 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Episodic Memory in LLMs with Sequence Order Recall Tasks
Oct 10, 2024



Current LLM benchmarks focus on evaluating models' memory of facts and semantic relations, primarily assessing semantic aspects of long-term memory. However, in humans, long-term memory also includes episodic memory, which links memories to their contexts, such as the time and place they occurred. The ability to contextualize memories is crucial for many cognitive tasks and everyday functions. This form of memory has not been evaluated in LLMs with existing benchmarks. To address the gap in evaluating memory in LLMs, we introduce Sequence Order Recall Tasks (SORT), which we adapt from tasks used to study episodic memory in cognitive psychology. SORT requires LLMs to recall the correct order of text segments, and provides a general framework that is both easily extendable and does not require any additional annotations. We present an initial evaluation dataset, Book-SORT, comprising 36k pairs of segments extracted from 9 books recently added to the public domain. Based on a human experiment with 155 participants, we show that humans can recall sequence order based on long-term memory of a book. We find that models can perform the task with high accuracy when relevant text is given in-context during the SORT evaluation. However, when presented with the book text only during training, LLMs' performance on SORT falls short. By allowing to evaluate more aspects of memory, we believe that SORT will aid in the emerging development of memory-augmented models.
MPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
Scope is all you need: Transforming LLMs for HPC Code
Aug 18, 2023



With easier access to powerful compute resources, there is a growing trend in the field of AI for software development to develop larger and larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size (e.g., billions of parameters) and demand expensive compute resources for training. We found this design choice confusing - why do we need large LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question design choices made by existing LLMs by developing smaller LLMs for specific domains - we call them domain-specific LLMs. Specifically, we start off with HPC as a domain and propose a novel tokenizer named Tokompiler, designed specifically for preprocessing code in HPC and compilation-centric tasks. Tokompiler leverages knowledge of language primitives to generate language-oriented tokens, providing a context-aware understanding of code structure while avoiding human semantics attributed to code structures completely. We applied Tokompiler to pre-train two state-of-the-art models, SPT-Code and Polycoder, for a Fortran code corpus mined from GitHub. We evaluate the performance of these models against the conventional LLMs. Results demonstrate that Tokompiler significantly enhances code completion accuracy and semantic understanding compared to traditional tokenizers in normalized-perplexity tests, down to ~1 perplexity score. This research opens avenues for further advancements in domain-specific LLMs, catering to the unique demands of HPC and compilation tasks.
Brain encoding models based on multimodal transformers can transfer across language and vision
May 20, 2023



Encoding models have been used to assess how the human brain represents concepts in language and vision. While language and vision rely on similar concept representations, current encoding models are typically trained and tested on brain responses to each modality in isolation. Recent advances in multimodal pretraining have produced transformers that can extract aligned representations of concepts in language and vision. In this work, we used representations from multimodal transformers to train encoding models that can transfer across fMRI responses to stories and movies. We found that encoding models trained on brain responses to one modality can successfully predict brain responses to the other modality, particularly in cortical regions that represent conceptual meaning. Further analysis of these encoding models revealed shared semantic dimensions that underlie concept representations in language and vision. Comparing encoding models trained using representations from multimodal and unimodal transformers, we found that multimodal transformers learn more aligned representations of concepts in language and vision. Our results demonstrate how multimodal transformers can provide insights into the brain's capacity for multimodal processing.
Memory in humans and deep language models: Linking hypotheses for model augmentation
Oct 07, 2022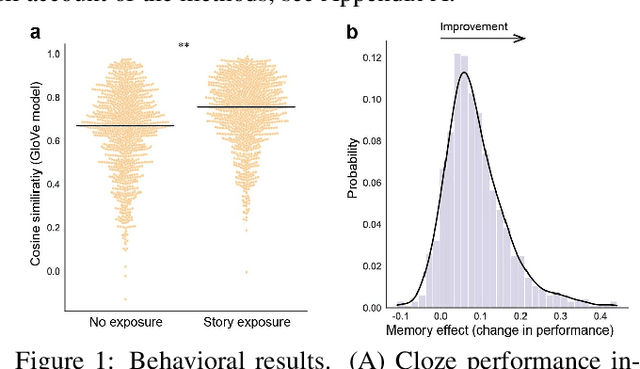
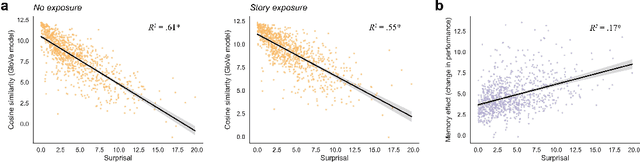
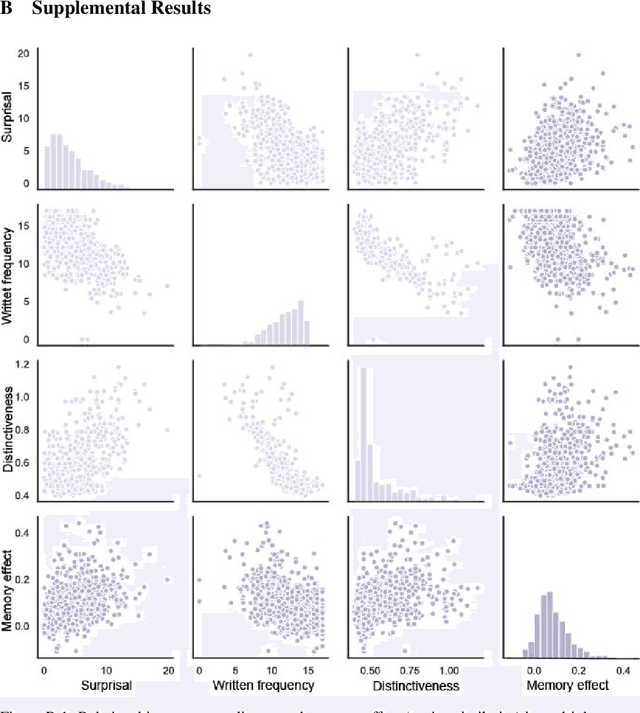
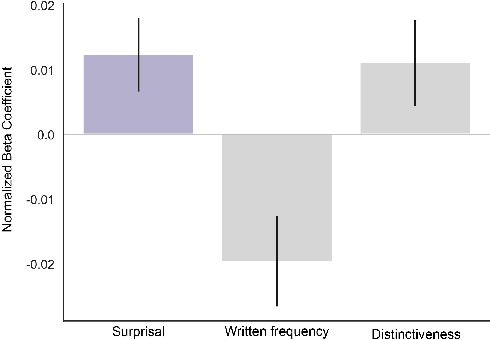
The computational complexity of the self-attention mechanism in Transformer models significantly limits their ability to generalize over long temporal durations. Memory-augmentation, or the explicit storing of past information in external memory for subsequent predictions, has become a constructive avenue for mitigating this limitation. We argue that memory-augmented Transformers can benefit substantially from considering insights from the memory literature in humans. We detail an approach to integrating evidence from the human memory system through the specification of cross-domain linking hypotheses. We then provide an empirical demonstration to evaluate the use of surprisal as a linking hypothesis, and further identify the limitations of this approach to inform future research.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021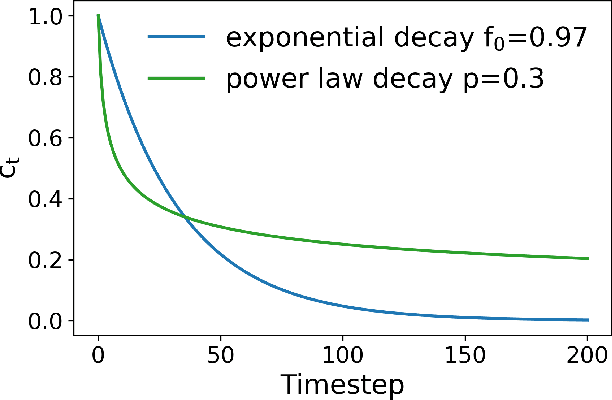
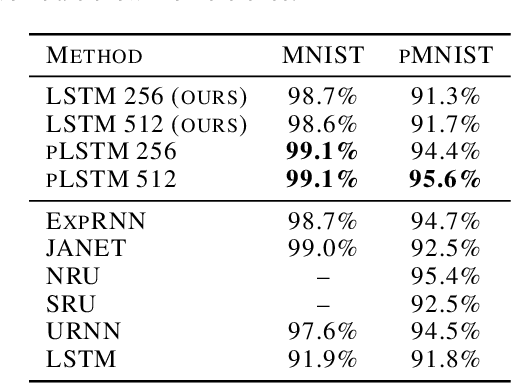
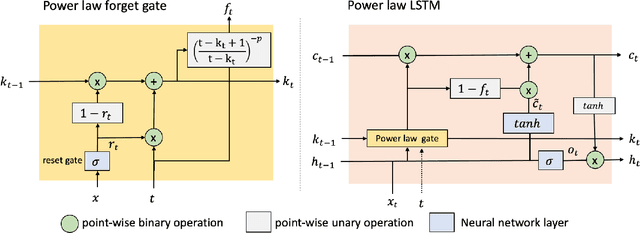
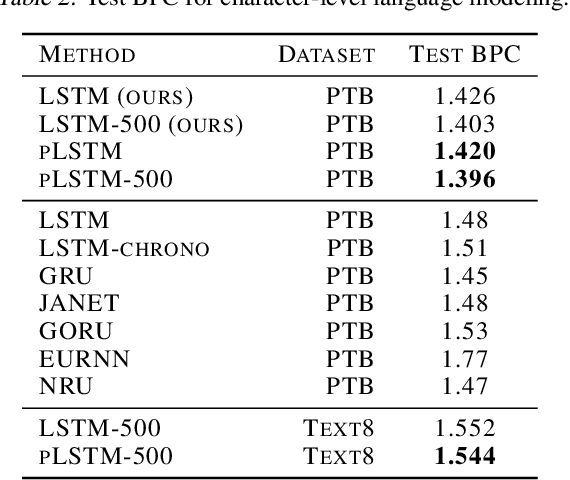
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Multi-timescale representation learning in LSTM Language Models
Sep 27, 2020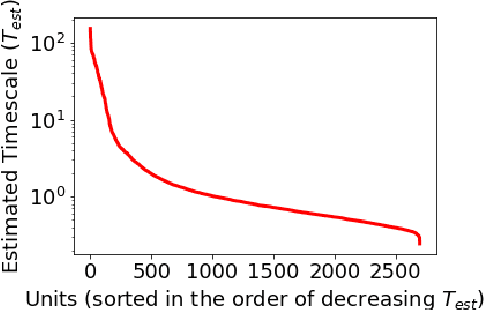
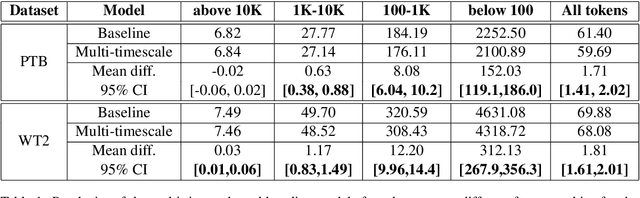
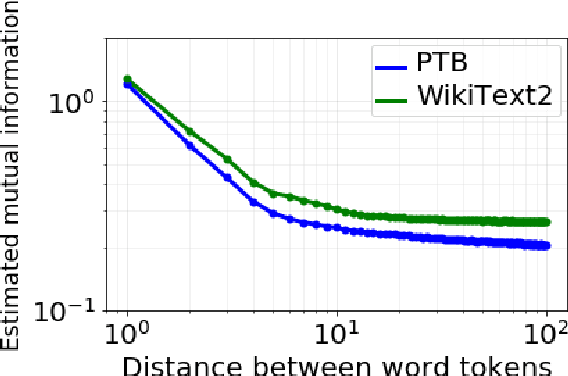

Although neural language models are effective at capturing statistics of natural language, their representations are challenging to interpret. In particular, it is unclear how these models retain information over multiple timescales. In this work, we construct explicitly multi-timescale language models by manipulating the input and forget gate biases in a long short-term memory (LSTM) network. The distribution of timescales is selected to approximate power law statistics of natural language through a combination of exponentially decaying memory cells. We then empirically analyze the timescale of information routed through each part of the model using word ablation experiments and forget gate visualizations. These experiments show that the multi-timescale model successfully learns representations at the desired timescales, and that the distribution includes longer timescales than a standard LSTM. Further, information about high-,mid-, and low-frequency words is routed preferentially through units with the appropriate timescales. Thus we show how to construct language models with interpretable representations of different information timescales.