 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Equivalent Adversarial Data Augmentation for Visual Question Answering
Paper and Code
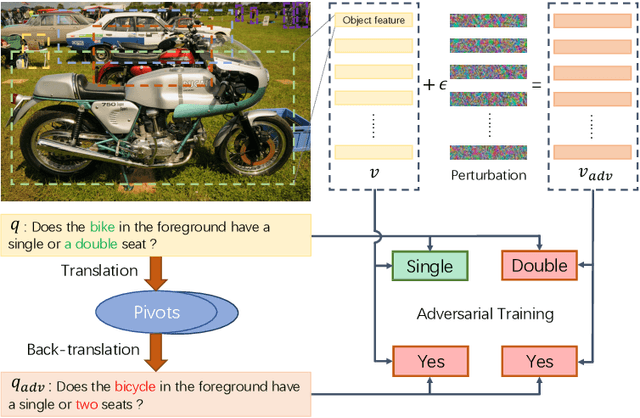
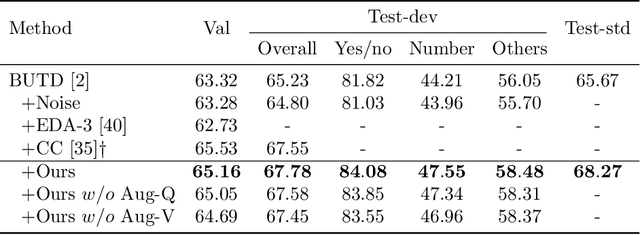


Visual Question Answering (VQA) has achieved great success thanks to the fast development of deep neural networks (DNN). On the other hand, the data augmentation, as one of the major tricks for DNN, has been widely used in many computer vision tasks. However, there are few works studying the data augmentation problem for VQA and none of the existing image based augmentation schemes (such as rotation and flipping) can be directly applied to VQA due to its semantic structure -- an $\langle image, question, answer\rangle$ triplet needs to be maintained correctly. For example, a direction related Question-Answer (QA) pair may not be true if the associated image is rotated or flipped. In this paper, instead of directly manipulating images and questions, we use generated adversarial examples for both images and questions as the augmented data. The augmented examples do not change the visual properties presented in the image as well as the \textbf{semantic} meaning of the question, the correctness of the $\langle image, question, answer\rangle$ is thus still maintained. We then use adversarial learning to train a classic VQA model (BUTD) with our augmented data. We find that we not only improve the overall performance on VQAv2, but also can withstand adversarial attack effectively, compared to the baseline model. The source code is available at https://github.com/zaynmi/seada-vqa.