 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiclass Classification with an Ensemble of Binary Classification Deep Networks
Jun 28, 2020
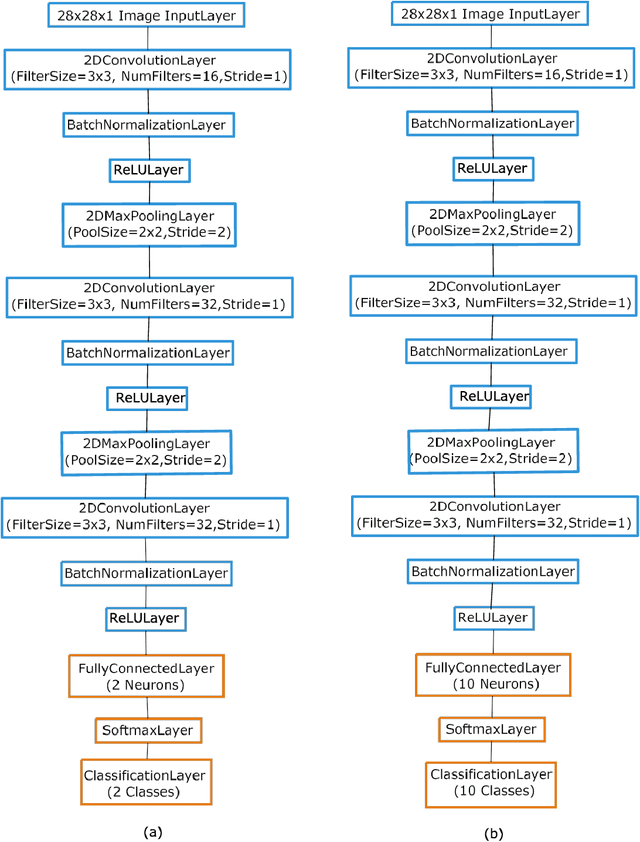
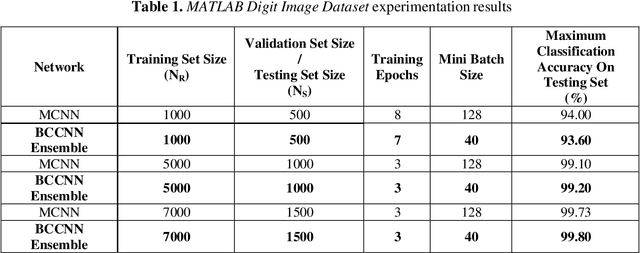
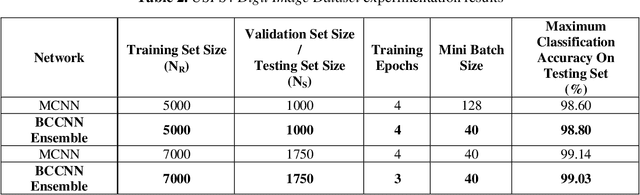
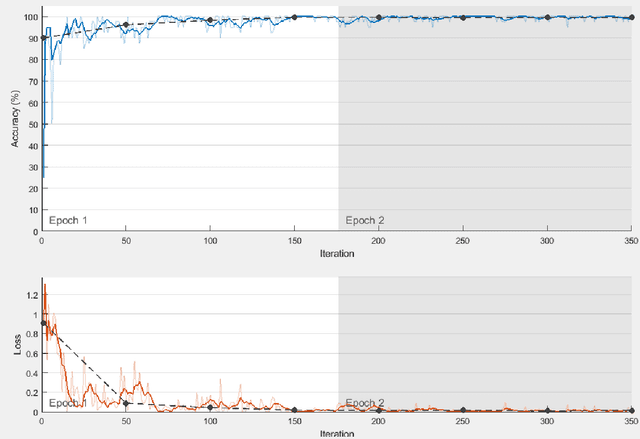
Deep neural network classifiers have been used frequently and are efficient. In multiclass deep network classifiers, the burden of classifying samples of different classes is put on a single classifier. As shown in this paper, the classification capability of deep networks can be further increased by using an ensemble of binary classification deep networks. In the proposed approach, a single (one-versus-all) deep network binary classifier is dedicated to each category classification. Subsequently, binary classification deep network ensembles have been investigated. Every network in an ensemble has been trained by a one-versus-all binary training technique using the Stochastic Gradient Descent with Momentum Algorithm. For classification of the test sample, the sample is presented to each network in the ensemble. After softmax-layer score voting, the network with the largest score is assumed to have classified the sample. Digit image recognition has been used for experimentation. Three datasets have been used for experimentation viz. the MATLAB Digit Image Dataset, the USPS+ Digit Image Dataset, and the MNIST Digit Image Dataset. The experiments demonstrate that given sufficient training, a Binary Classification Convolutional Neural Network (BCCNN) ensemble can outperform a conventional Multi-class Convolutional Neural Network (MCNN). In one of the experiments, it was noted that after training and testing of a BCCNN ensemble and an MCNN respectively on a subset of the MNIST Digit Image Dataset, the BCCNN ensemble gave a higher accuracy of 98.03% as compared to the MCNN which gave an accuracy of 97.90%. The architecture of the BCCNNs in an ensemble has also been modified in order to increase their recognition accuracy. On a large subset of the MNIST Digit Image Dataset, the modified BCCNN ensemble gave a higher accuracy of 98.50%, while as the MCNN gave an accuracy of 98.4875%.
Model-based Iterative Restoration for Binary Document Image Compression with Dictionary Learning
Apr 24, 2017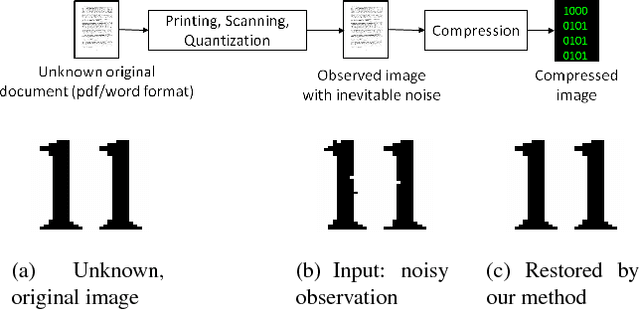

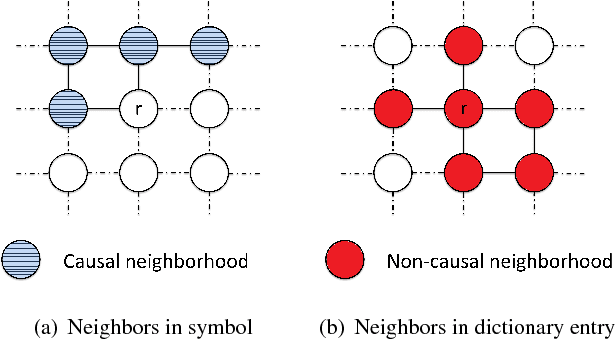
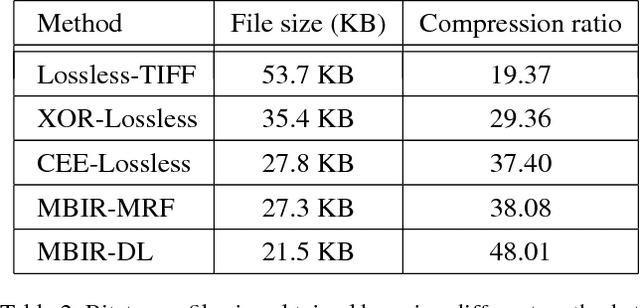
The inherent noise in the observed (e.g., scanned) binary document image degrades the image quality and harms the compression ratio through breaking the pattern repentance and adding entropy to the document images. In this paper, we design a cost function in Bayesian framework with dictionary learning. Minimizing our cost function produces a restored image which has better quality than that of the observed noisy image, and a dictionary for representing and encoding the image. After the restoration, we use this dictionary (from the same cost function) to encode the restored image following the symbol-dictionary framework by JBIG2 standard with the lossless mode. Experimental results with a variety of document images demonstrate that our method improves the image quality compared with the observed image, and simultaneously improves the compression ratio. For the test images with synthetic noise, our method reduces the number of flipped pixels by 48.2% and improves the compression ratio by 36.36% as compared with the best encoding methods. For the test images with real noise, our method visually improves the image quality, and outperforms the cutting-edge method by 28.27% in terms of the compression ratio.
Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias
Jan 18, 2021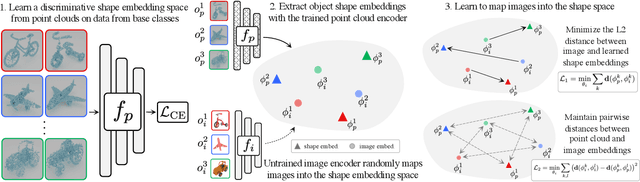
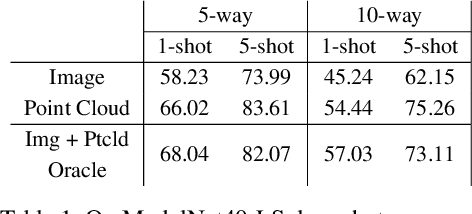
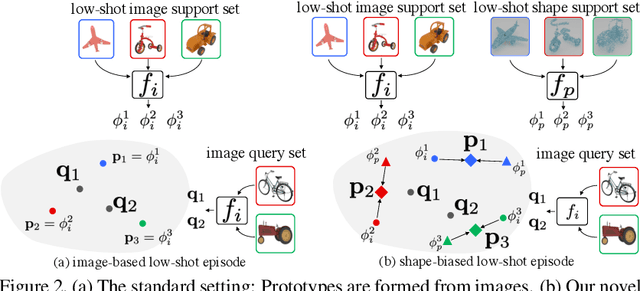
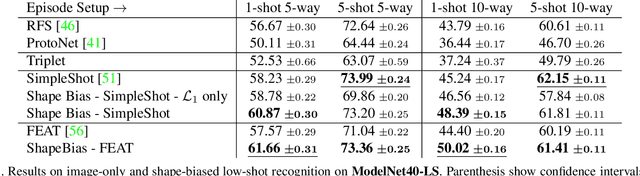
It is widely accepted that reasoning about object shape is important for object recognition. However, the most powerful object recognition methods today do not explicitly make use of object shape during learning. In this work, motivated by recent developments in low-shot learning, findings in developmental psychology, and the increased use of synthetic data in computer vision research, we investigate how reasoning about 3D shape can be used to improve low-shot learning methods' generalization performance. We propose a new way to improve existing low-shot learning approaches by learning a discriminative embedding space using 3D object shape, and utilizing this embedding by learning how to map images into it. Our new approach improves the performance of image-only low-shot learning approaches on multiple datasets. We also develop Toys4K, a new 3D object dataset with the biggest number of object categories that can also support low-shot learning.
Defense-friendly Images in Adversarial Attacks: Dataset and Metrics for Perturbation Difficulty
Nov 07, 2020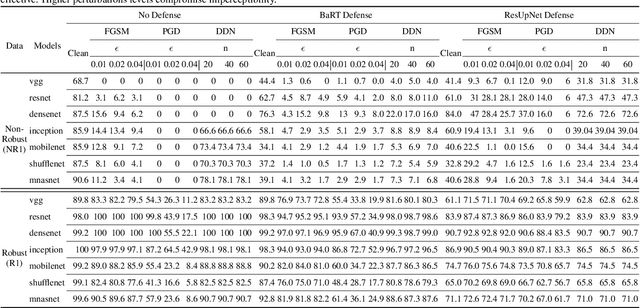
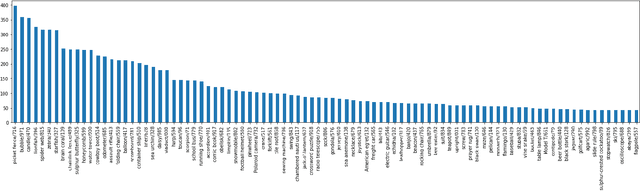
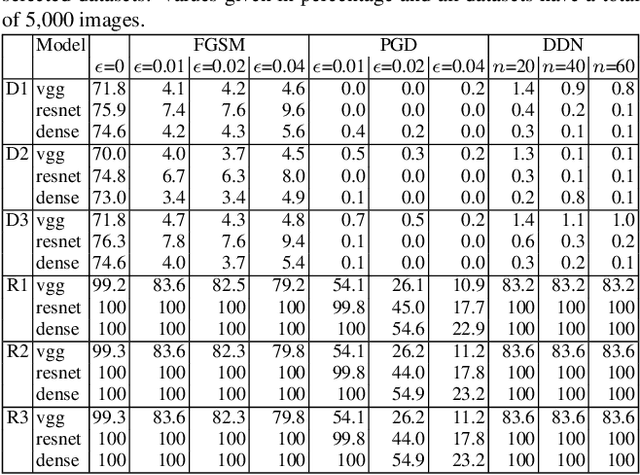

Dataset bias is a problem in adversarial machine learning, especially in the evaluation of defenses. An adversarial attack or defense algorithm may show better results on the reported dataset than can be replicated on other datasets. Even when two algorithms are compared, their relative performance can vary depending on the dataset. Deep learning offers state-of-the-art solutions for image recognition, but deep models are vulnerable even to small perturbations. Research in this area focuses primarily on adversarial attacks and defense algorithms. In this paper, we report for the first time, a class of robust images that are both resilient to attacks and that recover better than random images under adversarial attacks using simple defense techniques. Thus, a test dataset with a high proportion of robust images gives a misleading impression about the performance of an adversarial attack or defense. We propose three metrics to determine the proportion of robust images in a dataset and provide scoring to determine the dataset bias. We also provide an ImageNet-R dataset of 15000+ robust images to facilitate further research on this intriguing phenomenon of image strength under attack. Our dataset, combined with the proposed metrics, is valuable for unbiased benchmarking of adversarial attack and defense algorithms.
Optimizing the Trade-off between Single-Stage and Two-Stage Object Detectors using Image Difficulty Prediction
Aug 31, 2018


There are mainly two types of state-of-the-art object detectors. On one hand, we have two-stage detectors, such as Faster R-CNN (Region-based Convolutional Neural Networks) or Mask R-CNN, that (i) use a Region Proposal Network to generate regions of interests in the first stage and (ii) send the region proposals down the pipeline for object classification and bounding-box regression. Such models reach the highest accuracy rates, but are typically slower. On the other hand, we have single-stage detectors, such as YOLO (You Only Look Once) and SSD (Singe Shot MultiBox Detector), that treat object detection as a simple regression problem by taking an input image and learning the class probabilities and bounding box coordinates. Such models reach lower accuracy rates, but are much faster than two-stage object detectors. In this paper, we propose to use an image difficulty predictor to achieve an optimal trade-off between accuracy and speed in object detection. The image difficulty predictor is applied on the test images to split them into easy versus hard images. Once separated, the easy images are sent to the faster single-stage detector, while the hard images are sent to the more accurate two-stage detector. Our experiments on PASCAL VOC 2007 show that using image difficulty compares favorably to a random split of the images. Our method is flexible, in that it allows to choose a desired threshold for splitting the images into easy versus hard.
Two-way kernel matrix puncturing: towards resource-efficient PCA and spectral clustering
Feb 24, 2021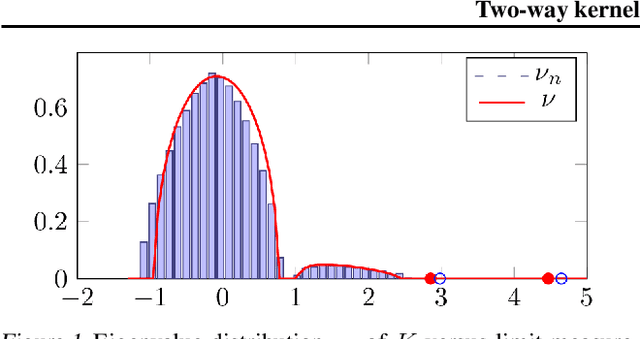
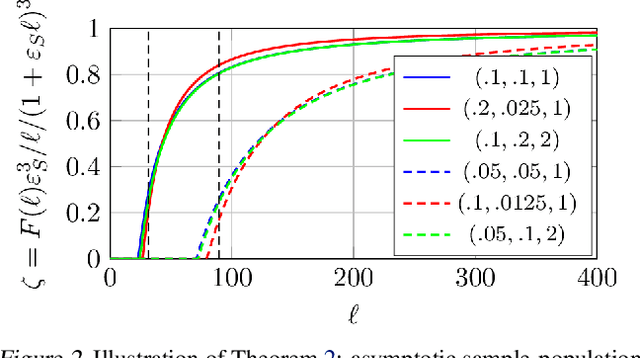
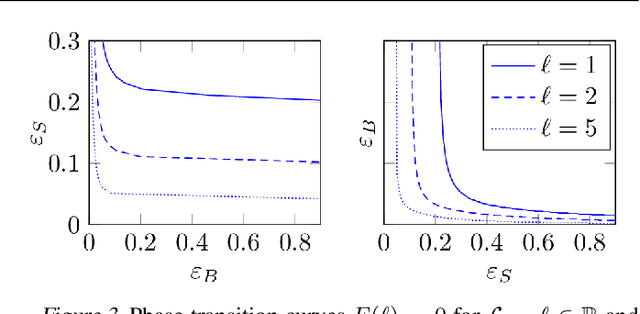
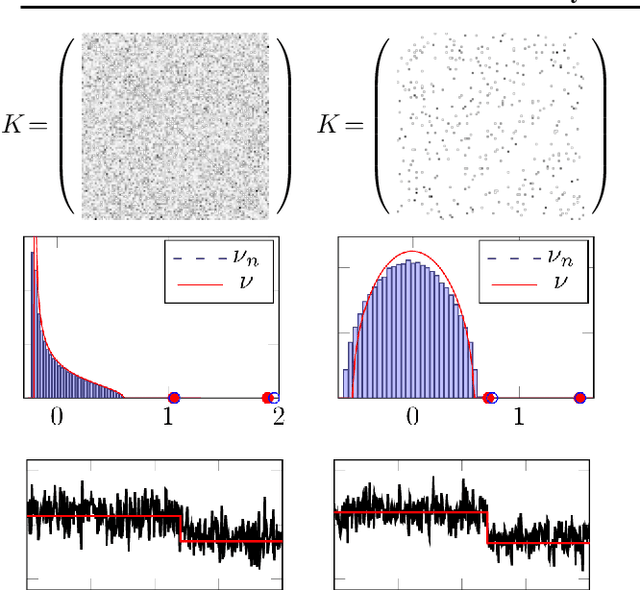
The article introduces an elementary cost and storage reduction method for spectral clustering and principal component analysis. The method consists in randomly "puncturing" both the data matrix $X\in\mathbb{C}^{p\times n}$ (or $\mathbb{R}^{p\times n}$) and its corresponding kernel (Gram) matrix $K$ through Bernoulli masks: $S\in\{0,1\}^{p\times n}$ for $X$ and $B\in\{0,1\}^{n\times n}$ for $K$. The resulting "two-way punctured" kernel is thus given by $K=\frac{1}{p}[(X \odot S)^{\sf H} (X \odot S)] \odot B$. We demonstrate that, for $X$ composed of independent columns drawn from a Gaussian mixture model, as $n,p\to\infty$ with $p/n\to c_0\in(0,\infty)$, the spectral behavior of $K$ -- its limiting eigenvalue distribution, as well as its isolated eigenvalues and eigenvectors -- is fully tractable and exhibits a series of counter-intuitive phenomena. We notably prove, and empirically confirm on GAN-generated image databases, that it is possible to drastically puncture the data, thereby providing possibly huge computational and storage gains, for a virtually constant (clustering of PCA) performance. This preliminary study opens as such the path towards rethinking, from a large dimensional standpoint, computational and storage costs in elementary machine learning models.
Goal-Oriented Gaze Estimation for Zero-Shot Learning
Mar 05, 2021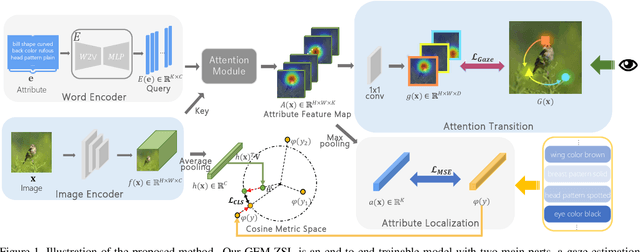
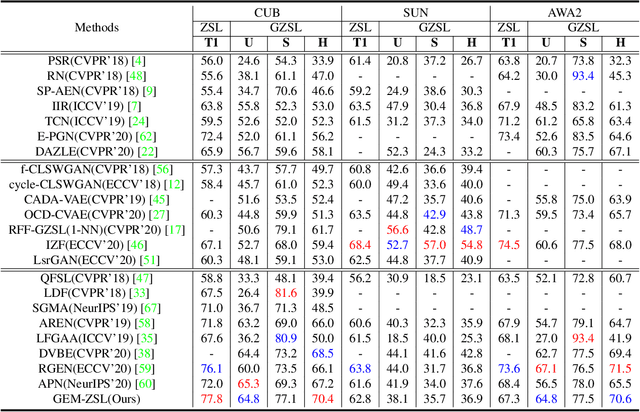
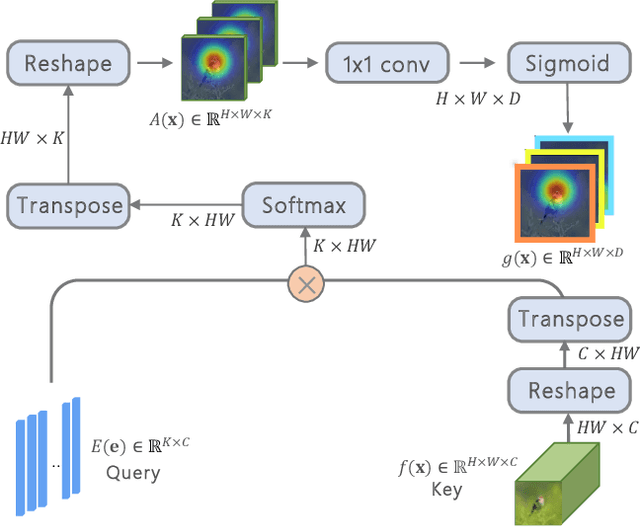
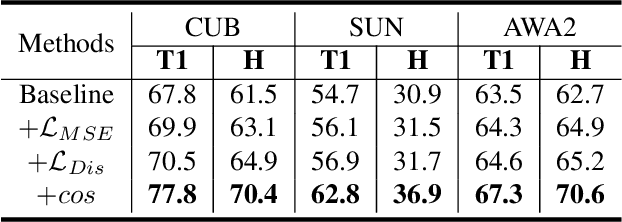
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen classes. Since semantic knowledge is built on attributes shared between different classes, which are highly local, strong prior for localization of object attribute is beneficial for visual-semantic embedding. Interestingly, when recognizing unseen images, human would also automatically gaze at regions with certain semantic clue. Therefore, we introduce a novel goal-oriented gaze estimation module (GEM) to improve the discriminative attribute localization based on the class-level attributes for ZSL. We aim to predict the actual human gaze location to get the visual attention regions for recognizing a novel object guided by attribute description. Specifically, the task-dependent attention is learned with the goal-oriented GEM, and the global image features are simultaneously optimized with the regression of local attribute features. Experiments on three ZSL benchmarks, i.e., CUB, SUN and AWA2, show the superiority or competitiveness of our proposed method against the state-of-the-art ZSL methods. The ablation analysis on real gaze data CUB-VWSW also validates the benefits and accuracy of our gaze estimation module. This work implies the promising benefits of collecting human gaze dataset and automatic gaze estimation algorithms on high-level computer vision tasks. The code is available at https://github.com/osierboy/GEM-ZSL.
One-Shot Object Localization in Medical Images based on Relative Position Regression
Dec 13, 2020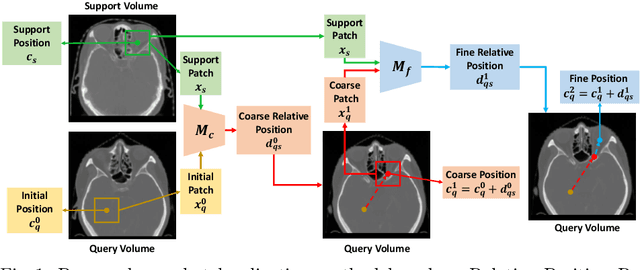
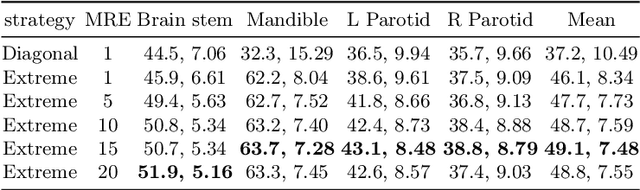
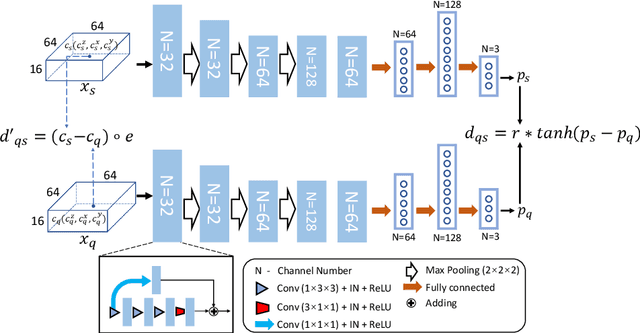
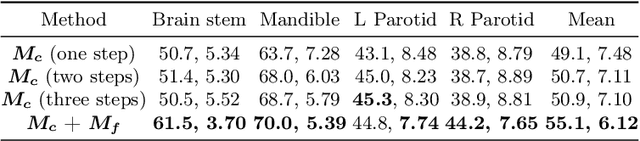
Deep learning networks have shown promising performance for accurate object localization in medial images, but require large amount of annotated data for supervised training, which is expensive and expertise burdensome. To address this problem, we present a one-shot framework for organ and landmark localization in volumetric medical images, which does not need any annotation during the training stage and could be employed to locate any landmarks or organs in test images given a support (reference) image during the inference stage. Our main idea comes from that tissues and organs from different human bodies have a similar relative position and context. Therefore, we could predict the relative positions of their non-local patches, thus locate the target organ. Our framework is composed of three parts: (1) A projection network trained to predict the 3D offset between any two patches from the same volume, where human annotations are not required. In the inference stage, it takes one given landmark in a reference image as a support patch and predicts the offset from a random patch to the corresponding landmark in the test (query) volume. (2) A coarse-to-fine framework contains two projection networks, providing more accurate localization of the target. (3) Based on the coarse-to-fine model, we transfer the organ boundingbox (B-box) detection to locating six extreme points along x, y and z directions in the query volume. Experiments on multi-organ localization from head-and-neck (HaN) CT volumes showed that our method acquired competitive performance in real time, which is more accurate and 10^5 times faster than template matching methods with the same setting. Code is available: https://github.com/LWHYC/RPR-Loc.
Efficient Robust Watermarking Based on Quaternion Singular Value Decomposition and Coefficient Pair Selection
Nov 06, 2020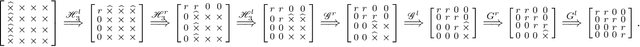
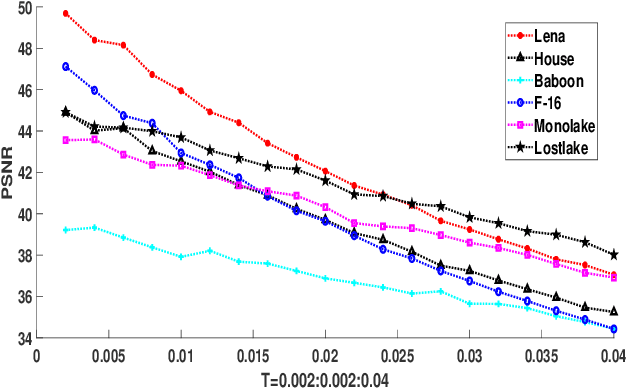
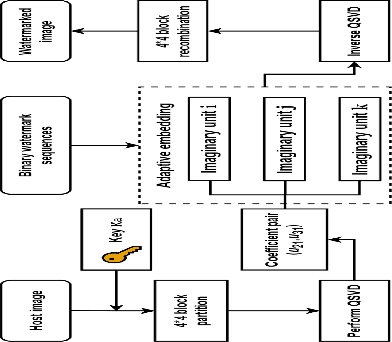
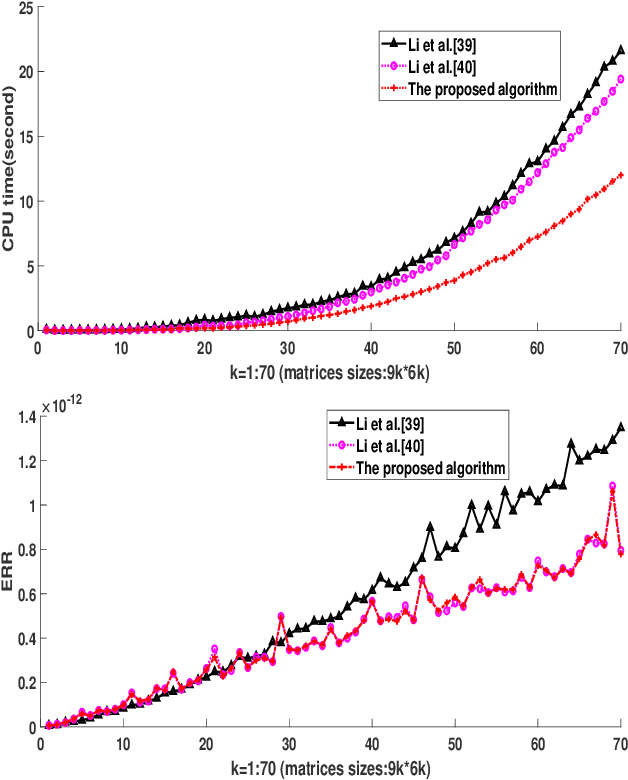
Quaternion singular value decomposition (QSVD) is a robust technique of digital watermarking which can extract high quality watermarks from watermarked images with low distortion. In this paper, QSVD technique is further investigated and an efficient robust watermarking scheme is proposed. The improved algebraic structure-preserving method is proposed to handle the problem of "explosion of complexity" occurred in the conventional QSVD design. Secret information is transmitted blindly by incorporating in QSVD two new strategies, namely, coefficient pair selection and adaptive embedding. Unlike conventional QSVD which embeds watermarks in a single imaginary unit, we propose to adaptively embed the watermark into the optimal hiding position using the Normalized Cross-Correlation (NC) method. This avoids the selection of coefficient pair with less correlation, and thus, it reduces embedding impact by decreasing the maximum modification of coefficient values. In this way, compared with conventional QSVD, the proposed watermarking strategy avoids more modifications to a single color image layer and a better visual quality of the watermarked image is observed. Meanwhile, adaptive QSVD resists some common geometric attacks, and it improves the robustness of conventional QSVD. With these improvements, our method outperforms conventional QSVD. Its superiority over other state-of-the-art methods is also demonstrated experimentally.
Superpixel Segmentation using Dynamic and Iterative Spanning Forest
Jul 08, 2020
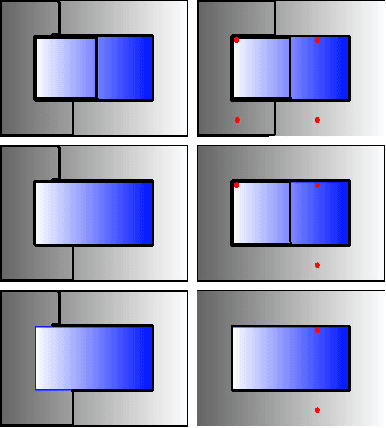

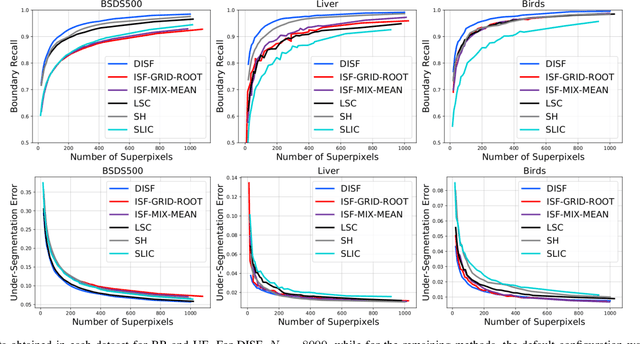
As constituent parts of image objects, superpixels can improve several higher-level operations. However, image segmentation methods might have their accuracy seriously compromised for reduced numbers of superpixels. We have investigated a solution based on the Iterative Spanning Forest (ISF) framework. In this work, we present Dynamic ISF (DISF) -- a method based on the following steps. (a) It starts from an image graph and a seed set with considerably more pixels than the desired number of superpixels. (b) The seeds compete among themselves, and each seed conquers its most closely connected pixels, resulting in an image partition (spanning forest) with connected superpixels. In step (c), DISF assigns relevance values to seeds based on superpixel analysis and removes the most irrelevant ones. Steps (b) and (c) are repeated until the desired number of superpixels is reached. DISF has the chance to reconstruct relevant edges after each iteration, when compared to region merging algorithms. As compared to other seed-based superpixel methods, DISF is more likely to find relevant seeds. It also introduces dynamic arc-weight estimation in the ISF framework for more effective superpixel delineation, and we demonstrate all results on three datasets with distinct object properties.