 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Disambiguate Strongly Interacting Hands via Probabilistic Per-pixel Part Segmentation
Jul 01, 2021
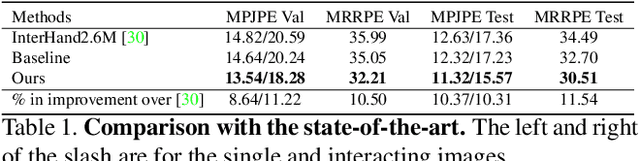
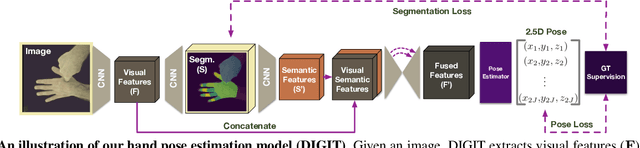

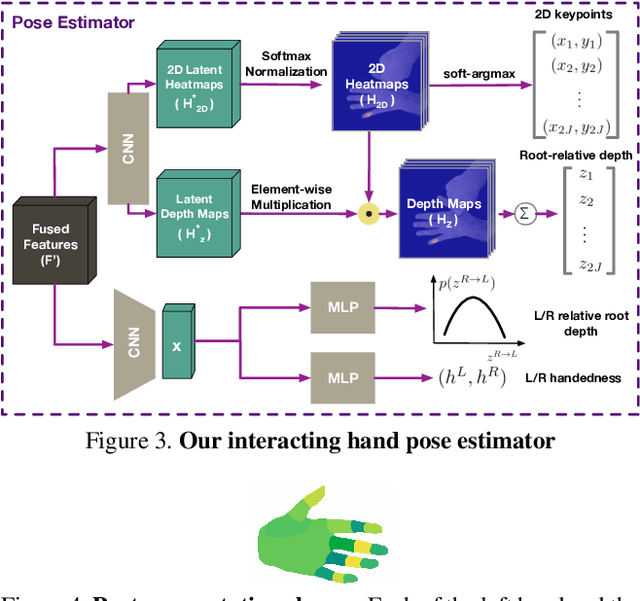
In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.
Visual Place Recognition using LiDAR Intensity Information
Mar 17, 2021


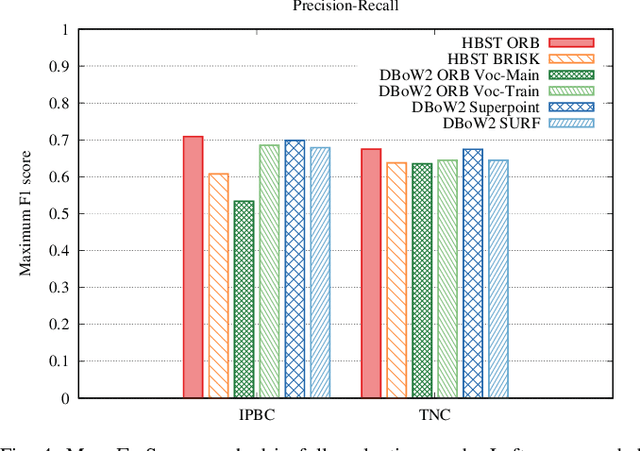
Robots and autonomous systems need to know where they are within a map to navigate effectively. Thus, simultaneous localization and mapping or SLAM is a common building block of robot navigation systems. When building a map via a SLAM system, robots need to re-recognize places to find loop closure and reduce the odometry drift. Image-based place recognition received a lot of attention in computer vision, and in this work, we investigate how such approaches can be used for 3D LiDAR data. Recent LiDAR sensors produce high-resolution 3D scans in combination with comparably stable intensity measurements. Through a cylindrical projection, we can turn this information into a panoramic image. As a result, we can apply techniques from visual place recognition to LiDAR intensity data. The question of how well this approach works in practice has not been answered so far. This paper provides an analysis of how such visual techniques can be with LiDAR data, and we provide an evaluation on different datasets. Our results suggest that this form of place recognition is possible and an effective means for determining loop closures.
Automatic Document Image Binarization using Bayesian Optimization
Oct 21, 2017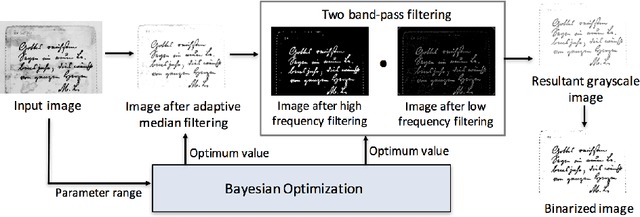
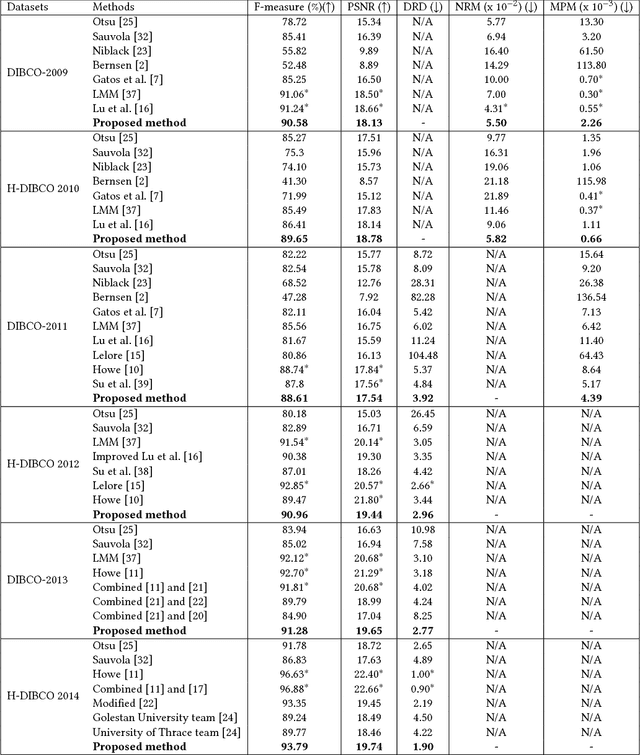

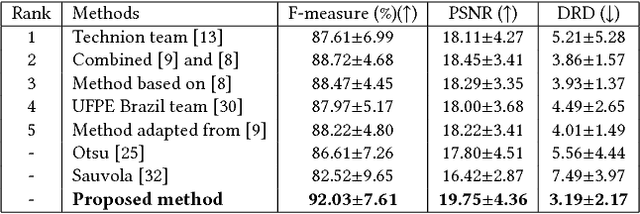
Document image binarization is often a challenging task due to various forms of degradation. Although there exist several binarization techniques in literature, the binarized image is typically sensitive to control parameter settings of the employed technique. This paper presents an automatic document image binarization algorithm to segment the text from heavily degraded document images. The proposed technique uses a two band-pass filtering approach for background noise removal, and Bayesian optimization for automatic hyperparameter selection for optimal results. The effectiveness of the proposed binarization technique is empirically demonstrated on the Document Image Binarization Competition (DIBCO) and the Handwritten Document Image Binarization Competition (H-DIBCO) datasets.
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
Jun 08, 2021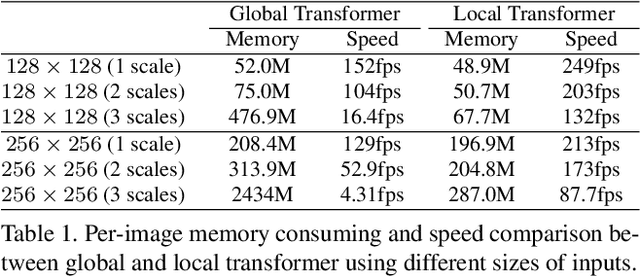
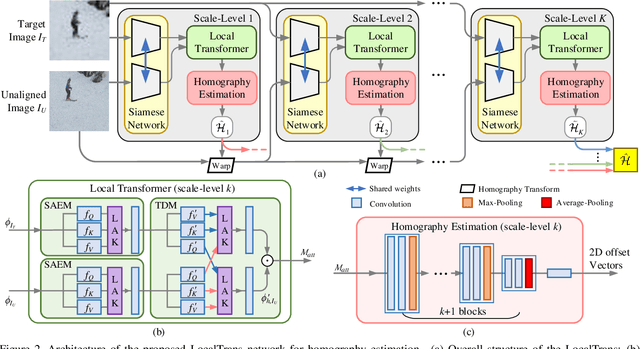
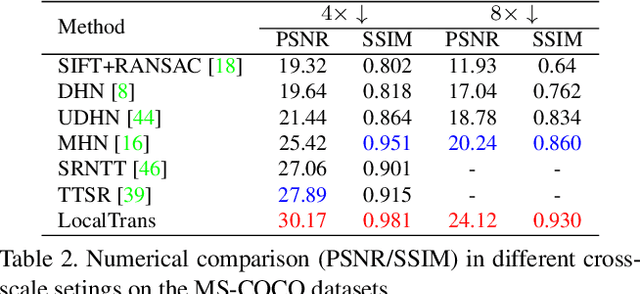
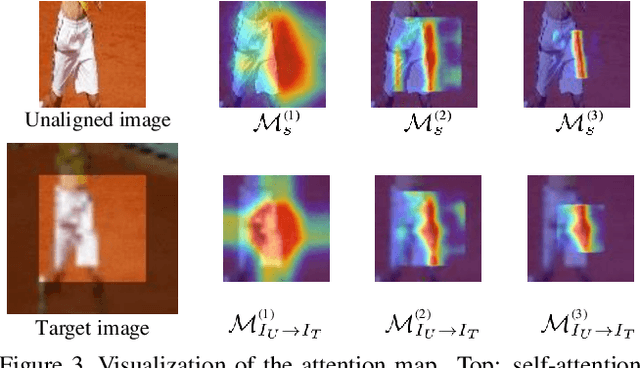
Cross-resolution image alignment is a key problem in multiscale gigapixel photography, which requires to estimate homography matrix using images with large resolution gap. Existing deep homography methods concatenate the input images or features, neglecting the explicit formulation of correspondences between them, which leads to degraded accuracy in cross-resolution challenges. In this paper, we consider the cross-resolution homography estimation as a multimodal problem, and propose a local transformer network embedded within a multiscale structure to explicitly learn correspondences between the multimodal inputs, namely, input images with different resolutions. The proposed local transformer adopts a local attention map specifically for each position in the feature. By combining the local transformer with the multiscale structure, the network is able to capture long-short range correspondences efficiently and accurately. Experiments on both the MS-COCO dataset and the real-captured cross-resolution dataset show that the proposed network outperforms existing state-of-the-art feature-based and deep-learning-based homography estimation methods, and is able to accurately align images under $10\times$ resolution gap.
Fast Monte Carlo Rendering via Multi-Resolution Sampling
Jun 24, 2021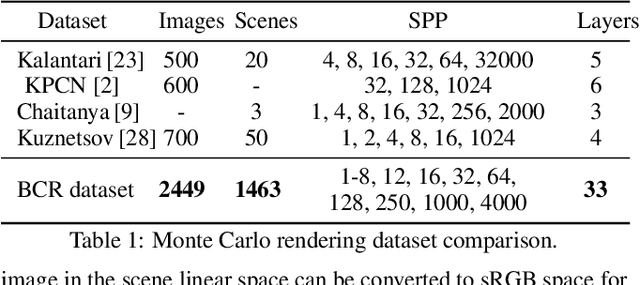

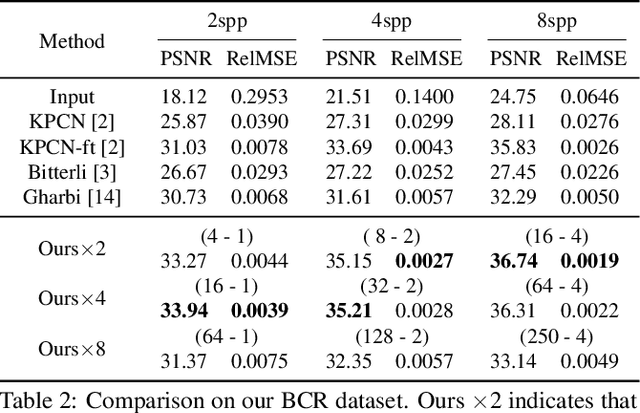
Monte Carlo rendering algorithms are widely used to produce photorealistic computer graphics images. However, these algorithms need to sample a substantial amount of rays per pixel to enable proper global illumination and thus require an immense amount of computation. In this paper, we present a hybrid rendering method to speed up Monte Carlo rendering algorithms. Our method first generates two versions of a rendering: one at a low resolution with a high sample rate (LRHS) and the other at a high resolution with a low sample rate (HRLS). We then develop a deep convolutional neural network to fuse these two renderings into a high-quality image as if it were rendered at a high resolution with a high sample rate. Specifically, we formulate this fusion task as a super resolution problem that generates a high resolution rendering from a low resolution input (LRHS), assisted with the HRLS rendering. The HRLS rendering provides critical high frequency details which are difficult to recover from the LRHS for any super resolution methods. Our experiments show that our hybrid rendering algorithm is significantly faster than the state-of-the-art Monte Carlo denoising methods while rendering high-quality images when tested on both our own BCR dataset and the Gharbi dataset. \url{https://github.com/hqqxyy/msspl}
One-Shot Medical Landmark Detection
Mar 08, 2021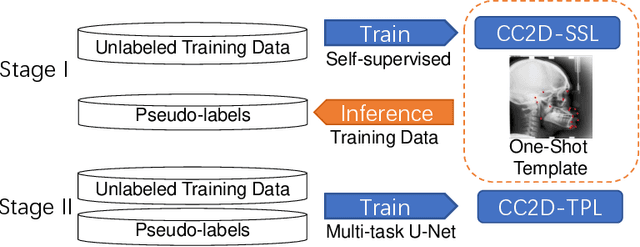
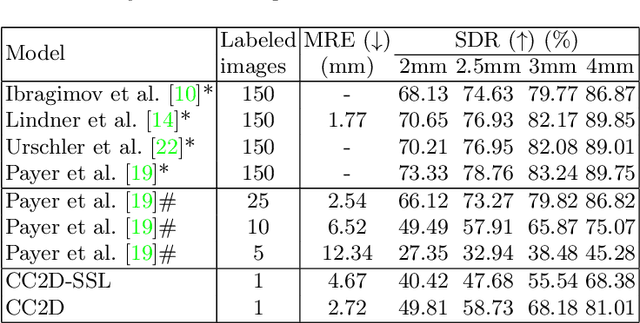
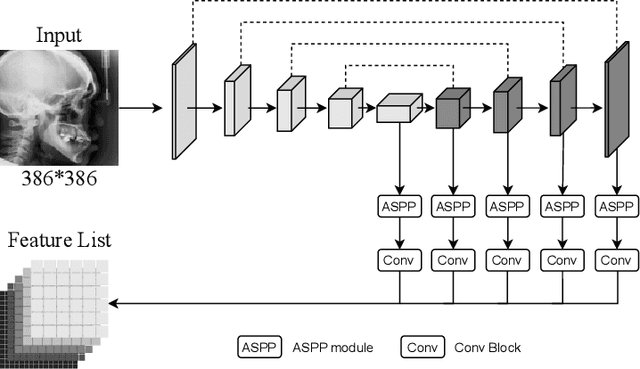
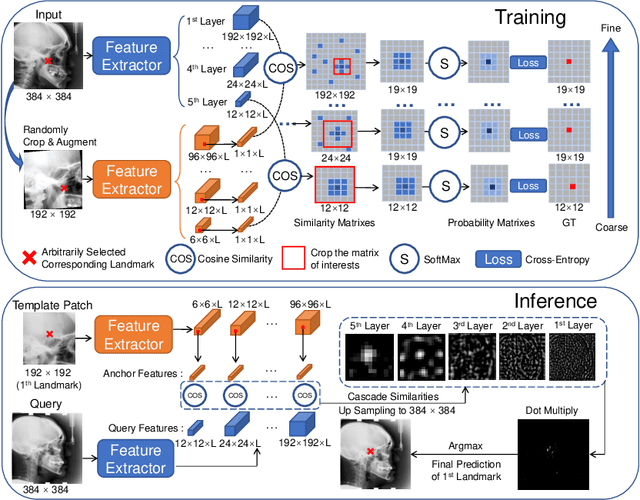
The success of deep learning methods relies on the availability of a large number of datasets with annotations; however, curating such datasets is burdensome, especially for medical images. To relieve such a burden for a landmark detection task, we explore the feasibility of using only a single annotated image and propose a novel framework named Cascade Comparing to Detect (CC2D) for one-shot landmark detection. CC2D consists of two stages: 1) Self-supervised learning (CC2D-SSL) and 2) Training with pseudo-labels (CC2D-TPL). CC2D-SSL captures the consistent anatomical information in a coarse-to-fine fashion by comparing the cascade feature representations and generates predictions on the training set. CC2D-TPL further improves the performance by training a new landmark detector with those predictions. The effectiveness of CC2D is evaluated on a widely-used public dataset of cephalometric landmark detection, which achieves a competitive detection accuracy of 81.01\% within 4.0mm, comparable to the state-of-the-art fully-supervised methods using a lot more than one training image.
Free-Form Image Inpainting with Gated Convolution
Jun 10, 2018

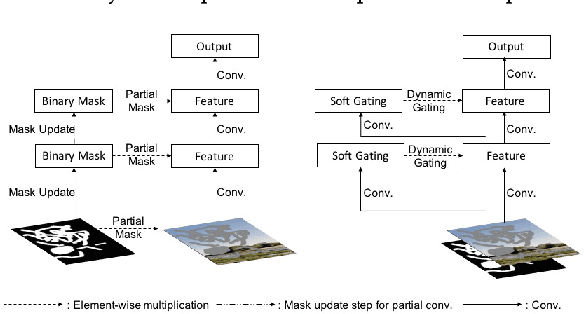

We present a novel deep learning based image inpainting system to complete images with free-form masks and inputs. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shapes, global and local GANs designed for a single rectangular mask are not suitable. To this end, we also present a novel GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminators on dense image patches. It is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. We show that our system helps users quickly remove distracting objects, modify image layouts, clear watermarks, edit faces and interactively create novel objects in images. Furthermore, visualization of learned feature representations reveals the effectiveness of gated convolution and provides an interpretation of how the proposed neural network fills in missing regions. More high-resolution results and video materials are available at http://jiahuiyu.com/deepfill2
Identifying centres of interest in paintings using alignment and edge detection: Case studies on works by Luc Tuymans
Jan 04, 2021

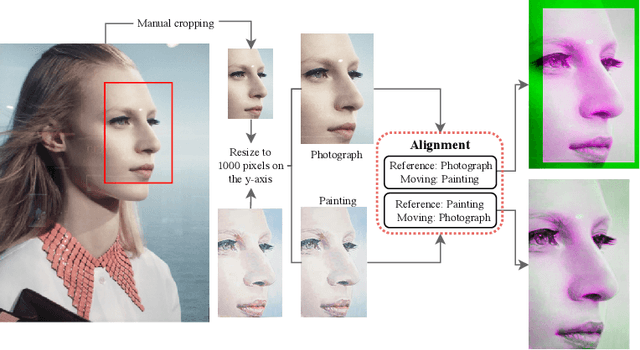
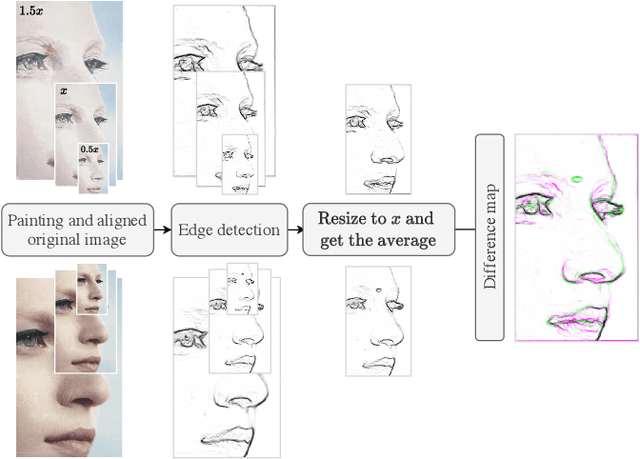
What is the creative process through which an artist goes from an original image to a painting? Can we examine this process using techniques from computer vision and pattern recognition? Here we set the first preliminary steps to algorithmically deconstruct some of the transformations that an artist applies to an original image in order to establish centres of interest, which are focal areas of a painting that carry meaning. We introduce a comparative methodology that first cuts out the minimal segment from the original image on which the painting is based, then aligns the painting with this source, investigates micro-differences to identify centres of interest and attempts to understand their role. In this paper we focus exclusively on micro-differences with respect to edges. We believe that research into where and how artists create centres of interest in paintings is valuable for curators, art historians, viewers, and art educators, and might even help artists to understand and refine their own artistic method.
Rectified Meta-Learning from Noisy Labels for Robust Image-based Plant Disease Diagnosis
Mar 18, 2020
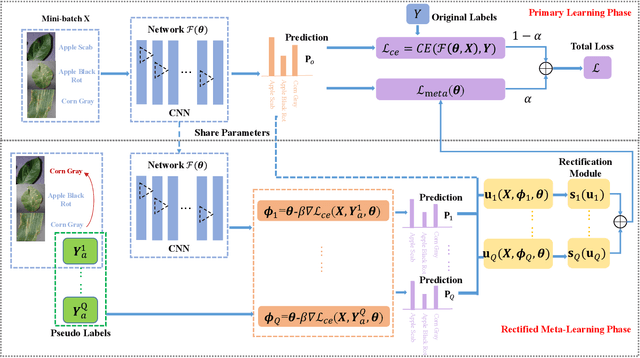
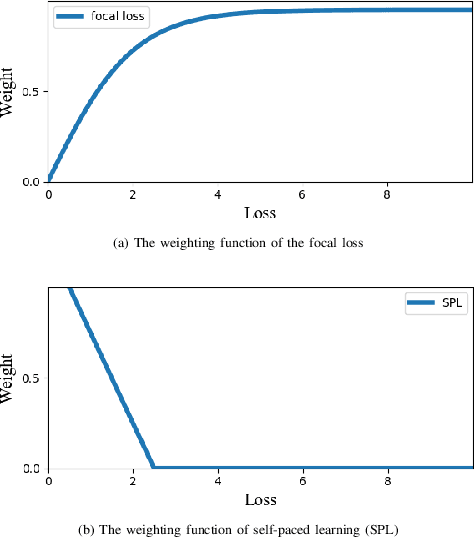

Plant diseases serve as one of main threats to food security and crop production. It is thus valuable to exploit recent advances of artificial intelligence to assist plant disease diagnosis. One popular approach is to transform this problem as a leaf image classification task, which can be then addressed by the powerful convolutional neural networks (CNNs). However, the performance of CNN-based classification approach depends on a large amount of high-quality manually labeled training data, which are inevitably introduced noise on labels in practice, leading to model overfitting and performance degradation. To overcome this problem, we propose a novel framework that incorporates rectified meta-learning module into common CNN paradigm to train a noise-robust deep network without using extra supervision information. The proposed method enjoys the following merits: i) A rectified meta-learning is designed to pay more attention to unbiased samples, leading to accelerated convergence and improved classification accuracy. ii) Our method is free on assumption of label noise distribution, which works well on various kinds of noise. iii) Our method serves as a plug-and-play module, which can be embedded into any deep models optimized by gradient descent based method. Extensive experiments are conducted to demonstrate the superior performance of our algorithm over the state-of-the-arts.
DeepCorrect: Correcting DNN models against Image Distortions
Jan 09, 2018



In recent years, the widespread use of deep neural networks (DNNs) has facilitated great improvements in performance for computer vision tasks like image classification and object recognition. In most realistic computer vision applications, an input image undergoes some form of image distortion such as blur and additive noise during image acquisition or transmission. Deep networks trained on pristine images perform poorly when tested on such distortions. In this paper, we evaluate the effect of image distortions like Gaussian blur and additive noise on the activations of pre-trained convolutional filters. We propose a metric to identify the most noise susceptible convolutional filters and rank them in order of the highest gain in classification accuracy upon correction. In our proposed approach called DeepCorrect, we apply small stacks of convolutional layers with residual connections, at the output of these ranked filters and train them to correct the worst distortion affected filter activations, whilst leaving the rest of the pre-trained filter outputs in the network unchanged. Performance results show that applying DeepCorrect models for common vision tasks like image classification (CIFAR-100, ImageNet), object recognition (Caltech-101, Caltech-256) and scene classification (SUN-397), significantly improves the robustness of DNNs against distorted images and outperforms the alternative approach of network fine-tuning.