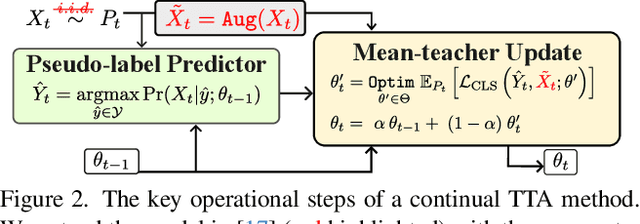
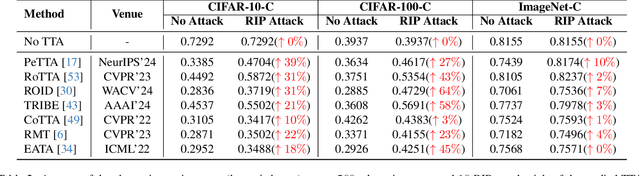
Test-time adaptation (TTA) has emerged as a promising solution to tackle the continual domain shift in machine learning by allowing model parameters to change at test time, via self-supervised learning on unlabeled testing data. At the same time, it unfortunately opens the door to unforeseen vulnerabilities for degradation over time. Through a simple theoretical continual TTA model, we successfully identify a risk in the sampling process of testing data that could easily degrade the performance of a continual TTA model. We name this risk as Reusing of Incorrect Prediction (RIP) that TTA attackers can employ or as a result of the unintended query from general TTA users. The risk posed by RIP is also highly realistic, as it does not require prior knowledge of model parameters or modification of testing samples. This simple requirement makes RIP as the first black-box TTA attack algorithm that stands out from existing white-box attempts. We extensively benchmark the performance of the most recent continual TTA approaches when facing the RIP attack, providing insights on its success, and laying out potential roadmaps that could enhance the resilience of future continual TTA systems.
Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
Dec 11, 2023Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
Persistent Test-time Adaptation in Episodic Testing Scenarios
Nov 30, 2023Current test-time adaptation (TTA) approaches aim to adapt to environments that change continuously. Yet, when the environments not only change but also recur in a correlated manner over time, such as in the case of day-night surveillance cameras, it is unclear whether the adaptability of these methods is sustained after a long run. This study aims to examine the error accumulation of TTA models when they are repeatedly exposed to previous testing environments, proposing a novel testing setting called episodic TTA. To study this phenomenon, we design a simulation of TTA process on a simple yet representative $\epsilon$-perturbed Gaussian Mixture Model Classifier and derive the theoretical findings revealing the dataset- and algorithm-dependent factors that contribute to the gradual degeneration of TTA methods through time. Our investigation has led us to propose a method, named persistent TTA (PeTTA). PeTTA senses the model divergence towards a collapsing and adjusts the adaptation strategy of TTA, striking a balance between two primary objectives: adaptation and preventing model collapse. The stability of PeTTA in the face of episodic TTA scenarios has been demonstrated through a set of comprehensive experiments on various benchmarks.