 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical world assistive signals for deep neural network classifiers -- neither defense nor attack
May 03, 2021
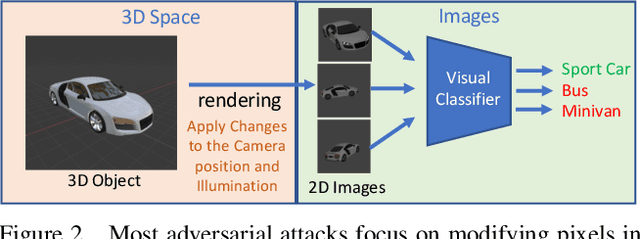
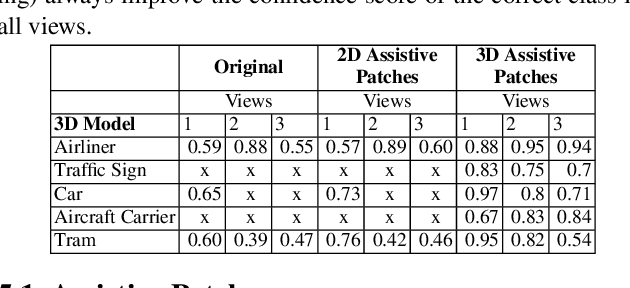
Deep Neural Networks lead the state of the art of computer vision tasks. Despite this, Neural Networks are brittle in that small changes in the input can drastically affect their prediction outcome and confidence. Consequently and naturally, research in this area mainly focus on adversarial attacks and defenses. In this paper, we take an alternative stance and introduce the concept of Assistive Signals, which are optimized to improve a model's confidence score regardless if it's under attack or not. We analyse some interesting properties of these assistive perturbations and extend the idea to optimize assistive signals in the 3D space for real-life scenarios simulating different lighting conditions and viewing angles. Experimental evaluations show that the assistive signals generated by our optimization method increase the accuracy and confidence of deep models more than those generated by conventional methods that work in the 2D space. In addition, our Assistive Signals illustrate the intrinsic bias of ML models towards certain patterns in real-life objects. We discuss how we can exploit these insights to re-think, or avoid, some patterns that might contribute to, or degrade, the detectability of objects in the real-world.
Defense-friendly Images in Adversarial Attacks: Dataset and Metrics for Perturbation Difficulty
Nov 07, 2020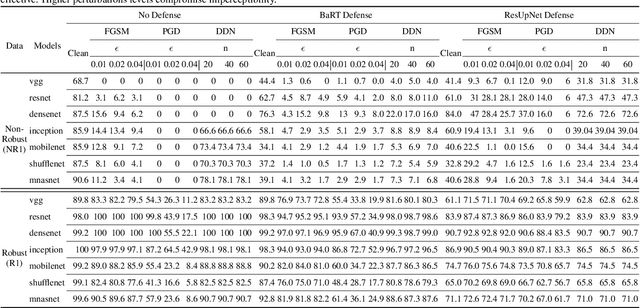
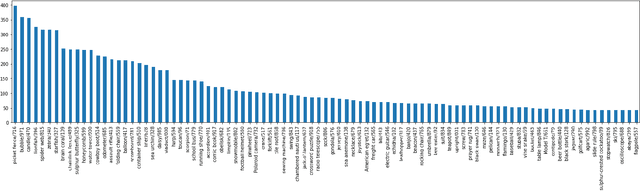

Dataset bias is a problem in adversarial machine learning, especially in the evaluation of defenses. An adversarial attack or defense algorithm may show better results on the reported dataset than can be replicated on other datasets. Even when two algorithms are compared, their relative performance can vary depending on the dataset. Deep learning offers state-of-the-art solutions for image recognition, but deep models are vulnerable even to small perturbations. Research in this area focuses primarily on adversarial attacks and defense algorithms. In this paper, we report for the first time, a class of robust images that are both resilient to attacks and that recover better than random images under adversarial attacks using simple defense techniques. Thus, a test dataset with a high proportion of robust images gives a misleading impression about the performance of an adversarial attack or defense. We propose three metrics to determine the proportion of robust images in a dataset and provide scoring to determine the dataset bias. We also provide an ImageNet-R dataset of 15000+ robust images to facilitate further research on this intriguing phenomenon of image strength under attack. Our dataset, combined with the proposed metrics, is valuable for unbiased benchmarking of adversarial attack and defense algorithms.
Adversarial Perturbations Prevail in the Y-Channel of the YCbCr Color Space
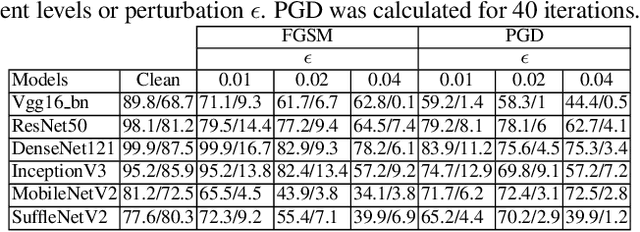
Feb 25, 2020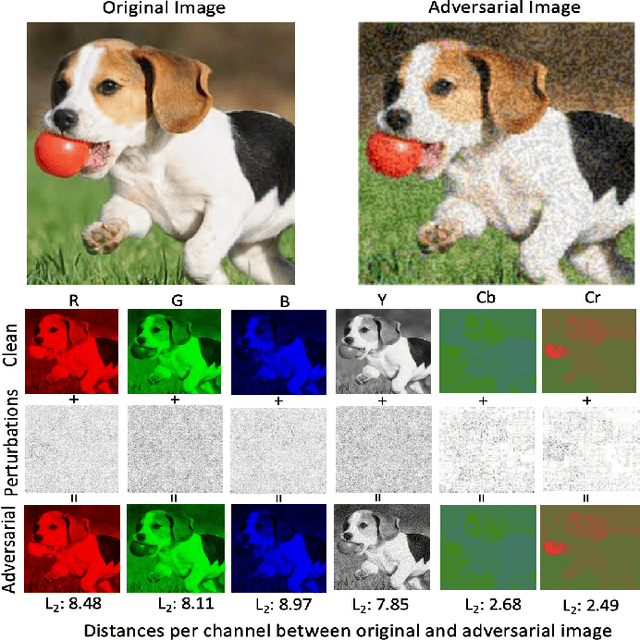
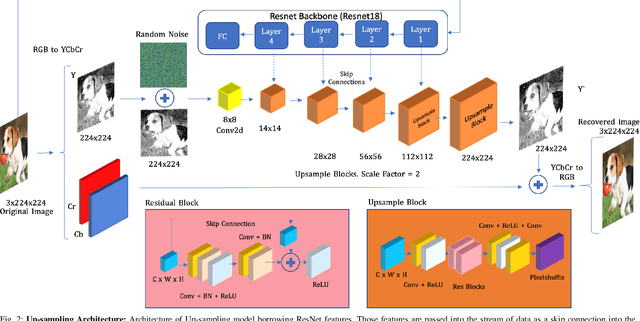
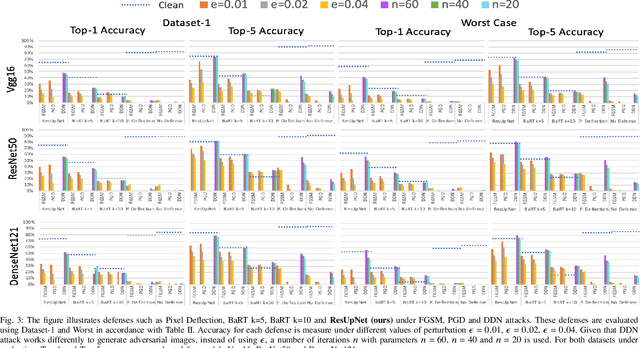

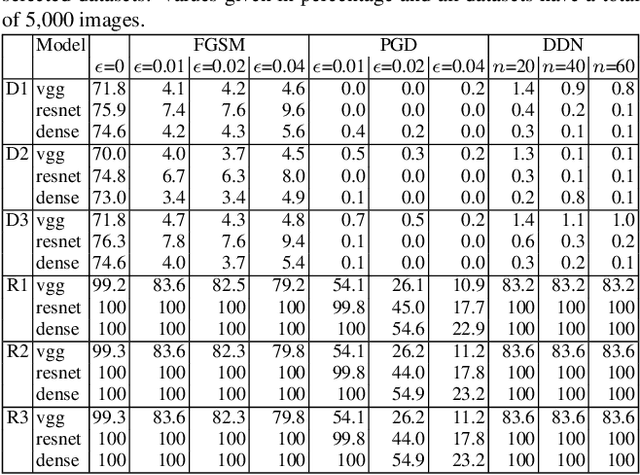
Deep learning offers state of the art solutions for image recognition. However, deep models are vulnerable to adversarial perturbations in images that are subtle but significantly change the model's prediction. In a white-box attack, these perturbations are generally learned for deep models that operate on RGB images and, hence, the perturbations are equally distributed in the RGB color space. In this paper, we show that the adversarial perturbations prevail in the Y-channel of the YCbCr space. Our finding is motivated from the fact that the human vision and deep models are more responsive to shape and texture rather than color. Based on our finding, we propose a defense against adversarial images. Our defence, coined ResUpNet, removes perturbations only from the Y-channel by exploiting ResNet features in an upsampling framework without the need for a bottleneck. At the final stage, the untouched CbCr-channels are combined with the refined Y-channel to restore the clean image. Note that ResUpNet is model agnostic as it does not modify the DNN structure. ResUpNet is trained end-to-end in Pytorch and the results are compared to existing defence techniques in the input transformation category. Our results show that our approach achieves the best balance between defence against adversarial attacks such as FGSM, PGD and DDN and maintaining the original accuracies of VGG-16, ResNet50 and DenseNet121 on clean images. We perform another experiment to show that learning adversarial perturbations only for the Y-channel results in higher fooling rates for the same perturbation magnitude.