 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\$OneMillion-Bench: How Far are Language Agents from Human Experts?
Mar 09, 2026As language models (LMs) evolve from chat assistants to long-horizon agents capable of multi-step reasoning and tool use, existing benchmarks remain largely confined to structured or exam-style tasks that fall short of real-world professional demands. To this end, we introduce \$OneMillion-Bench \$OneMillion-Bench, a benchmark of 400 expert-curated tasks spanning Law, Finance, Industry, Healthcare, and Natural Science, built to evaluate agents across economically consequential scenarios. Unlike prior work, the benchmark requires retrieving authoritative sources, resolving conflicting evidence, applying domain-specific rules, and making constraint decisions, where correctness depends as much on the reasoning process as the final answer. We adopt a rubric-based evaluation protocol scoring factual accuracy, logical coherence, practical feasibility, and professional compliance, focused on expert-level problems to ensure meaningful differentiation across agents. Together, \$OneMillion-Bench provides a unified testbed for assessing agentic reliability, professional depth, and practical readiness in domain-intensive scenarios.
Primitive Representation Learning for Scene Text Recognition
May 10, 2021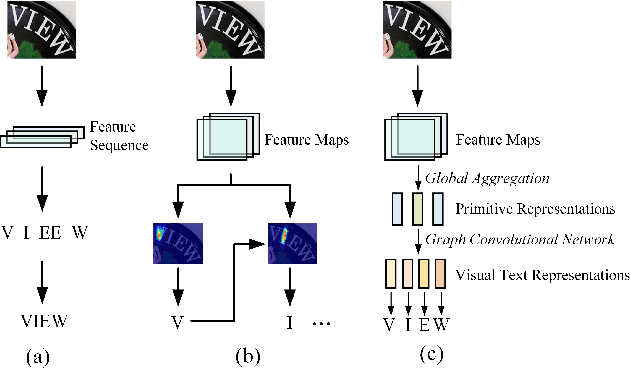
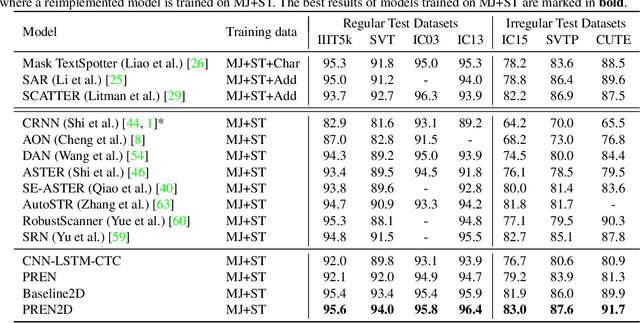
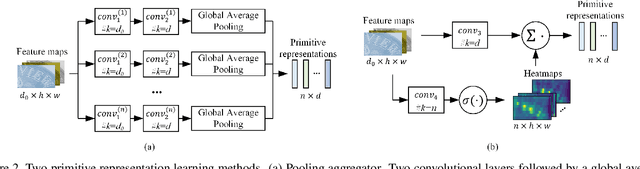

Scene text recognition is a challenging task due to diverse variations of text instances in natural scene images. Conventional methods based on CNN-RNN-CTC or encoder-decoder with attention mechanism may not fully investigate stable and efficient feature representations for multi-oriented scene texts. In this paper, we propose a primitive representation learning method that aims to exploit intrinsic representations of scene text images. We model elements in feature maps as the nodes of an undirected graph. A pooling aggregator and a weighted aggregator are proposed to learn primitive representations, which are transformed into high-level visual text representations by graph convolutional networks. A Primitive REpresentation learning Network (PREN) is constructed to use the visual text representations for parallel decoding. Furthermore, by integrating visual text representations into an encoder-decoder model with the 2D attention mechanism, we propose a framework called PREN2D to alleviate the misalignment problem in attention-based methods. Experimental results on both English and Chinese scene text recognition tasks demonstrate that PREN keeps a balance between accuracy and efficiency, while PREN2D achieves state-of-the-art performance.
Shape Estimation for Elongated Deformable Object using B-spline Chained Multiple Random Matrices Model
Apr 10, 2020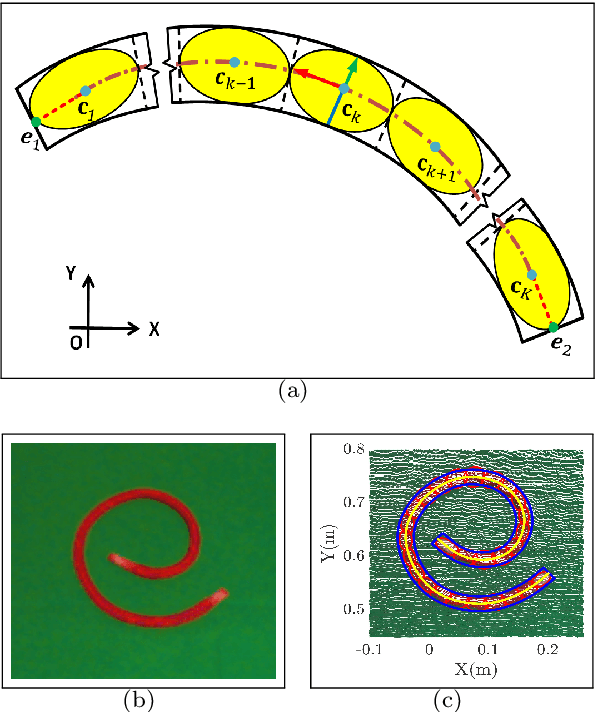
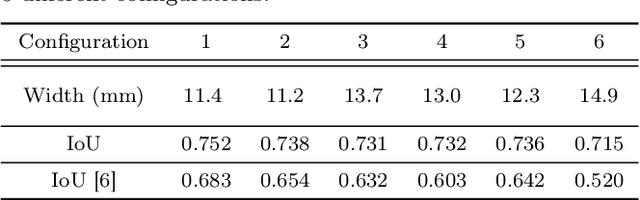
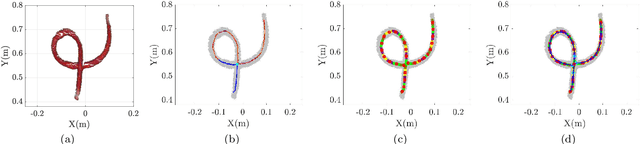
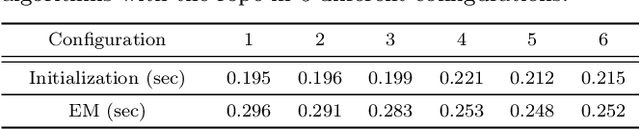
In this paper, a B-spline chained multiple random matrices representation is proposed to model geometric characteristics of an elongated deformable object. The hyper degrees of freedom structure of the elongated deformable object make its shape estimation challenging. Based on the likelihood function of the proposed model, an expectation-maximization (EM) method is derived to estimate the shape of the elongated deformable object. A split and merge method based on the Euclidean minimum spanning tree (EMST) is proposed to provide initialization for the EM algorithm. The proposed algorithm is evaluated for the shape estimation of the elongated deformable objects in scenarios, such as the static rope with various configurations (including configurations with intersection), the continuous manipulation of a rope and a plastic tube, and the assembly of two plastic tubes. The execution time is computed and the accuracy of the shape estimation results is evaluated based on the comparisons between the estimated width values and its ground-truth, and the intersection over union (IoU) metric.
Image Moment Models for Extended Object Tracking
Apr 09, 2018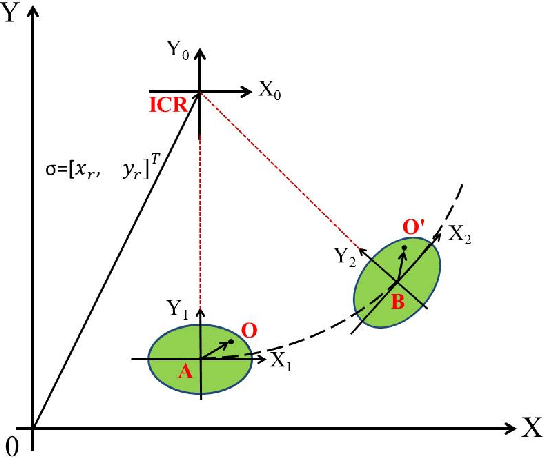
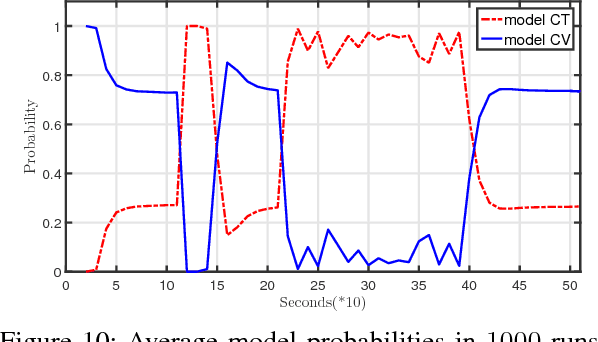

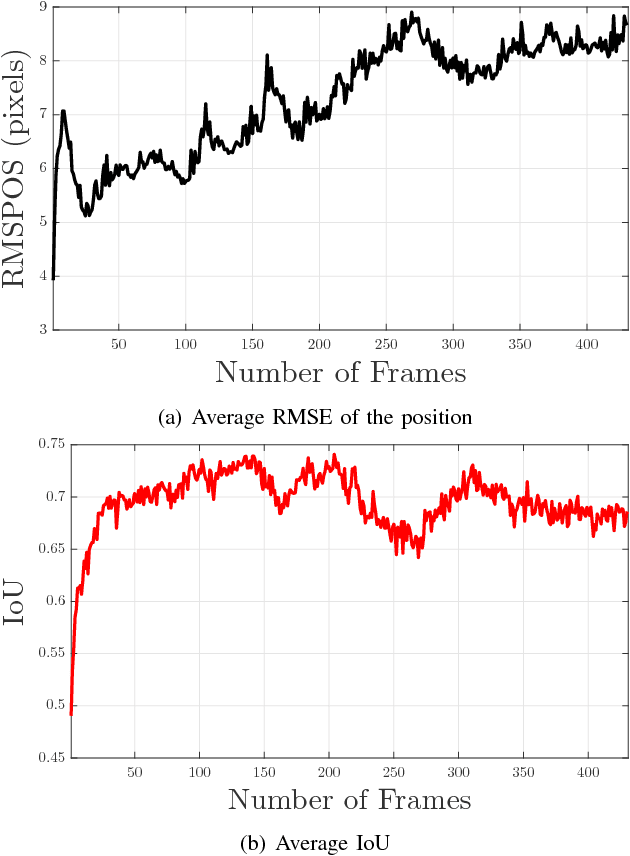
In this paper, a novel image moments based model for shape estimation and tracking of an object moving with a complex trajectory is presented. The camera is assumed to be stationary looking at a moving object. Point features inside the object are sampled as measurements. An ellipsoidal approximation of the shape is assumed as a primitive shape. The shape of an ellipse is estimated using a combination of image moments. Dynamic model of image moments when the object moves under the constant velocity or coordinated turn motion model is derived as a function for the shape estimation of the object. An Unscented Kalman Filter-Interacting Multiple Model (UKF-IMM) filter algorithm is applied to estimate the shape of the object (approximated as an ellipse) and track its position and velocity. A likelihood function based on average log-likelihood is derived for the IMM filter. Simulation results of the proposed UKF-IMM algorithm with the image moments based models are presented that show the estimations of the shape of the object moving in complex trajectories. Comparison results, using intersection over union (IOU), and position and velocity root mean square errors (RMSE) as metrics, with a benchmark algorithm from literature are presented. Results on real image data captured from the quadcopter are also presented.
Visual Tracking Using Sparse Coding and Earth Mover's Distance
Apr 06, 2018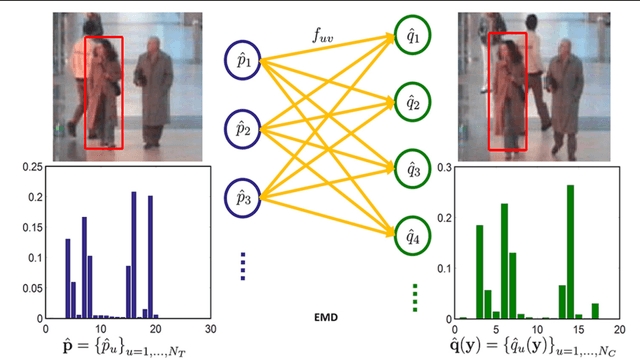
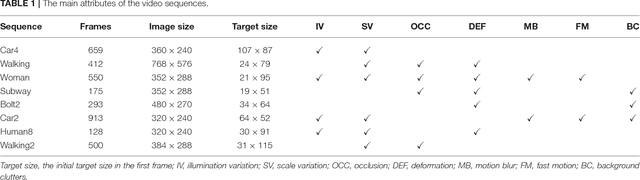
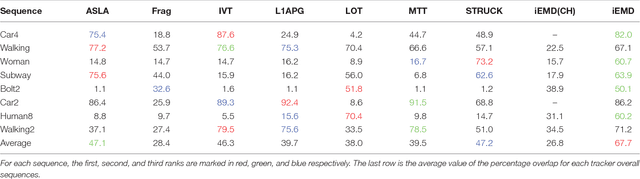
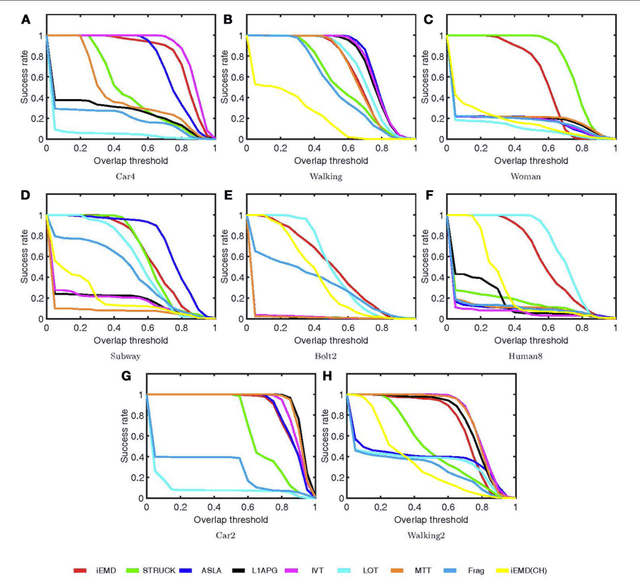
An efficient iterative Earth Mover's Distance (iEMD) algorithm for visual tracking is proposed in this paper. The Earth Mover's Distance (EMD) is used as the similarity measure to search for the optimal template candidates in feature-spatial space in a video sequence. The computation of the EMD is formulated as the transportation problem from linear programming. The efficiency of the EMD optimization problem limits its use for visual tracking. To alleviate this problem, a transportation-simplex method is used for EMD optimization and a monotonically convergent iterative optimization algorithm is developed. The local sparse representation is used as the appearance models for the iEMD tracker. The maximum-alignment-pooling method is used for constructing a sparse coding histogram which reduces the computational complexity of the EMD optimization. The template update algorithm based on the EMD is also presented. The iEMD tracking algorithm assumes small inter-frame movement in order to guarantee convergence. When the camera is mounted on a moving robot, e.g., a flying quadcopter, the camera could experience a sudden and rapid motion leading to large inter-frame movements. To ensure that the tracking algorithm converges, a gyro-aided extension of the iEMD tracker is presented, where synchronized gyroscope information is utilized to compensate for the rotation of the camera. The iEMD algorithm's performance is evaluated using eight publicly available datasets. The performance of the iEMD algorithm is compared with seven state-of-the-art tracking algorithms based on relative percentage overlap. The robustness of this algorithm for large inter-frame displacements is also illustrated.