 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Explainable Harmful Meme Detection through Multimodal Debate between Large Language Models
Jan 24, 2024
The age of social media is flooded with Internet memes, necessitating a clear grasp and effective identification of harmful ones. This task presents a significant challenge due to the implicit meaning embedded in memes, which is not explicitly conveyed through the surface text and image. However, existing harmful meme detection methods do not present readable explanations that unveil such implicit meaning to support their detection decisions. In this paper, we propose an explainable approach to detect harmful memes, achieved through reasoning over conflicting rationales from both harmless and harmful positions. Specifically, inspired by the powerful capacity of Large Language Models (LLMs) on text generation and reasoning, we first elicit multimodal debate between LLMs to generate the explanations derived from the contradictory arguments. Then we propose to fine-tune a small language model as the debate judge for harmfulness inference, to facilitate multimodal fusion between the harmfulness rationales and the intrinsic multimodal information within memes. In this way, our model is empowered to perform dialectical reasoning over intricate and implicit harm-indicative patterns, utilizing multimodal explanations originating from both harmless and harmful arguments. Extensive experiments on three public meme datasets demonstrate that our harmful meme detection approach achieves much better performance than state-of-the-art methods and exhibits a superior capacity for explaining the meme harmfulness of the model predictions.
* The first work towards explainable harmful meme detection by harnessing advanced LLMs
Frequency Masking for Universal Deepfake Detection
Jan 17, 2024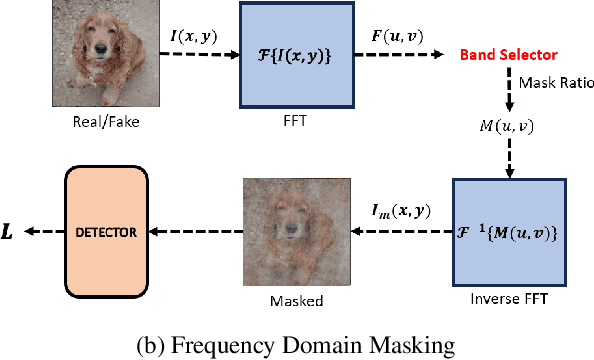
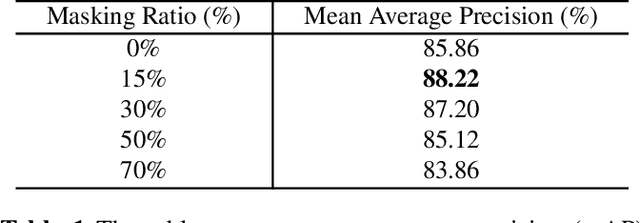
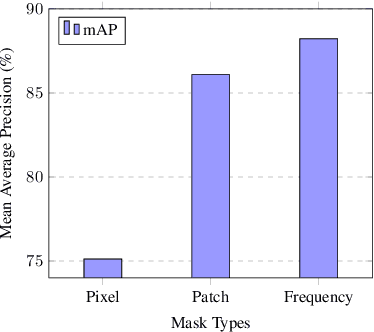
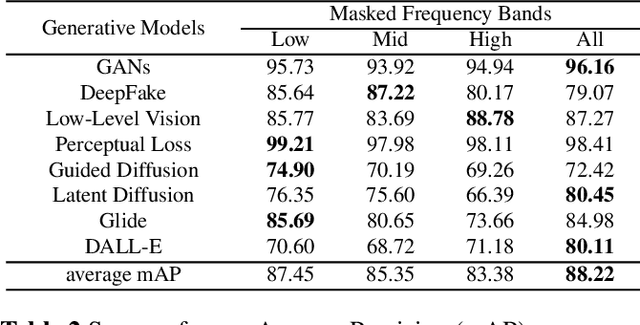
We study universal deepfake detection. Our goal is to detect synthetic images from a range of generative AI approaches, particularly from emerging ones which are unseen during training of the deepfake detector. Universal deepfake detection requires outstanding generalization capability. Motivated by recently proposed masked image modeling which has demonstrated excellent generalization in self-supervised pre-training, we make the first attempt to explore masked image modeling for universal deepfake detection. We study spatial and frequency domain masking in training deepfake detectors. Based on empirical analysis, we propose a novel deepfake detector via frequency masking. Our focus on frequency domain is different from the majority, which primarily target spatial domain detection. Our comparative analyses reveal substantial performance gains over existing methods. Code and models are publicly available.
DreamTuner: Single Image is Enough for Subject-Driven Generation
Dec 21, 2023Diffusion-based models have demonstrated impressive capabilities for text-to-image generation and are expected for personalized applications of subject-driven generation, which require the generation of customized concepts with one or a few reference images. However, existing methods based on fine-tuning fail to balance the trade-off between subject learning and the maintenance of the generation capabilities of pretrained models. Moreover, other methods that utilize additional image encoders tend to lose important details of the subject due to encoding compression. To address these challenges, we propose DreamTurner, a novel method that injects reference information from coarse to fine to achieve subject-driven image generation more effectively. DreamTurner introduces a subject-encoder for coarse subject identity preservation, where the compressed general subject features are introduced through an attention layer before visual-text cross-attention. We then modify the self-attention layers within pretrained text-to-image models to self-subject-attention layers to refine the details of the target subject. The generated image queries detailed features from both the reference image and itself in self-subject-attention. It is worth emphasizing that self-subject-attention is an effective, elegant, and training-free method for maintaining the detailed features of customized subjects and can serve as a plug-and-play solution during inference. Finally, with additional subject-driven fine-tuning, DreamTurner achieves remarkable performance in subject-driven image generation, which can be controlled by a text or other conditions such as pose. For further details, please visit the project page at https://dreamtuner-diffusion.github.io/.
Beyond Subspace Isolation: Many-to-Many Transformer for Light Field Image Super-resolution
Jan 01, 2024The effective extraction of spatial-angular features plays a crucial role in light field image super-resolution (LFSR) tasks, and the introduction of convolution and Transformers leads to significant improvement in this area. Nevertheless, due to the large 4D data volume of light field images, many existing methods opted to decompose the data into a number of lower-dimensional subspaces and perform Transformers in each sub-space individually. As a side effect, these methods inadvertently restrict the self-attention mechanisms to a One-to-One scheme accessing only a limited subset of LF data, explicitly preventing comprehensive optimization on all spatial and angular cues. In this paper, we identify this limitation as subspace isolation and introduce a novel Many-to-Many Transformer (M2MT) to address it. M2MT aggregates angular information in the spatial subspace before performing the self-attention mechanism. It enables complete access to all information across all sub-aperture images (SAIs) in a light field image. Consequently, M2MT is enabled to comprehensively capture long-range correlation dependencies. With M2MT as the pivotal component, we develop a simple yet effective M2MT network for LFSR. Our experimental results demonstrate that M2MT achieves state-of-the-art performance across various public datasets. We further conduct in-depth analysis using local attribution maps (LAM) to obtain visual interpretability, and the results validate that M2MT is empowered with a truly non-local context in both spatial and angular subspaces to mitigate subspace isolation and acquire effective spatial-angular representation.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 16, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.
Context Enhanced Transformer for Single Image Object Detection
Dec 26, 2023With the increasing importance of video data in real-world applications, there is a rising need for efficient object detection methods that utilize temporal information. While existing video object detection (VOD) techniques employ various strategies to address this challenge, they typically depend on locally adjacent frames or randomly sampled images within a clip. Although recent Transformer-based VOD methods have shown promising results, their reliance on multiple inputs and additional network complexity to incorporate temporal information limits their practical applicability. In this paper, we propose a novel approach to single image object detection, called Context Enhanced TRansformer (CETR), by incorporating temporal context into DETR using a newly designed memory module. To efficiently store temporal information, we construct a class-wise memory that collects contextual information across data. Additionally, we present a classification-based sampling technique to selectively utilize the relevant memory for the current image. In the testing, We introduce a test-time memory adaptation method that updates individual memory functions by considering the test distribution. Experiments with CityCam and ImageNet VID datasets exhibit the efficiency of the framework on various video systems. The project page and code will be made available at: https://ku-cvlab.github.io/CETR.
Expediting Contrastive Language-Image Pretraining via Self-distilled Encoders
Dec 19, 2023Recent advances in vision language pretraining (VLP) have been largely attributed to the large-scale data collected from the web. However, uncurated dataset contains weakly correlated image-text pairs, causing data inefficiency. To address the issue, knowledge distillation have been explored at the expense of extra image and text momentum encoders to generate teaching signals for misaligned image-text pairs. In this paper, our goal is to resolve the misalignment problem with an efficient distillation framework. To this end, we propose ECLIPSE: Expediting Contrastive Language-Image Pretraining with Self-distilled Encoders. ECLIPSE features a distinctive distillation architecture wherein a shared text encoder is utilized between an online image encoder and a momentum image encoder. This strategic design choice enables the distillation to operate within a unified projected space of text embedding, resulting in better performance. Based on the unified text embedding space, ECLIPSE compensates for the additional computational cost of the momentum image encoder by expediting the online image encoder. Through our extensive experiments, we validate that there is a sweet spot between expedition and distillation where the partial view from the expedited online image encoder interacts complementarily with the momentum teacher. As a result, ECLIPSE outperforms its counterparts while achieving substantial acceleration in inference speed.
SemanticSLAM: Learning based Semantic Map Construction and Robust Camera Localization
Jan 23, 2024Current techniques in Visual Simultaneous Localization and Mapping (VSLAM) estimate camera displacement by comparing image features of consecutive scenes. These algorithms depend on scene continuity, hence requires frequent camera inputs. However, processing images frequently can lead to significant memory usage and computation overhead. In this study, we introduce SemanticSLAM, an end-to-end visual-inertial odometry system that utilizes semantic features extracted from an RGB-D sensor. This approach enables the creation of a semantic map of the environment and ensures reliable camera localization. SemanticSLAM is scene-agnostic, which means it doesn't require retraining for different environments. It operates effectively in indoor settings, even with infrequent camera input, without prior knowledge. The strength of SemanticSLAM lies in its ability to gradually refine the semantic map and improve pose estimation. This is achieved by a convolutional long-short-term-memory (ConvLSTM) network, trained to correct errors during map construction. Compared to existing VSLAM algorithms, SemanticSLAM improves pose estimation by 17%. The resulting semantic map provides interpretable information about the environment and can be easily applied to various downstream tasks, such as path planning, obstacle avoidance, and robot navigation. The code will be publicly available at https://github.com/Leomingyangli/SemanticSLAM
* 2023 IEEE Symposium Series on Computational Intelligence (SSCI) 6 pages
DeepCERES: A Deep learning method for cerebellar lobule segmentation using ultra-high resolution multimodal MRI
Jan 23, 2024This paper introduces a novel multimodal and high-resolution human brain cerebellum lobule segmentation method. Unlike current tools that operate at standard resolution ($1 \text{ mm}^{3}$) or using mono-modal data, the proposed method improves cerebellum lobule segmentation through the use of a multimodal and ultra-high resolution ($0.125 \text{ mm}^{3}$) training dataset. To develop the method, first, a database of semi-automatically labelled cerebellum lobules was created to train the proposed method with ultra-high resolution T1 and T2 MR images. Then, an ensemble of deep networks has been designed and developed, allowing the proposed method to excel in the complex cerebellum lobule segmentation task, improving precision while being memory efficient. Notably, our approach deviates from the traditional U-Net model by exploring alternative architectures. We have also integrated deep learning with classical machine learning methods incorporating a priori knowledge from multi-atlas segmentation, which improved precision and robustness. Finally, a new online pipeline, named DeepCERES, has been developed to make available the proposed method to the scientific community requiring as input only a single T1 MR image at standard resolution.
APLe: Token-Wise Adaptive for Multi-Modal Prompt Learning
Jan 23, 2024Pre-trained Vision-Language (V-L) models set the benchmark for generalization to downstream tasks among the noteworthy contenders. Many characteristics of the V-L model have been explored in existing research including the challenge of the sensitivity to text input and the tuning process across multi-modal prompts. With the advanced utilization of the V-L model like CLIP, recent approaches deploy learnable prompts instead of hand-craft prompts to boost the generalization performance and address the aforementioned challenges. Inspired by layer-wise training, which is wildly used in image fusion, we note that using a sequential training process to adapt different modalities branches of CLIP efficiently facilitates the improvement of generalization. In the context of addressing the multi-modal prompting challenge, we propose Token-wise Adaptive for Multi-modal Prompt Learning (APLe) for tuning both modalities prompts, vision and language, as tokens in a sequential manner. APLe addresses the challenges in V-L models to promote prompt learning across both modalities, which indicates a competitive generalization performance in line with the state-of-the-art. Preeminently, APLe shows robustness and favourable performance in prompt-length experiments with an absolute advantage in adopting the V-L models.