 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Reconstruction Nets for Image Super-Resolution with Gradient Sensitive Loss
Sep 19, 2018
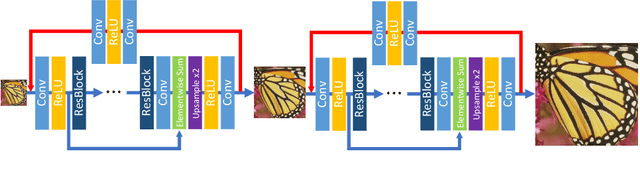
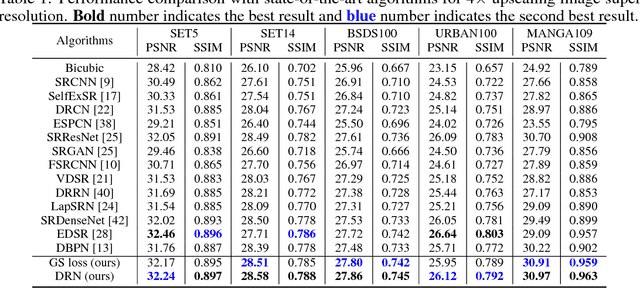
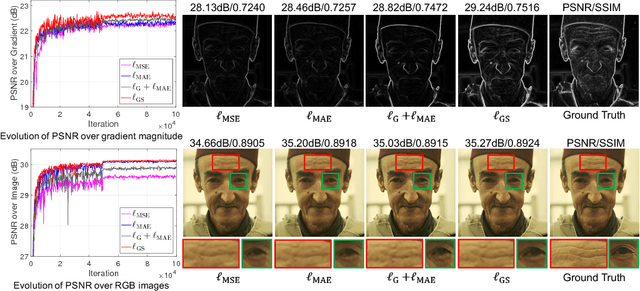
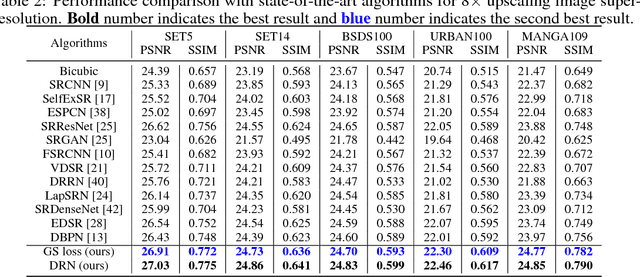
Deep neural networks have exhibited promising performance in image super-resolution (SR) due to the power in learning the non-linear mapping from low-resolution (LR) images to high-resolution (HR) images. However, most deep learning methods employ feed-forward architectures, and thus the dependencies between LR and HR images are not fully exploited, leading to limited learning performance. Moreover, most deep learning based SR methods apply the pixel-wise reconstruction error as the loss, which, however, may fail to capture high-frequency information and produce perceptually unsatisfying results, whilst the recent perceptual loss relies on some pre-trained deep model and they may not generalize well. In this paper, we introduce a mask to separate the image into low- and high-frequency parts based on image gradient magnitude, and then devise a gradient sensitive loss to well capture the structures in the image without sacrificing the recovery of low-frequency content. Moreover, by investigating the duality in SR, we develop a dual reconstruction network (DRN) to improve the SR performance. We provide theoretical analysis on the generalization performance of our method and demonstrate its effectiveness and superiority with thorough experiments.
A Miniaturized Semantic Segmentation Method for Remote Sensing Image
Oct 27, 2018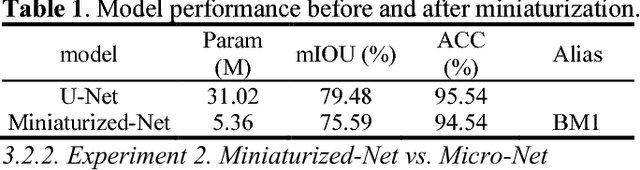
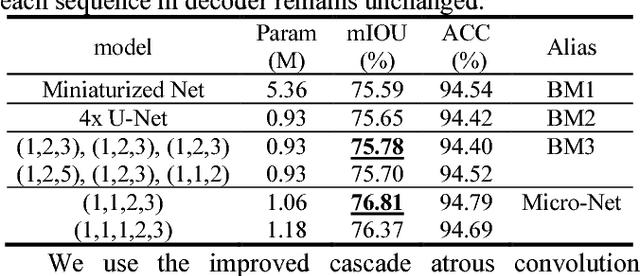
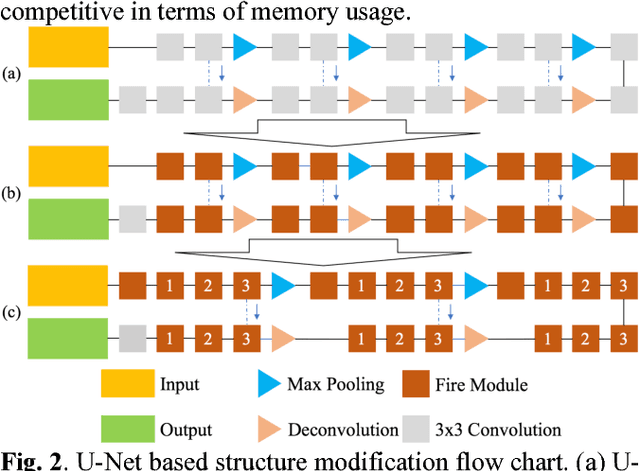
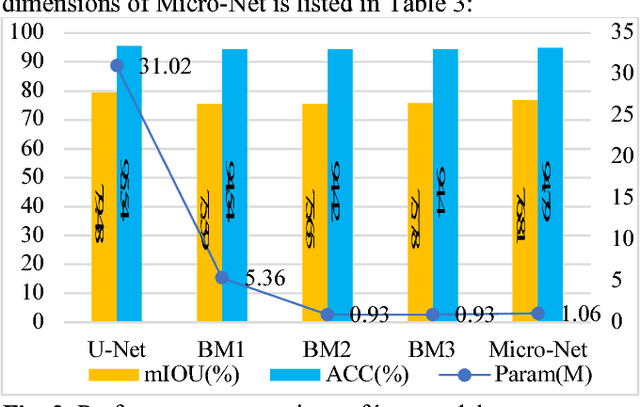
In order to save the memory, we propose a miniaturization method for neural network to reduce the parameter quantity existed in remote sensing (RS) image semantic segmentation model. The compact convolution optimization method is first used for standard U-Net to reduce the weights quantity. With the purpose of decreasing model performance loss caused by miniaturization and based on the characteristics of remote sensing image, fewer down-samplings and improved cascade atrous convolution are then used to improve the performance of the miniaturized U-Net. Compared with U-Net, our proposed Micro-Net not only achieves 29.26 times model compression, but also basically maintains the performance unchanged on the public dataset. We provide a Keras and Tensorflow hybrid programming implementation for our model: https://github.com/Isnot2bad/Micro-Net
Deep Autofocus for Synthetic Aperture Sonar
Oct 29, 2020
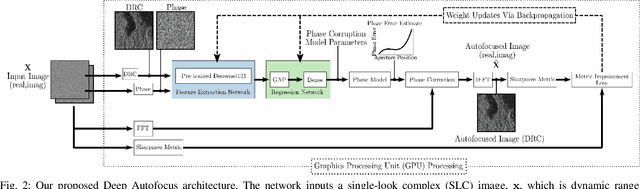
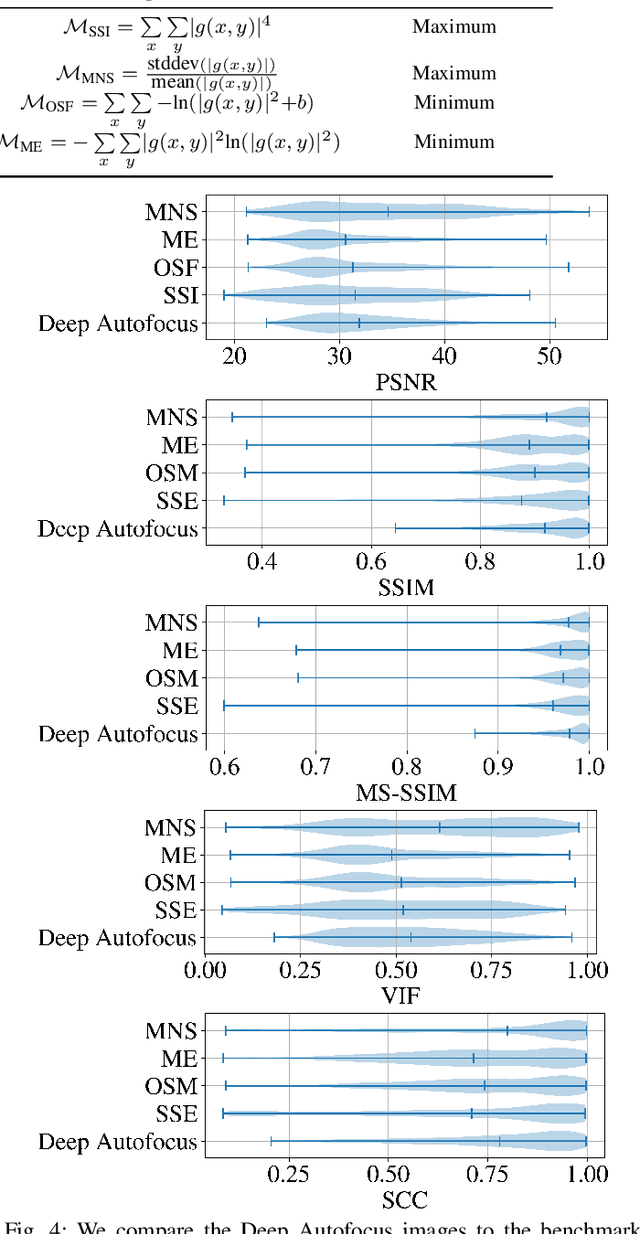

Synthetic aperture sonar (SAS) requires precise positional and environmental information to produce well-focused output during the image reconstruction step. However, errors in these measurements are commonly present resulting in defocused imagery. To overcome these issues, an \emph{autofocus} algorithm is employed as a post-processing step after image reconstruction for the purpose of improving image quality using the image content itself. These algorithms are usually iterative and metric-based in that they seek to optimize an image sharpness metric. In this letter, we demonstrate the potential of machine learning, specifically deep learning, to address the autofocus problem. We formulate the problem as a self-supervised, phase error estimation task using a deep network we call Deep Autofocus. Our formulation has the advantages of being non-iterative (and thus fast) and not requiring ground truth focused-defocused images pairs as often required by other deblurring deep learning methods. We compare our technique against a set of common sharpness metrics optimized using gradient descent over a real-world dataset. Our results demonstrate Deep Autofocus can produce imagery that is perceptually as good as benchmark iterative techniques but at a substantially lower computational cost. We conclude that our proposed Deep Autofocus can provide a more favorable cost-quality trade-off than state-of-the-art alternatives with significant potential of future research.
SnapMix: Semantically Proportional Mixing for Augmenting Fine-grained Data
Dec 09, 2020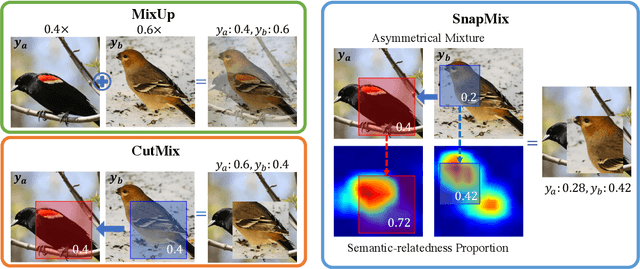

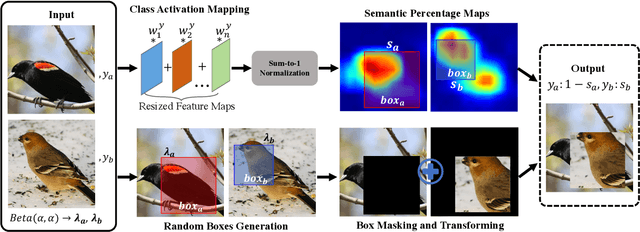

Data mixing augmentation has proved effective in training deep models. Recent methods mix labels mainly based on the mixture proportion of image pixels. As the main discriminative information of a fine-grained image usually resides in subtle regions, methods along this line are prone to heavy label noise in fine-grained recognition. We propose in this paper a novel scheme, termed as Semantically Proportional Mixing (SnapMix), which exploits class activation map (CAM) to lessen the label noise in augmenting fine-grained data. SnapMix generates the target label for a mixed image by estimating its intrinsic semantic composition, and allows for asymmetric mixing operations and ensures semantic correspondence between synthetic images and target labels. Experiments show that our method consistently outperforms existing mixed-based approaches on various datasets and under different network depths. Furthermore, by incorporating the mid-level features, the proposed SnapMix achieves top-level performance, demonstrating its potential to serve as a solid baseline for fine-grained recognition. Our code is available at https://github.com/Shaoli-Huang/SnapMix.git.
Image-based Survival Analysis for Lung Cancer Patients using CNNs
Oct 08, 2018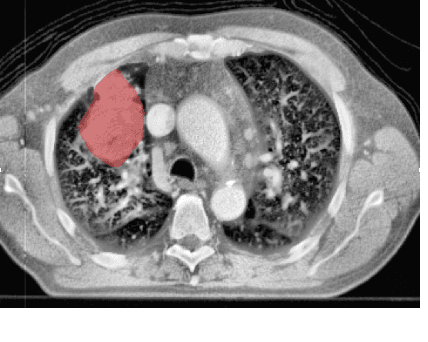
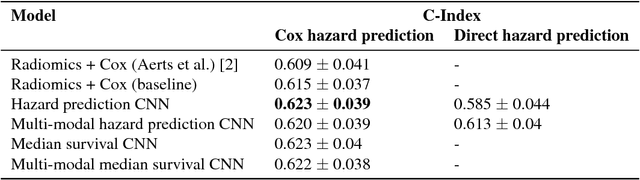
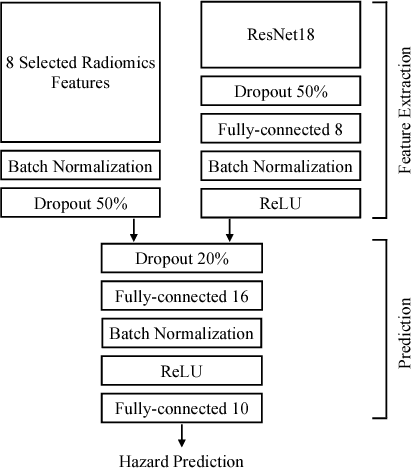
Traditional survival models such as the Cox proportional hazards model are typically based on scalar or categorical clinical features. With the advent of increasingly large image datasets, it has become feasible to incorporate quantitative image features into survival prediction. So far, this kind of analysis is mostly based on radiomics features, i.e. a fixed set of features that is mathematically defined a priori. To capture highly abstract information, it is desirable to learn the feature extraction using convolutional neural networks. However, for tomographic medical images, model training is difficult because on the one hand, only few samples of 3D image data fit into one batch at once and on the other hand, survival loss functions are essentially ordering measures that require large batch sizes. In this work, we show that by simplifying survival analysis to median survival classification, convolutional neural networks can be trained with small batch sizes and learn features that predict survival equally well as end-to-end hazard prediction networks. Our approach outperforms the previous state of the art in a publicly available lung cancer dataset.
Deep Learning for Vision-Based Fall Detection System: Enhanced Optical Dynamic Flow
Mar 18, 2021Accurate fall detection for the assistance of older people is crucial to reduce incidents of deaths or injuries due to falls. Meanwhile, a vision-based fall detection system has shown some significant results to detect falls. Still, numerous challenges need to be resolved. The impact of deep learning has changed the landscape of the vision-based system, such as action recognition. The deep learning technique has not been successfully implemented in vision-based fall detection systems due to the requirement of a large amount of computation power and the requirement of a large amount of sample training data. This research aims to propose a vision-based fall detection system that improves the accuracy of fall detection in some complex environments such as the change of light condition in the room. Also, this research aims to increase the performance of the pre-processing of video images. The proposed system consists of the Enhanced Dynamic Optical Flow technique that encodes the temporal data of optical flow videos by the method of rank pooling, which thereby improves the processing time of fall detection and improves the classification accuracy in dynamic lighting conditions. The experimental results showed that the classification accuracy of the fall detection improved by around 3% and the processing time by 40 to 50ms. The proposed system concentrates on decreasing the processing time of fall detection and improving classification accuracy. Meanwhile, it provides a mechanism for summarizing a video into a single image by using a dynamic optical flow technique, which helps to increase the performance of image pre-processing steps.
* 16 pages
An Enhanced Randomly Initialized Convolutional Neural Network for Columnar Cactus Recognition in Unmanned Aerial Vehicle Imagery
May 10, 2021
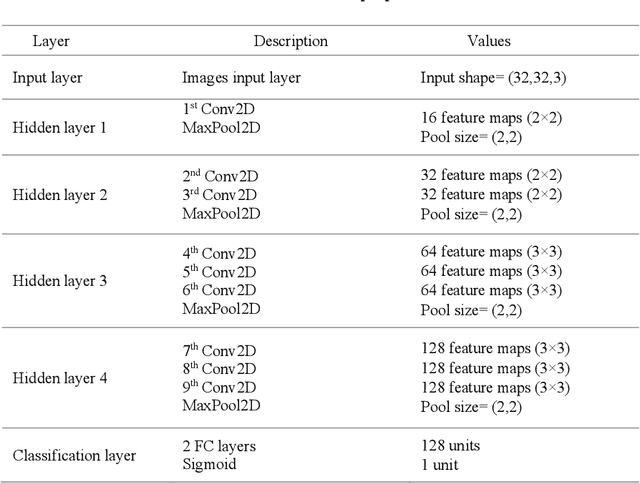

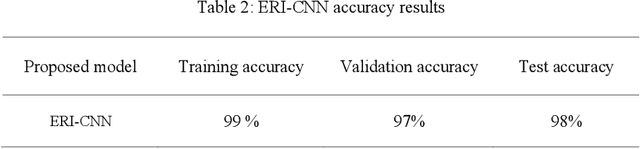
Recently, Convolutional Neural Networks (CNNs) have made a great performance for remote sensing image classification. Plant recognition using CNNs is one of the active deep learning research topics due to its added-value in different related fields, especially environmental conservation and natural areas preservation. Automatic recognition of plants in protected areas helps in the surveillance process of these zones and ensures the sustainability of their ecosystems. In this work, we propose an Enhanced Randomly Initialized Convolutional Neural Network (ERI-CNN) for the recognition of columnar cactus, which is an endemic plant that exists in the Tehuac\'an-Cuicatl\'an Valley in southeastern Mexico. We used a public dataset created by a group of researchers that consists of more than 20000 remote sensing images. The experimental results confirm the effectiveness of the proposed model compared to other models reported in the literature like InceptionV3 and the modified LeNet-5 CNN. Our ERI-CNN provides 98% of accuracy, 97% of precision, 97% of recall, 97.5% as f1-score, and 0.056 loss.
Content Masked Loss: Human-Like Brush Stroke Planning in a Reinforcement Learning Painting Agent
Dec 18, 2020



The objective of most Reinforcement Learning painting agents is to minimize the loss between a target image and the paint canvas. Human painter artistry emphasizes important features of the target image rather than simply reproducing it (DiPaola 2007). Using adversarial or L2 losses in the RL painting models, although its final output is generally a work of finesse, produces a stroke sequence that is vastly different from that which a human would produce since the model does not have knowledge about the abstract features in the target image. In order to increase the human-like planning of the model without the use of expensive human data, we introduce a new loss function for use with the model's reward function: Content Masked Loss. In the context of robot painting, Content Masked Loss employs an object detection model to extract features which are used to assign higher weight to regions of the canvas that a human would find important for recognizing content. The results, based on 332 human evaluators, show that the digital paintings produced by our Content Masked model show detectable subject matter earlier in the stroke sequence than existing methods without compromising on the quality of the final painting.
Disparity Image Segmentation For ADAS
Jun 27, 2018We present a simple solution for segmenting grayscale images using existing Connected Component Labeling (CCL) algorithms (which are generally applied to binary images), which was efficient enough to be implemented in a constrained (embedded automotive) architecture. Our solution customizes the region growing and merging approach, and is primarily targeted for stereoscopic disparity images where nearer objects carry more relevance. We provide results from a standard OpenCV implementation for some basic cases and an image from the Tsukuba stereo-pair dataset.
Analysis and Applications of Class-wise Robustness in Adversarial Training
Jun 23, 2021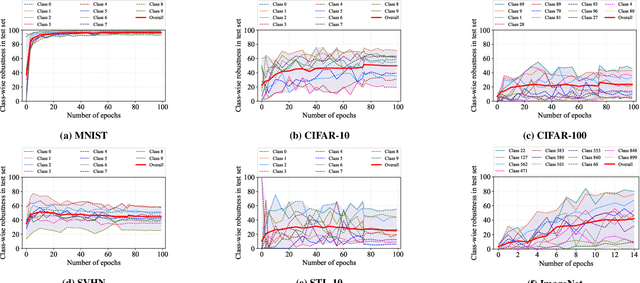
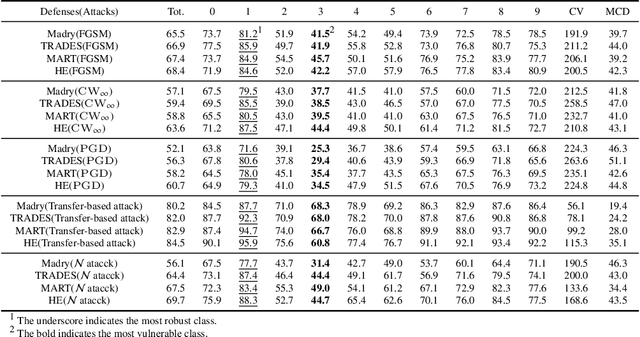

Adversarial training is one of the most effective approaches to improve model robustness against adversarial examples. However, previous works mainly focus on the overall robustness of the model, and the in-depth analysis on the role of each class involved in adversarial training is still missing. In this paper, we propose to analyze the class-wise robustness in adversarial training. First, we provide a detailed diagnosis of adversarial training on six benchmark datasets, i.e., MNIST, CIFAR-10, CIFAR-100, SVHN, STL-10 and ImageNet. Surprisingly, we find that there are remarkable robustness discrepancies among classes, leading to unbalance/unfair class-wise robustness in the robust models. Furthermore, we keep investigating the relations between classes and find that the unbalanced class-wise robustness is pretty consistent among different attack and defense methods. Moreover, we observe that the stronger attack methods in adversarial learning achieve performance improvement mainly from a more successful attack on the vulnerable classes (i.e., classes with less robustness). Inspired by these interesting findings, we design a simple but effective attack method based on the traditional PGD attack, named Temperature-PGD attack, which proposes to enlarge the robustness disparity among classes with a temperature factor on the confidence distribution of each image. Experiments demonstrate our method can achieve a higher attack rate than the PGD attack. Furthermore, from the defense perspective, we also make some modifications in the training and inference phase to improve the robustness of the most vulnerable class, so as to mitigate the large difference in class-wise robustness. We believe our work can contribute to a more comprehensive understanding of adversarial training as well as rethinking the class-wise properties in robust models.