 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDExter: Learning and Controlling Performance Expression with Diffusion Models
Jun 21, 2024



In the pursuit of developing expressive music performance models using artificial intelligence, this paper introduces DExter, a new approach leveraging diffusion probabilistic models to render Western classical piano performances. In this approach, performance parameters are represented in a continuous expression space and a diffusion model is trained to predict these continuous parameters while being conditioned on the musical score. Furthermore, DExter also enables the generation of interpretations (expressive variations of a performance) guided by perceptually meaningful features by conditioning jointly on score and perceptual feature representations. Consequently, we find that our model is useful for learning expressive performance, generating perceptually steered performances, and transferring performance styles. We assess the model through quantitative and qualitative analyses, focusing on specific performance metrics regarding dimensions like asynchrony and articulation, as well as through listening tests comparing generated performances with different human interpretations. Results show that DExter is able to capture the time-varying correlation of the expressive parameters, and compares well to existing rendering models in subjectively evaluated ratings. The perceptual-feature-conditioned generation and transferring capabilities of DExter are verified by a proxy model predicting perceptual characteristics of differently steered performances.
Expressivity-aware Music Performance Retrieval using Mid-level Perceptual Features and Emotion Word Embeddings
Jan 26, 2024



This paper explores a specific sub-task of cross-modal music retrieval. We consider the delicate task of retrieving a performance or rendition of a musical piece based on a description of its style, expressive character, or emotion from a set of different performances of the same piece. We observe that a general purpose cross-modal system trained to learn a common text-audio embedding space does not yield optimal results for this task. By introducing two changes -- one each to the text encoder and the audio encoder -- we demonstrate improved performance on a dataset of piano performances and associated free-text descriptions. On the text side, we use emotion-enriched word embeddings (EWE) and on the audio side, we extract mid-level perceptual features instead of generic audio embeddings. Our results highlight the effectiveness of mid-level perceptual features learnt from music and emotion enriched word embeddings learnt from emotion-labelled text in capturing musical expression in a cross-modal setting. Additionally, our interpretable mid-level features provide a route for introducing explainability in the retrieval and downstream recommendation processes.
Are we describing the same sound? An analysis of word embedding spaces of expressive piano performance
Dec 31, 2023Semantic embeddings play a crucial role in natural language-based information retrieval. Embedding models represent words and contexts as vectors whose spatial configuration is derived from the distribution of words in large text corpora. While such representations are generally very powerful, they might fail to account for fine-grained domain-specific nuances. In this article, we investigate this uncertainty for the domain of characterizations of expressive piano performance. Using a music research dataset of free text performance characterizations and a follow-up study sorting the annotations into clusters, we derive a ground truth for a domain-specific semantic similarity structure. We test five embedding models and their similarity structure for correspondence with the ground truth. We further assess the effects of contextualizing prompts, hubness reduction, cross-modal similarity, and k-means clustering. The quality of embedding models shows great variability with respect to this task; more general models perform better than domain-adapted ones and the best model configurations reach human-level agreement.
Decoding and Visualising Intended Emotion in an Expressive Piano Performance
Mar 03, 2023Expert musicians can mould a musical piece to convey specific emotions that they intend to communicate. In this paper, we place a mid-level features based music emotion model in this performer-to-listener communication scenario, and demonstrate via a small visualisation music emotion decoding in real time. We also extend the existing set of mid-level features using analogues of perceptual speed and perceived dynamics.
On Perceived Emotion in Expressive Piano Performance: Further Experimental Evidence for the Relevance of Mid-level Perceptual Features
Jul 28, 2021



Despite recent advances in audio content-based music emotion recognition, a question that remains to be explored is whether an algorithm can reliably discern emotional or expressive qualities between different performances of the same piece. In the present work, we analyze several sets of features on their effectiveness in predicting arousal and valence of six different performances (by six famous pianists) of Bach's Well-Tempered Clavier Book 1. These features include low-level acoustic features, score-based features, features extracted using a pre-trained emotion model, and Mid-level perceptual features. We compare their predictive power by evaluating them on several experiments designed to test performance-wise or piece-wise variations of emotion. We find that Mid-level features show significant contribution in performance-wise variation of both arousal and valence -- even better than the pre-trained emotion model. Our findings add to the evidence of Mid-level perceptual features being an important representation of musical attributes for several tasks -- specifically, in this case, for capturing the expressive aspects of music that manifest as perceived emotion of a musical performance.
Tracing Back Music Emotion Predictions to Sound Sources and Intuitive Perceptual Qualities
Jun 16, 2021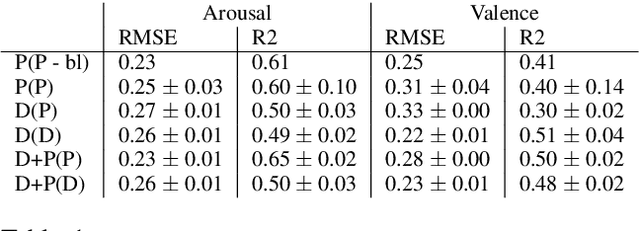
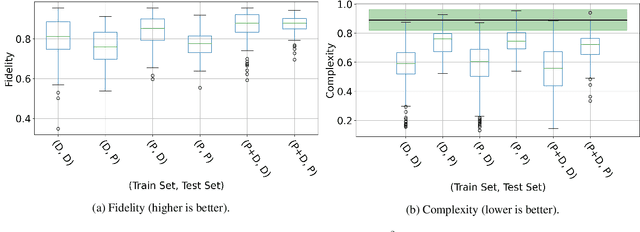
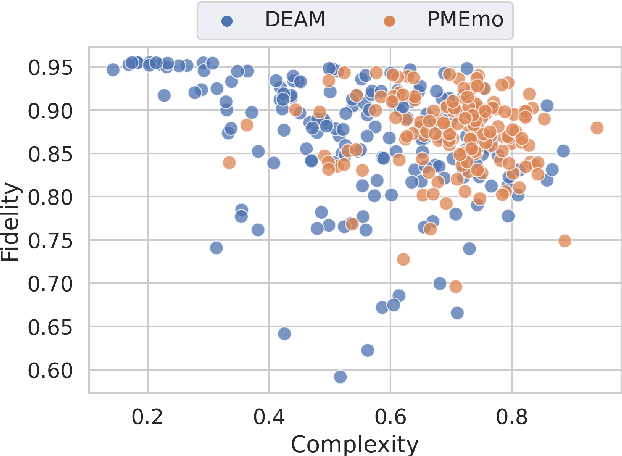
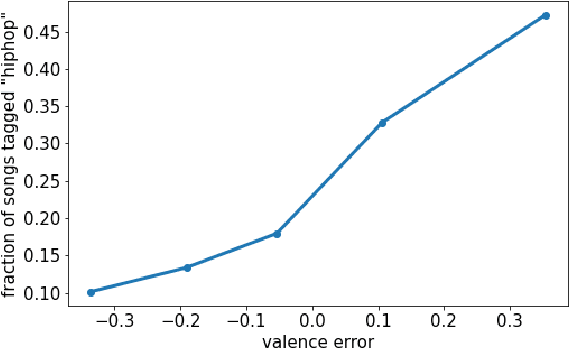
Music emotion recognition is an important task in MIR (Music Information Retrieval) research. Owing to factors like the subjective nature of the task and the variation of emotional cues between musical genres, there are still significant challenges in developing reliable and generalizable models. One important step towards better models would be to understand what a model is actually learning from the data and how the prediction for a particular input is made. In previous work, we have shown how to derive explanations of model predictions in terms of spectrogram image segments that connect to the high-level emotion prediction via a layer of easily interpretable perceptual features. However, that scheme lacks intuitive musical comprehensibility at the spectrogram level. In the present work, we bridge this gap by merging audioLIME -- a source-separation based explainer -- with mid-level perceptual features, thus forming an intuitive connection chain between the input audio and the output emotion predictions. We demonstrate the usefulness of this method by applying it to debug a biased emotion prediction model.
Towards Explaining Expressive Qualities in Piano Recordings: Transfer of Explanatory Features via Acoustic Domain Adaptation
Feb 26, 2021



Emotion and expressivity in music have been topics of considerable interest in the field of music information retrieval. In recent years, mid-level perceptual features have been suggested as means to explain computational predictions of musical emotion. We find that the diversity of musical styles and genres in the available dataset for learning these features is not sufficient for models to generalise well to specialised acoustic domains such as solo piano music. In this work, we show that by utilising unsupervised domain adaptation together with receptive-field regularised deep neural networks, it is possible to significantly improve generalisation to this domain. Additionally, we demonstrate that our domain-adapted models can better predict and explain expressive qualities in classical piano performances, as perceived and described by human listeners.
Receptive-Field Regularized CNNs for Music Classification and Tagging
Jul 27, 2020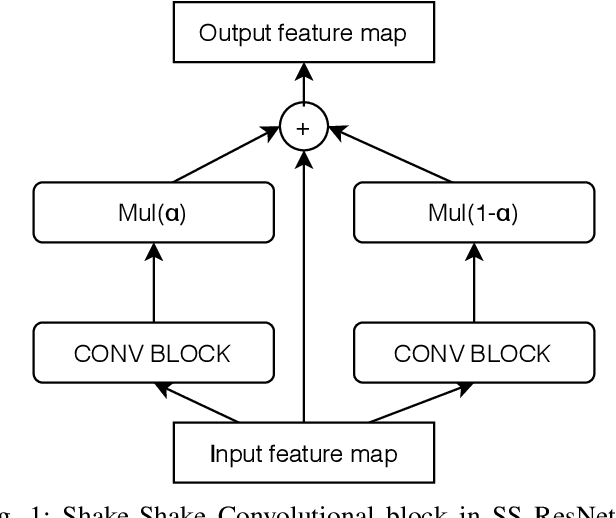
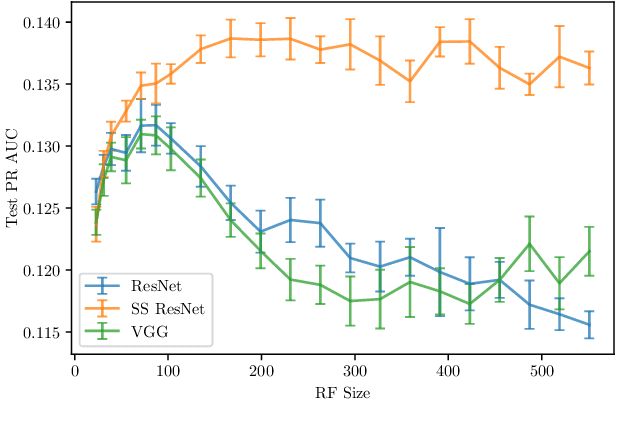
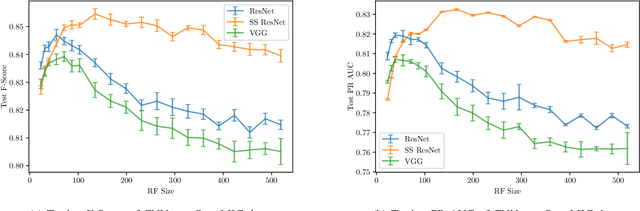
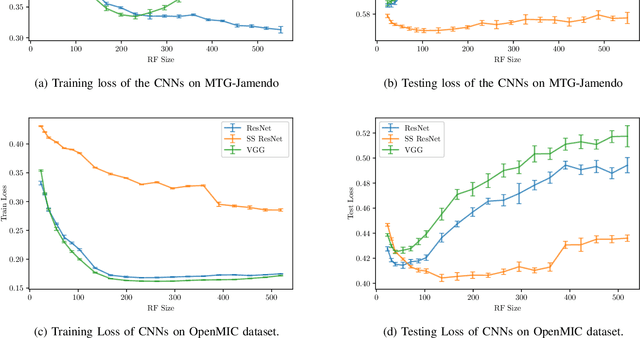
Convolutional Neural Networks (CNNs) have been successfully used in various Music Information Retrieval (MIR) tasks, both as end-to-end models and as feature extractors for more complex systems. However, the MIR field is still dominated by the classical VGG-based CNN architecture variants, often in combination with more complex modules such as attention, and/or techniques such as pre-training on large datasets. Deeper models such as ResNet -- which surpassed VGG by a large margin in other domains -- are rarely used in MIR. One of the main reasons for this, as we will show, is the lack of generalization of deeper CNNs in the music domain. In this paper, we present a principled way to make deep architectures like ResNet competitive for music-related tasks, based on well-designed regularization strategies. In particular, we analyze the recently introduced Receptive-Field Regularization and Shake-Shake, and show that they significantly improve the generalization of deep CNNs on music-related tasks, and that the resulting deep CNNs can outperform current more complex models such as CNNs augmented with pre-training and attention. We demonstrate this on two different MIR tasks and two corresponding datasets, thus offering our deep regularized CNNs as a new baseline for these datasets, which can also be used as a feature-extracting module in future, more complex approaches.
Emotion and Theme Recognition in Music with Frequency-Aware RF-Regularized CNNs
Oct 28, 2019

We present CP-JKU submission to MediaEval 2019; a Receptive Field-(RF)-regularized and Frequency-Aware CNN approach for tagging music with emotion/mood labels. We perform an investigation regarding the impact of the RF of the CNNs on their performance on this dataset. We observe that ResNets with smaller receptive fields -- originally adapted for acoustic scene classification -- also perform well in the emotion tagging task. We improve the performance of such architectures using techniques such as Frequency Awareness and Shake-Shake regularization, which were used in previous work on general acoustic recognition tasks.
Towards Explainable Music Emotion Recognition: The Route via Mid-level Features
Jul 08, 2019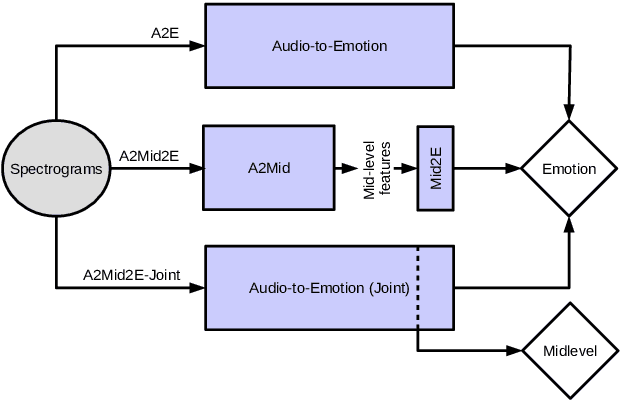

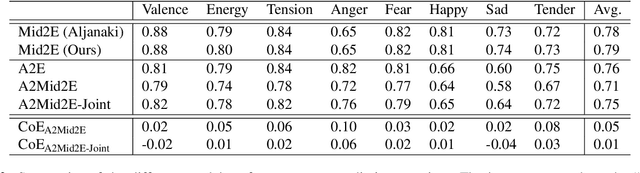
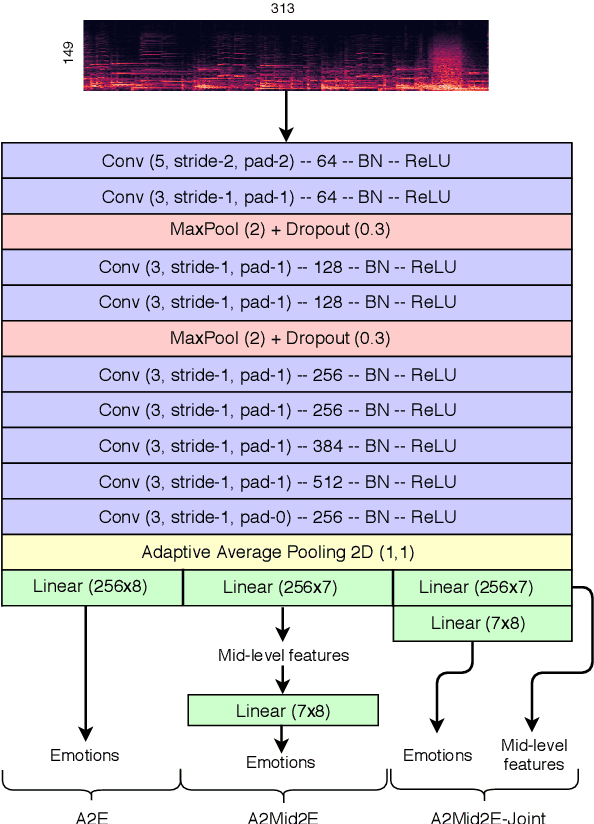
Emotional aspects play an important part in our interaction with music. However, modelling these aspects in MIR systems have been notoriously challenging since emotion is an inherently abstract and subjective experience, thus making it difficult to quantify or predict in the first place, and to make sense of the predictions in the next. In an attempt to create a model that can give a musically meaningful and intuitive explanation for its predictions, we propose a VGG-style deep neural network that learns to predict emotional characteristics of a musical piece together with (and based on) human-interpretable, mid-level perceptual features. We compare this to predicting emotion directly with an identical network that does not take into account the mid-level features and observe that the loss in predictive performance of going through the mid-level features is surprisingly low, on average. The design of our network allows us to visualize the effects of perceptual features on individual emotion predictions, and we argue that the small loss in performance in going through the mid-level features is justified by the gain in explainability of the predictions.