 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometry-aware data augmentation for monocular 3D object detection
Apr 12, 2021
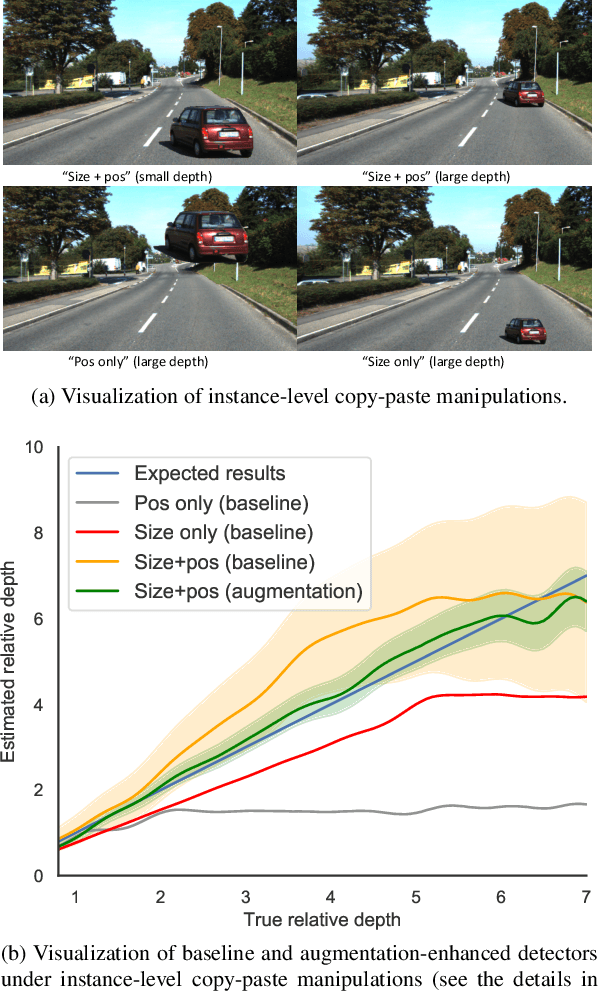
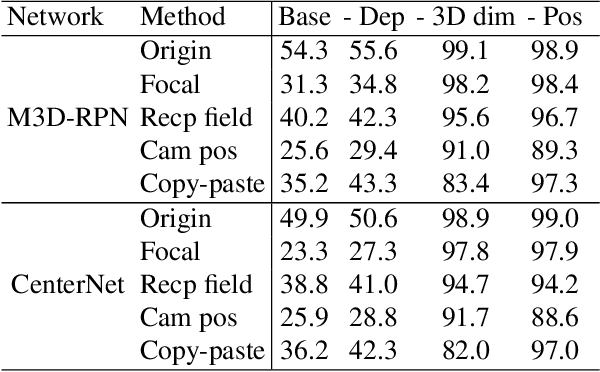

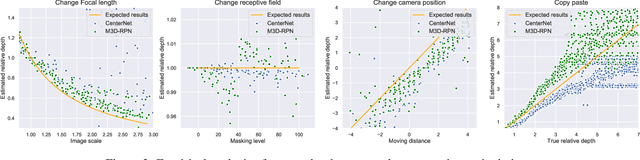
This paper focuses on monocular 3D object detection, one of the essential modules in autonomous driving systems. A key challenge is that the depth recovery problem is ill-posed in monocular data. In this work, we first conduct a thorough analysis to reveal how existing methods fail to robustly estimate depth when different geometry shifts occur. In particular, through a series of image-based and instance-based manipulations for current detectors, we illustrate existing detectors are vulnerable in capturing the consistent relationships between depth and both object apparent sizes and positions. To alleviate this issue and improve the robustness of detectors, we convert the aforementioned manipulations into four corresponding 3D-aware data augmentation techniques. At the image-level, we randomly manipulate the camera system, including its focal length, receptive field and location, to generate new training images with geometric shifts. At the instance level, we crop the foreground objects and randomly paste them to other scenes to generate new training instances. All the proposed augmentation techniques share the virtue that geometry relationships in objects are preserved while their geometry is manipulated. In light of the proposed data augmentation methods, not only the instability of depth recovery is effectively alleviated, but also the final 3D detection performance is significantly improved. This leads to superior improvements on the KITTI and nuScenes monocular 3D detection benchmarks with state-of-the-art results.
Incremental False Negative Detection for Contrastive Learning
Jun 07, 2021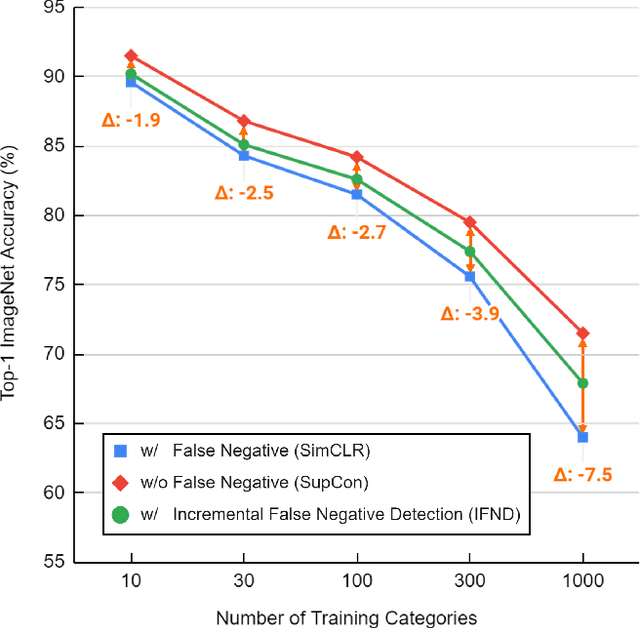
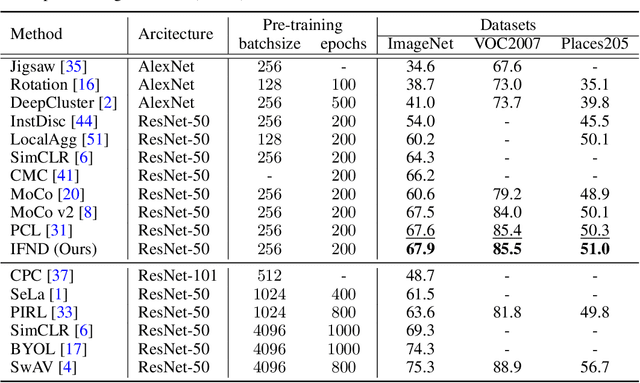
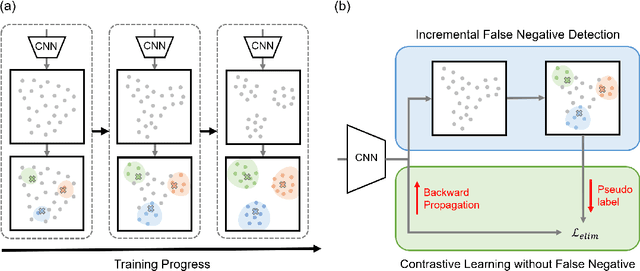
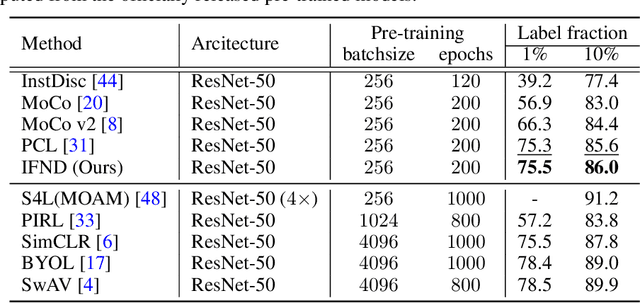
Self-supervised learning has recently shown great potential in vision tasks via contrastive learning, which aims to discriminate each image, or instance, in the dataset. However, such instance-level learning ignores the semantic relationship between instances and repels the anchor equally from the semantically similar samples, termed as false negatives. In this work, we first empirically highlight that the unfavorable effect from false negatives is more significant for the datasets containing images with more semantic concepts. To address the issue, we introduce a novel incremental false negative detection for self-supervised contrastive learning. Following the training process, when the encoder is gradually better-trained and the embedding space becomes more semantically structural, our method incrementally detects more reliable false negatives. Subsequently, during contrastive learning, we discuss two strategies to explicitly remove the detected false negatives. Extensive experiments show that our proposed method outperforms other self-supervised contrastive learning frameworks on multiple benchmarks within a limited compute.
Techniques for Symbol Grounding with SATNet
Jun 16, 2021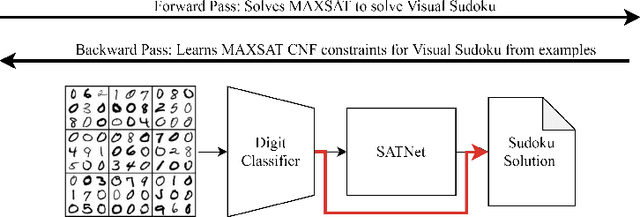

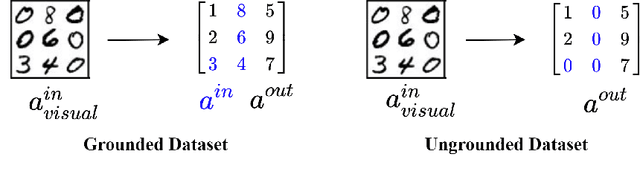

Many experts argue that the future of artificial intelligence is limited by the field's ability to integrate symbolic logical reasoning into deep learning architectures. The recently proposed differentiable MAXSAT solver, SATNet, was a breakthrough in its capacity to integrate with a traditional neural network and solve visual reasoning problems. For instance, it can learn the rules of Sudoku purely from image examples. Despite its success, SATNet was shown to succumb to a key challenge in neurosymbolic systems known as the Symbol Grounding Problem: the inability to map visual inputs to symbolic variables without explicit supervision ("label leakage"). In this work, we present a self-supervised pre-training pipeline that enables SATNet to overcome this limitation, thus broadening the class of problems that SATNet architectures can solve to include datasets where no intermediary labels are available at all. We demonstrate that our method allows SATNet to attain full accuracy even with a harder problem setup that prevents any label leakage. We additionally introduce a proofreading method that further improves the performance of SATNet architectures, beating the state-of-the-art on Visual Sudoku.
A Survey of Crowdsourcing in Medical Image Analysis
Feb 25, 2019

Rapid advances in image processing capabilities have been seen across many domains, fostered by the application of machine learning algorithms to "big-data". However, within the realm of medical image analysis, advances have been curtailed, in part, due to the limited availability of large-scale, well-annotated datasets. One of the main reasons for this is the high cost often associated with producing large amounts of high-quality meta-data. Recently, there has been growing interest in the application of crowdsourcing for this purpose; a technique that has proven effective for creating large-scale datasets across a range of disciplines, from computer vision to astrophysics. Despite the growing popularity of this approach, there has not yet been a comprehensive literature review to provide guidance to researchers considering using crowdsourcing methodologies in their own medical imaging analysis. In this survey, we review studies applying crowdsourcing to the analysis of medical images, published prior to July 2018. We identify common approaches, challenges and considerations, providing guidance of utility to researchers adopting this approach. Finally, we discuss future opportunities for development within this emerging domain.
Tracing Back Music Emotion Predictions to Sound Sources and Intuitive Perceptual Qualities
Jun 16, 2021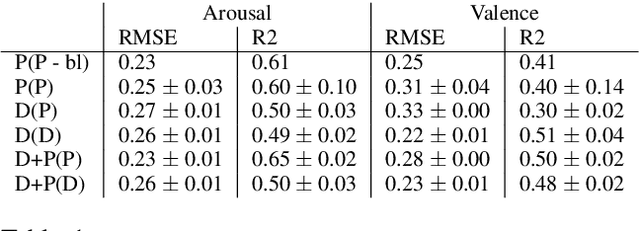
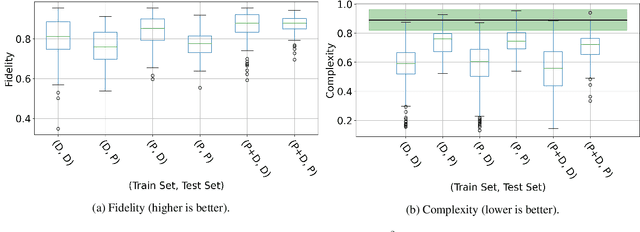
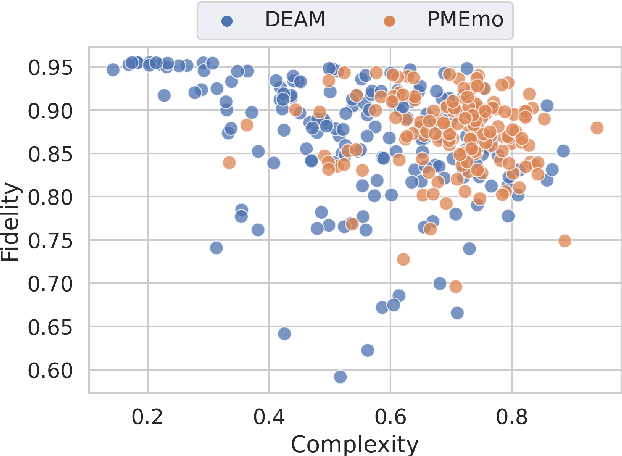
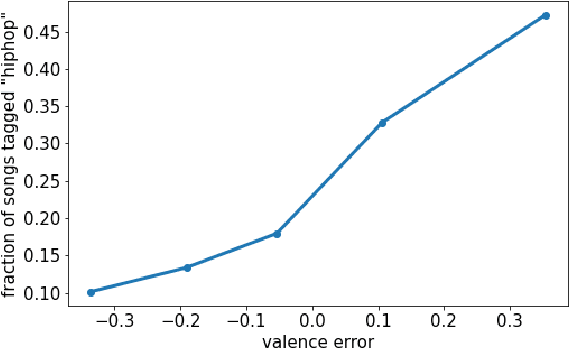
Music emotion recognition is an important task in MIR (Music Information Retrieval) research. Owing to factors like the subjective nature of the task and the variation of emotional cues between musical genres, there are still significant challenges in developing reliable and generalizable models. One important step towards better models would be to understand what a model is actually learning from the data and how the prediction for a particular input is made. In previous work, we have shown how to derive explanations of model predictions in terms of spectrogram image segments that connect to the high-level emotion prediction via a layer of easily interpretable perceptual features. However, that scheme lacks intuitive musical comprehensibility at the spectrogram level. In the present work, we bridge this gap by merging audioLIME -- a source-separation based explainer -- with mid-level perceptual features, thus forming an intuitive connection chain between the input audio and the output emotion predictions. We demonstrate the usefulness of this method by applying it to debug a biased emotion prediction model.
Towards Spectral Estimation from a Single RGB Image in the Wild
Dec 03, 2018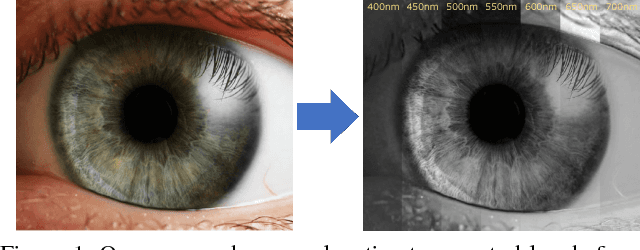
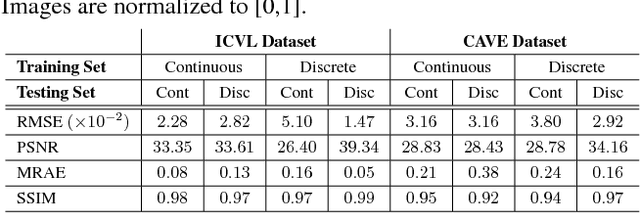
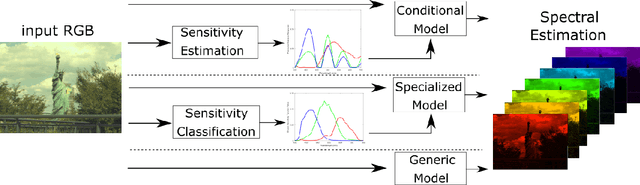

In contrast to the current literature, we address the problem of estimating the spectrum from a single common trichromatic RGB image obtained under unconstrained settings (e.g. unknown camera parameters, unknown scene radiance, unknown scene contents). For this we use a reference spectrum as provided by a hyperspectral image camera, and propose efficient deep learning solutions for sensitivity function estimation and spectral reconstruction from a single RGB image. We further expand the concept of spectral reconstruction such that to work for RGB images taken in the wild and propose a solution based on a convolutional network conditioned on the estimated sensitivity function. Besides the proposed solutions, we study also generic and sensitivity specialized models and discuss their limitations. We achieve state-of-the-art competitive results on the standard example-based spectral reconstruction benchmarks: ICVL, CAVE, NUS and NTIRE. Moreover, our experiments show that, for the first time, accurate spectral estimation from a single RGB image in the wild is within our reach.
Evidential Turing Processes
Jun 02, 2021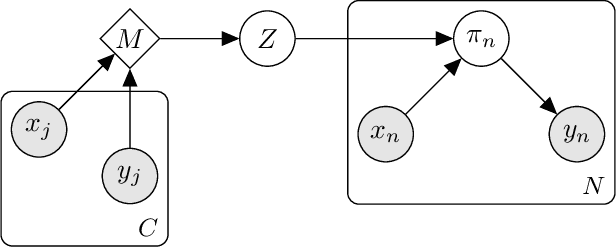

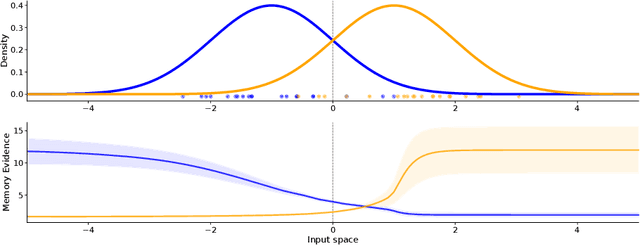
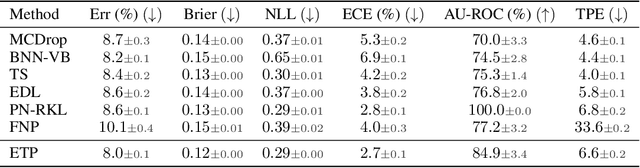
A probabilistic classifier with reliable predictive uncertainties i) fits successfully to the target domain data, ii) provides calibrated class probabilities in difficult regions of the target domain (e.g. class overlap), and iii) accurately identifies queries coming out of the target domain and reject them. We introduce an original combination of evidential deep learning, neural processes, and neural Turing machines capable of providing all three essential properties mentioned above for total uncertainty quantification. We observe our method on three image classification benchmarks and two neural net architectures to consistently give competitive or superior scores with respect to multiple uncertainty quantification metrics against state-of-the-art methods explicitly tailored to one or a few of them. Our unified solution delivers an implementation-friendly and computationally efficient recipe for safety clearance and provides intellectual economy to an investigation of algorithmic roots of epistemic awareness in deep neural nets.
RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Jun 25, 2021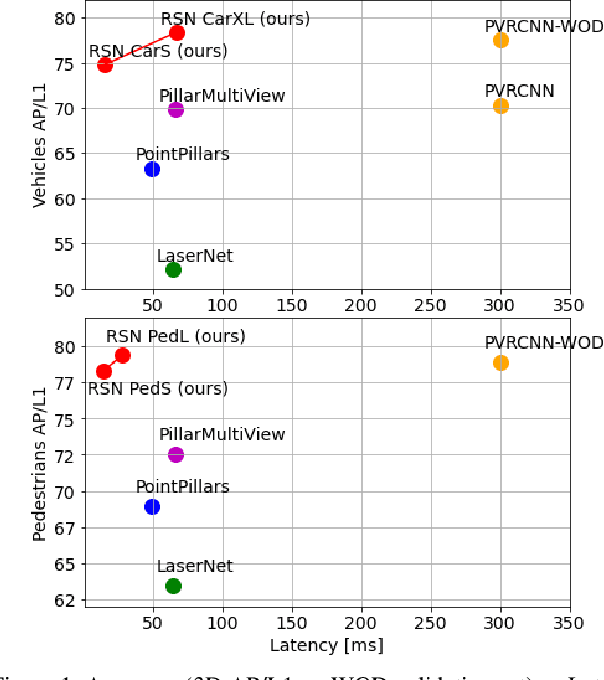
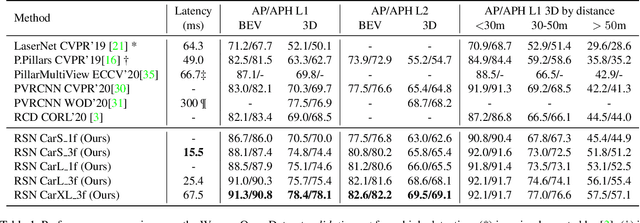
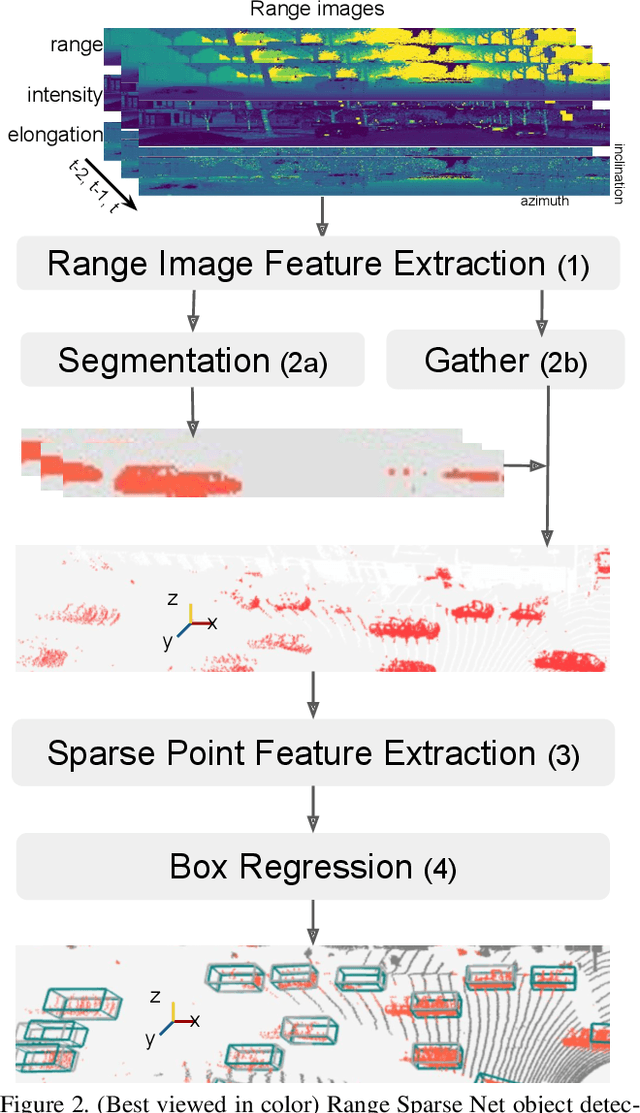
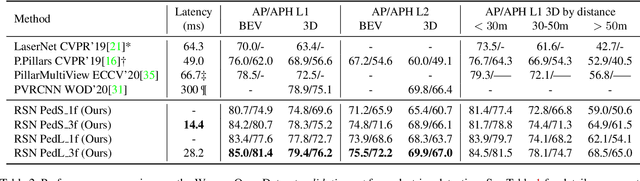
The detection of 3D objects from LiDAR data is a critical component in most autonomous driving systems. Safe, high speed driving needs larger detection ranges, which are enabled by new LiDARs. These larger detection ranges require more efficient and accurate detection models. Towards this goal, we propose Range Sparse Net (RSN), a simple, efficient, and accurate 3D object detector in order to tackle real time 3D object detection in this extended detection regime. RSN predicts foreground points from range images and applies sparse convolutions on the selected foreground points to detect objects. The lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. Combining features from the range image further enhance detection accuracy. RSN runs at more than 60 frames per second on a 150m x 150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors. As of 11/2020, RSN is ranked first in the WOD leaderboard based on the APH/LEVEL 1 metrics for LiDAR-based pedestrian and vehicle detection, while being several times faster than alternatives.
Scalable Perception-Action-Communication Loops with Convolutional and Graph Neural Networks
Jun 24, 2021In this paper, we present a perception-action-communication loop design using Vision-based Graph Aggregation and Inference (VGAI). This multi-agent decentralized learning-to-control framework maps raw visual observations to agent actions, aided by local communication among neighboring agents. Our framework is implemented by a cascade of a convolutional and a graph neural network (CNN / GNN), addressing agent-level visual perception and feature learning, as well as swarm-level communication, local information aggregation and agent action inference, respectively. By jointly training the CNN and GNN, image features and communication messages are learned in conjunction to better address the specific task. We use imitation learning to train the VGAI controller in an offline phase, relying on a centralized expert controller. This results in a learned VGAI controller that can be deployed in a distributed manner for online execution. Additionally, the controller exhibits good scaling properties, with training in smaller teams and application in larger teams. Through a multi-agent flocking application, we demonstrate that VGAI yields performance comparable to or better than other decentralized controllers, using only the visual input modality and without accessing precise location or motion state information.
Image Moment Models for Extended Object Tracking
Apr 09, 2018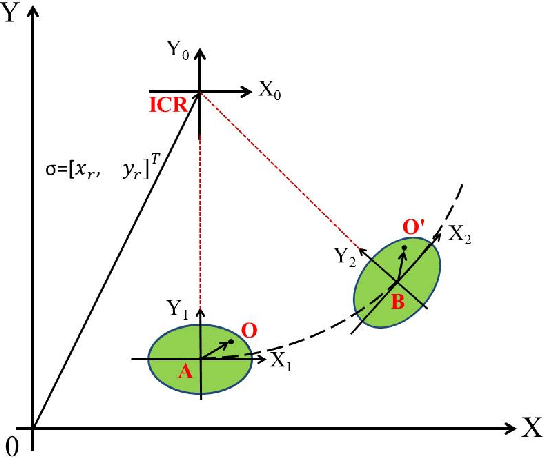
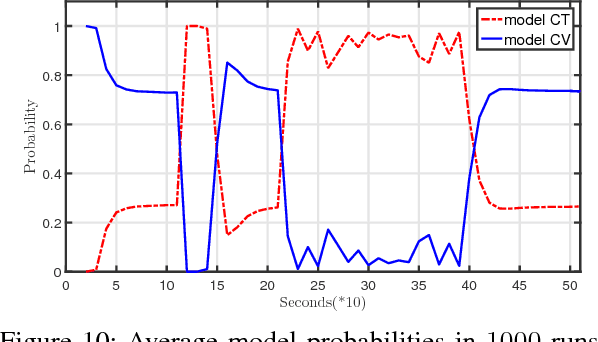

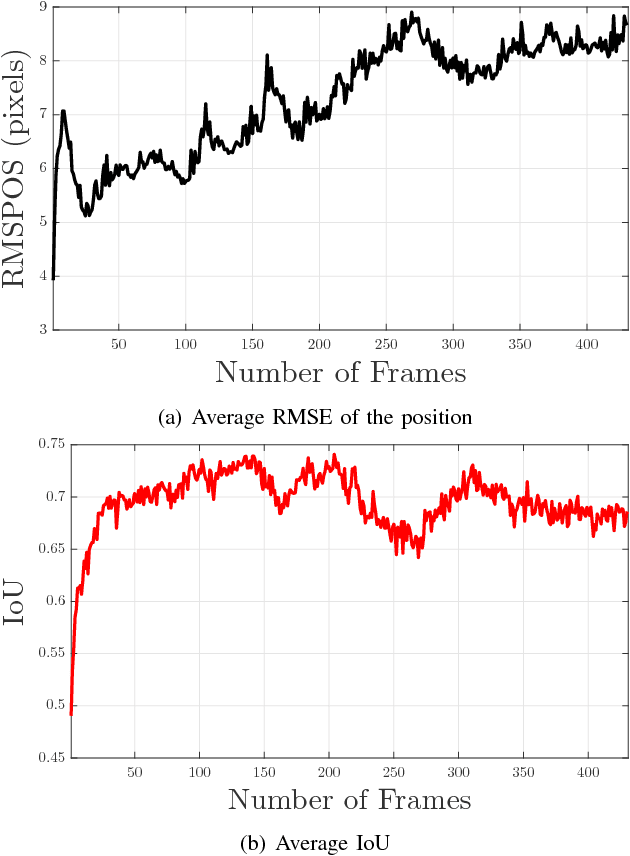
In this paper, a novel image moments based model for shape estimation and tracking of an object moving with a complex trajectory is presented. The camera is assumed to be stationary looking at a moving object. Point features inside the object are sampled as measurements. An ellipsoidal approximation of the shape is assumed as a primitive shape. The shape of an ellipse is estimated using a combination of image moments. Dynamic model of image moments when the object moves under the constant velocity or coordinated turn motion model is derived as a function for the shape estimation of the object. An Unscented Kalman Filter-Interacting Multiple Model (UKF-IMM) filter algorithm is applied to estimate the shape of the object (approximated as an ellipse) and track its position and velocity. A likelihood function based on average log-likelihood is derived for the IMM filter. Simulation results of the proposed UKF-IMM algorithm with the image moments based models are presented that show the estimations of the shape of the object moving in complex trajectories. Comparison results, using intersection over union (IOU), and position and velocity root mean square errors (RMSE) as metrics, with a benchmark algorithm from literature are presented. Results on real image data captured from the quadcopter are also presented.