 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PyTorch-Hebbian: facilitating local learning in a deep learning framework
Jan 31, 2021


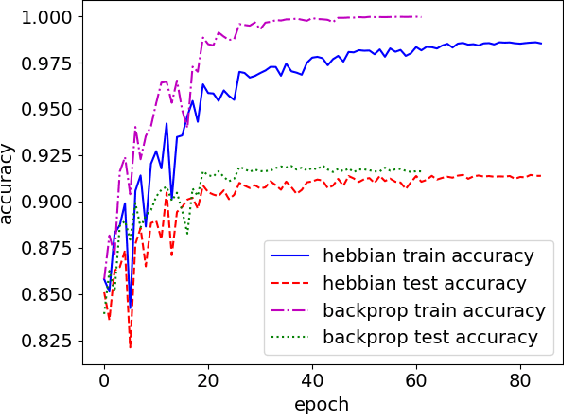
Recently, unsupervised local learning, based on Hebb's idea that change in synaptic efficacy depends on the activity of the pre- and postsynaptic neuron only, has shown potential as an alternative training mechanism to backpropagation. Unfortunately, Hebbian learning remains experimental and rarely makes it way into standard deep learning frameworks. In this work, we investigate the potential of Hebbian learning in the context of standard deep learning workflows. To this end, a framework for thorough and systematic evaluation of local learning rules in existing deep learning pipelines is proposed. Using this framework, the potential of Hebbian learned feature extractors for image classification is illustrated. In particular, the framework is used to expand the Krotov-Hopfield learning rule to standard convolutional neural networks without sacrificing accuracy compared to end-to-end backpropagation. The source code is available at https://github.com/Joxis/pytorch-hebbian.
Densely Connected High Order Residual Network for Single Frame Image Super Resolution
Apr 16, 2018


Deep convolutional neural networks (DCNN) have been widely adopted for research on super resolution recently, however previous work focused mainly on stacking as many layers as possible in their model, in this paper, we present a new perspective regarding to image restoration problems that we can construct the neural network model reflecting the physical significance of the image restoration process, that is, embedding the a priori knowledge of image restoration directly into the structure of our neural network model, we employed a symmetric non-linear colorspace, the sigmoidal transfer, to replace traditional transfers such as, sRGB, Rec.709, which are asymmetric non-linear colorspaces, we also propose a "reuse plus patch" method to deal with super resolution of different scaling factors, our proposed methods and model show generally superior performance over previous work even though our model was only roughly trained and could still be underfitting the training set.
Test-Time Adaptation for Super-Resolution: You Only Need to Overfit on a Few More Images
Apr 06, 2021
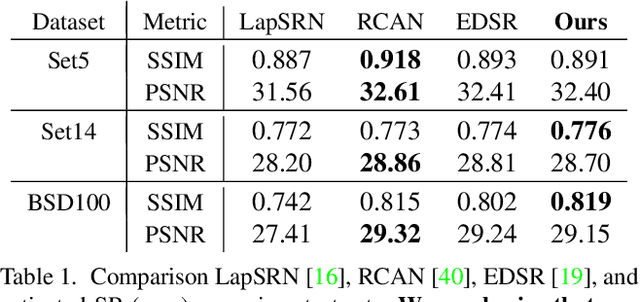
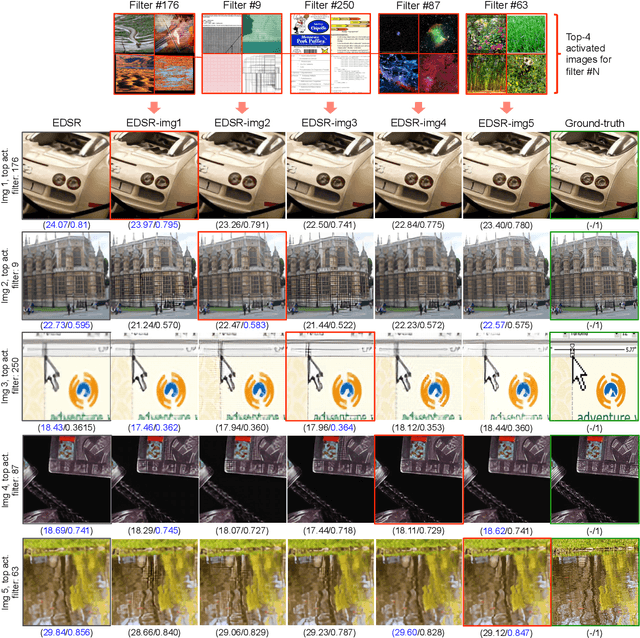
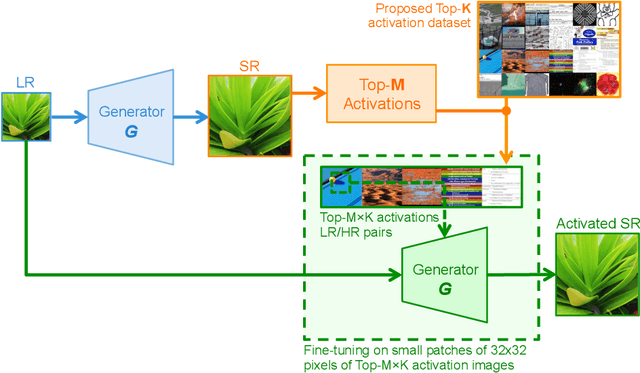
Existing reference (RF)-based super-resolution (SR) models try to improve perceptual quality in SR under the assumption of the availability of high-resolution RF images paired with low-resolution (LR) inputs at testing. As the RF images should be similar in terms of content, colors, contrast, etc. to the test image, this hinders the applicability in a real scenario. Other approaches to increase the perceptual quality of images, including perceptual loss and adversarial losses, tend to dramatically decrease fidelity to the ground-truth through significant decreases in PSNR/SSIM. Addressing both issues, we propose a simple yet universal approach to improve the perceptual quality of the HR prediction from a pre-trained SR network on a given LR input by further fine-tuning the SR network on a subset of images from the training dataset with similar patterns of activation as the initial HR prediction, with respect to the filters of a feature extractor. In particular, we show the effects of fine-tuning on these images in terms of the perceptual quality and PSNR/SSIM values. Contrary to perceptually driven approaches, we demonstrate that the fine-tuned network produces a HR prediction with both greater perceptual quality and minimal changes to the PSNR/SSIM with respect to the initial HR prediction. Further, we present novel numerical experiments concerning the filters of SR networks, where we show through filter correlation, that the filters of the fine-tuned network from our method are closer to "ideal" filters, than those of the baseline network or a network fine-tuned on random images.
Compositional GAN: Learning Conditional Image Composition
Aug 23, 2018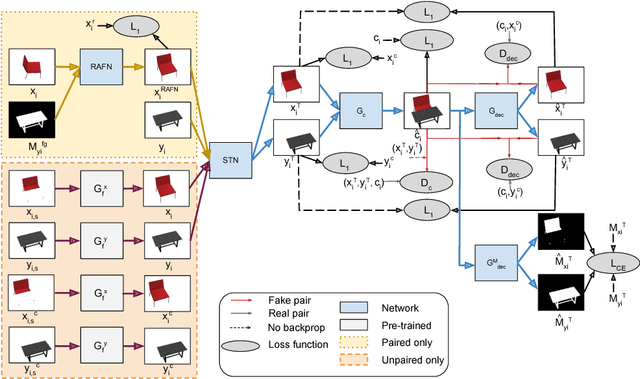

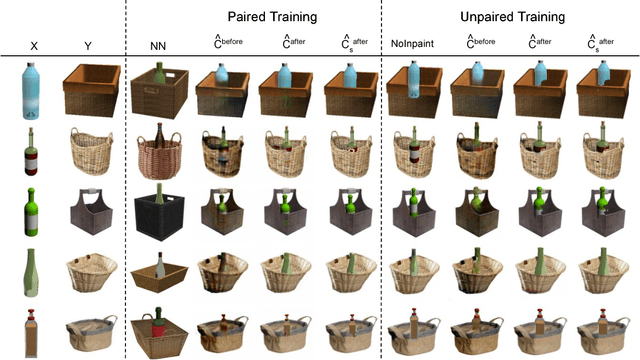
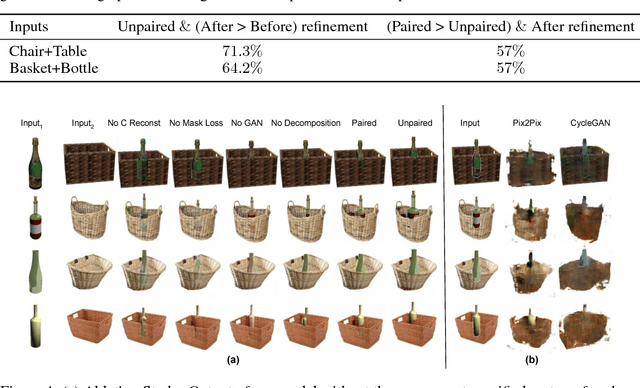
Generative Adversarial Networks (GANs) can produce images of surprising complexity and realism, but are generally modeled to sample from a single latent source ignoring the explicit spatial interaction between multiple entities that could be present in a scene. Capturing such complex interactions between different objects in the world, including their relative scaling, spatial layout, occlusion, or viewpoint transformation is a challenging problem. In this work, we propose to model object composition in a GAN framework as a self-consistent composition-decomposition network. Our model is conditioned on the object images from their marginal distributions to generate a realistic image from their joint distribution by explicitly learning the possible interactions. We evaluate our model through qualitative experiments and user evaluations in both the scenarios when either paired or unpaired examples for the individual object images and the joint scenes are given during training. Our results reveal that the learned model captures potential interactions between the two object domains given as input to output new instances of composed scene at test time in a reasonable fashion.
Semantic Equivalent Adversarial Data Augmentation for Visual Question Answering
Jul 19, 2020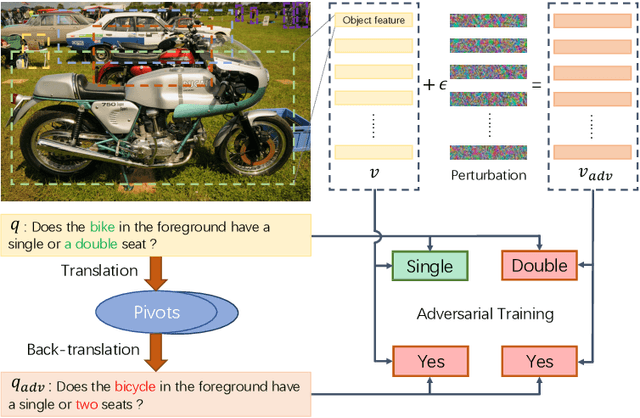
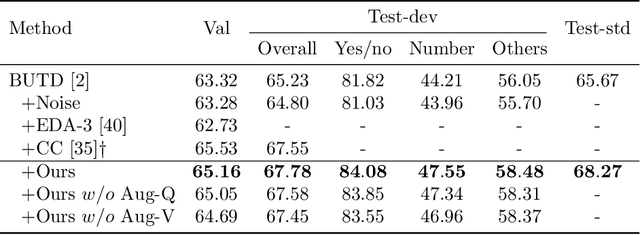


Visual Question Answering (VQA) has achieved great success thanks to the fast development of deep neural networks (DNN). On the other hand, the data augmentation, as one of the major tricks for DNN, has been widely used in many computer vision tasks. However, there are few works studying the data augmentation problem for VQA and none of the existing image based augmentation schemes (such as rotation and flipping) can be directly applied to VQA due to its semantic structure -- an $\langle image, question, answer\rangle$ triplet needs to be maintained correctly. For example, a direction related Question-Answer (QA) pair may not be true if the associated image is rotated or flipped. In this paper, instead of directly manipulating images and questions, we use generated adversarial examples for both images and questions as the augmented data. The augmented examples do not change the visual properties presented in the image as well as the \textbf{semantic} meaning of the question, the correctness of the $\langle image, question, answer\rangle$ is thus still maintained. We then use adversarial learning to train a classic VQA model (BUTD) with our augmented data. We find that we not only improve the overall performance on VQAv2, but also can withstand adversarial attack effectively, compared to the baseline model. The source code is available at https://github.com/zaynmi/seada-vqa.
Self supervised contrastive learning for digital histopathology
Nov 27, 2020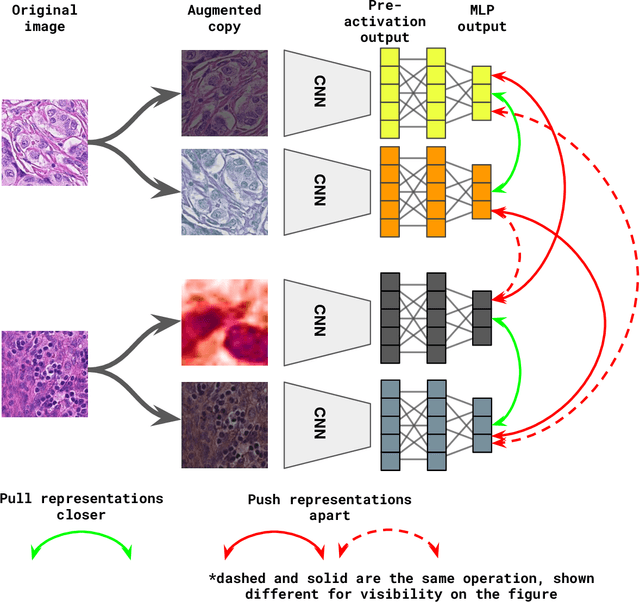
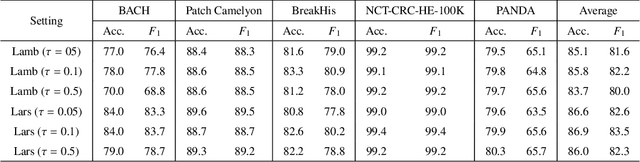
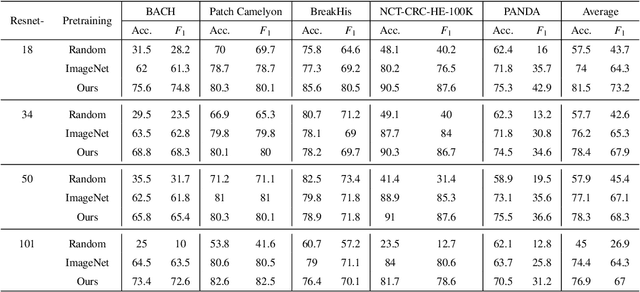
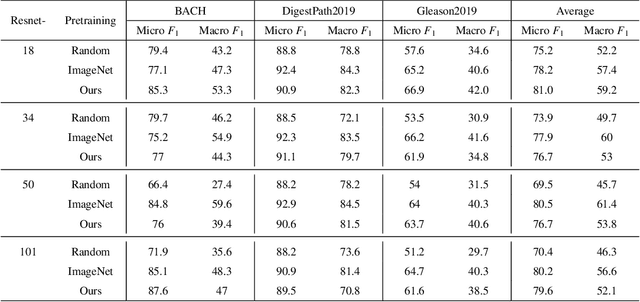
Unsupervised learning has been a long-standing goal of machine learning and is especially important for medical image analysis, where the learning can compensate for the scarcity of labeled datasets. A promising subclass of unsupervised learning is self-supervised learning, which aims to learn salient features using the raw input as the learning signal. In this paper, we use a contrastive self-supervised learning method Chen et al. (2020a) that achieved state-of-the-art results on natural-scene images, and apply this method to digital histopathology by collecting and training on 60 histopathology datasets without any labels. We find that combining multiple multi-organ datasets with different types of staining and resolution properties improves the quality of the learned features. Furthermore, we find drastically subsampling a dataset (e.g., using ? 1% of the available image patches) does not negatively impact the learned representations, unlike training on natural-scene images. Linear classifiers trained on top of the learned features show that networks pretrained on digital histopathology datasets perform better than ImageNet pretrained networks, boosting task performances up to 7.5% in accuracy and 8.9% in F1. These findings may also be useful when applying newer contrastive techniques to histopathology data. Pretrained PyTorch models are made publicly available at https://github.com/ozanciga/self-supervised-histopathology.
Improving Actor-Critic Reinforcement Learning via Hamiltonian Policy
Mar 22, 2021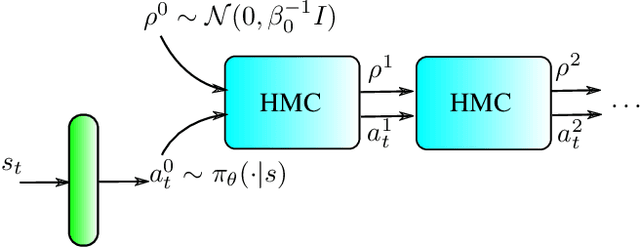

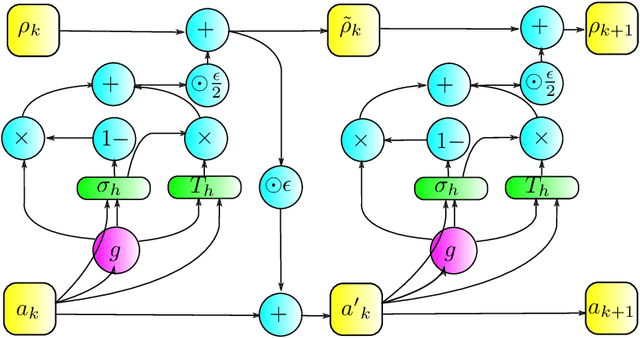
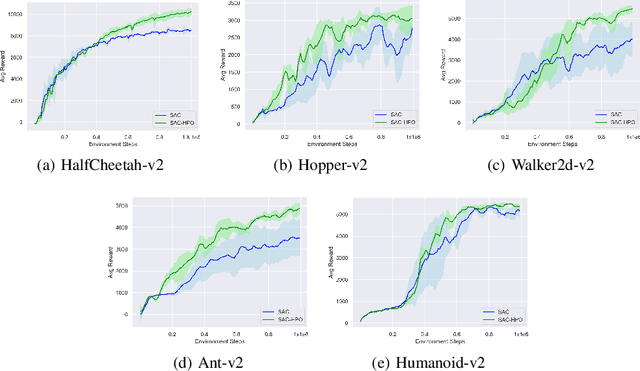
Approximating optimal policies in reinforcement learning (RL) is often necessary in many real-world scenarios, which is termed as policy optimization. By viewing the reinforcement learning from the perspective of variational inference (VI), the policy network is trained to obtain the approximate posterior of actions given the optimality criteria. However, in practice, the policy optimization may lead to suboptimal policy estimates due to the amortization gap and insufficient exploration. In this work, inspired by the previous use of Hamiltonian Monte Carlo (HMC) in VI, we propose to integrate policy optimization with HMC. As such we choose evolving actions from the base policy according to HMC. First, HMC can improve the policy distribution to better approximate the posterior and hence reduces the amortization gap. Second, HMC can also guide the exploration more to the regions with higher action values, enhancing the exploration efficiency. Instead of directly applying HMC into RL, we propose a new leapfrog operator to simulate the Hamiltonian dynamics. With comprehensive empirical experiments on continuous control baselines, including MuJoCo, PyBullet Roboschool and DeepMind Control Suite, we show that the proposed approach is a data-efficient, and an easy-to-implement improvement over previous policy optimization methods. Besides, the proposed approach can also outperform previous methods on DeepMind Control Suite, which has image-based high-dimensional observation space.
EvoSplit: An evolutionary approach to split a multi-label data set into disjoint subsets
Feb 12, 2021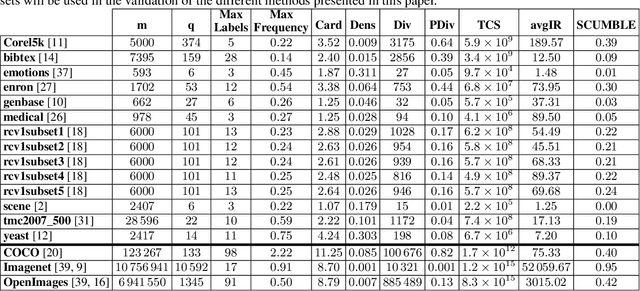

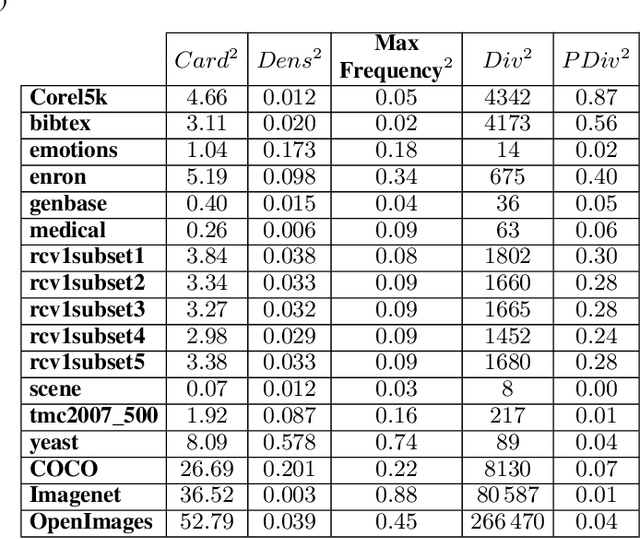
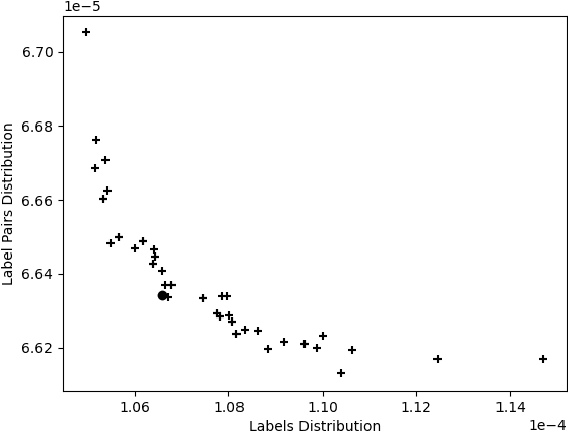
This paper presents a new evolutionary approach, EvoSplit, for the distribution of multi-label data sets into disjoint subsets for supervised machine learning. Currently, data set providers either divide a data set randomly or using iterative stratification, a method that aims to maintain the label (or label pair) distribution of the original data set into the different subsets. Following the same aim, this paper first introduces a single-objective evolutionary approach that tries to obtain a split that maximizes the similarity between those distributions independently. Second, a new multi-objective evolutionary algorithm is presented to maximize the similarity considering simultaneously both distributions (label and label pair). Both approaches are validated using well-known multi-label data sets as well as large image data sets currently used in computer vision and machine learning applications. EvoSplit improves the splitting of a data set in comparison to the iterative stratification following different measures: Label Distribution, Label Pair Distribution, Examples Distribution, folds and fold-label pairs with zero positive examples.
STGAN: A Unified Selective Transfer Network for Arbitrary Image Attribute Editing
Apr 22, 2019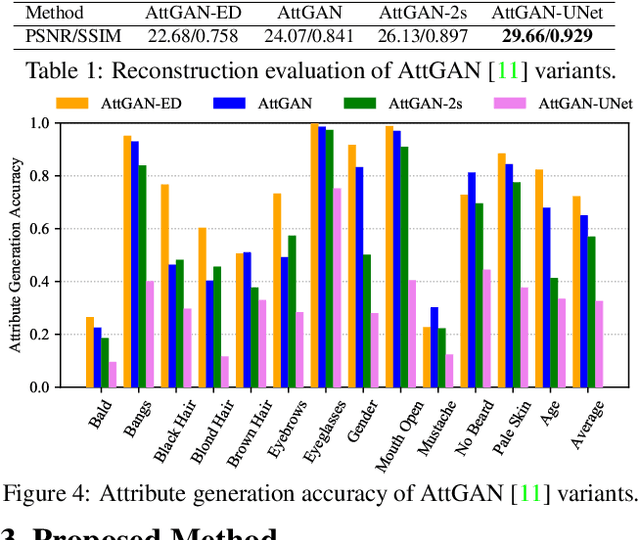



Arbitrary attribute editing generally can be tackled by incorporating encoder-decoder and generative adversarial networks. However, the bottleneck layer in encoder-decoder usually gives rise to blurry and low quality editing result. And adding skip connections improves image quality at the cost of weakened attribute manipulation ability. Moreover, existing methods exploit target attribute vector to guide the flexible translation to desired target domain. In this work, we suggest to address these issues from selective transfer perspective. Considering that specific editing task is certainly only related to the changed attributes instead of all target attributes, our model selectively takes the difference between target and source attribute vectors as input. Furthermore, selective transfer units are incorporated with encoder-decoder to adaptively select and modify encoder feature for enhanced attribute editing. Experiments show that our method (i.e., STGAN) simultaneously improves attribute manipulation accuracy as well as perception quality, and performs favorably against state-of-the-arts in arbitrary facial attribute editing and season translation.
Bimodal Stereo: Joint Shape and Pose Estimation from Color-Depth Image Pair
May 16, 2019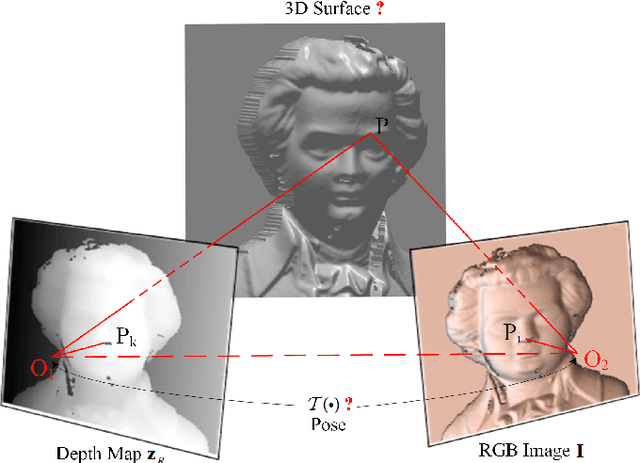
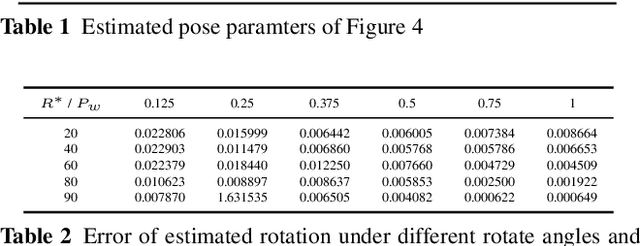
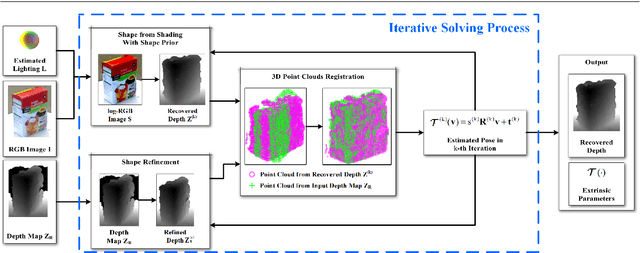
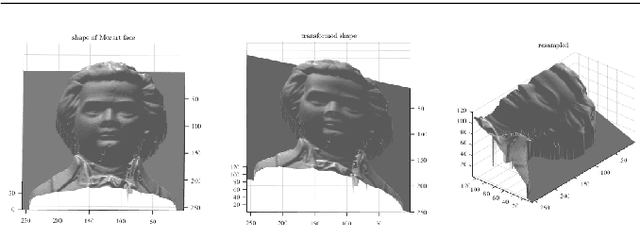
Mutual calibration between color and depth cameras is a challenging topic in multi-modal data registration. In this paper, we are confronted with a "Bimodal Stereo" problem, which aims to solve camera pose from a pair of an uncalibrated color image and a depth map from different views automatically. To address this problem, an iterative Shape-from-Shading (SfS) based framework is proposed to estimate shape and pose simultaneously. In the pipeline, the estimated shape is refined by the shape prior from the given depth map under the estimated pose. Meanwhile, the estimated pose is improved by the registration of estimated shape and shape from given depth map. We also introduce a shading based refinement in the pipeline to address noisy depth map with holes. Extensive experiments showed that through our method, both the depth map, the recovered shape as well as its pose can be desirably refined and recovered.