 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Trojan Detection Competitions with Linear Weight Classification
Nov 05, 2024



Neural networks can conceal malicious Trojan backdoors that allow a trigger to covertly change the model behavior. Detecting signs of these backdoors, particularly without access to any triggered data, is the subject of ongoing research and open challenges. In one common formulation of the problem, we are given a set of clean and poisoned models and need to predict whether a given test model is clean or poisoned. In this paper, we introduce a detector that works remarkably well across many of the existing datasets and domains. It is obtained by training a binary classifier on a large number of models' weights after performing a few different pre-processing steps including feature selection and standardization, reference model weights subtraction, and model alignment prior to detection. We evaluate this algorithm on a diverse set of Trojan detection benchmarks and domains and examine the cases where the approach is most and least effective.
TOP: Backdoor Detection in Neural Networks via Transferability of Perturbation
Mar 18, 2021
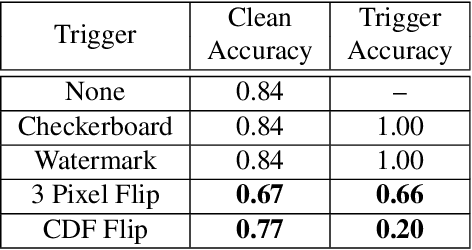
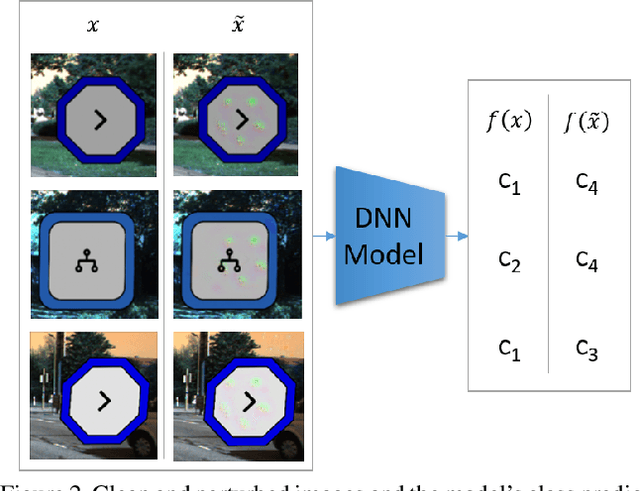
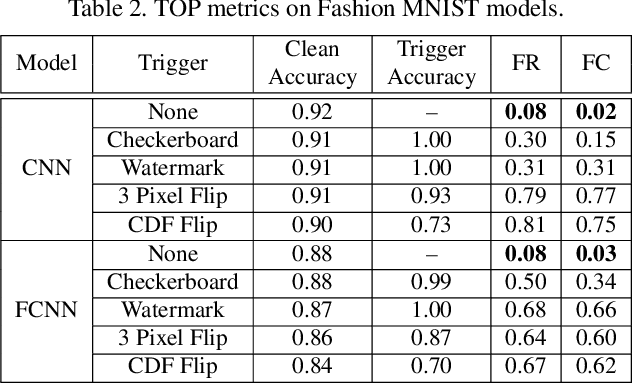
Deep neural networks (DNNs) are vulnerable to "backdoor" poisoning attacks, in which an adversary implants a secret trigger into an otherwise normally functioning model. Detection of backdoors in trained models without access to the training data or example triggers is an important open problem. In this paper, we identify an interesting property of these models: adversarial perturbations transfer from image to image more readily in poisoned models than in clean models. This holds for a variety of model and trigger types, including triggers that are not linearly separable from clean data. We use this feature to detect poisoned models in the TrojAI benchmark, as well as additional models.
Feedback-Based Tree Search for Reinforcement Learning
May 15, 2018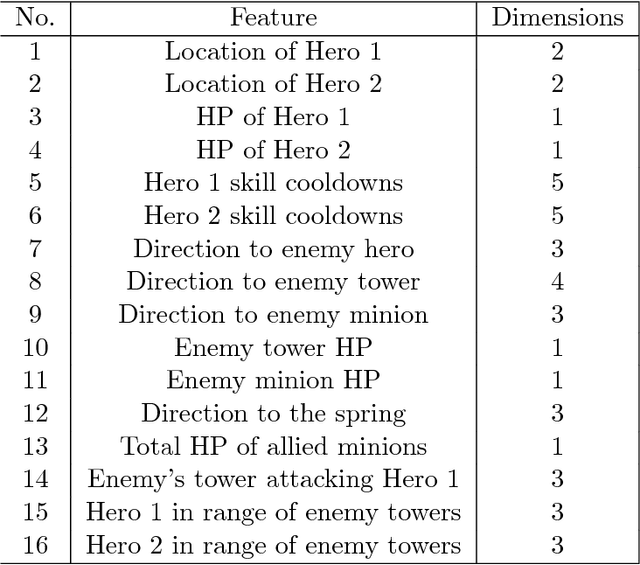
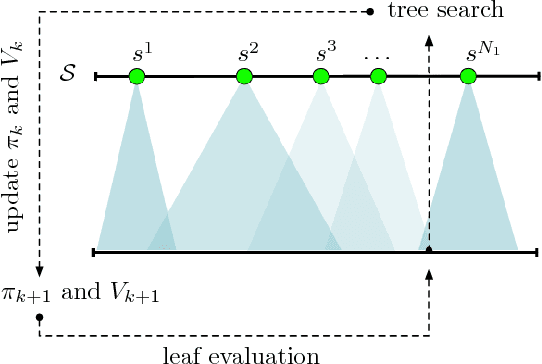

Inspired by recent successes of Monte-Carlo tree search (MCTS) in a number of artificial intelligence (AI) application domains, we propose a model-based reinforcement learning (RL) technique that iteratively applies MCTS on batches of small, finite-horizon versions of the original infinite-horizon Markov decision process. The terminal condition of the finite-horizon problems, or the leaf-node evaluator of the decision tree generated by MCTS, is specified using a combination of an estimated value function and an estimated policy function. The recommendations generated by the MCTS procedure are then provided as feedback in order to refine, through classification and regression, the leaf-node evaluator for the next iteration. We provide the first sample complexity bounds for a tree search-based RL algorithm. In addition, we show that a deep neural network implementation of the technique can create a competitive AI agent for the popular multi-player online battle arena (MOBA) game King of Glory.