Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOP: Backdoor Detection in Neural Networks via Transferability of Perturbation
Paper and Code
Mar 18, 2021
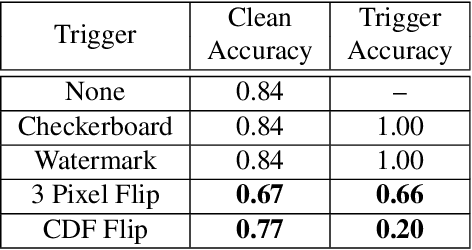
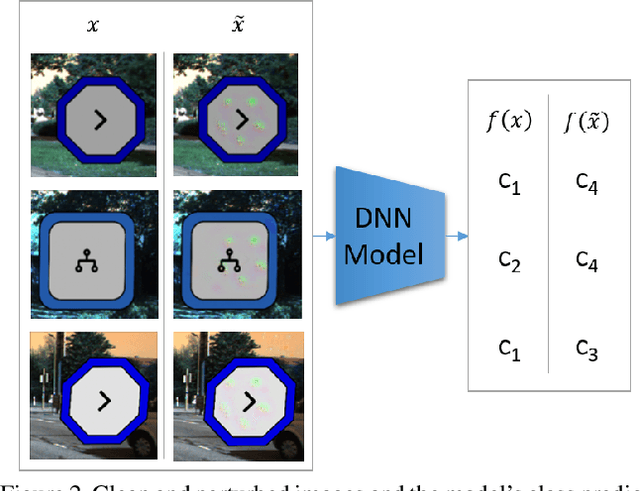
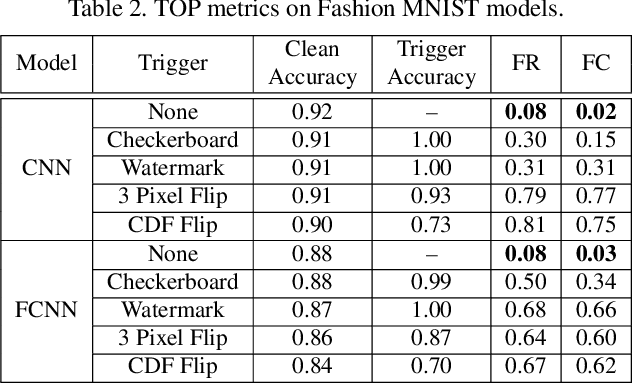
Deep neural networks (DNNs) are vulnerable to "backdoor" poisoning attacks, in which an adversary implants a secret trigger into an otherwise normally functioning model. Detection of backdoors in trained models without access to the training data or example triggers is an important open problem. In this paper, we identify an interesting property of these models: adversarial perturbations transfer from image to image more readily in poisoned models than in clean models. This holds for a variety of model and trigger types, including triggers that are not linearly separable from clean data. We use this feature to detect poisoned models in the TrojAI benchmark, as well as additional models.
View paper on