 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shadow Art Revisited: A Differentiable Rendering Based Approach
Jul 30, 2021

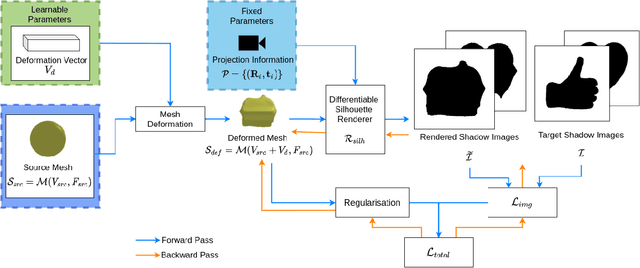
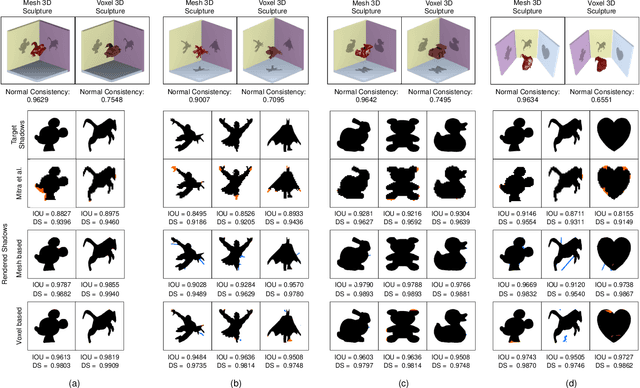
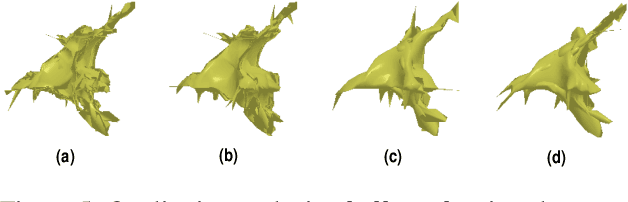
While recent learning based methods have been observed to be superior for several vision-related applications, their potential in generating artistic effects has not been explored much. One such interesting application is Shadow Art - a unique form of sculptural art where 2D shadows cast by a 3D sculpture produce artistic effects. In this work, we revisit shadow art using differentiable rendering based optimization frameworks to obtain the 3D sculpture from a set of shadow (binary) images and their corresponding projection information. Specifically, we discuss shape optimization through voxel as well as mesh-based differentiable renderers. Our choice of using differentiable rendering for generating shadow art sculptures can be attributed to its ability to learn the underlying 3D geometry solely from image data, thus reducing the dependence on 3D ground truth. The qualitative and quantitative results demonstrate the potential of the proposed framework in generating complex 3D sculptures that go beyond those seen in contemporary art pieces using just a set of shadow images as input. Further, we demonstrate the generation of 3D sculptures to cast shadows of faces, animated movie characters, and applicability of the framework to sketch-based 3D reconstruction of underlying shapes.
Image Generation from Layout
Nov 29, 2018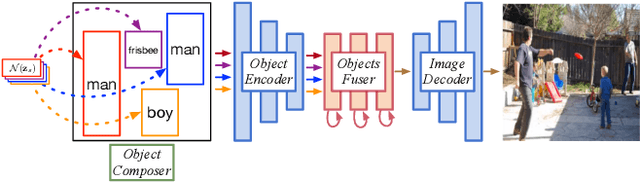
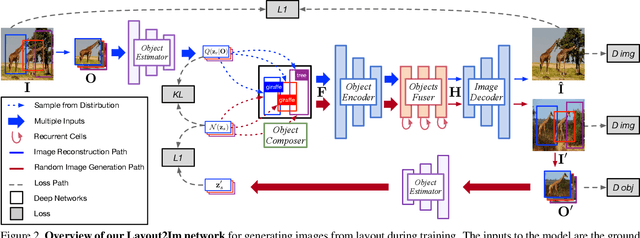

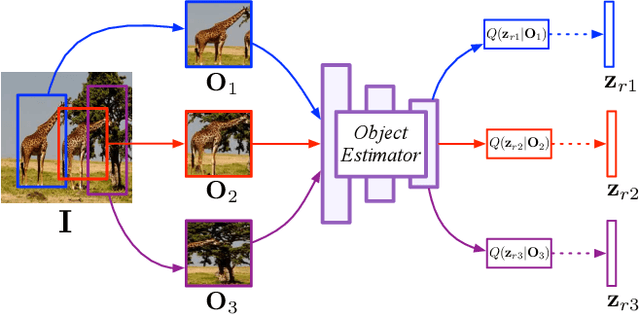
Despite significant recent progress on generative models, controlled generation of images depicting multiple and complex object layouts is still a difficult problem. Among the core challenges are the diversity of appearance a given object may possess and, as a result, exponential set of images consistent with a specified layout. To address these challenges, we propose a novel approach for layout-based image generation; we call it Layout2Im. Given the coarse spatial layout (bounding boxes + object categories), our model can generate a set of realistic images which have the correct objects in the desired locations. The representation of each object is disentangled into a specified/certain part (category) and an unspecified/uncertain part (appearance). The category is encoded using a word embedding and the appearance is distilled into a low-dimensional vector sampled from a normal distribution. Individual object representations are composed together using convolutional LSTM, to obtain an encoding of the complete layout, and then decoded to an image. Several loss terms are introduced to encourage accurate and diverse generation. The proposed Layout2Im model significantly outperforms the previous state of the art, boosting the best reported inception score by 24.66% and 28.57% on the very challenging COCO-Stuff and Visual Genome datasets, respectively. Extensive experiments also demonstrate our method's ability to generate complex and diverse images with multiple objects.
Dialogue Object Search
Jul 22, 2021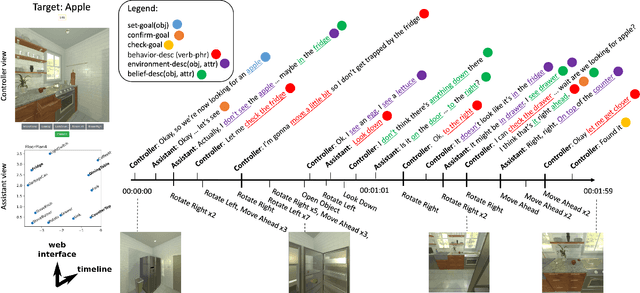
We envision robots that can collaborate and communicate seamlessly with humans. It is necessary for such robots to decide both what to say and how to act, while interacting with humans. To this end, we introduce a new task, dialogue object search: A robot is tasked to search for a target object (e.g. fork) in a human environment (e.g., kitchen), while engaging in a "video call" with a remote human who has additional but inexact knowledge about the target's location. That is, the robot conducts speech-based dialogue with the human, while sharing the image from its mounted camera. This task is challenging at multiple levels, from data collection, algorithm and system development,to evaluation. Despite these challenges, we believe such a task blocks the path towards more intelligent and collaborative robots. In this extended abstract, we motivate and introduce the dialogue object search task and analyze examples collected from a pilot study. We then discuss our next steps and conclude with several challenges on which we hope to receive feedback.
Learning to Resize Images for Computer Vision Tasks
Mar 17, 2021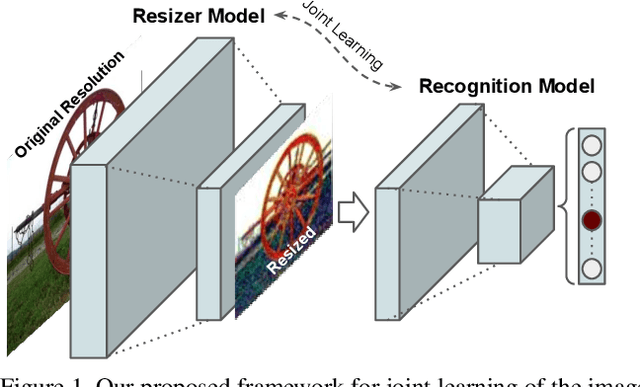


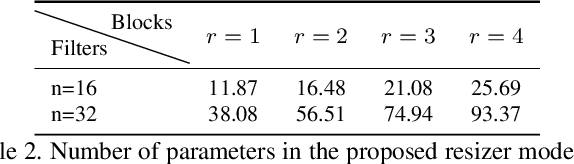
For all the ways convolutional neural nets have revolutionized computer vision in recent years, one important aspect has received surprisingly little attention: the effect of image size on the accuracy of tasks being trained for. Typically, to be efficient, the input images are resized to a relatively small spatial resolution (e.g. 224x224), and both training and inference are carried out at this resolution. The actual mechanism for this re-scaling has been an afterthought: Namely, off-the-shelf image resizers such as bilinear and bicubic are commonly used in most machine learning software frameworks. But do these resizers limit the on task performance of the trained networks? The answer is yes. Indeed, we show that the typical linear resizer can be replaced with learned resizers that can substantially improve performance. Importantly, while the classical resizers typically result in better perceptual quality of the downscaled images, our proposed learned resizers do not necessarily give better visual quality, but instead improve task performance. Our learned image resizer is jointly trained with a baseline vision model. This learned CNN-based resizer creates machine friendly visual manipulations that lead to a consistent improvement of the end task metric over the baseline model. Specifically, here we focus on the classification task with the ImageNet dataset, and experiment with four different models to learn resizers adapted to each model. Moreover, we show that the proposed resizer can also be useful for fine-tuning the classification baselines for other vision tasks. To this end, we experiment with three different baselines to develop image quality assessment (IQA) models on the AVA dataset.
Learning with Average Precision: Training Image Retrieval with a Listwise Loss
Jun 18, 2019
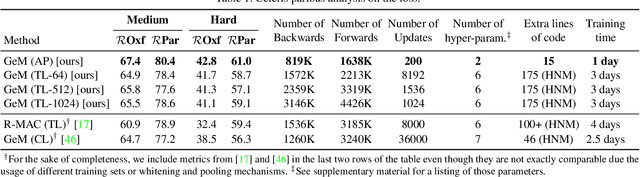
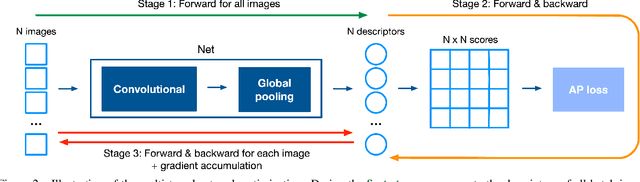
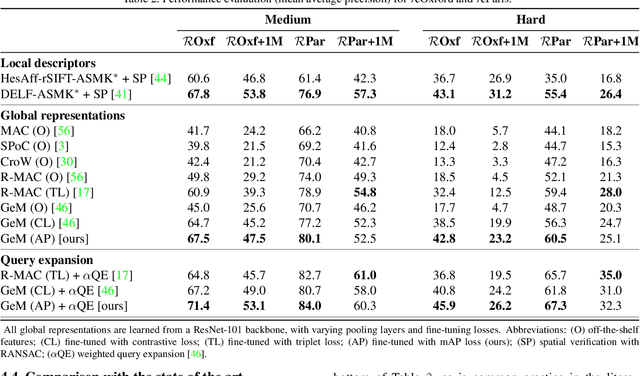
Image retrieval can be formulated as a ranking problem where the goal is to order database images by decreasing similarity to the query. Recent deep models for image retrieval have outperformed traditional methods by leveraging ranking-tailored loss functions, but important theoretical and practical problems remain. First, rather than directly optimizing the global ranking, they minimize an upper-bound on the essential loss, which does not necessarily result in an optimal mean average precision (mAP). Second, these methods require significant engineering efforts to work well, e.g. special pre-training and hard-negative mining. In this paper we propose instead to directly optimize the global mAP by leveraging recent advances in listwise loss formulations. Using a histogram binning approximation, the AP can be differentiated and thus employed to end-to-end learning. Compared to existing losses, the proposed method considers thousands of images simultaneously at each iteration and eliminates the need for ad hoc tricks. It also establishes a new state of the art on many standard retrieval benchmarks. Models and evaluation scripts have been made available at https://europe.naverlabs.com/Deep-Image-Retrieval/
Structure Destruction and Content Combination for Face Anti-Spoofing
Jul 22, 2021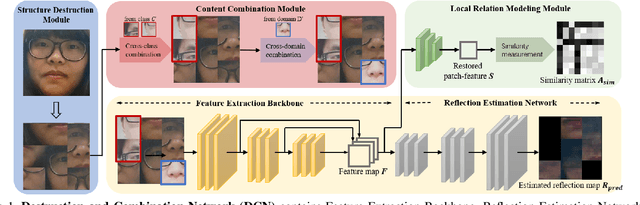
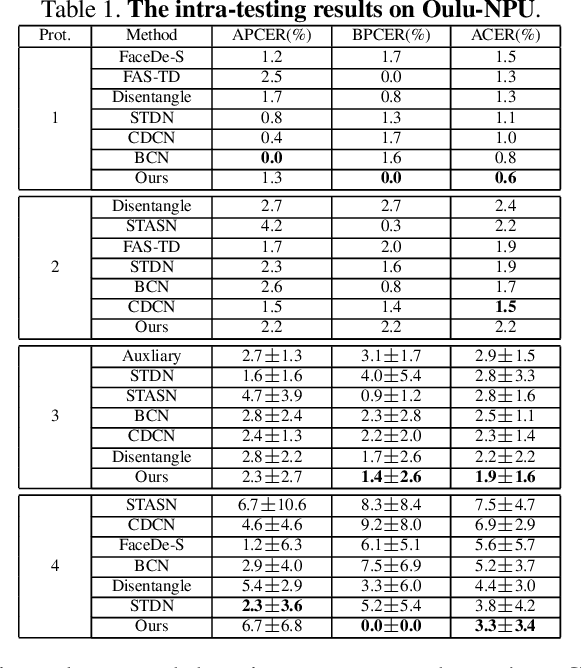
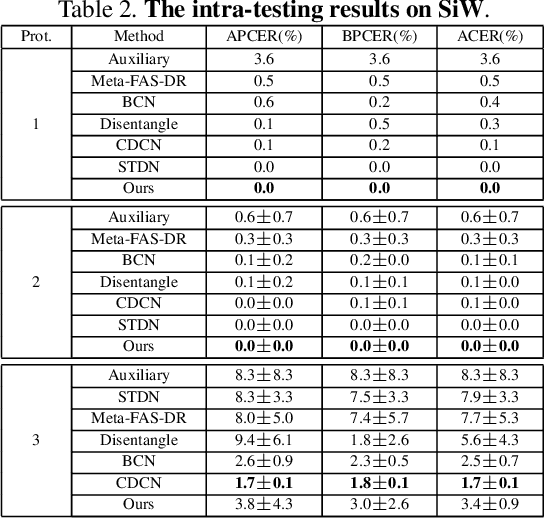

In pursuit of consolidating the face verification systems, prior face anti-spoofing studies excavate the hidden cues in original images to discriminate real persons and diverse attack types with the assistance of auxiliary supervision. However, limited by the following two inherent disturbances in their training process: 1) Complete facial structure in a single image. 2) Implicit subdomains in the whole dataset, these methods are prone to stick on memorization of the entire training dataset and show sensitivity to nonhomologous domain distribution. In this paper, we propose Structure Destruction Module and Content Combination Module to address these two imitations separately. The former mechanism destroys images into patches to construct a non-structural input, while the latter mechanism recombines patches from different subdomains or classes into a mixup construct. Based on this splitting-and-splicing operation, Local Relation Modeling Module is further proposed to model the second-order relationship between patches. We evaluate our method on extensive public datasets and promising experimental results to demonstrate the reliability of our method against state-of-the-art competitors.
TOP: Backdoor Detection in Neural Networks via Transferability of Perturbation
Mar 18, 2021
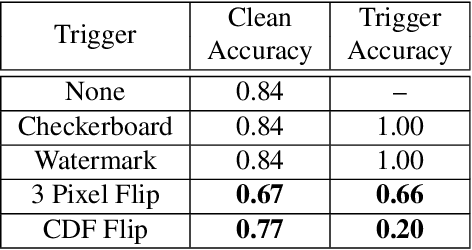
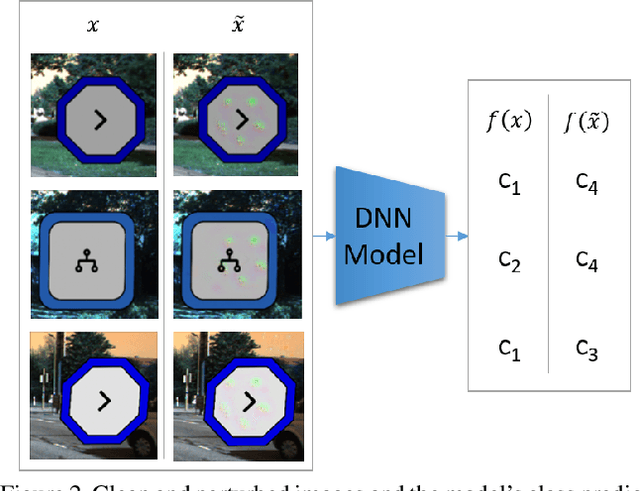
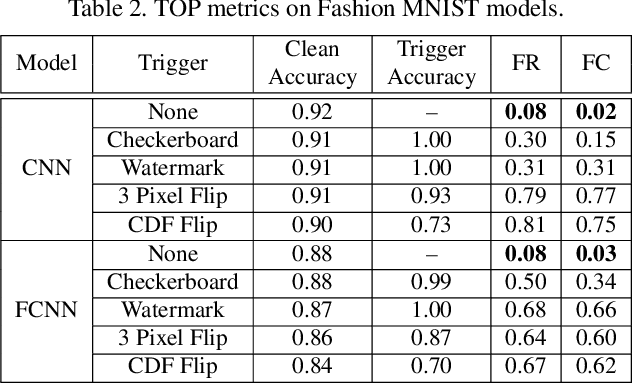
Deep neural networks (DNNs) are vulnerable to "backdoor" poisoning attacks, in which an adversary implants a secret trigger into an otherwise normally functioning model. Detection of backdoors in trained models without access to the training data or example triggers is an important open problem. In this paper, we identify an interesting property of these models: adversarial perturbations transfer from image to image more readily in poisoned models than in clean models. This holds for a variety of model and trigger types, including triggers that are not linearly separable from clean data. We use this feature to detect poisoned models in the TrojAI benchmark, as well as additional models.
Metadata Normalization
Apr 19, 2021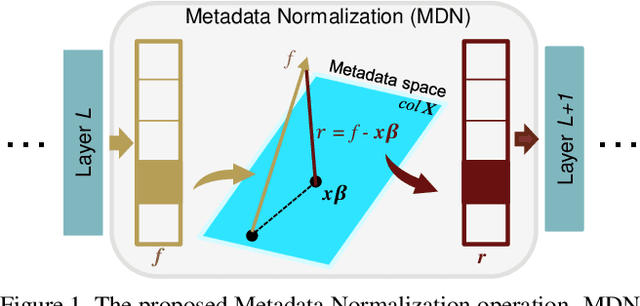
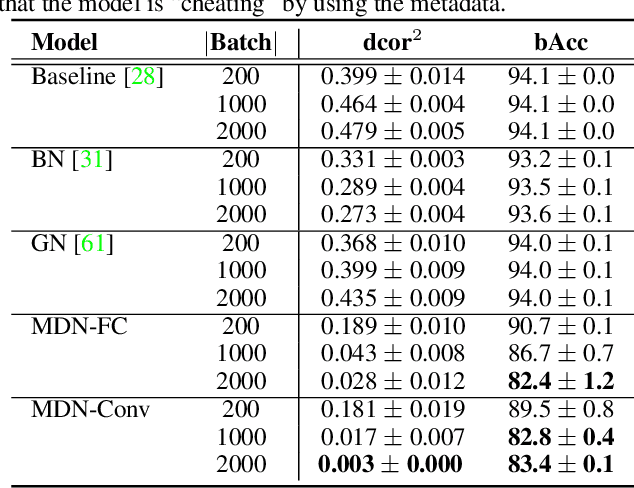

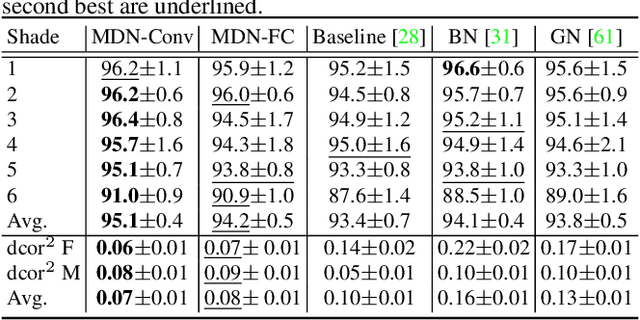
Batch Normalization (BN) and its variants have delivered tremendous success in combating the covariate shift induced by the training step of deep learning methods. While these techniques normalize feature distributions by standardizing with batch statistics, they do not correct the influence on features from extraneous variables or multiple distributions. Such extra variables, referred to as metadata here, may create bias or confounding effects (e.g., race when classifying gender from face images). We introduce the Metadata Normalization (MDN) layer, a new batch-level operation which can be used end-to-end within the training framework, to correct the influence of metadata on feature distributions. MDN adopts a regression analysis technique traditionally used for preprocessing to remove (regress out) the metadata effects on model features during training. We utilize a metric based on distance correlation to quantify the distribution bias from the metadata and demonstrate that our method successfully removes metadata effects on four diverse settings: one synthetic, one 2D image, one video, and one 3D medical image dataset.
Medical Instrument Segmentation in 3D US by Hybrid Constrained Semi-Supervised Learning
Jul 30, 2021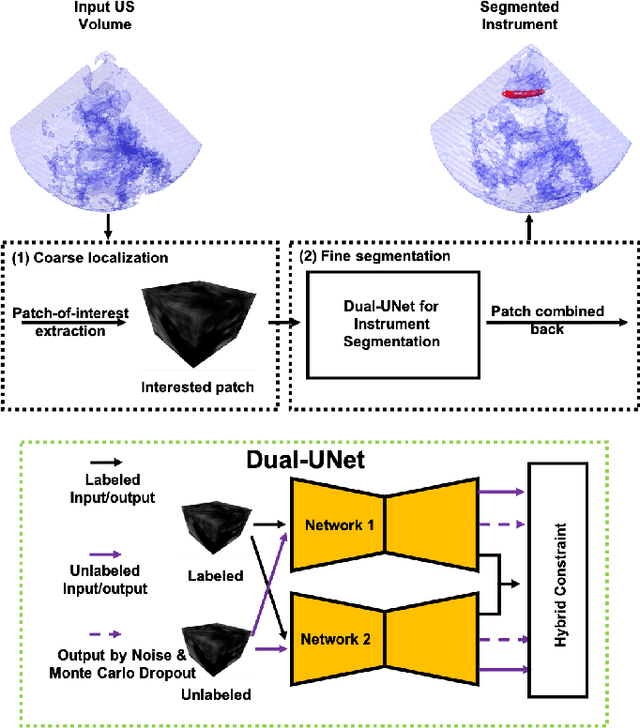

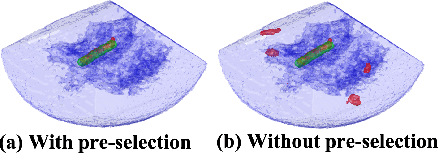
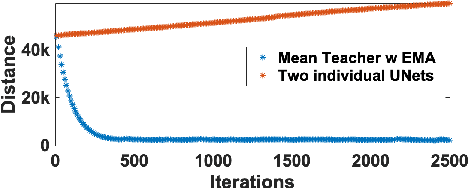
Medical instrument segmentation in 3D ultrasound is essential for image-guided intervention. However, to train a successful deep neural network for instrument segmentation, a large number of labeled images are required, which is expensive and time-consuming to obtain. In this article, we propose a semi-supervised learning (SSL) framework for instrument segmentation in 3D US, which requires much less annotation effort than the existing methods. To achieve the SSL learning, a Dual-UNet is proposed to segment the instrument. The Dual-UNet leverages unlabeled data using a novel hybrid loss function, consisting of uncertainty and contextual constraints. Specifically, the uncertainty constraints leverage the uncertainty estimation of the predictions of the UNet, and therefore improve the unlabeled information for SSL training. In addition, contextual constraints exploit the contextual information of the training images, which are used as the complementary information for voxel-wise uncertainty estimation. Extensive experiments on multiple ex-vivo and in-vivo datasets show that our proposed method achieves Dice score of about 68.6%-69.1% and the inference time of about 1 sec. per volume. These results are better than the state-of-the-art SSL methods and the inference time is comparable to the supervised approaches.
Infrared Small Target Detection Using Multi-patch Attention Network
Aug 13, 2021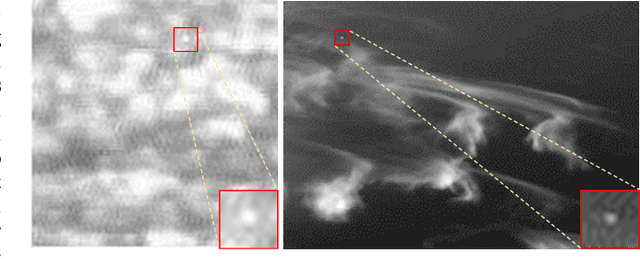

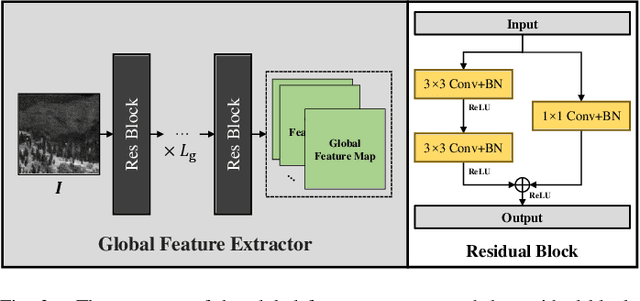
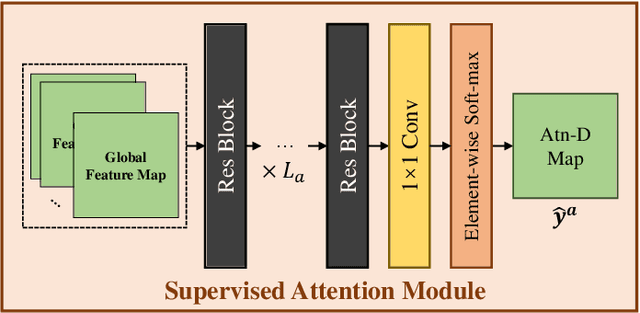
Infrared small target detection plays an important role in the infrared search and tracking applications. In recent years, deep learning techniques were introduced to this task and achieved noteworthy effects. Following general object segmentation methods, existing deep learning methods usually processed the image from the global view. However, the imaging locality of small targets and extreme class-imbalance between the target and background pixels were not well-considered by these deep learning methods, which causes the low-efficiency on training and high-dependence on numerous data. A multi-patch attention network (MANet) is proposed in this paper to detect small targets by jointly considering the global and local properties of infrared small target images. From the global view, a supervised attention module trained by the small target spread map is proposed to suppress most background pixels irrelevant with small target features. From the local view, local patches are split from global features and share the same convolution weights with each other in a patch net. By synthesizing the global and local properties, the data-driven framework proposed in this paper has fused multi-scale features for small target detection. Extensive synthetic and real data experiments show that the proposed method achieves the state-of-the-art performance compared with existing both conventional and deep learning methods.