 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-aliasing Deep Image Classifiers using Novel Depth Adaptive Blurring and Activation Function
Oct 03, 2021
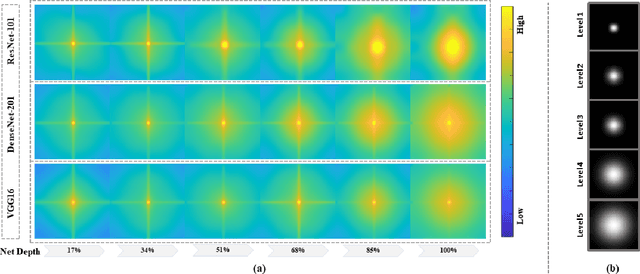

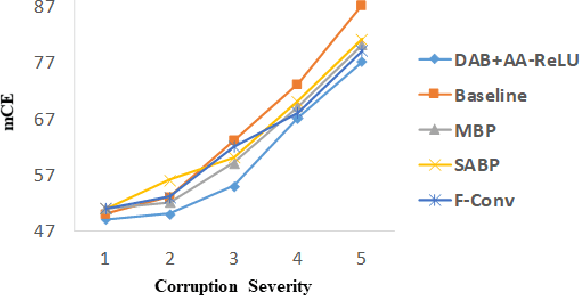
Deep convolutional networks are vulnerable to image translation or shift, partly due to common down-sampling layers, e.g., max-pooling and strided convolution. These operations violate the Nyquist sampling rate and cause aliasing. The textbook solution is low-pass filtering (blurring) before down-sampling, which can benefit deep networks as well. Even so, non-linearity units, such as ReLU, often re-introduce the problem, suggesting that blurring alone may not suffice. In this work, first, we analyse deep features with Fourier transform and show that Depth Adaptive Blurring is more effective, as opposed to monotonic blurring. To this end, we outline how this can replace existing down-sampling methods. Second, we introduce a novel activation function -- with a built-in low pass filter, to keep the problem from reappearing. From experiments, we observe generalisation on other forms of transformations and corruptions as well, e.g., rotation, scale, and noise. We evaluate our method under three challenging settings: (1) a variety of image translations; (2) adversarial attacks -- both $\ell_{p}$ bounded and unbounded; and (3) data corruptions and perturbations. In each setting, our method achieves state-of-the-art results and improves clean accuracy on various benchmark datasets.
A novel network training approach for open set image recognition
Sep 27, 2021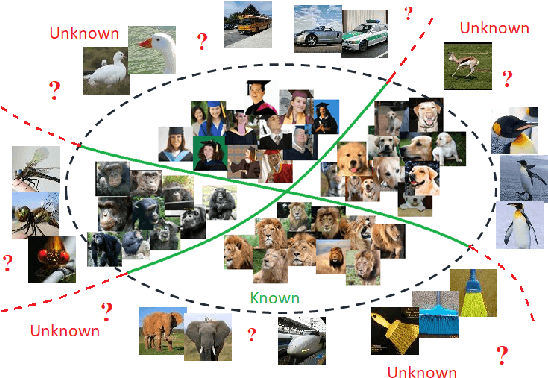
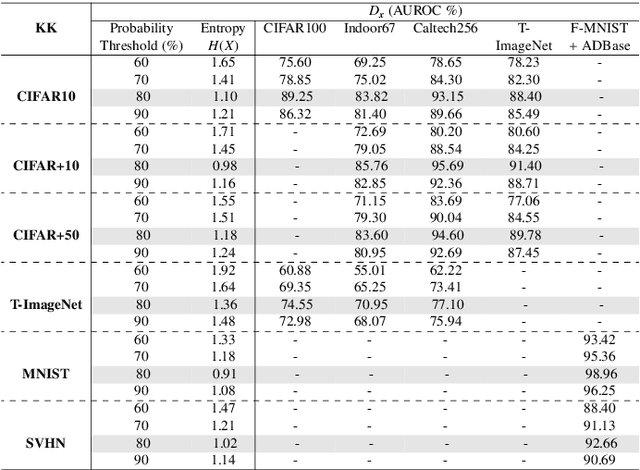
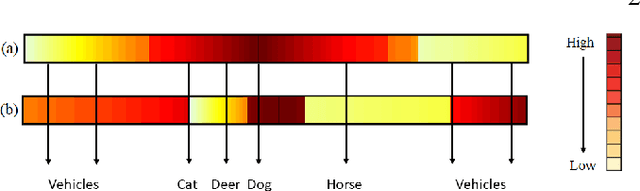
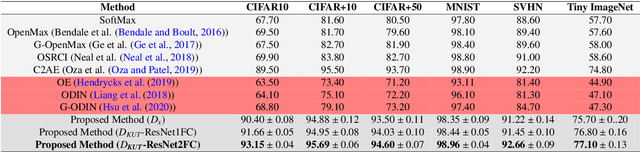
Convolutional Neural Networks (CNNs) are commonly designed for closed set arrangements, where test instances only belong to some "Known Known" (KK) classes used in training. As such, they predict a class label for a test sample based on the distribution of the KK classes. However, when used under the Open Set Recognition (OSR) setup (where an input may belong to an "Unknown Unknown" or UU class), such a network will always classify a test instance as one of the KK classes even if it is from a UU class. As a solution, recently, data augmentation based on Generative Adversarial Networks(GAN) has been used. In this work, we propose a novel approach for mining a "Known UnknownTrainer" or KUT set and design a deep OSR Network (OSRNet) to harness this dataset. The goal isto teach OSRNet the essence of the UUs through KUT set, which is effectively a collection of mined "hard Known Unknown negatives". Once trained, OSRNet can detect the UUs while maintaining high classification accuracy on KKs. We evaluate OSRNet on six benchmark datasets and demonstrate it outperforms contemporary OSR methods.
Thank you for Attention: A survey on Attention-based Artificial Neural Networks for Automatic Speech Recognition
Feb 14, 2021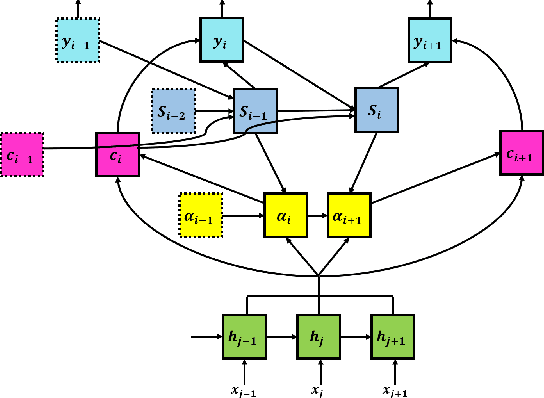
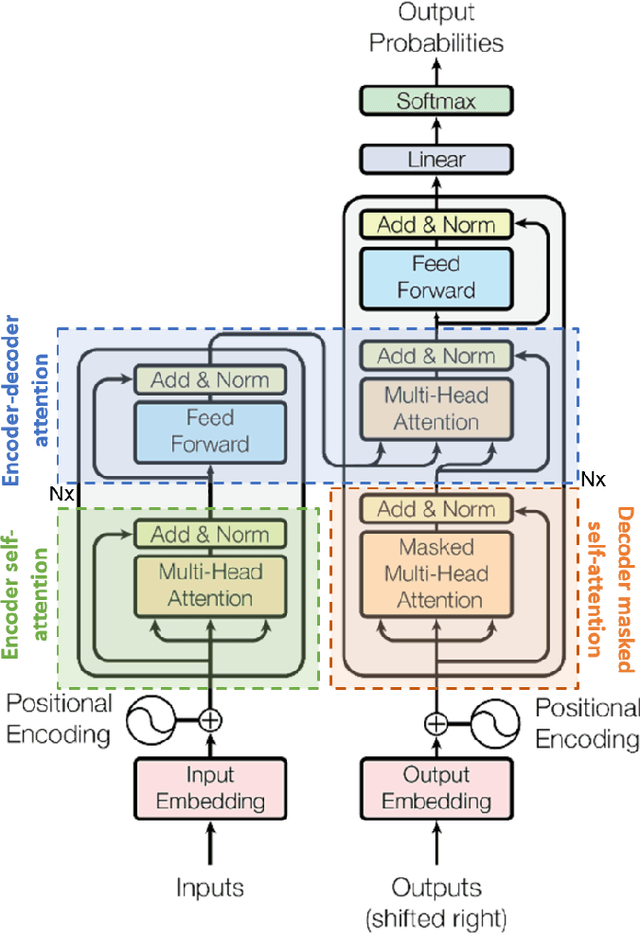
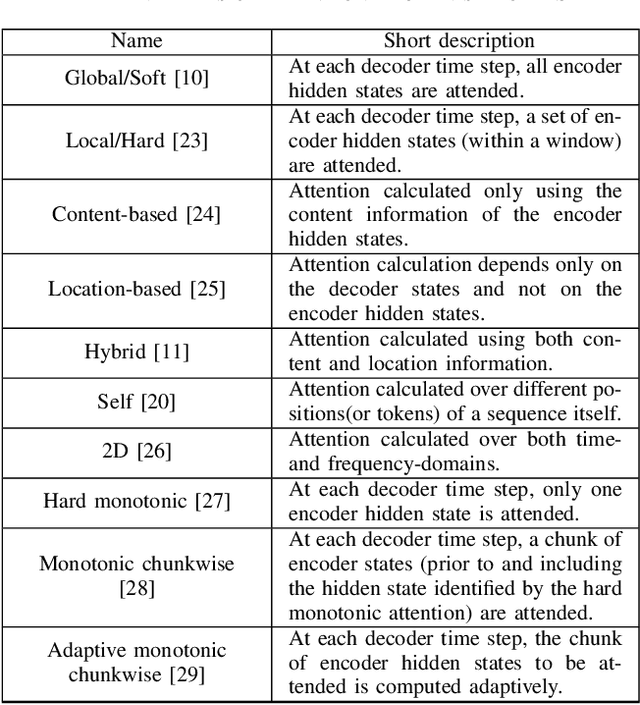
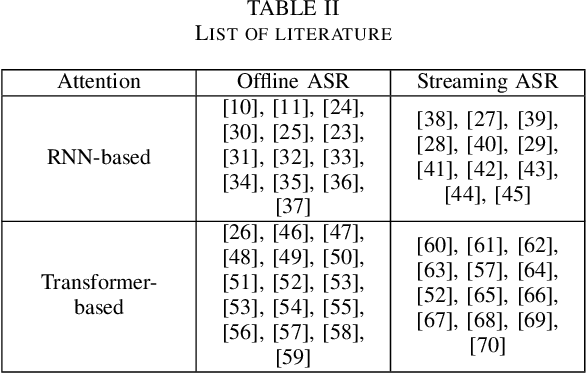
Attention is a very popular and effective mechanism in artificial neural network-based sequence-to-sequence models. In this survey paper, a comprehensive review of the different attention models used in developing automatic speech recognition systems is provided. The paper focuses on the development and evolution of attention models for offline and streaming speech recognition within recurrent neural network- and Transformer- based architectures.
An Integrated Attribute Guided Dense Attention Model for Fine-Grained Generalized Zero-Shot Learning
Feb 05, 2021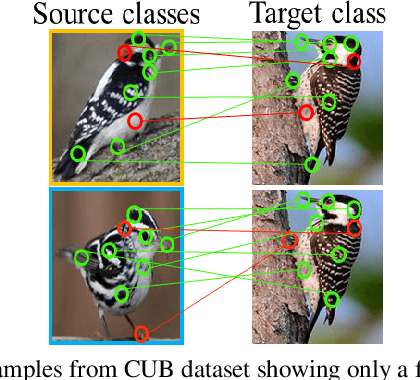
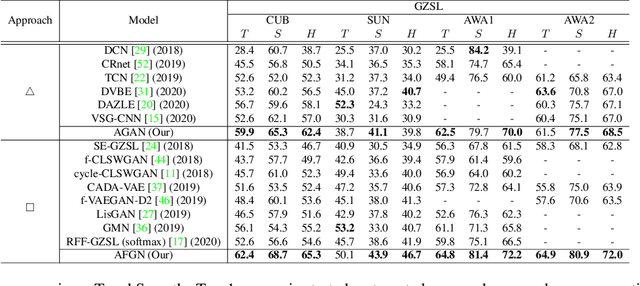
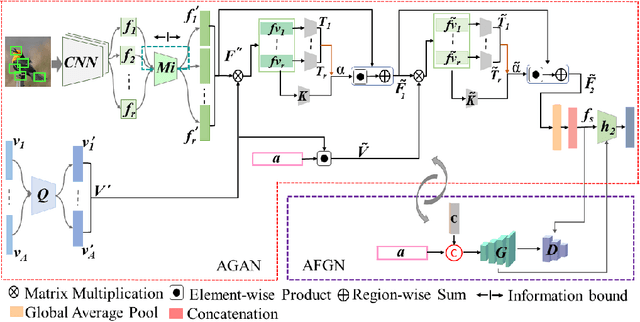
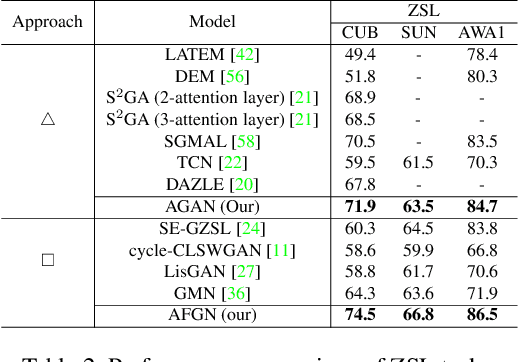
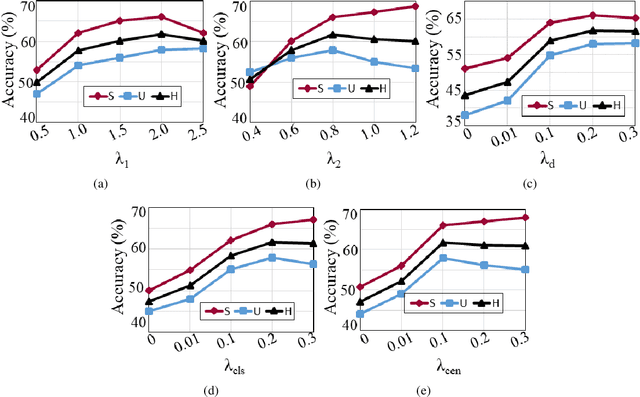
Embedding learning (EL) and feature synthesizing (FS) are two of the popular categories of fine-grained GZSL methods. The global feature exploring EL or FS methods do not explore fine distinction as they ignore local details. And, the local detail exploring EL or FS methods either neglect direct attribute guidance or global information. Consequently, neither method performs well. In this paper, we propose to explore global and direct attribute-supervised local visual features for both EL and FS categories in an integrated manner for fine-grained GZSL. The proposed integrated network has an EL sub-network and a FS sub-network. Consequently, the proposed integrated network can be tested in two ways. We propose a novel two-step dense attention mechanism to discover attribute-guided local visual features. We introduce new mutual learning between the sub-networks to exploit mutually beneficial information for optimization. Moreover, to reduce bias towards the source domain during testing, we propose to compute source-target class similarity based on mutual information and transfer-learn the target classes. We demonstrate that our proposed method outperforms contemporary methods on benchmark datasets.
Bidirectional Mapping Coupled GAN for Generalized Zero-Shot Learning
Dec 30, 2020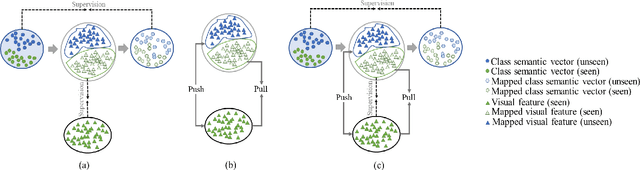
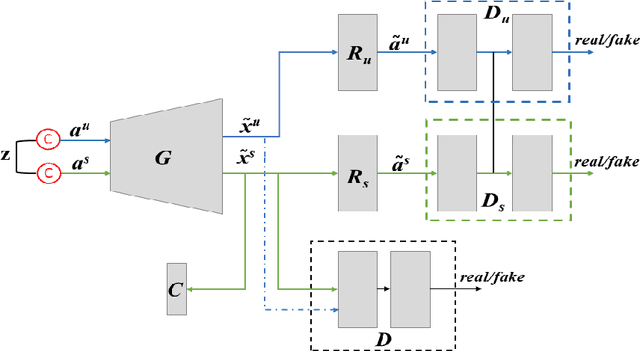
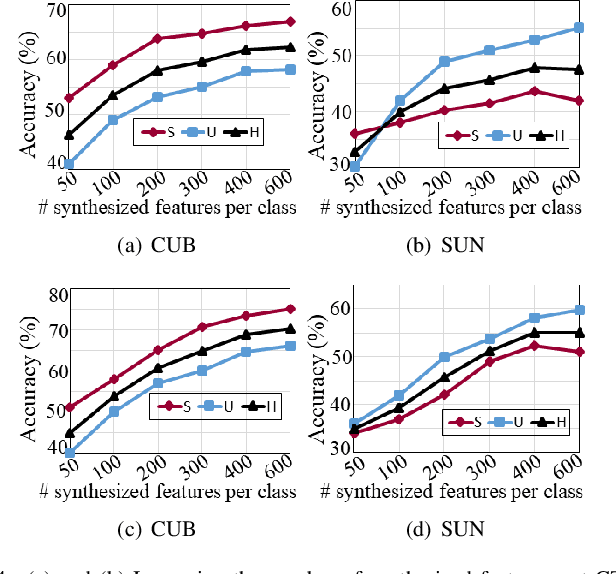
Bidirectional mapping-based generative models have achieved remarkable performance for the generalized zero-shot learning (GZSL) recognition by learning to construct visual features from class semantics and reconstruct class semantics back from generated visual features. The performance of these models relies on the quality of synthesized features. This depends on the ability of the model to capture the underlying seen data distribution by relating semantic-visual spaces, learning discriminative information, and re-purposing the learned distribution to recognize unseen data. This means learning the seen-unseen domains joint distribution is crucial for GZSL tasks. However, existing models only learn the underlying distribution of the seen domain as unseen data is inaccessible. In this work, we propose to utilize the available unseen class semantics along with seen class semantics and learn dual-domain joint distribution through a strong visual-semantic coupling. Therefore, we propose a bidirectional mapping coupled generative adversarial network (BMCoGAN) by extending the coupled generative adversarial network (CoGAN) into a dual-domain learning bidirectional mapping model. We further integrate a Wasserstein generative adversarial optimization to supervise the joint distribution learning. For retaining distinctive information in the synthesized visual space and reducing bias towards seen classes, we design an optimization, which pushes synthesized seen features towards real seen features and pulls synthesized unseen features away from real seen features. We evaluate BMCoGAN on several benchmark datasets against contemporary methods and show its superior performance. Also, we present ablative analysis to demonstrate the importance of different components in BMCoGAN.
Robust Image Classification Using A Low-Pass Activation Function and DCT Augmentation
Jul 18, 2020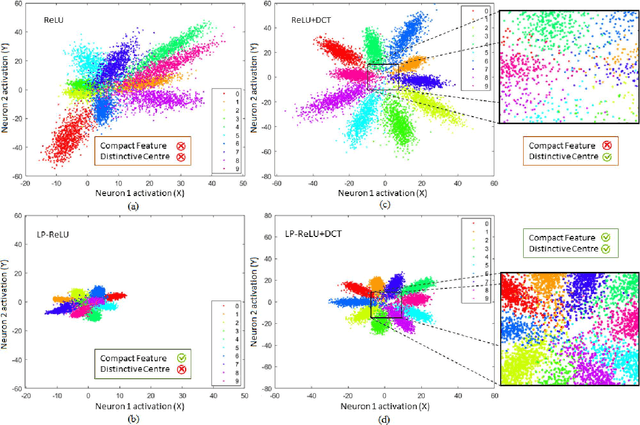
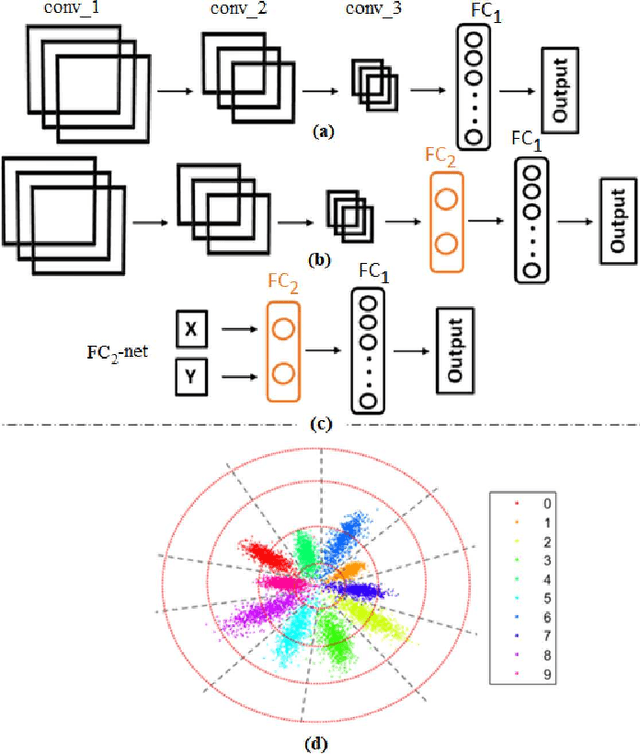
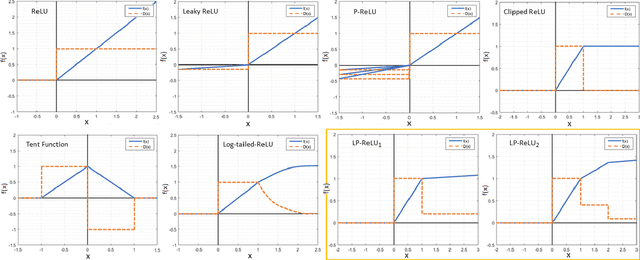
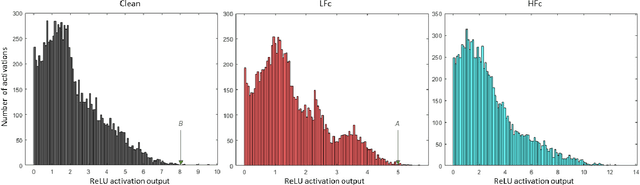
Convolutional Neural Network's (CNN's) performance disparity on clean and corrupted datasets has recently been noticed. In this work, we analyse common corruptions from a frequency perspective, i.e., High Frequency corruptions or HFc (e.g., noise) and Low Frequency corruptions or LFc (e.g., blur). A common signal processing solution to HFc is low-pass filtering. Intriguingly, the de-facto Activation Function (AF) used in modern CNNs, i.e., ReLU does not have any filtering mechanism resulting in unstable performance on HFc. In this work, we propose a family of novel AFs with low-pass filtering to improve robustness against HFc (we call it Low-Pass ReLU or LP-ReLU). To deal with LFc, we further enhance the AFs with Discrete Cosine Transform (DCT) based augmentation. LP-ReLU coupled with DCT augmentation, enables a deep network to tackle a variety of corruptions. We evaluate our method's performance on CIFAR-10-C and Tiny ImageNet-C datasets and achieve improvements of 5.1% and 7.2% in accuracy respectively compared to the State-Of-The-Art (SOTA). We further evaluate our method's performance stability on a variety of perturbations available in CIFAR-10-P and Tiny ImageNet-P. We also achieve new SOTA results in these experiments. We also devise a decision space visualisation process to further strengthen the understanding regarding CNN's lack of robustness against corrupted data.
Open Set Domain Adaptation with Multi-Classifier Adversarial Network
Jul 08, 2020
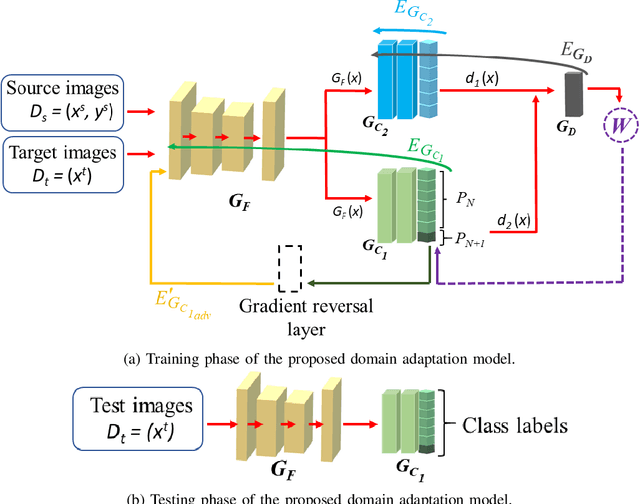
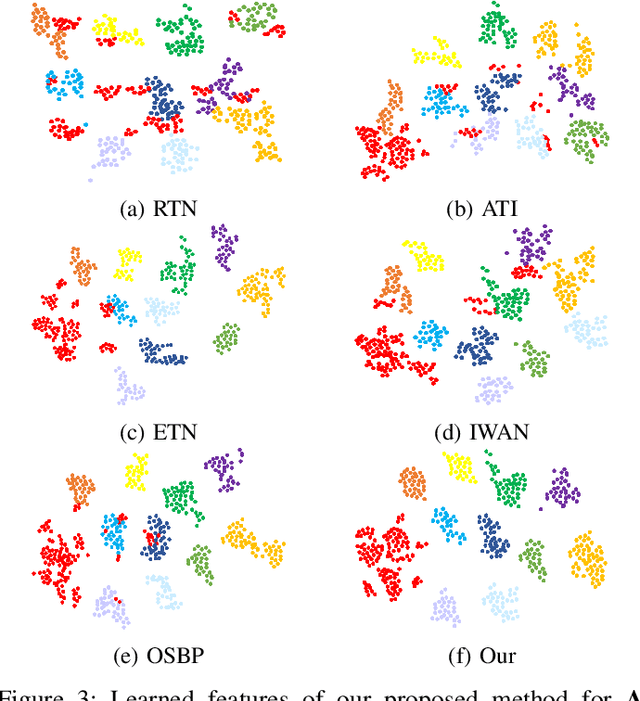
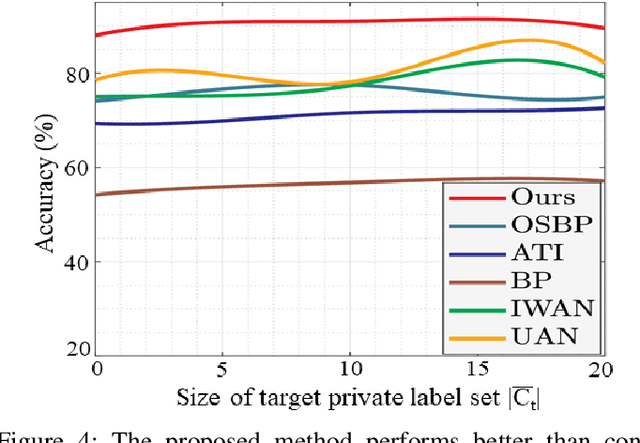
Domain adaptation aims to transfer knowledge from a domain with adequate labeled samples to a domain with scarce labeled samples. The majority of existing domain adaptation methods rely on the assumption of having identical label spaces across the source and target domains, which limits their application in real-world scenarios. To get rid of such an assumption, prior research has introduced various open set domain adaptation settings in the literature. This paper focuses on the type of open set domain adaptation setting where the target domain has both private (`unknown classes') label space beside the shared (`known classes') label space. However, the source domain only has the `known classes' label space. Prevalent distribution-matching domain adaptation methods are inadequate in such a setting that demands adaptation from a smaller source domain to a larger and diverse target domain with more classes. For addressing this specific open set domain adaptation setting, prior research introduces a domain adversarial model with an empirical fixed threshold which lacks at handling false-negative transfers. We propose a multi-classifier based weighting scheme for the adversarial domain adaptation model to address this issue and improve performance. Our proposed method assigns distinguishable weights to target samples belonging to the known and unknown classes to limit false-negative transfers, and simultaneously reduce the domain gap between shared classes of the source and target domains. A thorough evaluation shows that our proposed method outperforms existing domain adaptation methods for a number of domain adaptation datasets.
Depth Augmented Networks with Optimal Fine-tuning
Mar 25, 2019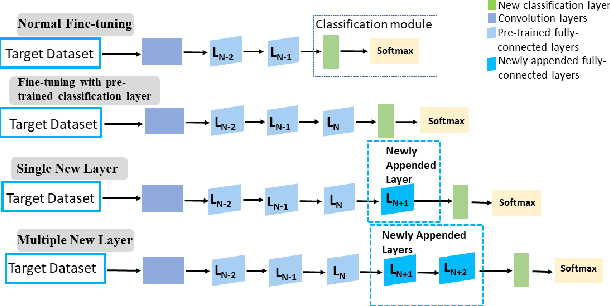
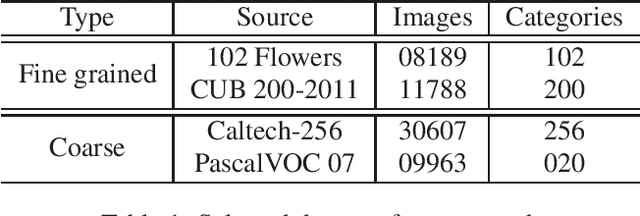
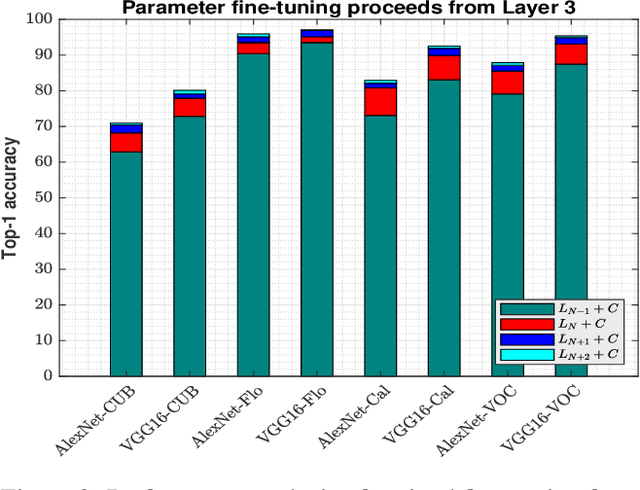

Convolutional neural networks (CNN) have been shown to achieve state-of-the-art performance in a significant number of computer vision tasks. Although they require large labelled training datasets to learn the CNN models, they have striking attributes of transferring learned representations from large source sets to smaller target sets by normal fine-tuning approaches. Prior research has shown that these techniques boost the performance on smaller target sets. In this paper, we demonstrate that growing network depth capacity beyond classification layer along with careful normalization and scaling scheme boosts fine-tuning by creating harmony between the pre-trained and new layers to adjust more to the target task. This indicates pre-trained classification layer holds high-level (global) image information that can be propagated through the newly introduced layers in fine-tuning. We evaluate our depth augmented networks following our designed incremental fine-tuning scheme on several benchmark datatsets and show that they outperform contemporary transfer learning approaches. On average, for fine-grained datasets we achieve up to 6.7% (AlexNet), 5.4% (VGG16) and for coarse datasets 9.3% (AlexNet), 8.7% (VGG16) improvement than normal fine-tuning. In addition, our in-depth analysis manifests freezing highly generic layers encourage better learning of target tasks. Furthermore, we have found that the learning rate for newly introduced layers of depth augmented networks depend on target set and size of new layers.
Distortion Robust Image Classification using Deep Convolutional Neural Network with Discrete Cosine Transform
Nov 19, 2018
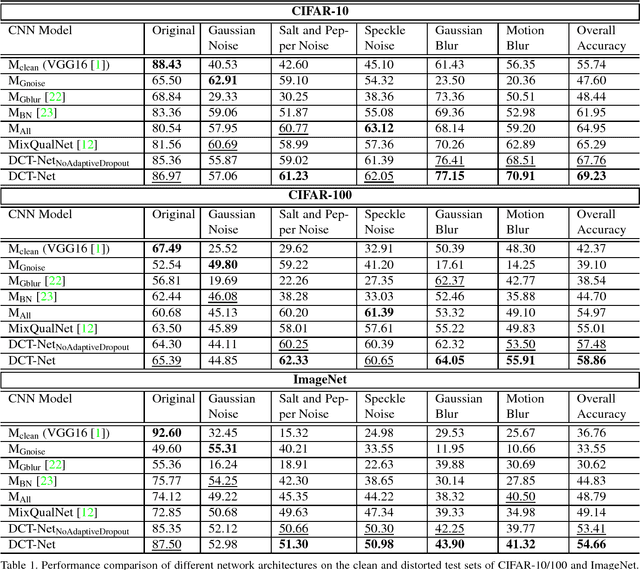


Convolutional Neural Network is good at image classification. However, it is found to be vulnerable to image quality degradation. Even a small amount of distortion such as noise or blur can severely hamper the performance of these CNN architectures. Most of the work in the literature strives to mitigate this problem simply by fine-tuning a pre-trained CNN on mutually exclusive or a union set of distorted training data. This iterative fine-tuning process with all known types of distortion is exhaustive and the network struggles to handle unseen distortions. In this work, we propose distortion robust DCT-Net, a Discrete Cosine Transform based module integrated into a deep network which is built on top of VGG16. Unlike other works in the literature, DCT-Net is "blind" to the distortion type and level in an image both during training and testing. As a part of the training process, the proposed DCT module discards input information which mostly represents the contribution of high frequencies. The DCT-Net is trained "blindly" only once and applied in generic situation without further retraining. We also extend the idea of traditional dropout and present a training adaptive version of the same. We evaluate our proposed method against Gaussian blur, motion blur, salt and pepper noise, Gaussian noise and speckle noise added to CIFAR-10/100 and ImageNet test sets. Experimental results demonstrate that once trained, DCT-Net not only generalizes well to a variety of unseen image distortions but also outperforms other methods in the literature.
An Efficient Transfer Learning Technique by Using Final Fully-Connected Layer Output Features of Deep Networks
Nov 19, 2018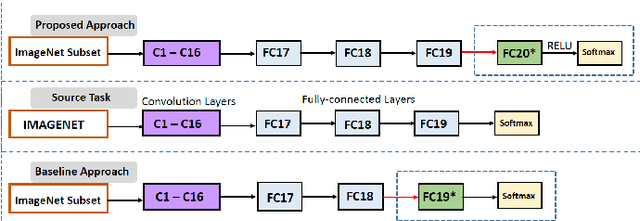
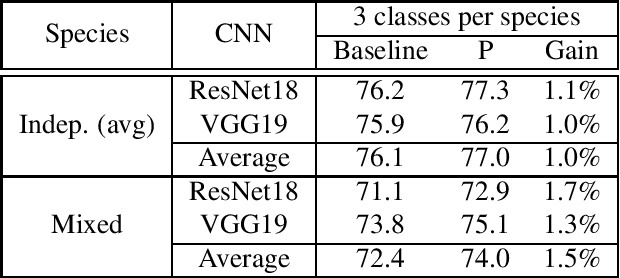
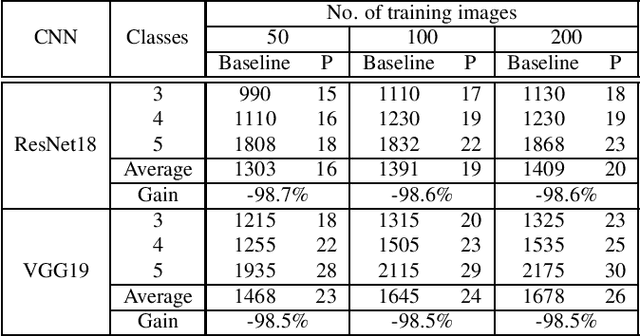
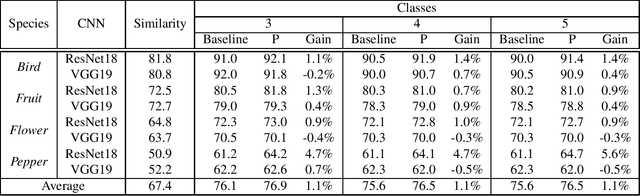
In this paper, we propose a computationally efficient transfer learning approach using the output vector of final fully-connected layer of deep convolutional neural networks for classification. Our proposed technique uses a single layer perceptron classifier designed with hyper-parameters to focus on improving computational efficiency without adversely affecting the performance of classification compared to the baseline technique. Our investigations show that our technique converges much faster than baseline yielding very competitive classification results. We execute thorough experiments to understand the impact of similarity between pre-trained and new classes, similarity among new classes, number of training samples in the performance of classification using transfer learning of the final fully-connected layer's output features.