 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Listener Attention: Gaze-Guided Audio-Visual Speech Enhancement Framework
Apr 09, 2026This paper presents a Gaze-Guided Audio-Visual Speech Enhancement (GG-AVSE) framework to address the cocktail party problem. A major challenge in conventional AVSE is identifying the listener's intended speaker in multi-talker environments. GG-AVSE addresses this issue by exploiting gaze direction as a supervisory cue for target-speaker selection. Specifically, we propose the GG-VM module, which combines gaze signals with a YOLO5Face detector to extract the target speaker's facial features and integrates them with the pretrained AVSEMamba model through two strategies: zero-shot merging and partial visual fine-tuning. For evaluation, we introduce the AVSEC2-Gaze dataset. Experimental results show that GG-AVSE achieves substantial performance gains over gaze-free baselines: a 10.08% improvement in PESQ (2.370 to 2.609), a 5.18% improvement in STOI (0.8802 to 0.9258), and a 23.69% improvement in SI-SDR (9.16 to 11.33). These results confirm that gaze provides an effective cue for resolving target-speaker ambiguity and highlight the scalability of GG-AVSE for real-world applications.
LLM-Guided Reinforcement Learning for Audio-Visual Speech Enhancement
Mar 17, 2026In existing Audio-Visual Speech Enhancement (AVSE) methods, objectives such as Scale-Invariant Signal-to-Noise Ratio (SI-SNR) and Mean Squared Error (MSE) are widely used; however, they often correlate poorly with perceptual quality and provide limited interpretability for optimization. This work proposes a reinforcement learning-based AVSE framework with a Large Language Model (LLM)-based interpretable reward model. An audio LLM generates natural language descriptions of enhanced speech, which are converted by a sentiment analysis model into a 1-5 rating score serving as the PPO reward for fine-tuning a pretrained AVSE model. Compared with scalar metrics, LLM-generated feedback is semantically rich and explicitly describes improvements in speech quality. Experiments on the 4th COG-MHEAR AVSE Challenge (AVSEC-4) dataset show that the proposed method outperforms a supervised baseline and a DNSMOS-based RL baseline in PESQ, STOI, neural quality metrics, and subjective listening tests.
FedKLPR: Personalized Federated Learning for Person Re-Identification with Adaptive Pruning
Aug 24, 2025



Person re-identification (Re-ID) is a fundamental task in intelligent surveillance and public safety. Federated learning (FL) offers a privacy-preserving solution by enabling collaborative model training without centralized data collection. However, applying FL to real-world re-ID systems faces two major challenges: statistical heterogeneity across clients due to non-IID data distributions, and substantial communication overhead caused by frequent transmission of large-scale models. To address these issues, we propose FedKLPR, a lightweight and communication-efficient federated learning framework for person re-identification. FedKLPR introduces four key components. First, the KL-Divergence Regularization Loss (KLL) constrains local models by minimizing the divergence from the global feature distribution, effectively mitigating the effects of statistical heterogeneity and improving convergence stability under non-IID conditions. Secondly, KL-Divergence-Prune Weighted Aggregation (KLPWA) integrates pruning ratio and distributional similarity into the aggregation process, thereby improving the robustness of the global model while significantly reducing communication overhead. Furthermore, sparse Activation Skipping (SAS) mitigates the dilution of critical parameters during the aggregation of pruned client models by excluding zero-valued weights from the update process. Finally, Cross-Round Recovery (CRR) introduces a dynamic pruning control mechanism that halts pruning when necessary, enabling deeper compression while maintaining model accuracy. Experimental results on eight benchmark datasets demonstrate that FedKLPR achieves significant communication reduction. Compared with the state-of-the-art, FedKLPR reduces 33\%-38\% communication cost on ResNet-50 and 20\%-40\% communication cost on ResNet-34, while maintaining model accuracy within 1\% degradation.
FGFP: A Fractional Gaussian Filter and Pruning for Deep Neural Networks Compression
Jul 30, 2025



Network compression techniques have become increasingly important in recent years because the loads of Deep Neural Networks (DNNs) are heavy for edge devices in real-world applications. While many methods compress neural network parameters, deploying these models on edge devices remains challenging. To address this, we propose the fractional Gaussian filter and pruning (FGFP) framework, which integrates fractional-order differential calculus and Gaussian function to construct fractional Gaussian filters (FGFs). To reduce the computational complexity of fractional-order differential operations, we introduce Gr\"unwald-Letnikov fractional derivatives to approximate the fractional-order differential equation. The number of parameters for each kernel in FGF is minimized to only seven. Beyond the architecture of Fractional Gaussian Filters, our FGFP framework also incorporates Adaptive Unstructured Pruning (AUP) to achieve higher compression ratios. Experiments on various architectures and benchmarks show that our FGFP framework outperforms recent methods in accuracy and compression. On CIFAR-10, ResNet-20 achieves only a 1.52% drop in accuracy while reducing the model size by 85.2%. On ImageNet2012, ResNet-50 achieves only a 1.63% drop in accuracy while reducing the model size by 69.1%.
Pomo3D: 3D-Aware Portrait Accessorizing and More
Sep 22, 2024We propose Pomo3D, a 3D portrait manipulation framework that allows free accessorizing by decomposing and recomposing portraits and accessories. It enables the avatars to attain out-of-distribution (OOD) appearances of simultaneously wearing multiple accessories. Existing methods still struggle to offer such explicit and fine-grained editing; they either fail to generate additional objects on given portraits or cause alterations to portraits (e.g., identity shift) when generating accessories. This restriction presents a noteworthy obstacle as people typically seek to create charming appearances with diverse and fashionable accessories in the virtual universe. Our approach provides an effective solution to this less-addressed issue. We further introduce the Scribble2Accessories module, enabling Pomo3D to create 3D accessories from user-drawn accessory scribble maps. Moreover, we design a bias-conscious mapper to mitigate biased associations present in real-world datasets. In addition to object-level manipulation above, Pomo3D also offers extensive editing options on portraits, including global or local editing of geometry and texture and avatar stylization, elevating 3D editing of neural portraits to a more comprehensive level.
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Apr 09, 2024



Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
FedFR: Joint Optimization Federated Framework for Generic and Personalized Face Recognition
Dec 23, 2021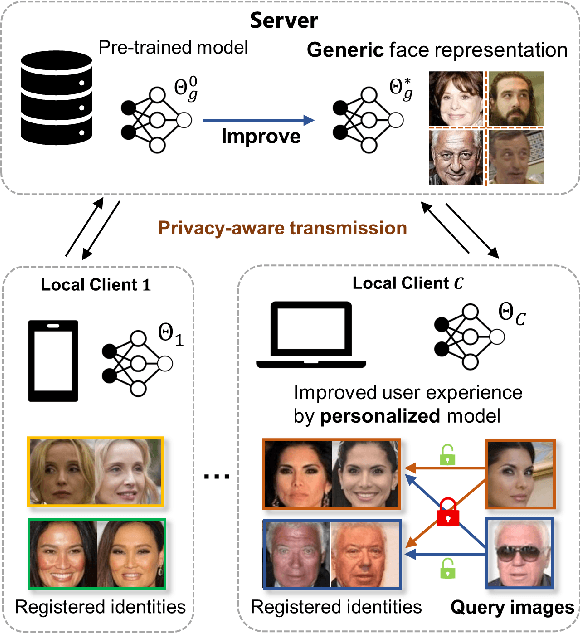
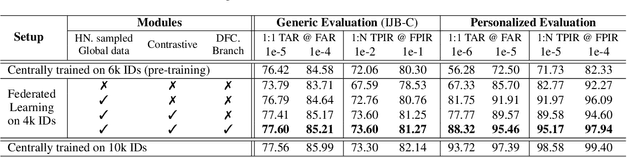
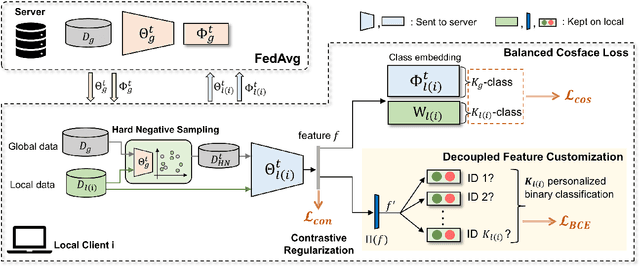
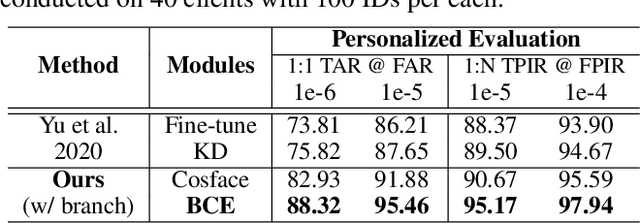
Current state-of-the-art deep learning based face recognition (FR) models require a large number of face identities for central training. However, due to the growing privacy awareness, it is prohibited to access the face images on user devices to continually improve face recognition models. Federated Learning (FL) is a technique to address the privacy issue, which can collaboratively optimize the model without sharing the data between clients. In this work, we propose a FL based framework called FedFR to improve the generic face representation in a privacy-aware manner. Besides, the framework jointly optimizes personalized models for the corresponding clients via the proposed Decoupled Feature Customization module. The client-specific personalized model can serve the need of optimized face recognition experience for registered identities at the local device. To the best of our knowledge, we are the first to explore the personalized face recognition in FL setup. The proposed framework is validated to be superior to previous approaches on several generic and personalized face recognition benchmarks with diverse FL scenarios. The source codes and our proposed personalized FR benchmark under FL setup are available at https://github.com/jackie840129/FedFR.
Learning Discriminative Shrinkage Deep Networks for Image Deconvolution
Nov 27, 2021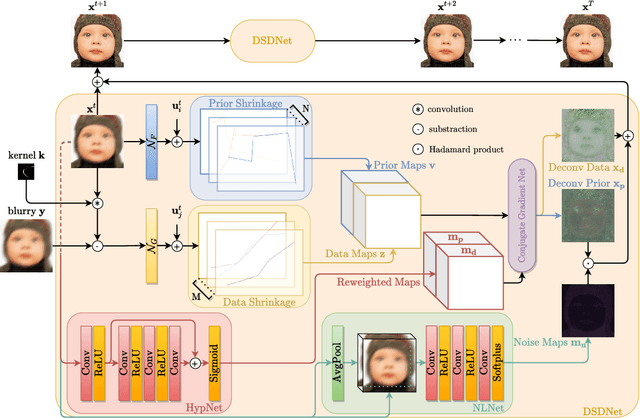
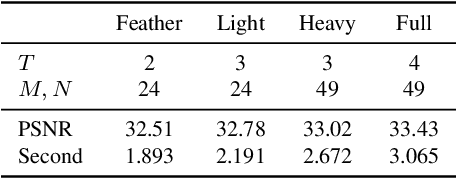
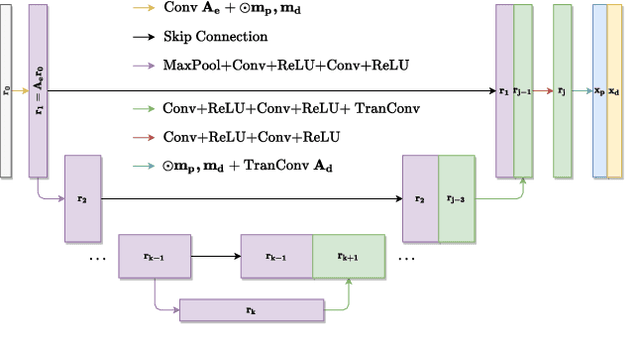
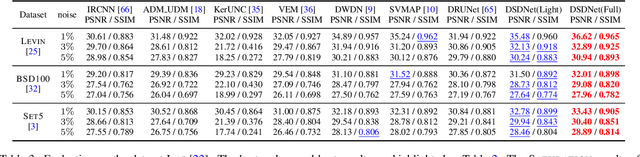
Non-blind deconvolution is an ill-posed problem. Most existing methods usually formulate this problem into a maximum-a-posteriori framework and address it by designing kinds of regularization terms and data terms of the latent clear images. In this paper, we propose an effective non-blind deconvolution approach by learning discriminative shrinkage functions to implicitly model these terms. In contrast to most existing methods that use deep convolutional neural networks (CNNs) or radial basis functions to simply learn the regularization term, we formulate both the data term and regularization term and split the deconvolution model into data-related and regularization-related sub-problems according to the alternating direction method of multipliers. We explore the properties of the Maxout function and develop a deep CNN model with a Maxout layer to learn discriminative shrinkage functions to directly approximate the solutions of these two sub-problems. Moreover, given the fast Fourier transform based image restoration usually leads to ringing artifacts while conjugate gradient-based image restoration is time-consuming, we develop the conjugate gradient network to restore the latent clear images effectively and efficiently. Experimental results show that the proposed method performs favorably against the state-of-the-art ones in terms of efficiency and accuracy.
Interactive Object Segmentation with Dynamic Click Transform
Jun 19, 2021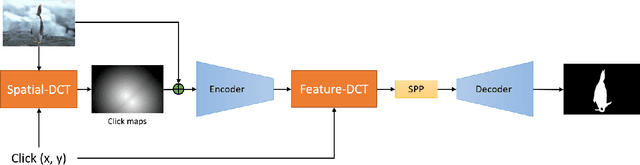


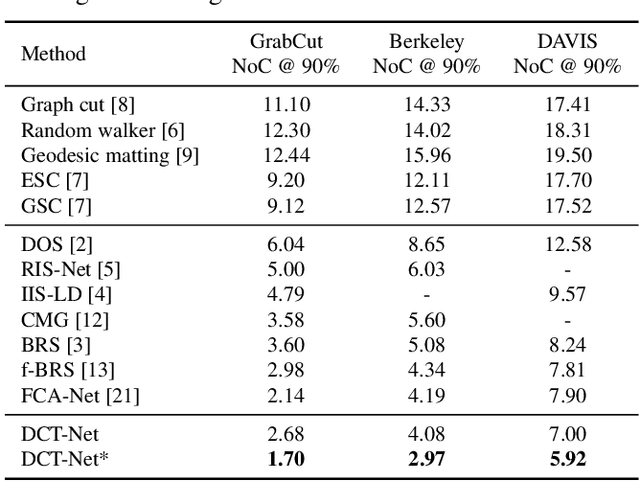
In the interactive segmentation, users initially click on the target object to segment the main body and then provide corrections on mislabeled regions to iteratively refine the segmentation masks. Most existing methods transform these user-provided clicks into interaction maps and concatenate them with image as the input tensor. Typically, the interaction maps are determined by measuring the distance of each pixel to the clicked points, ignoring the relation between clicks and mislabeled regions. We propose a Dynamic Click Transform Network~(DCT-Net), consisting of Spatial-DCT and Feature-DCT, to better represent user interactions. Spatial-DCT transforms each user-provided click with individual diffusion distance according to the target scale, and Feature-DCT normalizes the extracted feature map to a specific distribution predicted from the clicked points. We demonstrate the effectiveness of our proposed method and achieve favorable performance compared to the state-of-the-art on three standard benchmark datasets.
Hard Samples Rectification for Unsupervised Cross-domain Person Re-identification
Jun 14, 2021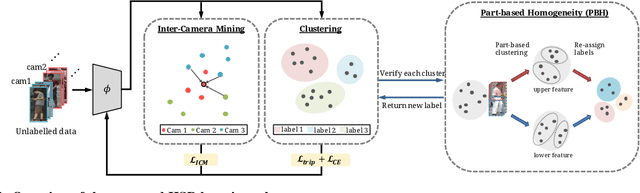
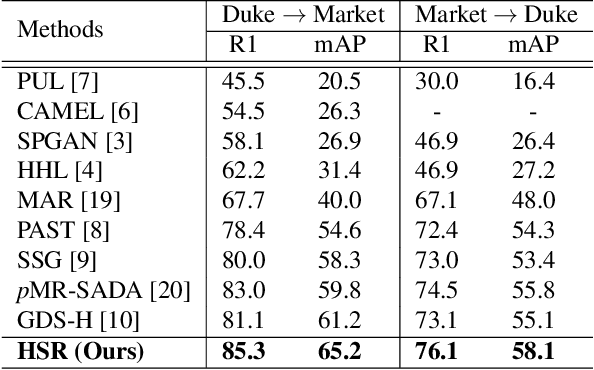
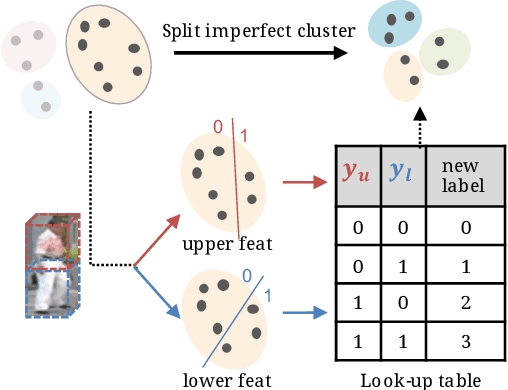
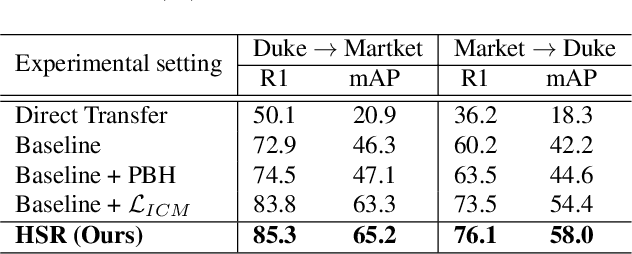
Person re-identification (re-ID) has received great success with the supervised learning methods. However, the task of unsupervised cross-domain re-ID is still challenging. In this paper, we propose a Hard Samples Rectification (HSR) learning scheme which resolves the weakness of original clustering-based methods being vulnerable to the hard positive and negative samples in the target unlabelled dataset. Our HSR contains two parts, an inter-camera mining method that helps recognize a person under different views (hard positive) and a part-based homogeneity technique that makes the model discriminate different persons but with similar appearance (hard negative). By rectifying those two hard cases, the re-ID model can learn effectively and achieve promising results on two large-scale benchmarks.