 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSCBench: A PVC Diagnostic Benchmark for Commodity Supply Chain Reasoning
Jan 05, 2026Large Language Models (LLMs) have achieved remarkable success in general benchmarks, yet their competence in commodity supply chains (CSCs) -- a domain governed by institutional rule systems and feasibility constraints -- remains under-explored. CSC decisions are shaped jointly by process stages (e.g., planning, procurement, delivery), variety-specific rules (e.g., contract specifications and delivery grades), and reasoning depth (from retrieval to multi-step analysis and decision selection). We introduce CSCBench, a 2.3K+ single-choice benchmark for CSC reasoning, instantiated through our PVC 3D Evaluation Framework (Process, Variety, and Cognition). The Process axis aligns tasks with SCOR+Enable; the Variety axis operationalizes commodity-specific rule systems under coupled material-information-financial constraints, grounded in authoritative exchange guidebooks/rulebooks and industry reports; and the Cognition axis follows Bloom's revised taxonomy. Evaluating representative LLMs under a direct prompting setting, we observe strong performance on the Process and Cognition axes but substantial degradation on the Variety axis, especially on Freight Agreements. CSCBench provides a diagnostic yardstick for measuring and improving LLM capabilities in this high-stakes domain.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
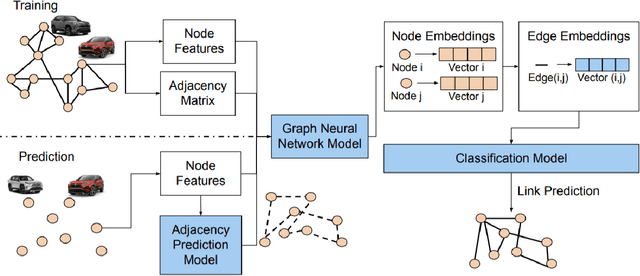
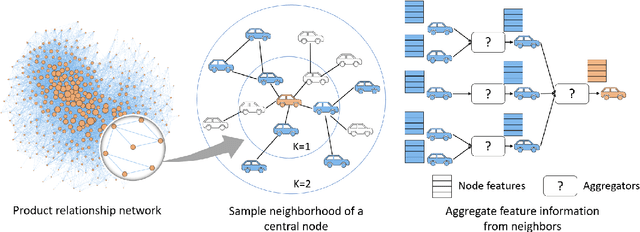
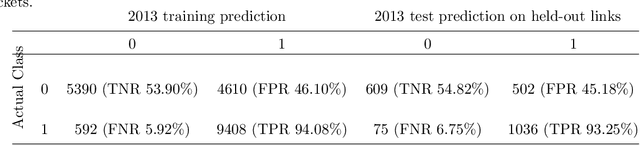
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.