 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeo-NI: Geometry-aware Neural Interpolation for Light Field Rendering
Jun 20, 2022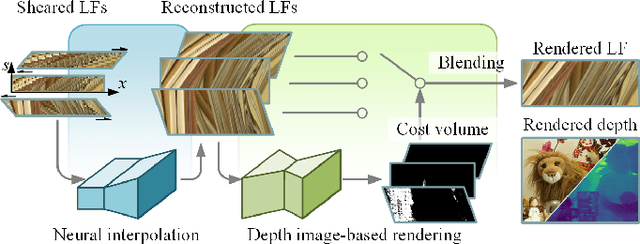
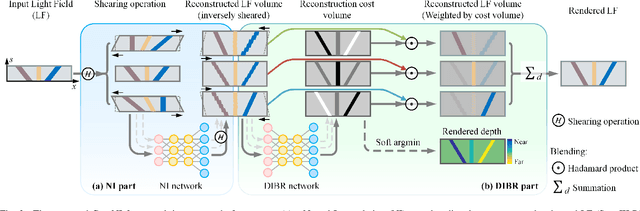


In this paper, we present a Geometry-aware Neural Interpolation (Geo-NI) framework for light field rendering. Previous learning-based approaches either rely on the capability of neural networks to perform direct interpolation, which we dubbed Neural Interpolation (NI), or explore scene geometry for novel view synthesis, also known as Depth Image-Based Rendering (DIBR). Instead, we incorporate the ideas behind these two kinds of approaches by launching the NI with a novel DIBR pipeline. Specifically, the proposed Geo-NI first performs NI using input light field sheared by a set of depth hypotheses. Then the DIBR is implemented by assigning the sheared light fields with a novel reconstruction cost volume according to the reconstruction quality under different depth hypotheses. The reconstruction cost is interpreted as a blending weight to render the final output light field by blending the reconstructed light fields along the dimension of depth hypothesis. By combining the superiorities of NI and DIBR, the proposed Geo-NI is able to render views with large disparity with the help of scene geometry while also reconstruct non-Lambertian effect when depth is prone to be ambiguous. Extensive experiments on various datasets demonstrate the superior performance of the proposed geometry-aware light field rendering framework.
ProbNVS: Fast Novel View Synthesis with Learned Probability-Guided Sampling
Apr 07, 2022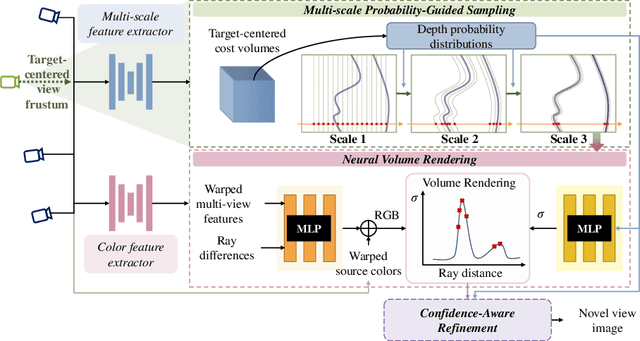
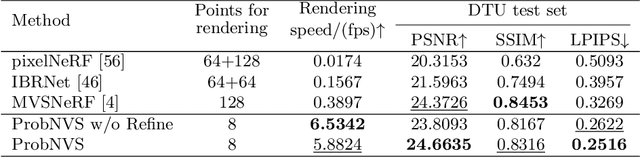
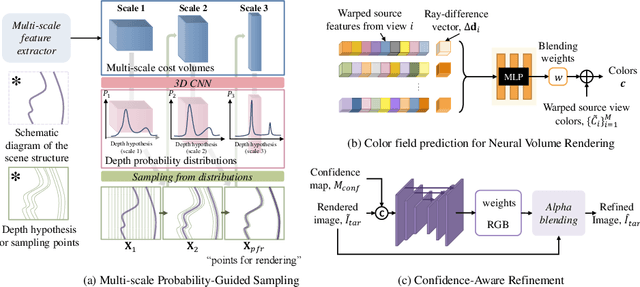
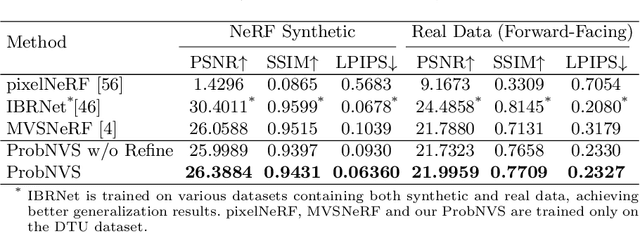
Existing state-of-the-art novel view synthesis methods rely on either fairly accurate 3D geometry estimation or sampling of the entire space for neural volumetric rendering, which limit the overall efficiency. In order to improve the rendering efficiency by reducing sampling points without sacrificing rendering quality, we propose to build a novel view synthesis framework based on learned MVS priors that enables general, fast and photo-realistic view synthesis simultaneously. Specifically, fewer but important points are sampled under the guidance of depth probability distributions extracted from the learned MVS architecture. Based on the learned probability-guided sampling, a neural volume rendering module is elaborately devised to fully aggregate source view information as well as the learned scene structures to synthesize photorealistic target view images. Finally, the rendering results in uncertain, occluded and unreferenced regions can be further improved by incorporating a confidence-aware refinement module. Experiments show that our method achieves 15 to 40 times faster rendering compared to state-of-the-art baselines, with strong generalization capacity and comparable high-quality novel view synthesis performance.
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
Jun 13, 2021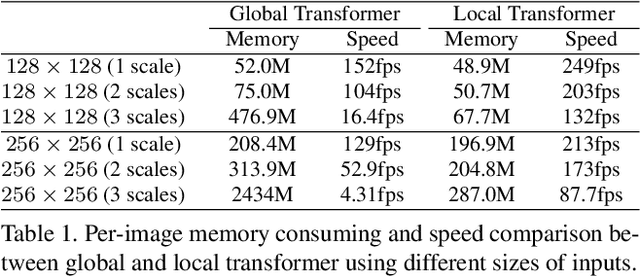
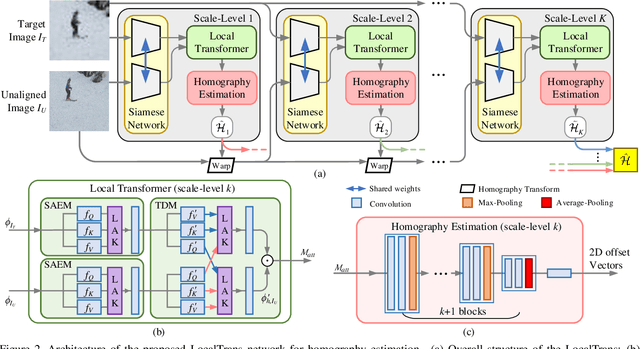
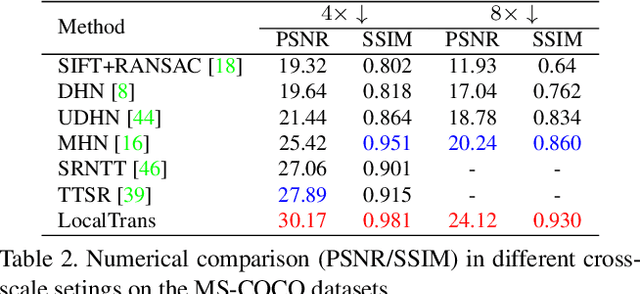
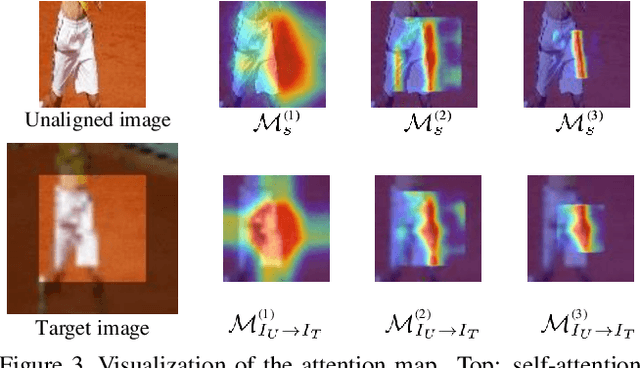
Cross-resolution image alignment is a key problem in multiscale gigapixel photography, which requires to estimate homography matrix using images with large resolution gap. Existing deep homography methods concatenate the input images or features, neglecting the explicit formulation of correspondences between them, which leads to degraded accuracy in cross-resolution challenges. In this paper, we consider the cross-resolution homography estimation as a multimodal problem, and propose a local transformer network embedded within a multiscale structure to explicitly learn correspondences between the multimodal inputs, namely, input images with different resolutions. The proposed local transformer adopts a local attention map specifically for each position in the feature. By combining the local transformer with the multiscale structure, the network is able to capture long-short range correspondences efficiently and accurately. Experiments on both the MS-COCO dataset and the real-captured cross-resolution dataset show that the proposed network outperforms existing state-of-the-art feature-based and deep-learning-based homography estimation methods, and is able to accurately align images under $10\times$ resolution gap.
Cross-MPI: Cross-scale Stereo for Image Super-Resolution using Multiplane Images
Nov 30, 2020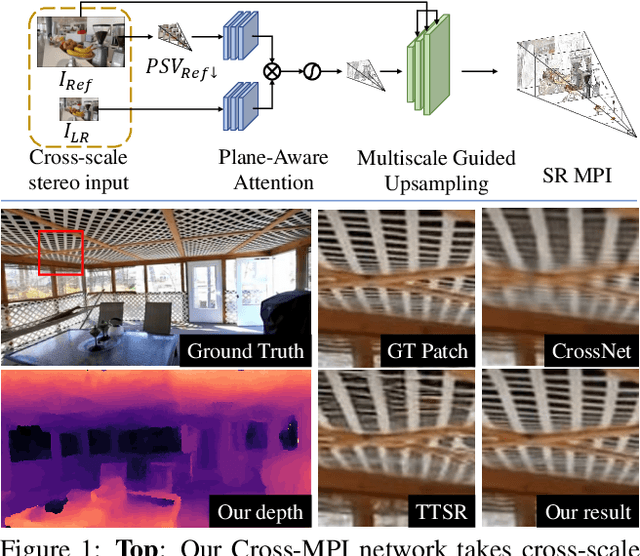
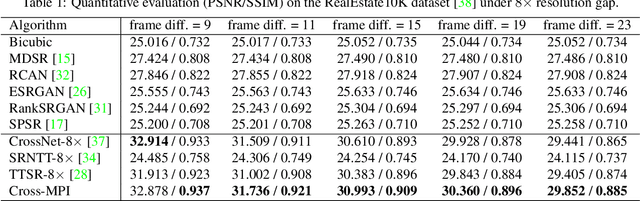
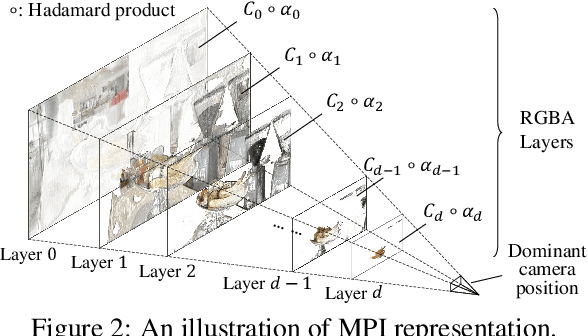

The combination of various cameras is enriching the way of computational photography, among which referencebased super-resolution (RefSR) plays a critical role in multiscale imaging systems. However, existing RefSR approaches fail to accomplish high-fidelity super-resolution under a large resolution gap, e.g., 8x upscaling, due to the less consideration of underneath scene structure. In this paper, we aim to solve the RefSR problem (in actual multiscale camera systems) inspired by multiplane images (MPI) representation. Specifically, we propose Cross-MPI, an end-to-end RefSR network composed of a novel planeaware attention-based MPI mechanism, a multiscale guided upsampling module as well as a super-resolution (SR) synthesis and fusion module. Instead of using a direct and exhaustive matching between the cross-scale stereo, the proposed plane-aware attention mechanism fully utilizes the concealed scene structure for efficient attention-based correspondence searching. Further combined with a gentle coarse-to-fine guided upsampling strategy, the proposed Cross-MPI is able to achieve a robust and accurate detail transmission. Experimental results on both digital synthesized and optical zoomed cross-scale data show the Cross- MPI framework can achieve superior performance against the existing RefSR methods, and is a real fit for actual multiscale camera systems even with large scale differences.