 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image denoising and restoration with CNN-LSTM Encoder Decoder with Direct Attention
Jan 16, 2018
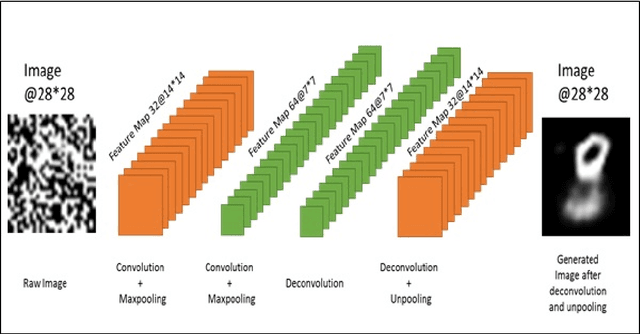
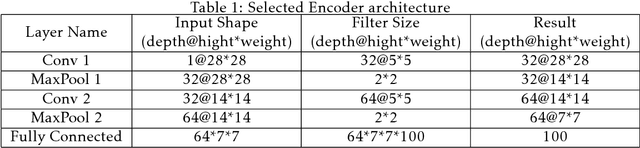
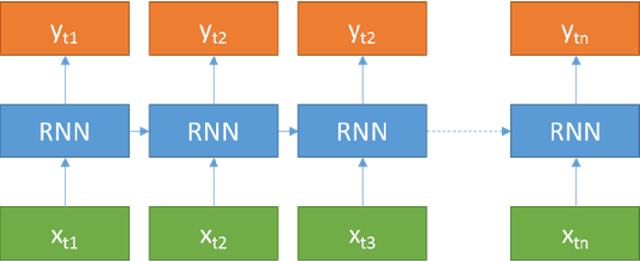
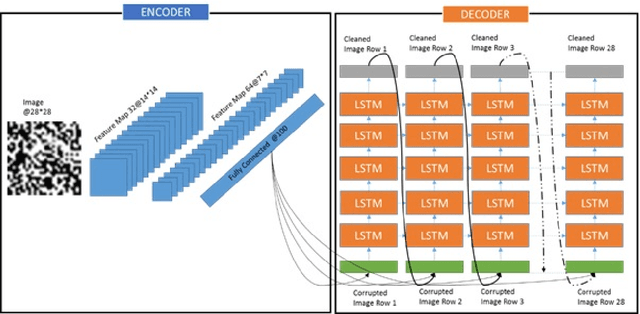
Image denoising is always a challenging task in the field of computer vision and image processing. In this paper, we have proposed an encoder-decoder model with direct attention, which is capable of denoising and reconstruct highly corrupted images. Our model consists of an encoder and a decoder, where the encoder is a convolutional neural network and decoder is a multilayer Long Short-Term memory network. In the proposed model, the encoder reads an image and catches the abstraction of that image in a vector, where decoder takes that vector as well as the corrupted image to reconstruct a clean image. We have trained our model on MNIST handwritten digit database after making lower half of every image as black as well as adding noise top of that. After a massive destruction of the images where it is hard for a human to understand the content of those images, our model can retrieve that image with minimal error. Our proposed model has been compared with convolutional encoder-decoder, where our model has performed better at generating missing part of the images than convolutional autoencoder.
Distortion Robust Image Classification using Deep Convolutional Neural Network with Discrete Cosine Transform
Nov 19, 2018
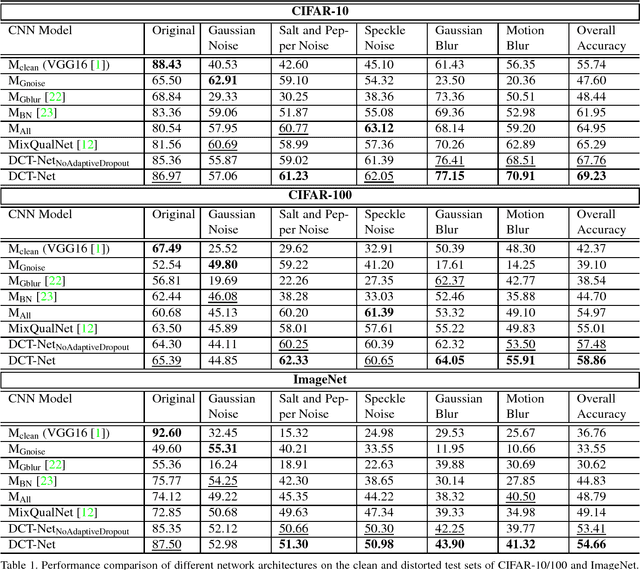


Convolutional Neural Network is good at image classification. However, it is found to be vulnerable to image quality degradation. Even a small amount of distortion such as noise or blur can severely hamper the performance of these CNN architectures. Most of the work in the literature strives to mitigate this problem simply by fine-tuning a pre-trained CNN on mutually exclusive or a union set of distorted training data. This iterative fine-tuning process with all known types of distortion is exhaustive and the network struggles to handle unseen distortions. In this work, we propose distortion robust DCT-Net, a Discrete Cosine Transform based module integrated into a deep network which is built on top of VGG16. Unlike other works in the literature, DCT-Net is "blind" to the distortion type and level in an image both during training and testing. As a part of the training process, the proposed DCT module discards input information which mostly represents the contribution of high frequencies. The DCT-Net is trained "blindly" only once and applied in generic situation without further retraining. We also extend the idea of traditional dropout and present a training adaptive version of the same. We evaluate our proposed method against Gaussian blur, motion blur, salt and pepper noise, Gaussian noise and speckle noise added to CIFAR-10/100 and ImageNet test sets. Experimental results demonstrate that once trained, DCT-Net not only generalizes well to a variety of unseen image distortions but also outperforms other methods in the literature.
OCTOPUS: Overcoming Performance andPrivatization Bottlenecks in Distributed Learning
May 03, 2021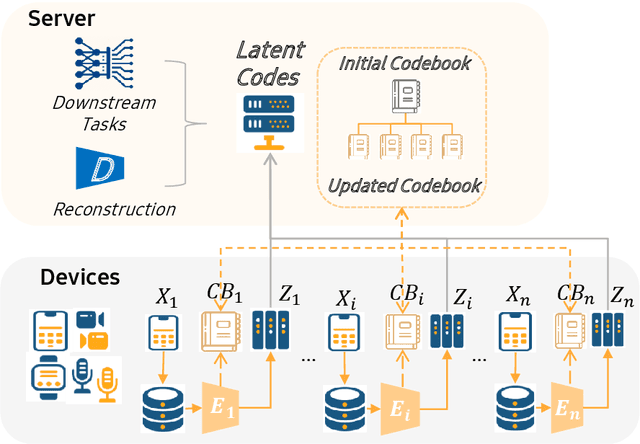

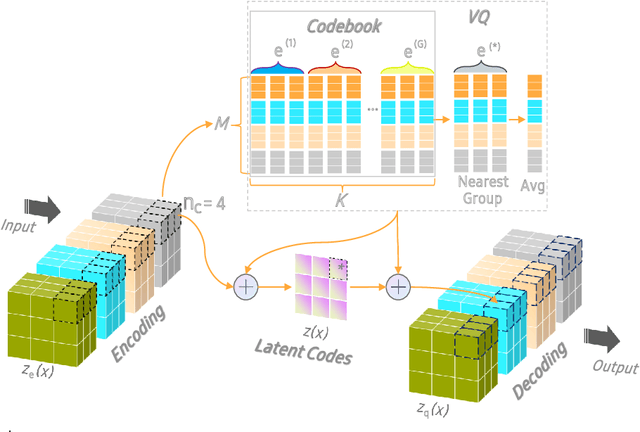
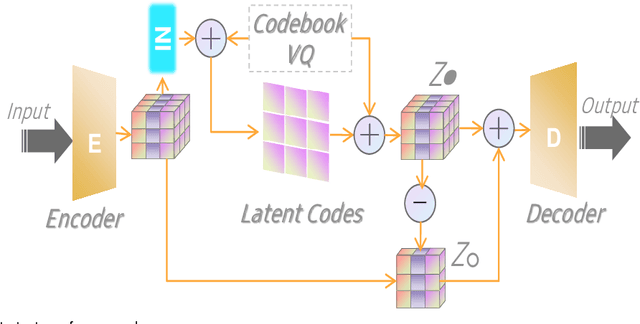
The diversity and quantity of the data warehousing, gathering data from distributed devices such as mobile phones, can enhance machine learning algorithms' success and robustness. Federated learning enables distributed participants to collaboratively learn a commonly-shared model while holding data locally. However, it is also faced with expensive communication and limitations due to the heterogeneity of distributed data sources and lack of access to global data. In this paper, we investigate a practical distributed learning scenario where multiple downstream tasks (e.g., classifiers) could be learned from dynamically-updated and non-iid distributed data sources, efficiently and providing local privatization. We introduce a new distributed learning scheme to address communication overhead via latent compression, leveraging global data while providing local privatization of local data without additional cost due to encryption or perturbation. This scheme divides the learning into (1) informative feature encoding, extracting and transmitting the latent space compressed representation features of local data at each node to address communication overhead; (2) downstream tasks centralized at the server using the encoded codes gathered from each node to address computing and storage overhead. Besides, a disentanglement strategy is applied to address the privatization of sensitive components of local data. Extensive experiments are conducted on image and speech datasets. The results demonstrate that downstream tasks on the compact latent representations can achieve comparable accuracy to centralized learning with the privatization of local data.
In Situ Translational Hand-Eye Calibration of Laser Profile Sensors using Arbitrary Objects
Mar 22, 2021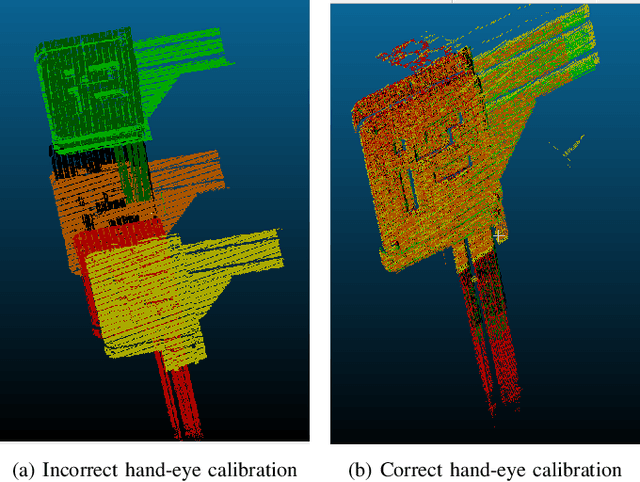
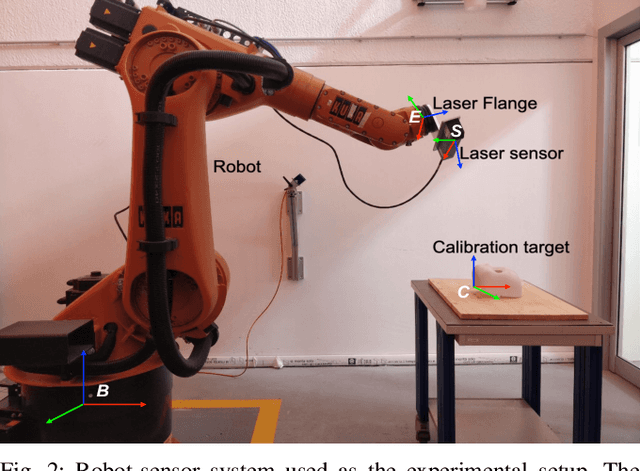


Hand-eye calibration of laser profile sensors is the process of extracting the homogeneous transformation between the laser profile sensor frame and the end-effector frame of a robot in order to express the data extracted by the sensor in the robot's global coordinate system. For laser profile scanners this is a challenging procedure, as they provide data only in two dimensions and state-of-the-art calibration procedures require the use of specialised calibration targets. This paper presents a novel method to extract the translation-part of the hand-eye calibration matrix with rotation-part known a priori in a target-agnostic way. Our methodology is applicable to any 2D image or 3D object as a calibration target and can also be performed in situ in the final application. The method is experimentally validated on a real robot-sensor setup with 2D and 3D targets.
InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations
Aug 18, 2019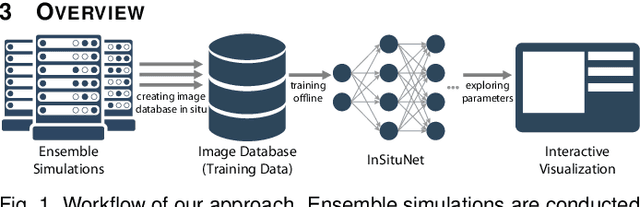
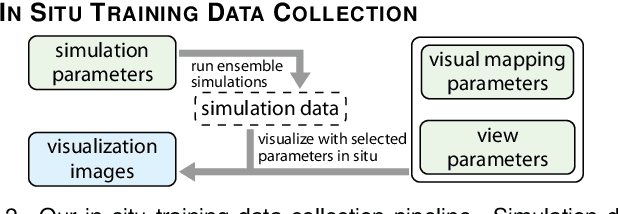
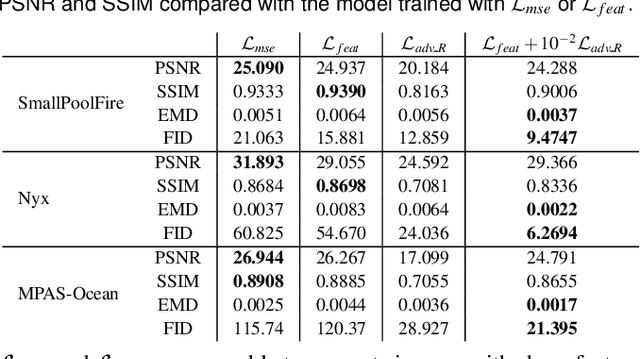
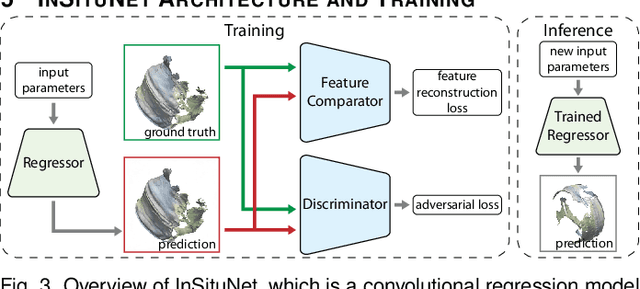
We propose InSituNet, a deep learning based surrogate model to support parameter space exploration for ensemble simulations that are visualized in situ. In situ visualization, generating visualizations at simulation time, is becoming prevalent in handling large-scale simulations because of the I/O and storage constraints. However, in situ visualization approaches limit the flexibility of post-hoc exploration because the raw simulation data are no longer available. Although multiple image-based approaches have been proposed to mitigate this limitation, those approaches lack the ability to explore the simulation parameters. Our approach allows flexible exploration of parameter space for large-scale ensemble simulations by taking advantage of the recent advances in deep learning. Specifically, we design InSituNet as a convolutional regression model to learn the mapping from the simulation and visualization parameters to the visualization results. With the trained model, users can generate new images for different simulation parameters under various visualization settings, which enables in-depth analysis of the underlying ensemble simulations. We demonstrate the effectiveness of InSituNet in combustion, cosmology, and ocean simulations through quantitative and qualitative evaluations.
Self-supervised Learning of Depth Inference for Multi-view Stereo
Apr 07, 2021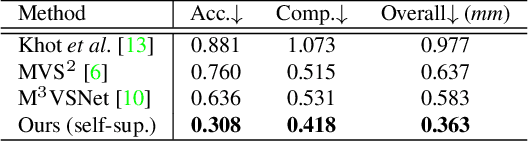
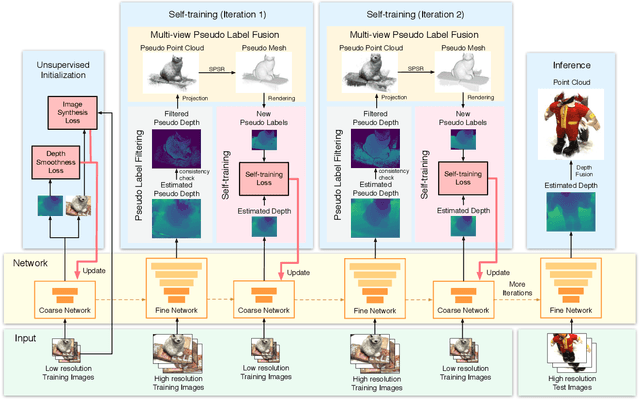
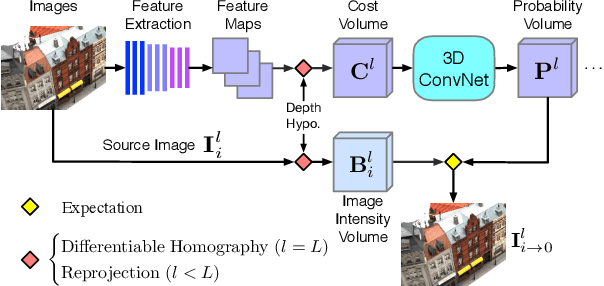
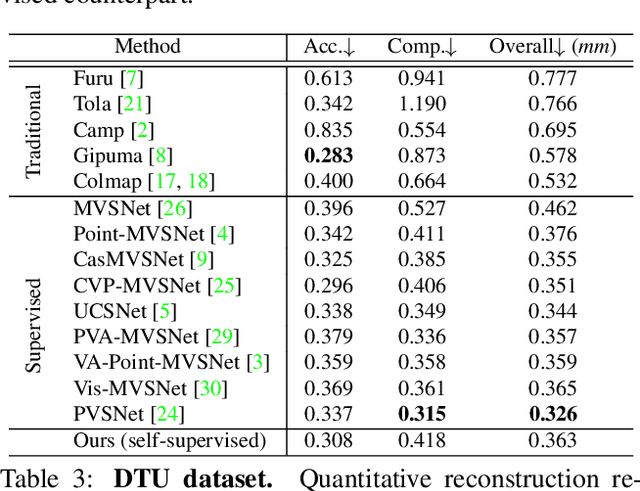
Recent supervised multi-view depth estimation networks have achieved promising results. Similar to all supervised approaches, these networks require ground-truth data during training. However, collecting a large amount of multi-view depth data is very challenging. Here, we propose a self-supervised learning framework for multi-view stereo that exploit pseudo labels from the input data. We start by learning to estimate depth maps as initial pseudo labels under an unsupervised learning framework relying on image reconstruction loss as supervision. We then refine the initial pseudo labels using a carefully designed pipeline leveraging depth information inferred from higher resolution images and neighboring views. We use these high-quality pseudo labels as the supervision signal to train the network and improve, iteratively, its performance by self-training. Extensive experiments on the DTU dataset show that our proposed self-supervised learning framework outperforms existing unsupervised multi-view stereo networks by a large margin and performs on par compared to the supervised counterpart. Code is available at https://github.com/JiayuYANG/Self-supervised-CVP-MVSNet.
GAN-based Virtual Re-Staining: A Promising Solution for Whole Slide Image Analysis
Jan 13, 2019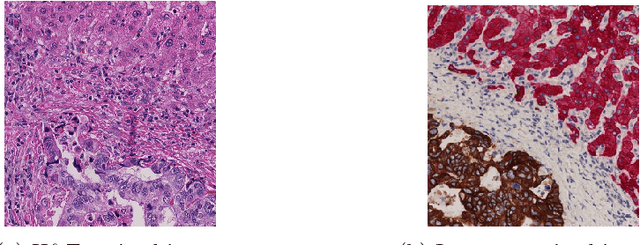
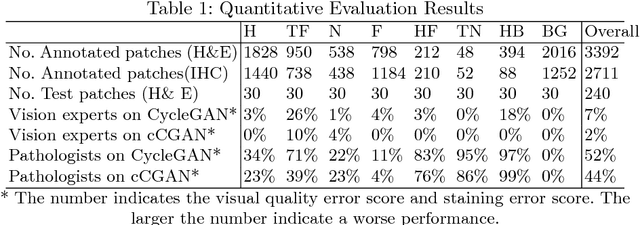
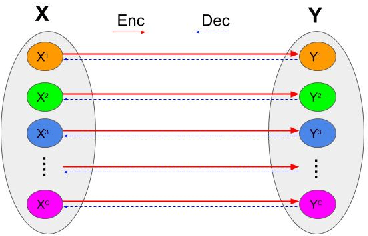
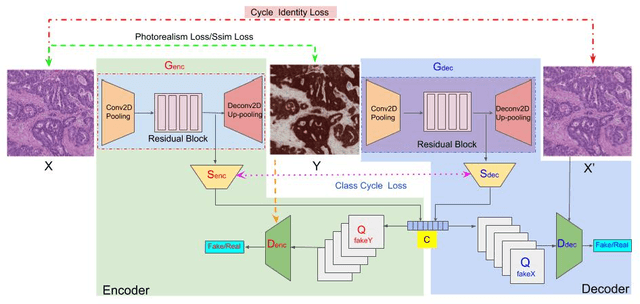
Histopathological cancer diagnosis is based on visual examination of stained tissue slides. Hematoxylin and eosin (H\&E) is a standard stain routinely employed worldwide. It is easy to acquire and cost effective, but cells and tissue components show low-contrast with varying tones of dark blue and pink, which makes difficult visual assessments, digital image analysis, and quantifications. These limitations can be overcome by IHC staining of target proteins of the tissue slide. IHC provides a selective, high-contrast imaging of cells and tissue components, but their use is largely limited by a significantly more complex laboratory processing and high cost. We proposed a conditional CycleGAN (cCGAN) network to transform the H\&E stained images into IHC stained images, facilitating virtual IHC staining on the same slide. This data-driven method requires only a limited amount of labelled data but will generate pixel level segmentation results. The proposed cCGAN model improves the original network \cite{zhu_unpaired_2017} by adding category conditions and introducing two structural loss functions, which realize a multi-subdomain translation and improve the translation accuracy as well. % need to give reasons here. Experiments demonstrate that the proposed model outperforms the original method in unpaired image translation with multi-subdomains. We also explore the potential of unpaired images to image translation method applied on other histology images related tasks with different staining techniques.
Global Deep Learning Methods for Multimodality Isointense Infant Brain Image Segmentation
Dec 10, 2018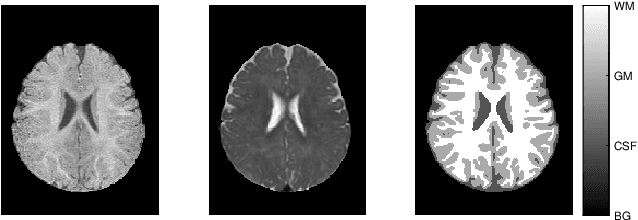
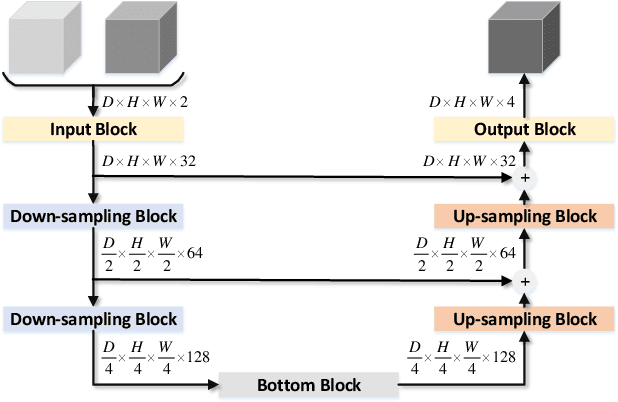
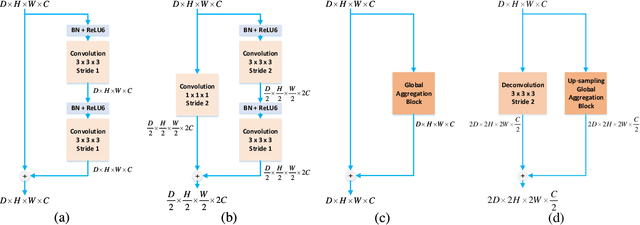
An important step in early brain development study is to perform automatic segmentation of infant brain magnetic resonance (MR) images into cerebrospinal fluid (CSF), gray matter (GM) and white matter (WM) regions. This task is especially challenging in the isointense stage (approximately 6-8 months of age) when GM and WM exhibit similar levels of intensities in MR images. Deep learning has shown its great promise in various image segmentation tasks. However, existing models do not have an efficient and effective way to aggregate global information. They also suffer from information loss during up-sampling operations. In this work, we address these problems by proposing a global aggregation block, which can be flexibly used for global information fusion. We build a novel model based on 3D U-Net to make fast and accurate voxel-wise dense prediction. We perform thorough experiments, and results indicate that our model outperforms previous best models significantly on 3D multimodality isointense infant brain MR image segmentation.
Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions
Dec 03, 2018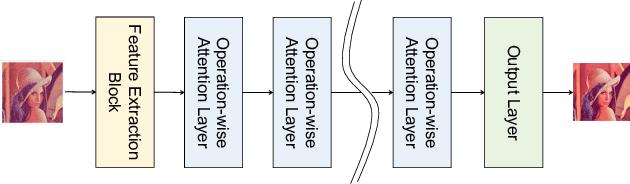
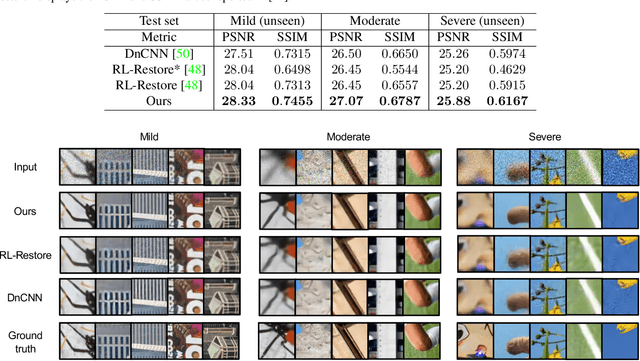
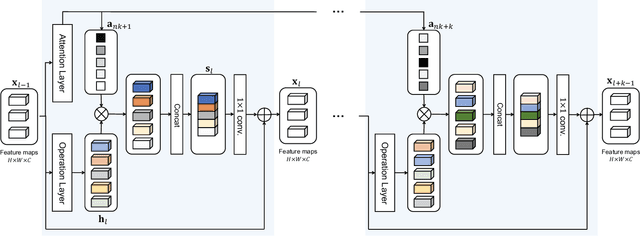

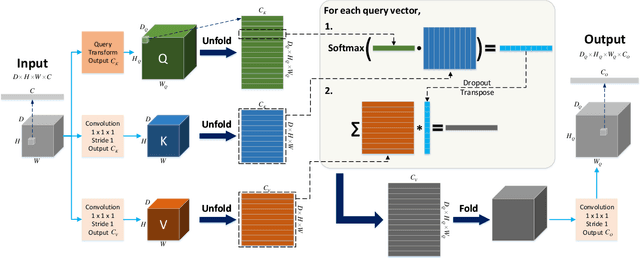
Many studies have been conducted so far on image restoration, the problem of restoring a clean image from its distorted version. There are many different types of distortion which affect image quality. Previous studies have focused on single types of distortion, proposing methods for removing them. However, image quality degrades due to multiple factors in the real world. Thus, depending on applications, e.g., vision for autonomous cars or surveillance cameras, we need to be able to deal with multiple combined distortions with unknown mixture ratios. For this purpose, we propose a simple yet effective layer architecture of neural networks. It performs multiple operations in parallel, which are weighted by an attention mechanism to enable selection of proper operations depending on the input. The layer can be stacked to form a deep network, which is differentiable and thus can be trained in an end-to-end fashion by gradient descent. The experimental results show that the proposed method works better than previous methods by a good margin on tasks of restoring images with multiple combined distortions.
Fast Zero-Shot Image Tagging
May 31, 2016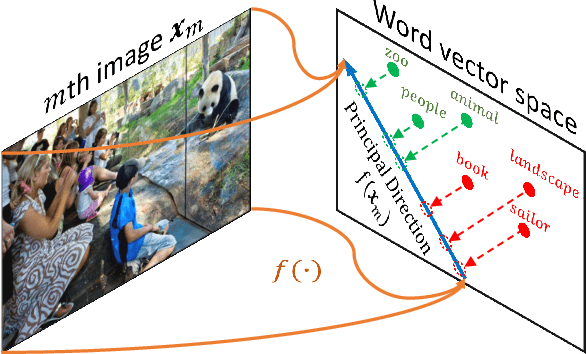
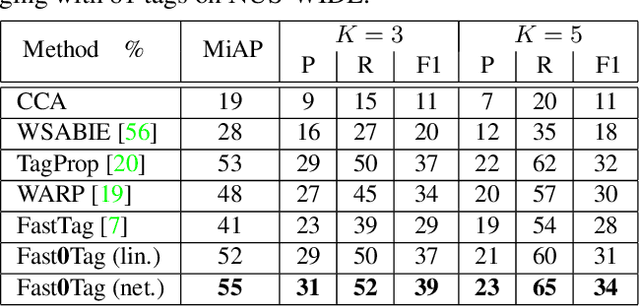
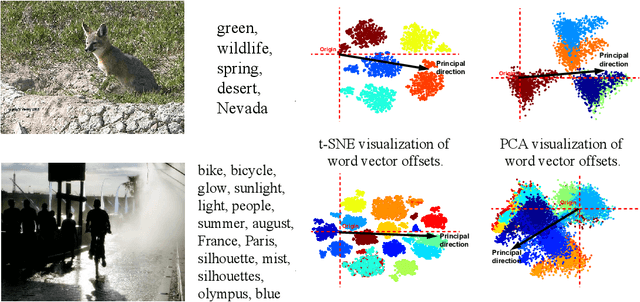
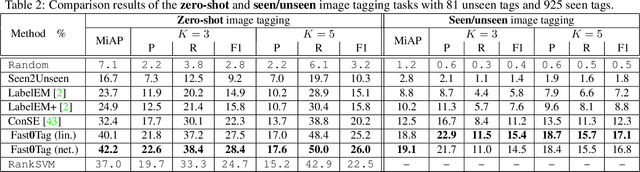
The well-known word analogy experiments show that the recent word vectors capture fine-grained linguistic regularities in words by linear vector offsets, but it is unclear how well the simple vector offsets can encode visual regularities over words. We study a particular image-word relevance relation in this paper. Our results show that the word vectors of relevant tags for a given image rank ahead of the irrelevant tags, along a principal direction in the word vector space. Inspired by this observation, we propose to solve image tagging by estimating the principal direction for an image. Particularly, we exploit linear mappings and nonlinear deep neural networks to approximate the principal direction from an input image. We arrive at a quite versatile tagging model. It runs fast given a test image, in constant time w.r.t.\ the training set size. It not only gives superior performance for the conventional tagging task on the NUS-WIDE dataset, but also outperforms competitive baselines on annotating images with previously unseen tags
* 9 pages (not including reference). This paper has been accepted by CVPR 2016