 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021
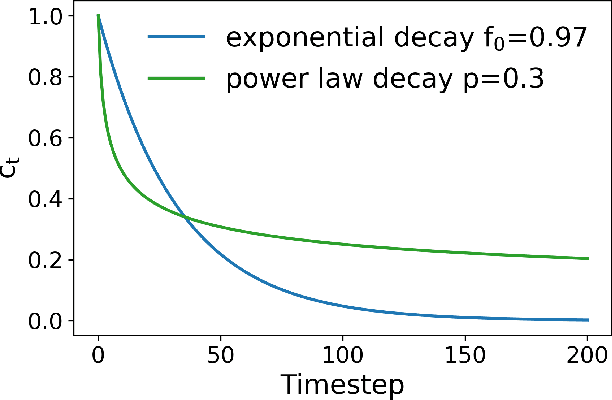
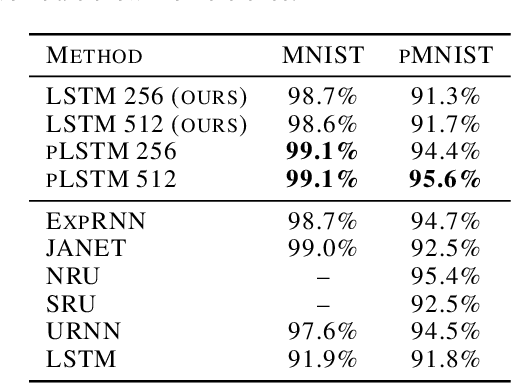
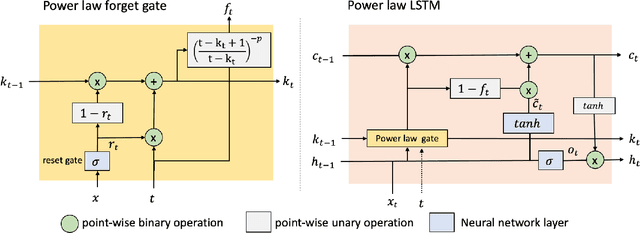
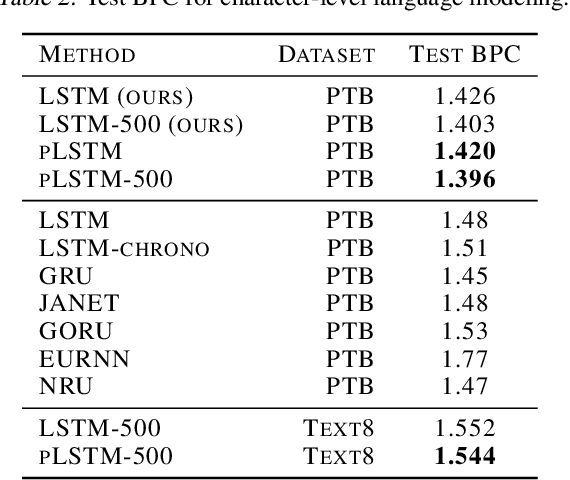
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Snowy Night-to-Day Translator and Semantic Segmentation Label Similarity for Snow Hazard Indicator
Feb 28, 2021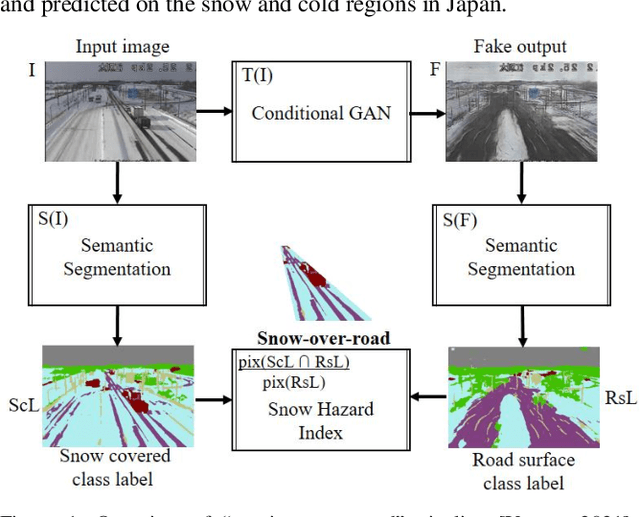
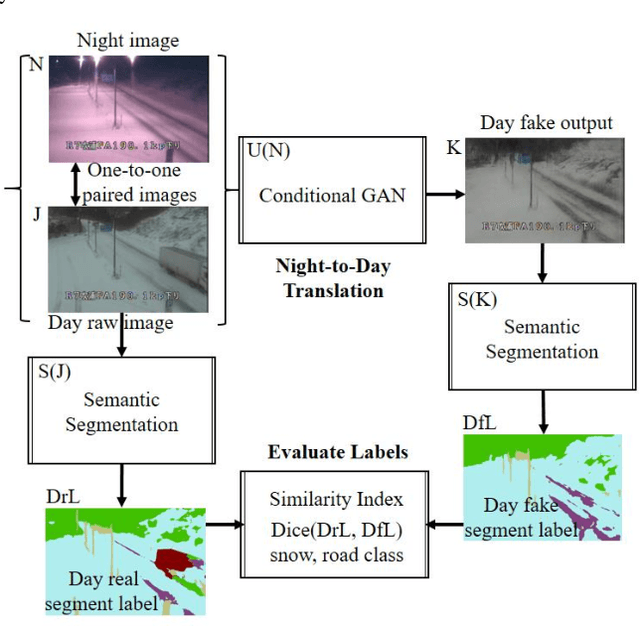


In 2021, Japan recorded more than three times as much snowfall as usual, so road user maybe come across dangerous situation. The poor visibility caused by snow triggers traffic accidents. For example, 2021 January 19, due to the dry snow and the strong wind speed of 27 m / s, blizzards occurred and the outlook has been ineffective. Because of the whiteout phenomenon, multiple accidents with 17 casualties occurred, and 134 vehicles were stacked up for 10 hours over 1 km. At the night time zone, the temperature drops and the road surface tends to freeze. CCTV images on the road surface have the advantage that we enable to monitor the status of major points at the same time. Road managers are required to make decisions on road closures and snow removal work owing to the road surface conditions even at night. In parallel, they would provide road users to alert for hazardous road surfaces. This paper propose a method to automate a snow hazard indicator that the road surface region is generated from the night snow image using the Conditional GAN, pix2pix. In addition, the road surface and the snow covered ROI are predicted using the semantic segmentation DeepLabv3+ with a backbone MobileNet, and the snow hazard indicator to automatically compute how much the night road surface is covered with snow. We demonstrate several results applied to the cold and snow region in the winter of Japan January 19 to 21 2021, and mention the usefulness of high similarity between snowy night-to-day fake output and real snowy day image for night snow visibility.
Detecting optical transients using artificial neural networks and reference images from different surveys
Sep 28, 2020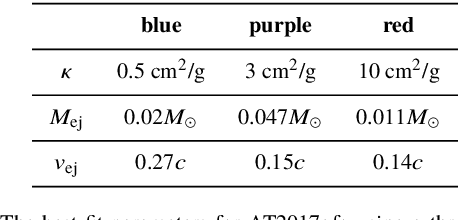
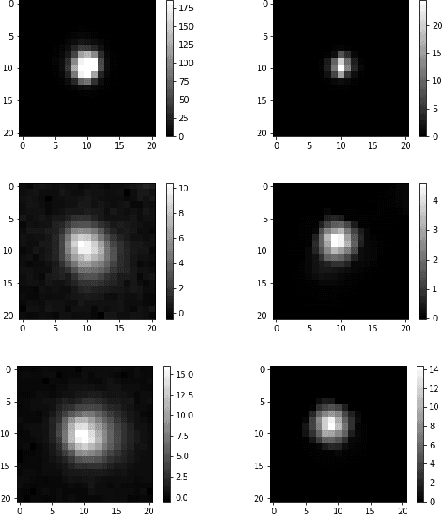
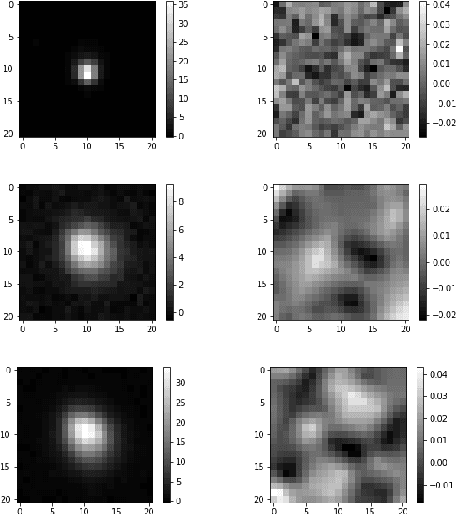
To search for optical counterparts to gravitational waves, it is crucial to develop an efficient follow-up method that allows for both a quick telescopic scan of the event localization region and search through the resulting image data for plausible optical transients. We present a method to detect these transients based on an artificial neural network. We describe the architecture of two networks capable of comparing images of the same part of the sky taken by different telescopes. One image corresponds to the epoch in which a potential transient could exist; the other is a reference image of an earlier epoch. We use data obtained by the Dr. Cristina V. Torres Memorial Astronomical Observatory and archival reference images from the Sloan Digital Sky Survey. We trained a convolutional neural network and a dense layer network on simulated source samples and tested the trained networks on samples created from real image data. Autonomous detection methods replace the standard process of detecting transients, which is normally achieved by source extraction of a difference image followed by human inspection of the detected candidates. Replacing the human inspection component with an entirely autonomous method would allow for a rapid and automatic follow-up of interesting targets of opportunity. The method will be further tested on telescopes participating in the Transient Optical Robotic Observatory of the South Collaboration.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
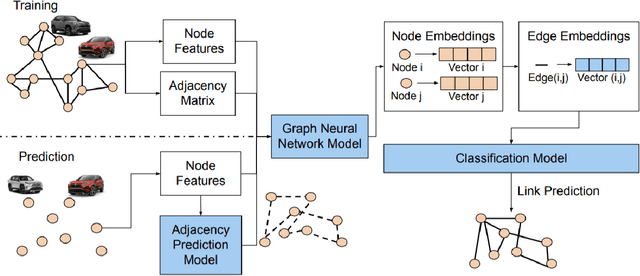
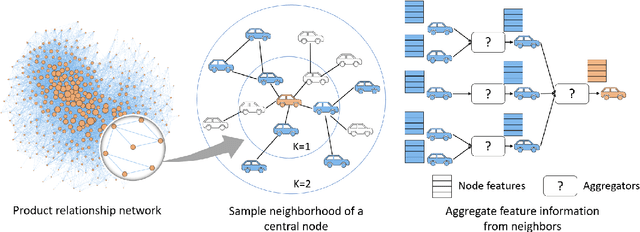
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.
Demonstrating Cloth Folding to Robots: Design and Evaluation of a 2D and a 3D User Interface
Apr 07, 2021
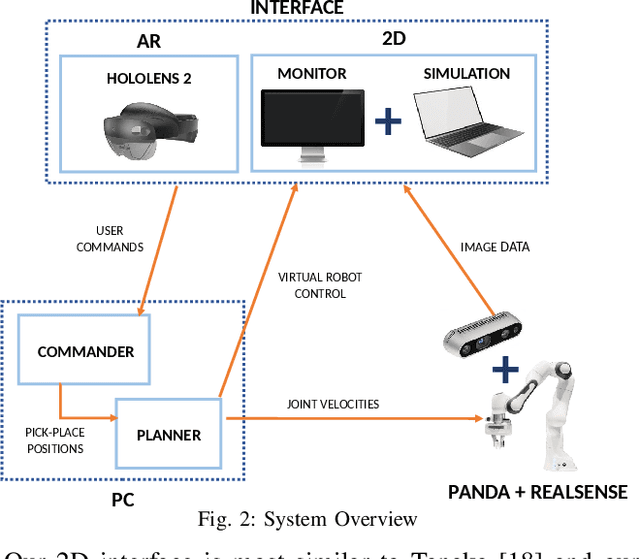
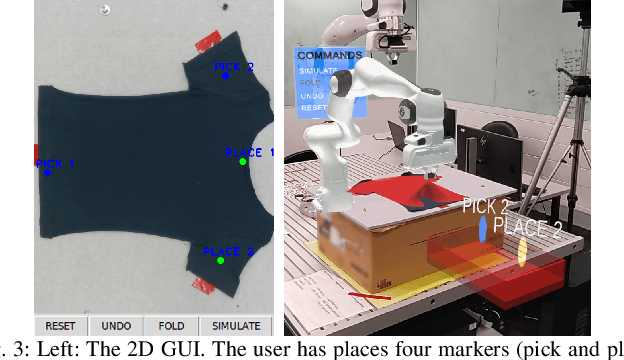
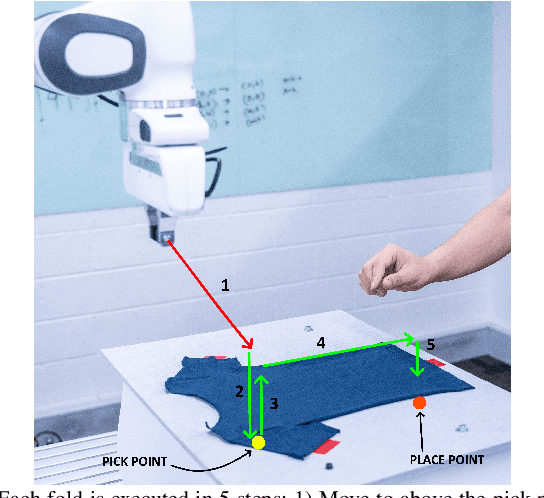
An appropriate user interface to collect human demonstration data for deformable object manipulation has been mostly overlooked in the literature. We present an interaction design for demonstrating cloth folding to robots. Users choose pick and place points on the cloth and can preview a visualization of a simulated cloth before real-robot execution. Two interfaces are proposed: A 2D display-and-mouse interface where points are placed by clicking on an image of the cloth, and a 3D Augmented Reality interface where the chosen points are placed by hand gestures. We conduct a user study with 18 participants, in which each user completed two sequential folds to achieve a cloth goal shape. Results show that while both interfaces were acceptable, the 3D interface was found to be more suitable for understanding the task, and the 2D interface suitable for repetition. Results also found that fold previews improve three key metrics: task efficiency, the ability to predict the final shape of the cloth and overall user satisfaction.
Pretrained equivariant features improve unsupervised landmark discovery
Apr 07, 2021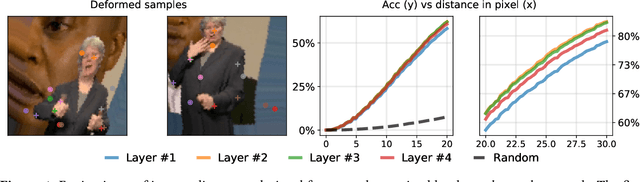
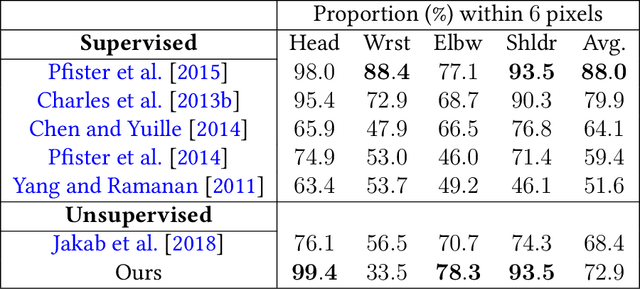
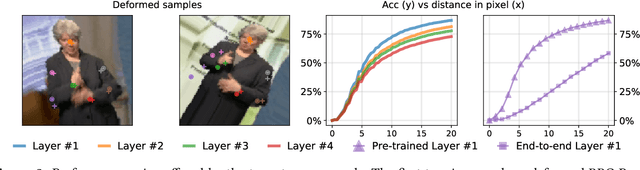
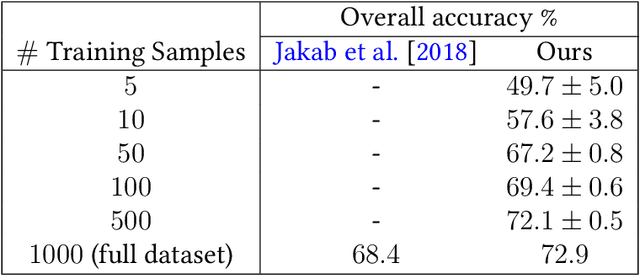
Locating semantically meaningful landmark points is a crucial component of a large number of computer vision pipelines. Because of the small number of available datasets with ground truth landmark annotations, it is important to design robust unsupervised and semi-supervised methods for landmark detection. Many of the recent unsupervised learning methods rely on the equivariance properties of landmarks to synthetic image deformations. Our work focuses on such widely used methods and sheds light on its core problem, its inability to produce equivariant intermediate convolutional features. This finding leads us to formulate a two-step unsupervised approach that overcomes this challenge by first learning powerful pixel-based features and then use the pre-trained features to learn a landmark detector by the traditional equivariance method. Our method produces state-of-the-art results in several challenging landmark detection datasets such as the BBC Pose dataset and the Cat-Head dataset. It performs comparably on a range of other benchmarks.
The Effect of Class Definitions on the Transferability of Adversarial Attacks Against Forensic CNNs
Jan 26, 2021
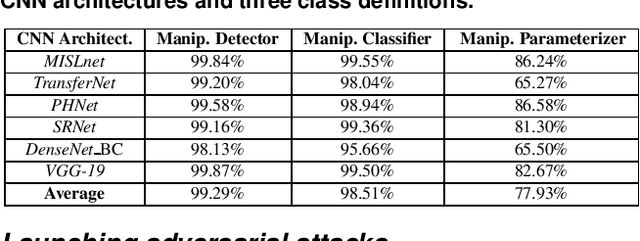
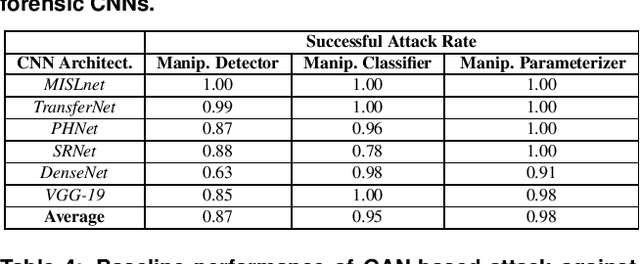
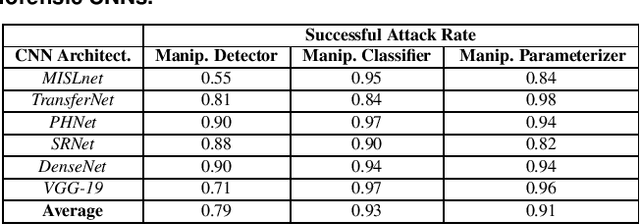
In recent years, convolutional neural networks (CNNs) have been widely used by researchers to perform forensic tasks such as image tampering detection. At the same time, adversarial attacks have been developed that are capable of fooling CNN-based classifiers. Understanding the transferability of adversarial attacks, i.e. an attacks ability to attack a different CNN than the one it was trained against, has important implications for designing CNNs that are resistant to attacks. While attacks on object recognition CNNs are believed to be transferrable, recent work by Barni et al. has shown that attacks on forensic CNNs have difficulty transferring to other CNN architectures or CNNs trained using different datasets. In this paper, we demonstrate that adversarial attacks on forensic CNNs are even less transferrable than previously thought even between virtually identical CNN architectures! We show that several common adversarial attacks against CNNs trained to identify image manipulation fail to transfer to CNNs whose only difference is in the class definitions (i.e. the same CNN architectures trained using the same data). We note that all formulations of class definitions contain the unaltered class. This has important implications for the future design of forensic CNNs that are robust to adversarial and anti-forensic attacks.
3D Scene Compression through Entropy Penalized Neural Representation Functions
Apr 26, 2021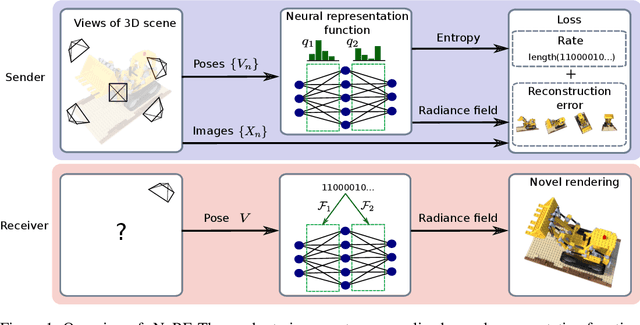
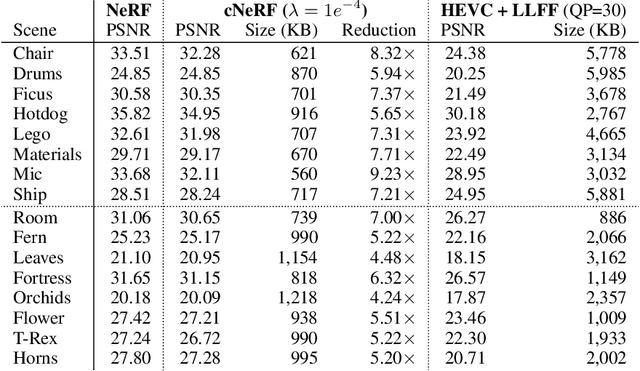
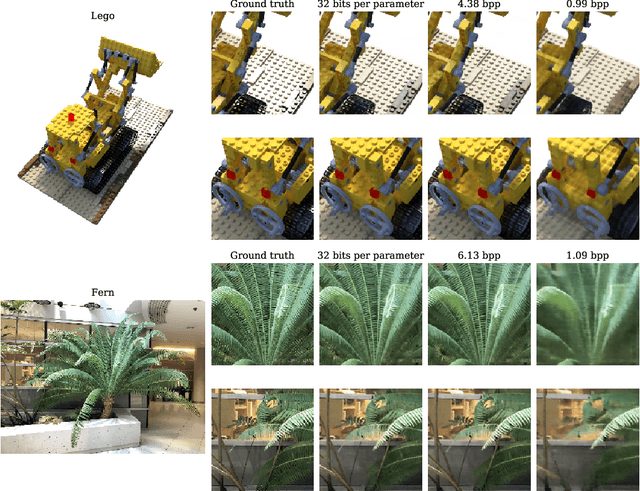
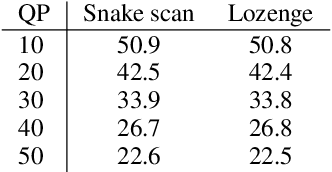
Some forms of novel visual media enable the viewer to explore a 3D scene from arbitrary viewpoints, by interpolating between a discrete set of original views. Compared to 2D imagery, these types of applications require much larger amounts of storage space, which we seek to reduce. Existing approaches for compressing 3D scenes are based on a separation of compression and rendering: each of the original views is compressed using traditional 2D image formats; the receiver decompresses the views and then performs the rendering. We unify these steps by directly compressing an implicit representation of the scene, a function that maps spatial coordinates to a radiance vector field, which can then be queried to render arbitrary viewpoints. The function is implemented as a neural network and jointly trained for reconstruction as well as compressibility, in an end-to-end manner, with the use of an entropy penalty on the parameters. Our method significantly outperforms a state-of-the-art conventional approach for scene compression, achieving simultaneously higher quality reconstructions and lower bitrates. Furthermore, we show that the performance at lower bitrates can be improved by jointly representing multiple scenes using a soft form of parameter sharing.
Integrating Data and Image Domain Deep Learning for Limited Angle Tomography using Consensus Equilibrium
Aug 31, 2019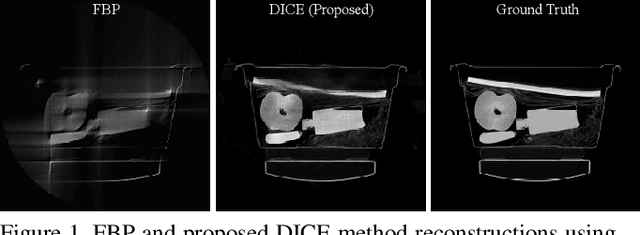
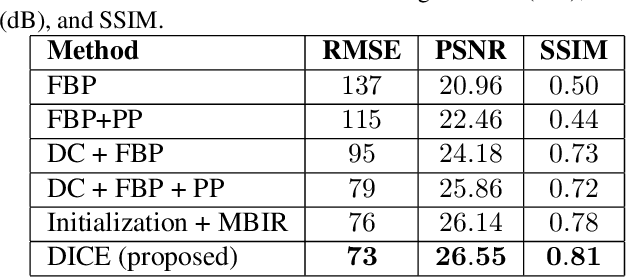
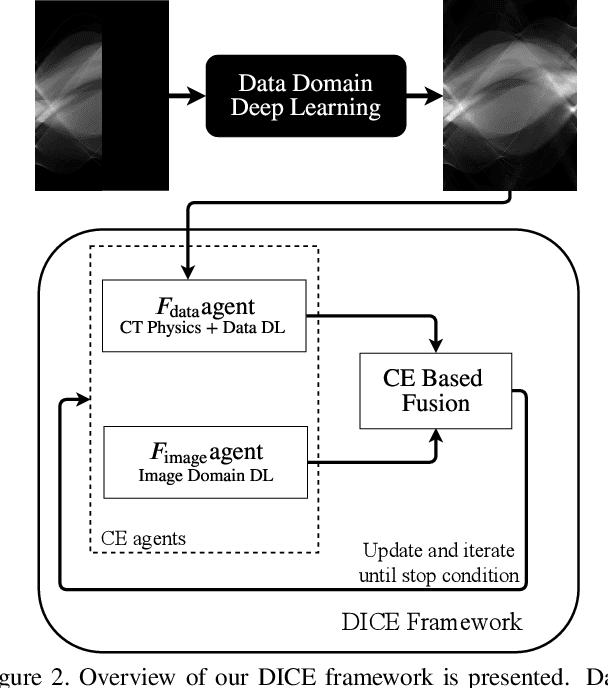
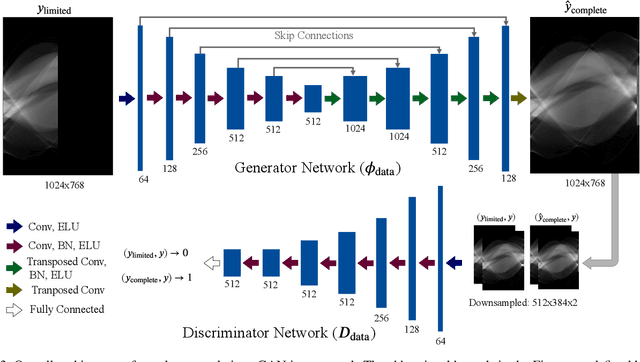
Computed Tomography (CT) is a non-invasive imaging modality with applications ranging from healthcare to security. It reconstructs cross-sectional images of an object using a collection of projection data collected at different angles. Conventional methods, such as FBP, require that the projection data be uniformly acquired over the complete angular range. In some applications, it is not possible to acquire such data. Security is one such domain where non-rotational scanning configurations are being developed which violate the complete data assumption. Conventional methods produce images from such data that are filled with artifacts. The recent success of deep learning (DL) methods has inspired researchers to post-process these artifact laden images using deep neural networks (DNNs). This approach has seen limited success on real CT problems. Another approach has been to pre-process the incomplete data using DNNs aiming to avoid the creation of artifacts altogether. Due to imperfections in the learning process, this approach can still leave perceptible residual artifacts. In this work, we aim to combine the power of deep learning in both the data and image domains through a two-step process based on the consensus equilibrium (CE) framework. Specifically, we use conditional generative adversarial networks (cGANs) in both the data and the image domain for enhanced performance and efficient computation and combine them through a consensus process. We demonstrate the effectiveness of our approach on a real security CT dataset for a challenging 90 degree limited-angle problem. The same framework can be applied to other limited data problems arising in applications such as electron microscopy, non-destructive evaluation, and medical imaging.
Towards Unbiased COVID-19 Lesion Localisation and Segmentation via Weakly Supervised Learning
Mar 01, 2021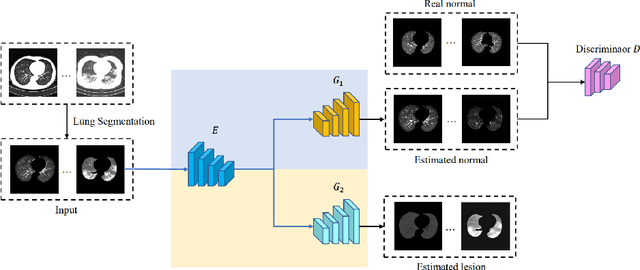
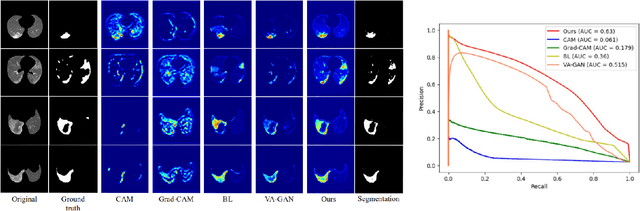
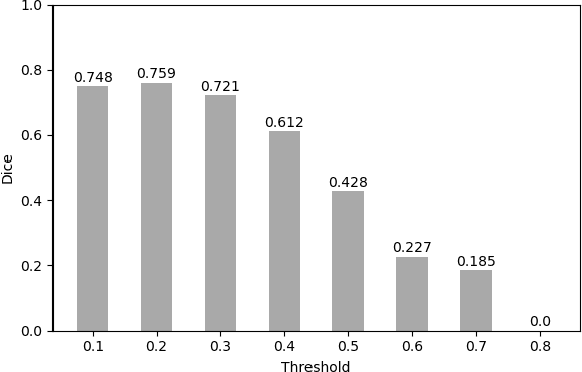
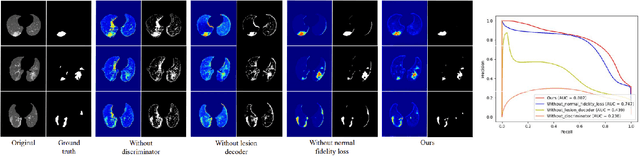
Despite tremendous efforts, it is very challenging to generate a robust model to assist in the accurate quantification assessment of COVID-19 on chest CT images. Due to the nature of blurred boundaries, the supervised segmentation methods usually suffer from annotation biases. To support unbiased lesion localisation and to minimise the labeling costs, we propose a data-driven framework supervised by only image-level labels. The framework can explicitly separate potential lesions from original images, with the help of a generative adversarial network and a lesion-specific decoder. Experiments on two COVID-19 datasets demonstrate the effectiveness of the proposed framework and its superior performance to several existing methods.