 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Model Representations and their Robustness against Noise for Speech Emotion Analysis
Mar 03, 2023



Pre-trained model representations have demonstrated state-of-the-art performance in speech recognition, natural language processing, and other applications. Speech models, such as Bidirectional Encoder Representations from Transformers (BERT) and Hidden units BERT (HuBERT), have enabled generating lexical and acoustic representations to benefit speech recognition applications. We investigated the use of pre-trained model representations for estimating dimensional emotions, such as activation, valence, and dominance, from speech. We observed that while valence may rely heavily on lexical representations, activation and dominance rely mostly on acoustic information. In this work, we used multi-modal fusion representations from pre-trained models to generate state-of-the-art speech emotion estimation, and we showed a 100% and 30% relative improvement in concordance correlation coefficient (CCC) on valence estimation compared to standard acoustic and lexical baselines. Finally, we investigated the robustness of pre-trained model representations against noise and reverberation degradation and noticed that lexical and acoustic representations are impacted differently. We discovered that lexical representations are more robust to distortions compared to acoustic representations, and demonstrated that knowledge distillation from a multi-modal model helps to improve the noise-robustness of acoustic-based models.
MAEEG: Masked Auto-encoder for EEG Representation Learning
Oct 27, 2022



Decoding information from bio-signals such as EEG, using machine learning has been a challenge due to the small data-sets and difficulty to obtain labels. We propose a reconstruction-based self-supervised learning model, the masked auto-encoder for EEG (MAEEG), for learning EEG representations by learning to reconstruct the masked EEG features using a transformer architecture. We found that MAEEG can learn representations that significantly improve sleep stage classification (~5% accuracy increase) when only a small number of labels are given. We also found that input sample lengths and different ways of masking during reconstruction-based SSL pretraining have a huge effect on downstream model performance. Specifically, learning to reconstruct a larger proportion and more concentrated masked signal results in better performance on sleep classification. Our findings provide insight into how reconstruction-based SSL could help representation learning for EEG.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022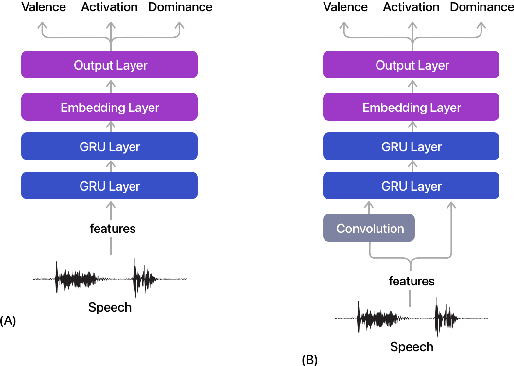
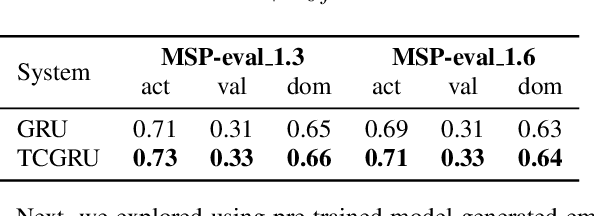
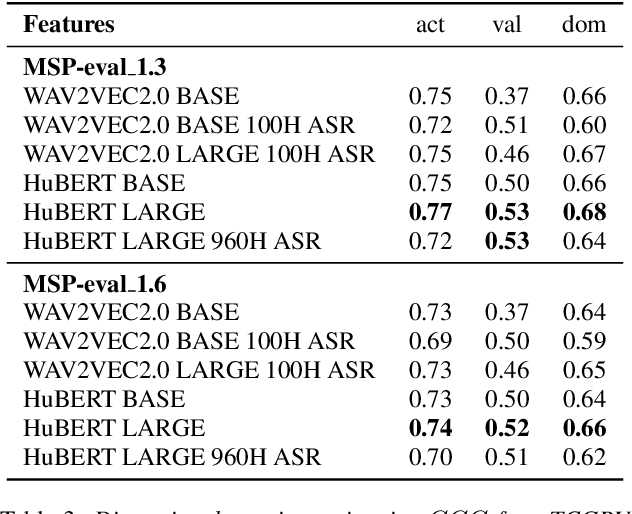
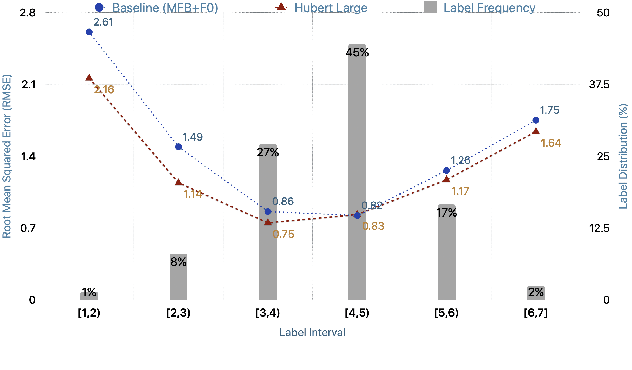
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021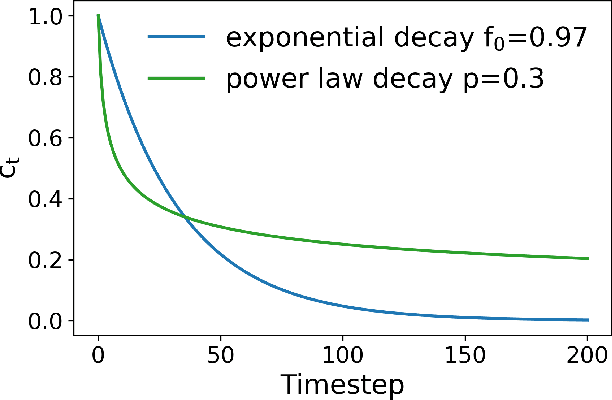
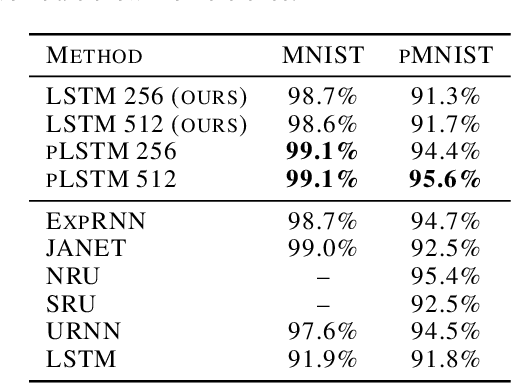
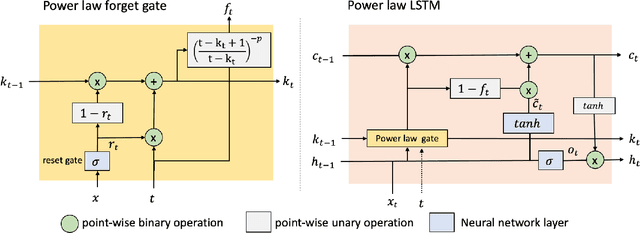
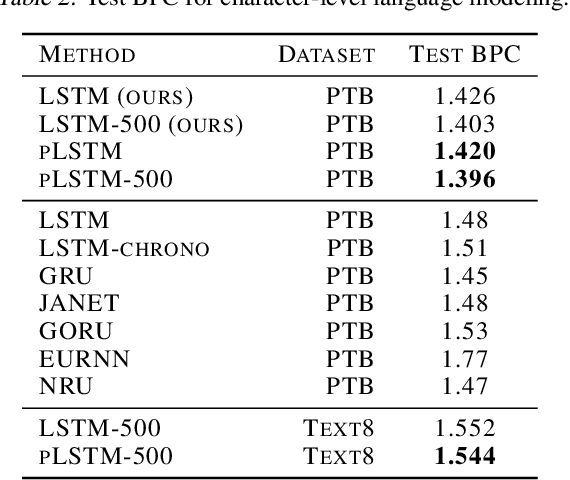
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Mapping the Timescale Organization of Neural Language Models
Dec 12, 2020
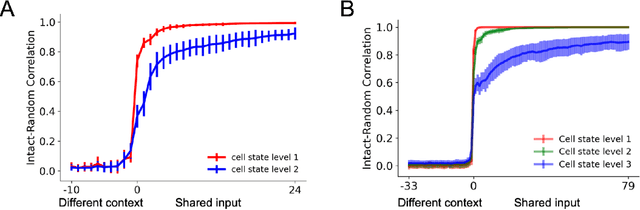
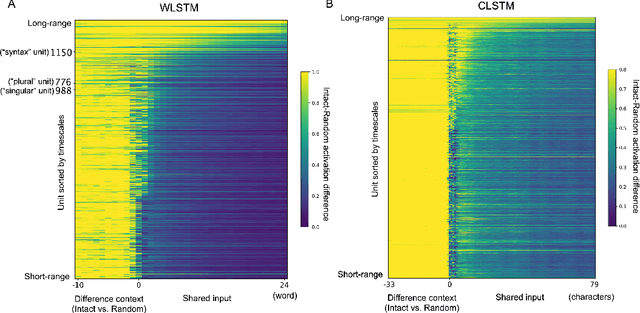
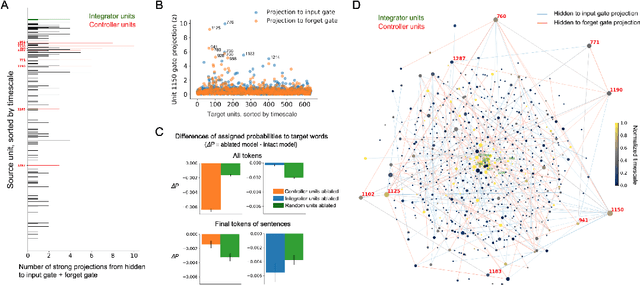
In the human brain, sequences of language input are processed within a distributed and hierarchical architecture, in which higher stages of processing encode contextual information over longer timescales. In contrast, in recurrent neural networks which perform natural language processing, we know little about how the multiple timescales of contextual information are functionally organized. Therefore, we applied tools developed in neuroscience to map the "processing timescales" of individual units within a word-level LSTM language model. This timescale-mapping method assigned long timescales to units previously found to track long-range syntactic dependencies, and revealed a new cluster of previously unreported long-timescale units. Next, we explored the functional role of units by examining the relationship between their processing timescales and network connectivity. We identified two classes of long-timescale units: "Controller" units composed a densely interconnected subnetwork and strongly projected to the forget and input gates of the rest of the network, while "Integrator" units showed the longest timescales in the network, and expressed projection profiles closer to the mean projection profile. Ablating integrator and controller units affected model performance at different position of a sentence, suggesting distinctive functions of these two sets of units. Finally, we tested the generalization of these results to a character-level LSTM model. In summary, we demonstrated a model-free technique for mapping the timescale organization in neural network models, and we applied this method to reveal the timescale and functional organization of LSTM language models.