 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning: A Survey
Jan 25, 2021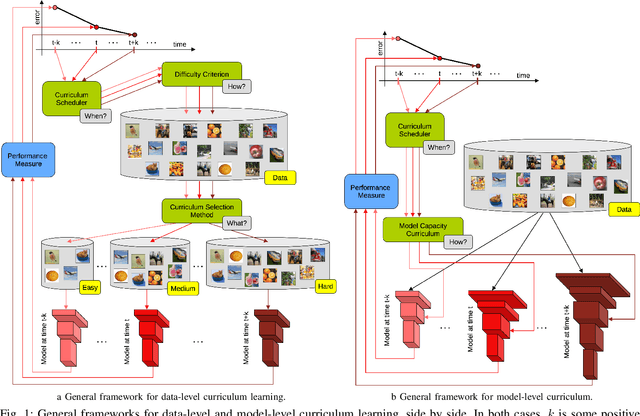
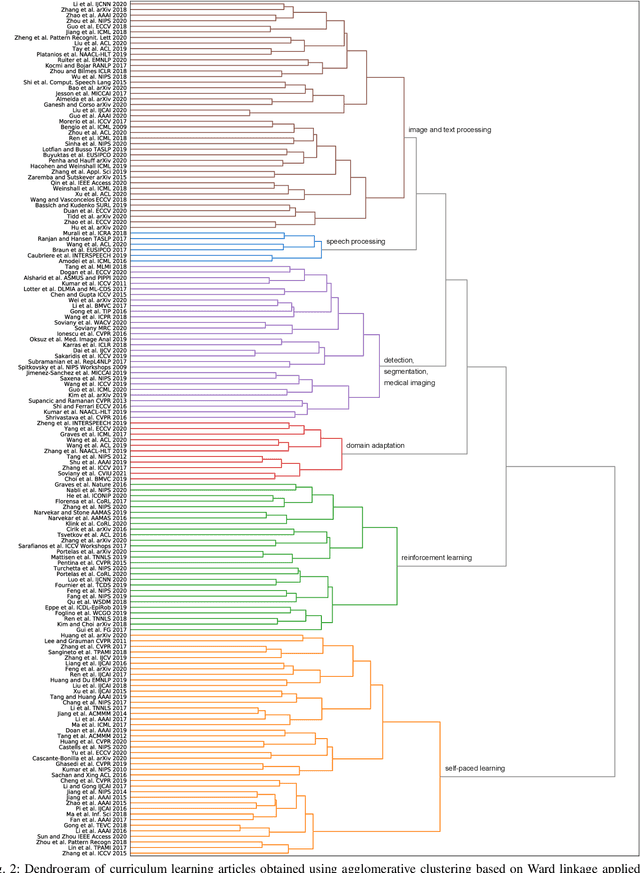
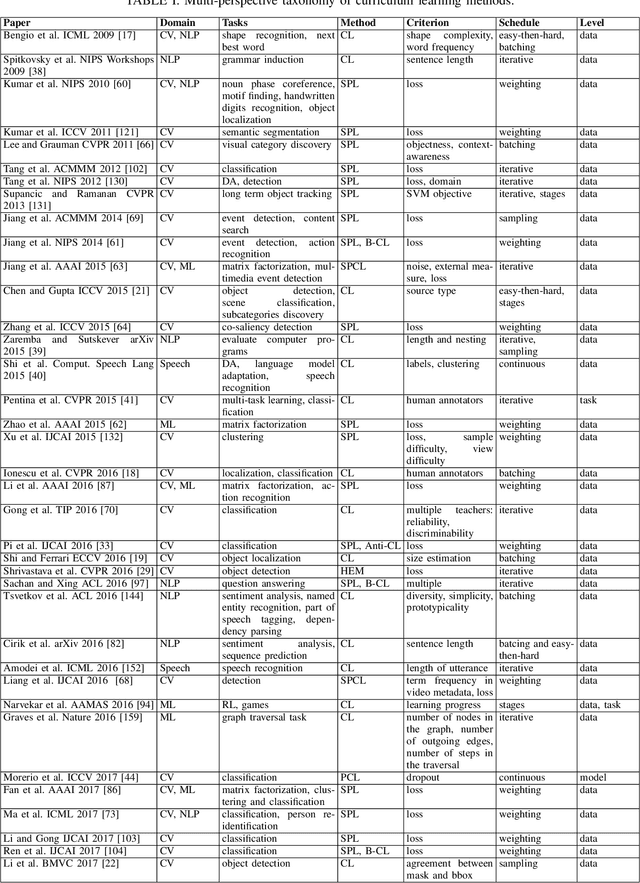
Training machine learning models in a meaningful order, from the easy samples to the hard ones, using curriculum learning can provide performance improvements over the standard training approach based on random data shuffling, without any additional computational costs. Curriculum learning strategies have been successfully employed in all areas of machine learning, in a wide range of tasks. However, the necessity of finding a way to rank the samples from easy to hard, as well as the right pacing function for introducing more difficult data can limit the usage of the curriculum approaches. In this survey, we show how these limits have been tackled in the literature, and we present different curriculum learning instantiations for various tasks in machine learning. We construct a multi-perspective taxonomy of curriculum learning approaches by hand, considering various classification criteria. We further build a hierarchical tree of curriculum learning methods using an agglomerative clustering algorithm, linking the discovered clusters with our taxonomy. At the end, we provide some interesting directions for future work.
Curriculum Learning with Diversity for Supervised Computer Vision Tasks
Sep 22, 2020

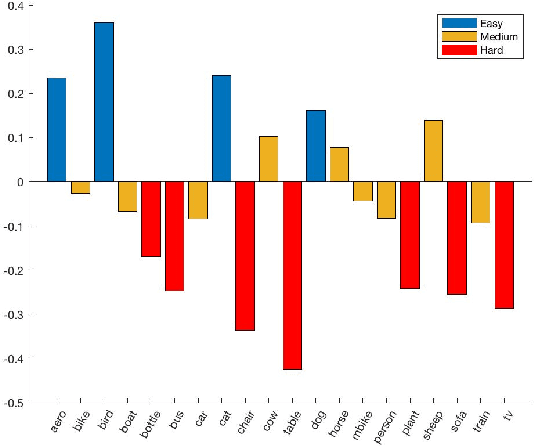
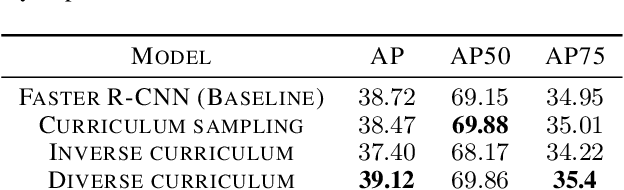
Curriculum learning techniques are a viable solution for improving the accuracy of automatic models, by replacing the traditional random training with an easy-to-hard strategy. However, the standard curriculum methodology does not automatically provide improved results, but it is constrained by multiple elements like the data distribution or the proposed model. In this paper, we introduce a novel curriculum sampling strategy which takes into consideration the diversity of the training data together with the difficulty of the inputs. We determine the difficulty using a state-of-the-art estimator based on the human time required for solving a visual search task. We consider this kind of difficulty metric to be better suited for solving general problems, as it is not based on certain task-dependent elements, but more on the context of each image. We ensure the diversity during training, giving higher priority to elements from less visited classes. We conduct object detection and instance segmentation experiments on Pascal VOC 2007 and Cityscapes data sets, surpassing both the randomly-trained baseline and the standard curriculum approach. We prove that our strategy is very efficient for unbalanced data sets, leading to faster convergence and more accurate results, when other curriculum-based strategies fail.
Curriculum Self-Paced Learning for Cross-Domain Object Detection
Nov 15, 2019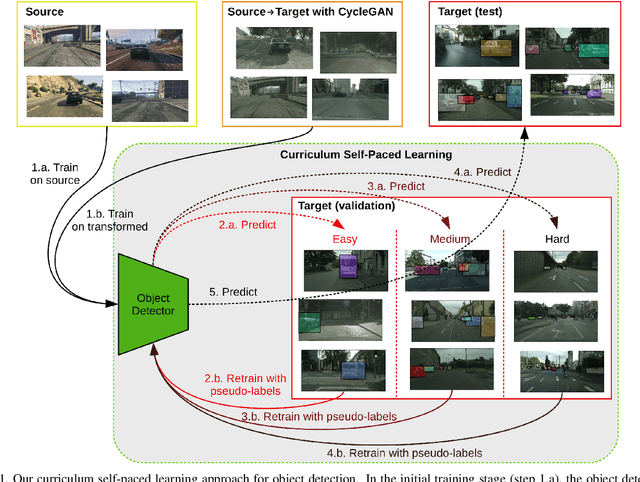
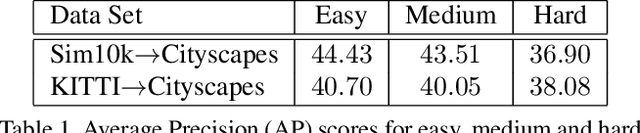
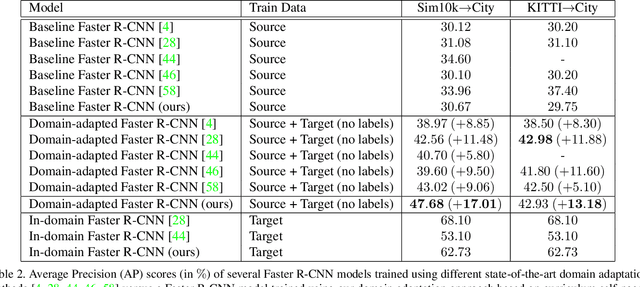

Training (source) domain bias affects state-of-the-art object detectors, such as Faster R-CNN, when applied to new (target) domains. To alleviate this problem, researchers proposed various domain adaptation methods to improve object detection results in the cross-domain setting, e.g. by translating images with ground-truth labels from the source domain to the target domain using Cycle-GAN or by applying self-paced learning. On top of combining Cycle-GAN transformations and self-paced learning, in this paper, we propose a novel self-paced algorithm that learns from easy to hard. To estimate the difficulty of each image, we use the number of detected objects divided by their average size. Our method is simple and effective, without any overhead during inference. It uses only pseudo-labels for samples taken from the target domain, i.e. the domain adaptation is unsupervised. We conduct experiments on two cross-domain benchmarks, showing better results than the state of the art. We also perform an ablation study demonstrating the utility of each component in our framework.
Image Difficulty Curriculum for Generative Adversarial Networks (CuGAN)
Oct 22, 2019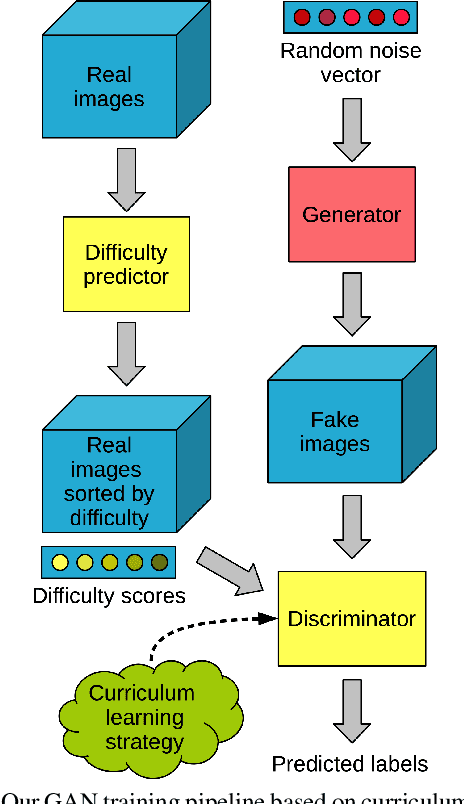


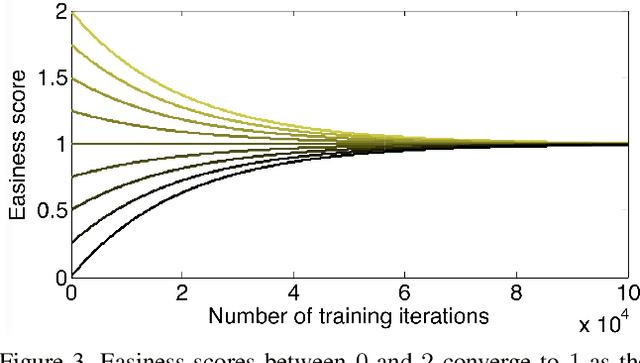
Despite the significant advances in recent years, Generative Adversarial Networks (GANs) are still notoriously hard to train. In this paper, we propose three novel curriculum learning strategies for training GANs. All strategies are first based on ranking the training images by their difficulty scores, which are estimated by a state-of-the-art image difficulty predictor. Our first strategy is to divide images into gradually more difficult batches. Our second strategy introduces a novel curriculum loss function for the discriminator that takes into account the difficulty scores of the real images. Our third strategy is based on sampling from an evolving distribution, which favors the easier images during the initial training stages and gradually converges to a uniform distribution, in which samples are equally likely, regardless of difficulty. We compare our curriculum learning strategies with the classic training procedure on two tasks: image generation and image translation. Our experiments indicate that all strategies provide faster convergence and superior results. For example, our best curriculum learning strategy applied on spectrally normalized GANs (SNGANs) fooled human annotators in thinking that generated CIFAR-like images are real in 25.0% of the presented cases, while the SNGANs trained using the classic procedure fooled the annotators in only 18.4% cases. Similarly, in image translation, the human annotators preferred the images produced by the Cycle-consistent GAN (CycleGAN) trained using curriculum learning in 40.5% cases and those produced by CycleGAN based on classic training in only 19.8% cases, 39.7% cases being labeled as ties.
Continuous Trade-off Optimization between Fast and Accurate Deep Face Detectors
Nov 27, 2018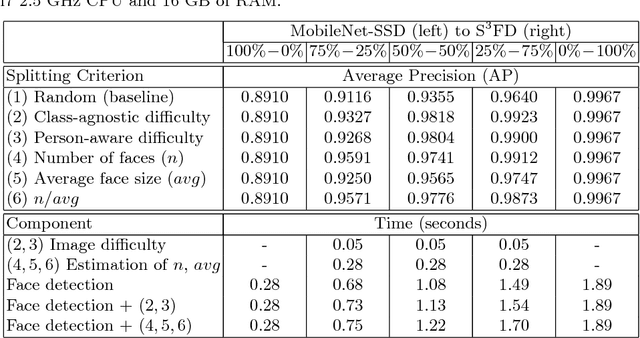

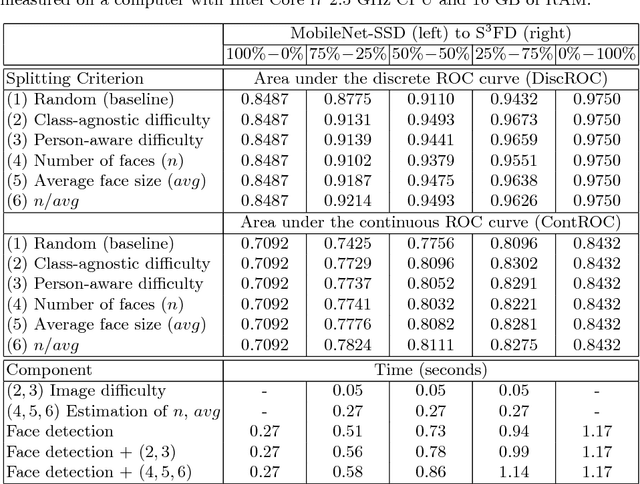
Although deep neural networks offer better face detection results than shallow or handcrafted models, their complex architectures come with higher computational requirements and slower inference speeds than shallow neural networks. In this context, we study five straightforward approaches to achieve an optimal trade-off between accuracy and speed in face detection. All the approaches are based on separating the test images in two batches, an easy batch that is fed to a faster face detector and a difficult batch that is fed to a more accurate yet slower detector. We conduct experiments on the AFW and the FDDB data sets, using MobileNet-SSD as the fast face detector and S3FD (Single Shot Scale-invariant Face Detector) as the accurate face detector, both models being pre-trained on the WIDER FACE data set. Our experiments show that the proposed difficulty metrics compare favorably to a random split of the images.
Optimizing the Trade-off between Single-Stage and Two-Stage Object Detectors using Image Difficulty Prediction
Aug 31, 2018


There are mainly two types of state-of-the-art object detectors. On one hand, we have two-stage detectors, such as Faster R-CNN (Region-based Convolutional Neural Networks) or Mask R-CNN, that (i) use a Region Proposal Network to generate regions of interests in the first stage and (ii) send the region proposals down the pipeline for object classification and bounding-box regression. Such models reach the highest accuracy rates, but are typically slower. On the other hand, we have single-stage detectors, such as YOLO (You Only Look Once) and SSD (Singe Shot MultiBox Detector), that treat object detection as a simple regression problem by taking an input image and learning the class probabilities and bounding box coordinates. Such models reach lower accuracy rates, but are much faster than two-stage object detectors. In this paper, we propose to use an image difficulty predictor to achieve an optimal trade-off between accuracy and speed in object detection. The image difficulty predictor is applied on the test images to split them into easy versus hard images. Once separated, the easy images are sent to the faster single-stage detector, while the hard images are sent to the more accurate two-stage detector. Our experiments on PASCAL VOC 2007 show that using image difficulty compares favorably to a random split of the images. Our method is flexible, in that it allows to choose a desired threshold for splitting the images into easy versus hard.