 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Open Domain Dialogue Generation with Latent Images
Apr 04, 2020

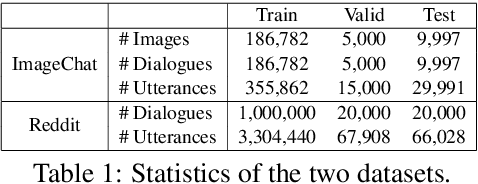
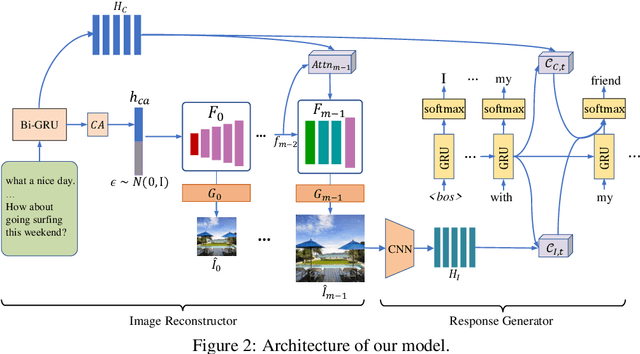
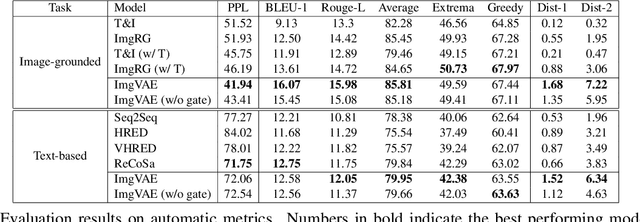
We consider grounding open domain dialogues with images. Existing work assumes that both an image and a textual context are available, but image-grounded dialogues by nature are more difficult to obtain than textual dialogues. Thus, we propose learning a response generation model with both image-grounded dialogues and textual dialogues by assuming that there is a latent variable in a textual dialogue that represents the image, and trying to recover the latent image through text-to-image generation techniques. The likelihood of the two types of dialogues is then formulated by a response generator and an image reconstructor that are learned within a conditional variational auto-encoding framework. Empirical studies are conducted in both image-grounded conversation and text-based conversation. In the first scenario, image-grounded dialogues, especially under a low-resource setting, can be effectively augmented by textual dialogues with latent images; while in the second scenario, latent images can enrich the content of responses and at the same time keep them relevant to contexts.
DeepLiDAR: Deep Surface Normal Guided Depth Prediction for Outdoor Scene from Sparse LiDAR Data and Single Color Image
Dec 02, 2018
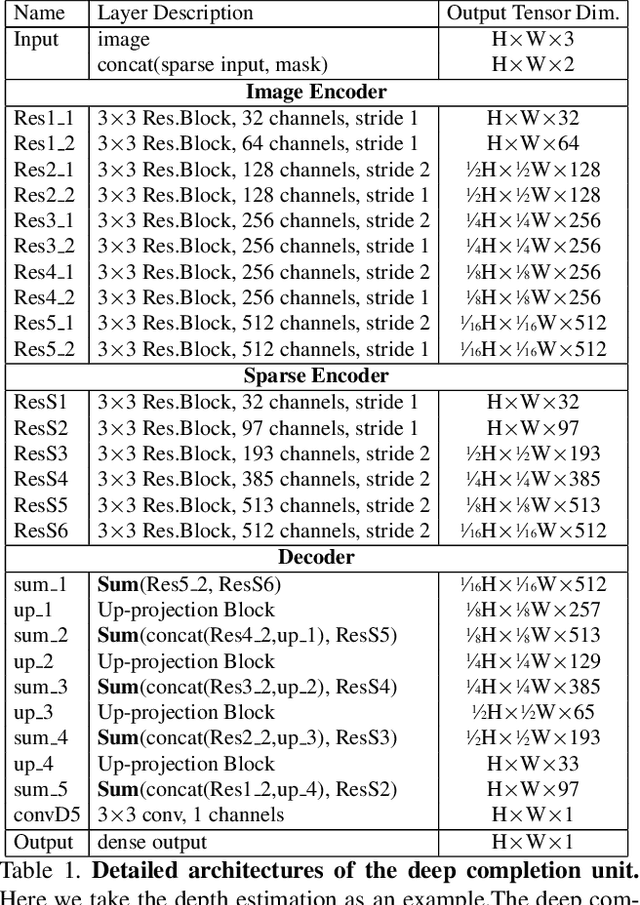
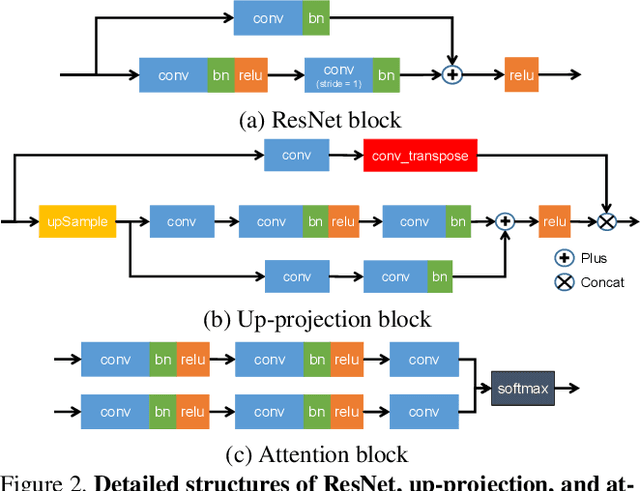
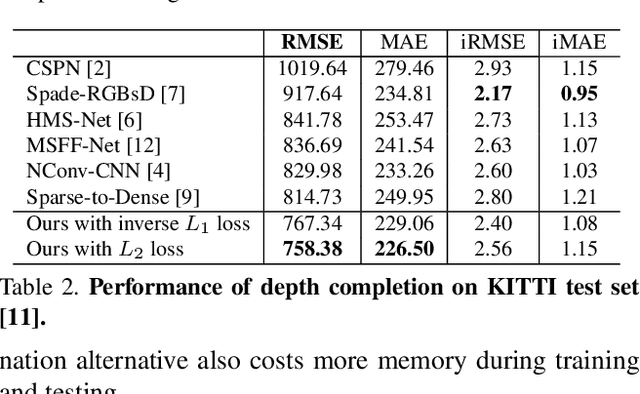
In this paper, we propose a deep learning architecture that produces accurate dense depth for the outdoor scene from a single color image and a sparse depth. Inspired by the indoor depth completion, our network estimates surface normals as the intermediate representation to produce dense depth, and can be trained end-to-end. With a modified encoder-decoder structure, our network effectively fuses the dense color image and the sparse LiDAR depth. To address outdoor specific challenges, our network predicts a confidence mask to handle mixed LiDAR signals near foreground boundaries due to occlusion, and combines estimates from the color image and surface normals with learned attention maps to improve the depth accuracy especially for distant areas. Extensive experiments demonstrate that our model improves upon the state-of-the-art performance on KITTI depth completion benchmark. Ablation study shows the positive impact of each model components to the final performance, and comprehensive analysis shows that our model generalizes well to the input with higher sparsity or from indoor scenes.
Deep Learning Framework for Multi-class Breast Cancer Histology Image Classification
Feb 03, 2018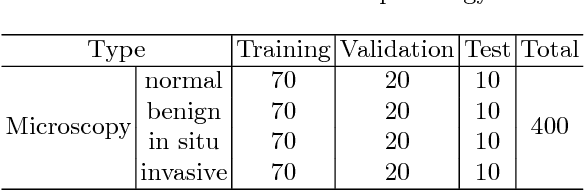

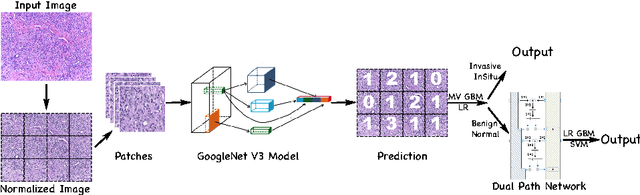
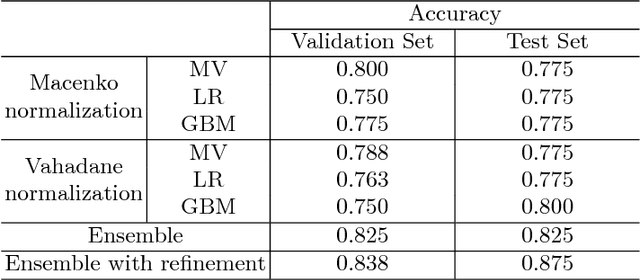
In this work, we present a deep learning framework for multi-class breast cancer image classification as our submission to the International Conference on Image Analysis and Recognition (ICIAR) 2018 Grand Challenge on BreAst Cancer Histology images (BACH). As these histology images are too large to fit into GPU memory, we first propose using Inception V3 to perform patch level classification. The patch level predictions are then passed through an ensemble fusion framework involving majority voting, gradient boosting machine (GBM), and logistic regression to obtain the image level prediction. We improve the sensitivity of the Normal and Benign predicted classes by designing a Dual Path Network (DPN) to be used as a feature extractor where these extracted features are further sent to a second layer of ensemble prediction fusion using GBM, logistic regression, and support vector machine (SVM) to refine predictions. Experimental results demonstrate our framework shows a 12.5$\%$ improvement over the state-of-the-art model.
Performance of Image Registration Tools on High-Resolution 3D Brain Images
Jul 13, 2018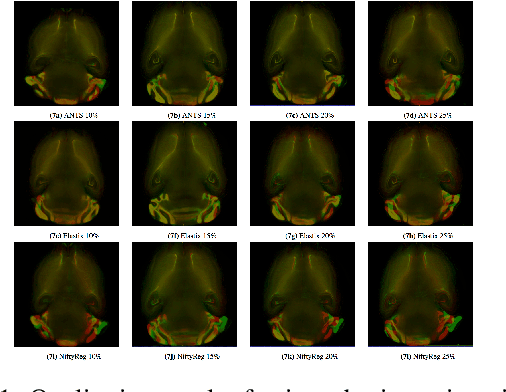
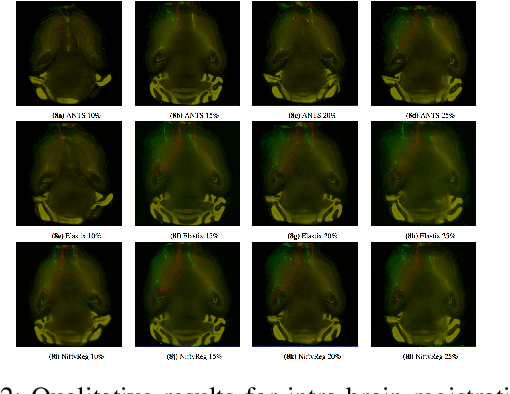
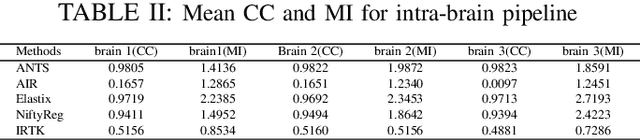
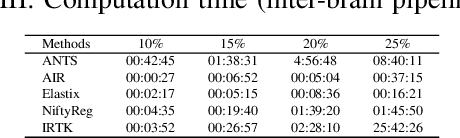
Recent progress in tissue clearing has allowed for the imaging of entire organs at single-cell resolution. These methods produce very large 3D images (several gigabytes for a whole mouse brain). A necessary step in analysing these images is registration across samples. Existing methods of registration were developed for lower resolution image modalities (e.g. MRI) and it is unclear whether their performance and accuracy is satisfactory at this larger scale. In this study, we used data from different mouse brains cleared with the CUBIC protocol to evaluate five freely available image registration tools. We used several performance metrics to assess accuracy, and completion time as a measure of efficiency. The results of this evaluation suggest that the ANTS registration tool provides the best registration accuracy while Elastix has the highest computational efficiency among the methods with an acceptable accuracy. The results also highlight the need to develop new registration methods optimised for these high-resolution 3D images.
Image processing using miniKanren
Mar 16, 2014
An integral image is one of the most efficient optimization technique for image processing. However an integral image is only a special case of delayed stream or memoization. This research discusses generalizing concept of integral image optimization technique, and how to generate an integral image optimized program code automatically from abstracted image processing algorithm. In oder to abstruct algorithms, we forces to miniKanren.
Spectral Synthesis for Satellite-to-Satellite Translation
Oct 12, 2020Earth observing satellites carrying multi-spectral sensors are widely used to monitor the physical and biological states of the atmosphere, land, and oceans. These satellites have different vantage points above the earth and different spectral imaging bands resulting in inconsistent imagery from one to another. This presents challenges in building downstream applications. What if we could generate synthetic bands for existing satellites from the union of all domains? We tackle the problem of generating synthetic spectral imagery for multispectral sensors as an unsupervised image-to-image translation problem with partial labels and introduce a novel shared spectral reconstruction loss. Simulated experiments performed by dropping one or more spectral bands show that cross-domain reconstruction outperforms measurements obtained from a second vantage point. On a downstream cloud detection task, we show that generating synthetic bands with our model improves segmentation performance beyond our baseline. Our proposed approach enables synchronization of multispectral data and provides a basis for more homogeneous remote sensing datasets.
ICAM-reg: Interpretable Classification and Regression with Feature Attribution for Mapping Neurological Phenotypes in Individual Scans
Mar 03, 2021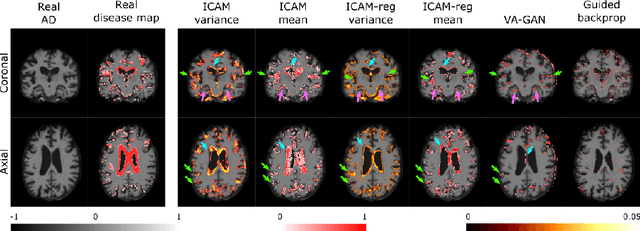
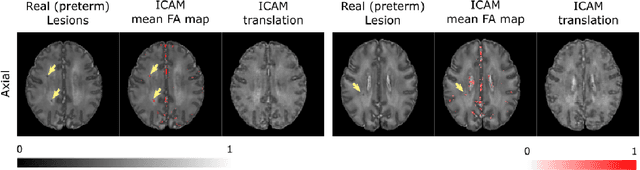
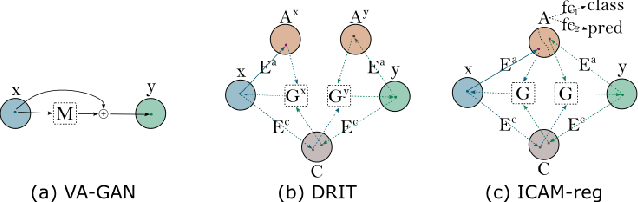
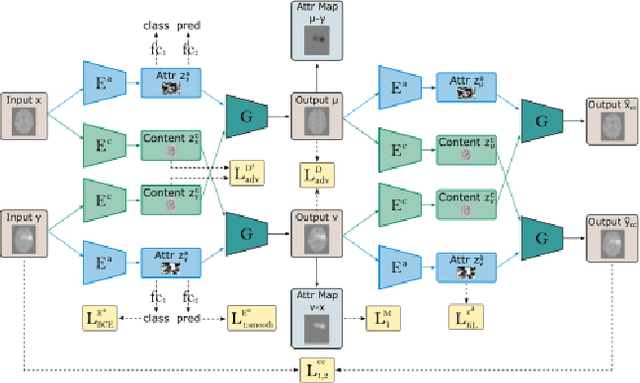
An important goal of medical imaging is to be able to precisely detect patterns of disease specific to individual scans; however, this is challenged in brain imaging by the degree of heterogeneity of shape and appearance. Traditional methods, based on image registration to a global template, historically fail to detect variable features of disease, as they utilise population-based analyses, suited primarily to studying group-average effects. In this paper we therefore take advantage of recent developments in generative deep learning to develop a method for simultaneous classification, or regression, and feature attribution (FA). Specifically, we explore the use of a VAE-GAN translation network called ICAM, to explicitly disentangle class relevant features from background confounds for improved interpretability and regression of neurological phenotypes. We validate our method on the tasks of Mini-Mental State Examination (MMSE) cognitive test score prediction for the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, as well as brain age prediction, for both neurodevelopment and neurodegeneration, using the developing Human Connectome Project (dHCP) and UK Biobank datasets. We show that the generated FA maps can be used to explain outlier predictions and demonstrate that the inclusion of a regression module improves the disentanglement of the latent space. Our code is freely available on Github https://github.com/CherBass/ICAM.
Adaptive Image Denoising by Mixture Adaptation
Jun 25, 2016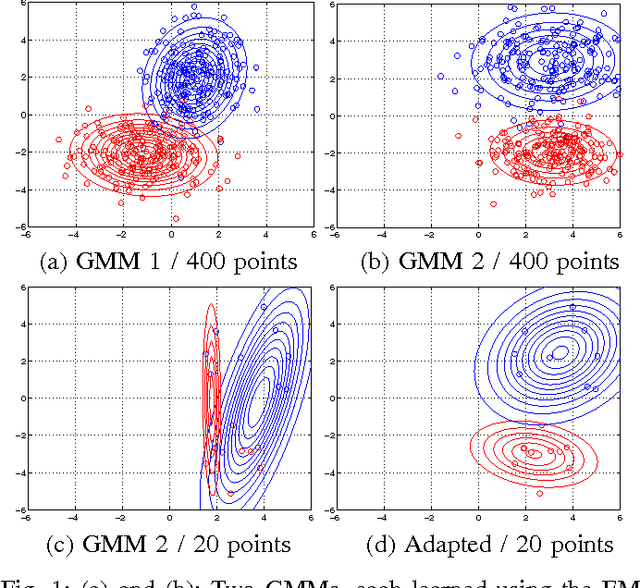

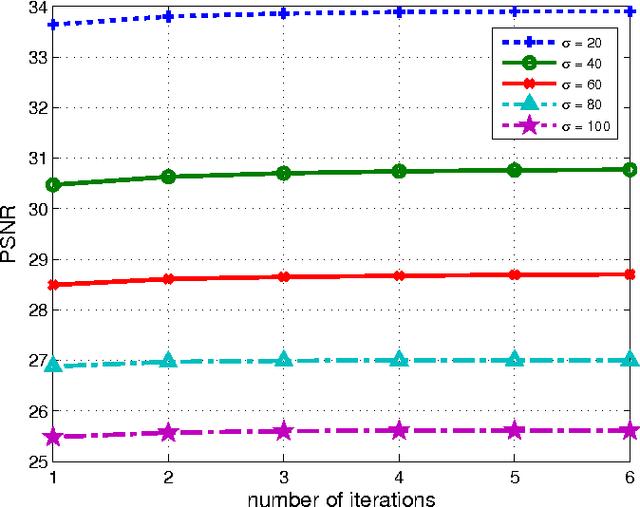
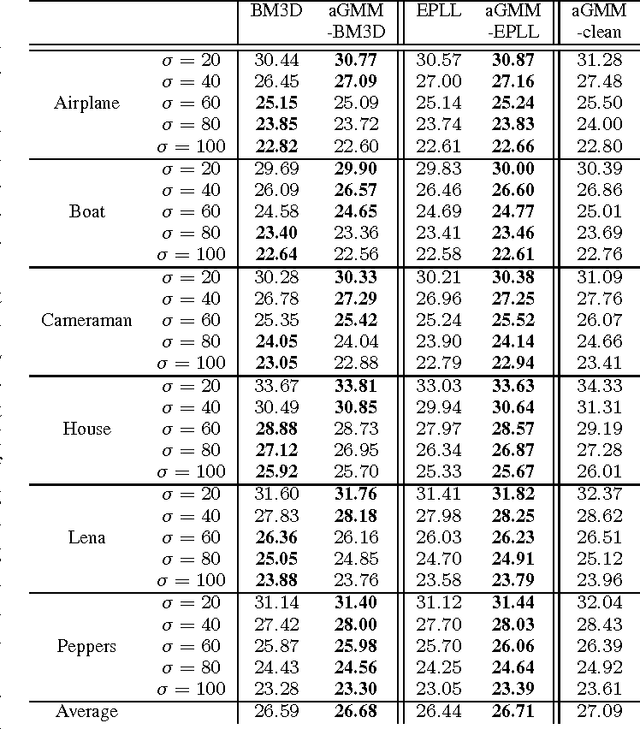
We propose an adaptive learning procedure to learn patch-based image priors for image denoising. The new algorithm, called the Expectation-Maximization (EM) adaptation, takes a generic prior learned from a generic external database and adapts it to the noisy image to generate a specific prior. Different from existing methods that combine internal and external statistics in ad-hoc ways, the proposed algorithm is rigorously derived from a Bayesian hyper-prior perspective. There are two contributions of this paper: First, we provide full derivation of the EM adaptation algorithm and demonstrate methods to improve the computational complexity. Second, in the absence of the latent clean image, we show how EM adaptation can be modified based on pre-filtering. Experimental results show that the proposed adaptation algorithm yields consistently better denoising results than the one without adaptation and is superior to several state-of-the-art algorithms.
Backtracking Spatial Pyramid Pooling (SPP)-based Image Classifier for Weakly Supervised Top-down Salient Object Detection
Aug 14, 2018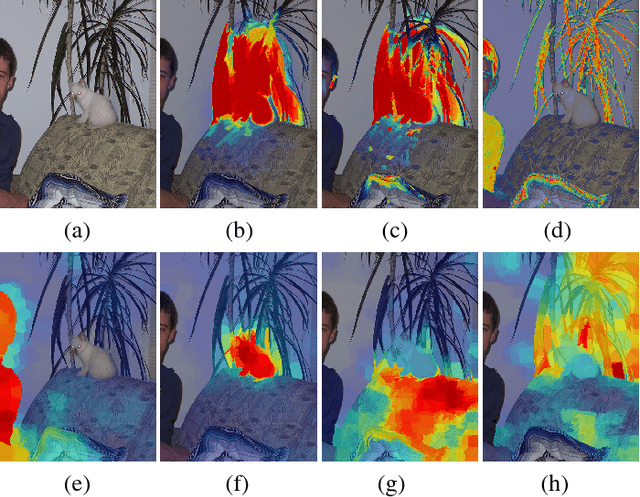
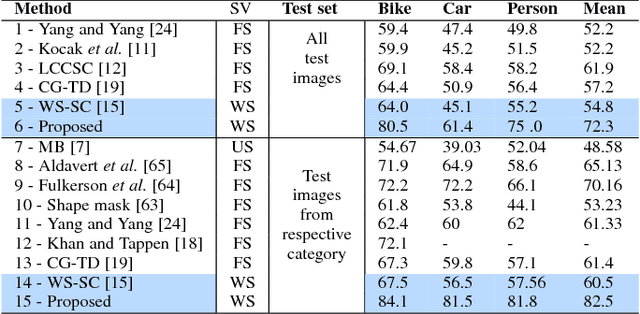


Top-down saliency models produce a probability map that peaks at target locations specified by a task/goal such as object detection. They are usually trained in a fully supervised setting involving pixel-level annotations of objects. We propose a weakly supervised top-down saliency framework using only binary labels that indicate the presence/absence of an object in an image. First, the probabilistic contribution of each image region to the confidence of a CNN-based image classifier is computed through a backtracking strategy to produce top-down saliency. From a set of saliency maps of an image produced by fast bottom-up saliency approaches, we select the best saliency map suitable for the top-down task. The selected bottom-up saliency map is combined with the top-down saliency map. Features having high combined saliency are used to train a linear SVM classifier to estimate feature saliency. This is integrated with combined saliency and further refined through a multi-scale superpixel-averaging of saliency map. We evaluate the performance of the proposed weakly supervised topdown saliency and achieve comparable performance with fully supervised approaches. Experiments are carried out on seven challenging datasets and quantitative results are compared with 40 closely related approaches across 4 different applications.
* 14 pages, 7 figures
Chest X-Rays Image Inpainting with Context Encoders
Dec 03, 2018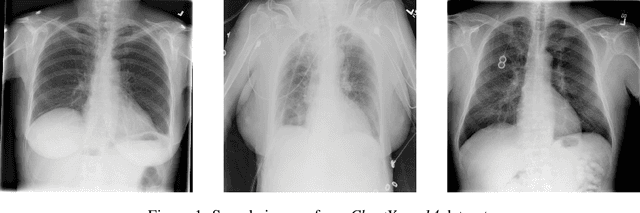

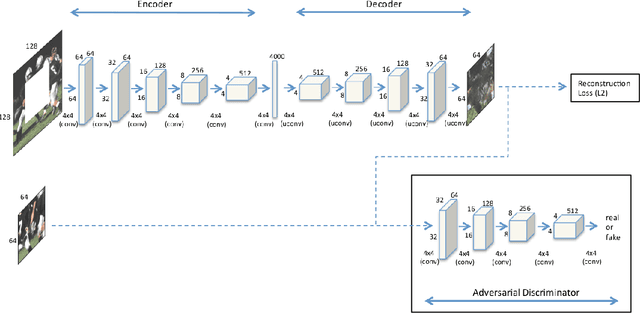
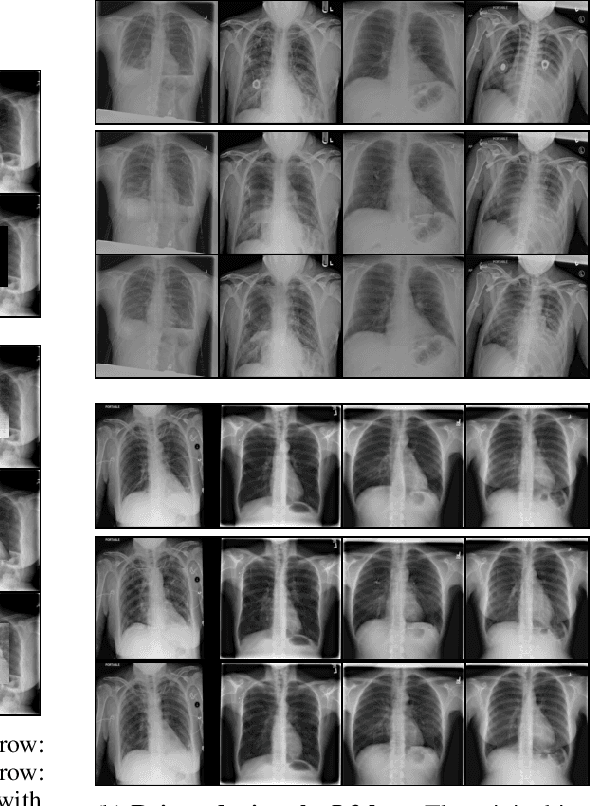
Chest X-rays are one of the most commonly used technologies for medical diagnosis. Many deep learning models have been proposed to improve and automate the abnormality detection task on this type of data. In this paper, we propose a different approach based on image inpainting under adversarial training first introduced by Goodfellow et al. We configure the context encoder model for this task and train it over 1.1M 128x128 images from healthy X-rays. The goal of our model is to reconstruct the missing central 64x64 patch. Once the model has learned how to inpaint healthy tissue, we test its performance on images with and without abnormalities. We discuss and motivate our results considering PSNR, MSE and SSIM scores as evaluation metrics. In addition, we conduct a 2AFC observer study showing that in half of the times an expert is unable to distinguish real images from the ones reconstructed using our model. By computing and visualizing the pixel-wise difference between source and reconstructed images, we can highlight abnormalities to simplify further detection and classification tasks.