 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Quantile Regression for Extreme Precipitation Downscaling
May 12, 2026Deep super-resolution networks for precipitation downscaling achieve strong bulk skill yet systematically under-predict the heavy-tail events that drive flood risk. We demonstrate that the primary obstacle is the loss function, not the data: under intensity-weighted MAE, real and synthetic labels at the same input are simply averaged, meaning data augmentation shifts the predicted mean rather than the conditional distribution. We resolve this with Q-SRDRN, a multi-quantile super-resolution network trained with pinball loss at tau in 0.50, 0.95, 0.99, 0.999. Two CNN-specific design choices make this practical: IncrementBound enforces monotonicity while preserving each quantile channel's gradient identity, and separate per-quantile output heads provide independent filter banks for bulk and tail detection. Under this design, data augmentation via cVAE becomes complementary: the median head absorbs synthetic patterns without contaminating upper quantiles. Empirically, on Florida (convective/tropical-cyclone dominated), the un-augmented Q-SRDRN P999 head detects 1,598 of 2,111 events at 200 mm/day versus 88 for the deterministic baseline--an 18x detection-rate gain (4.2% to 75.7%)--with 63% lower KL divergence and 3.9% lower RMSE. Adding cVAE-generated samples lifts the P50 channel from 14 to 1,038 hits at 200 mm/day. On California (atmospheric-river dominated), the architecture reaches near-perfect detection (P999 SEDI >= 0.996 through 300 mm/day). On Texas, the baseline catches only 2 of 10,720 events at 200 mm/day while the P999 head catches 8,776 (81.9%). While the cVAE does not transfer across regions, multi-quantile regression captures extremes wherever the large-scale signal is strong, while augmentation rescues the median where it is not.
Exploring Robust Multi-Agent Workflows for Environmental Data Management
Apr 02, 2026Embedding LLM-driven agents into environmental FAIR data management is compelling - they can externalize operational knowledge and scale curation across heterogeneous data and evolving conventions. However, replacing deterministic components with probabilistic workflows changes the failure mode: LLM pipelines may generate plausible but incorrect outputs that pass superficial checks and propagate into irreversible actions such as DOI minting and public release. We introduce EnviSmart, a production data management system deployed on campus-wide storage infrastructure for environmental research. EnviSmart treats reliability as an architectural property through two mechanisms: a three-track knowledge architecture that externalizes behaviors (governance constraints), domain knowledge (retrievable context), and skills (tool-using procedures) as persistent, interlocking artifacts; and a role-separated multi-agent design where deterministic validators and audited handoffs restore fail-stop semantics at trust boundaries before irreversible steps. We compare two production deployments. The University's GIS Center Ecological Archive (849 curated datasets) serves as a single-agent baseline. SF2Bench, a compound flooding benchmark comprising 2,452 monitoring stations and 8,557 published files spanning 39 years, validates the multi-agent workflow. The multi-agent approach improved both efficiency - completed by a single operator in two days with repeated artifact reuse across deployments - and reliability: audited handoffs detected and blocked a coordinate transformation error affecting all 2,452 stations before publication. A representative incident (ISS-004) demonstrated boundary-based containment with 10-minute detection latency, zero user exposure, and 80-minute resolution. This paper has been accepted at PEARC 2026.
Feature-Function Curvature Analysis: A Geometric Framework for Explaining Differentiable Models
Oct 31, 2025Explainable AI (XAI) is critical for building trust in complex machine learning models, yet mainstream attribution methods often provide an incomplete, static picture of a model's final state. By collapsing a feature's role into a single score, they are confounded by non-linearity and interactions. To address this, we introduce Feature-Function Curvature Analysis (FFCA), a novel framework that analyzes the geometry of a model's learned function. FFCA produces a 4-dimensional signature for each feature, quantifying its: (1) Impact, (2) Volatility, (3) Non-linearity, and (4) Interaction. Crucially, we extend this framework into Dynamic Archetype Analysis, which tracks the evolution of these signatures throughout the training process. This temporal view moves beyond explaining what a model learned to revealing how it learns. We provide the first direct, empirical evidence of hierarchical learning, showing that models consistently learn simple linear effects before complex interactions. Furthermore, this dynamic analysis provides novel, practical diagnostics for identifying insufficient model capacity and predicting the onset of overfitting. Our comprehensive experiments demonstrate that FFCA, through its static and dynamic components, provides the essential geometric context that transforms model explanation from simple quantification to a nuanced, trustworthy analysis of the entire learning process.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
Sandcastles in the Storm: Revisiting the (Im)possibility of Strong Watermarking
May 11, 2025



Watermarking AI-generated text is critical for combating misuse. Yet recent theoretical work argues that any watermark can be erased via random walk attacks that perturb text while preserving quality. However, such attacks rely on two key assumptions: (1) rapid mixing (watermarks dissolve quickly under perturbations) and (2) reliable quality preservation (automated quality oracles perfectly guide edits). Through large-scale experiments and human-validated assessments, we find mixing is slow: 100% of perturbed texts retain traces of their origin after hundreds of edits, defying rapid mixing. Oracles falter, as state-of-the-art quality detectors misjudge edits (77% accuracy), compounding errors during attacks. Ultimately, attacks underperform: automated walks remove watermarks just 26% of the time -- dropping to 10% under human quality review. These findings challenge the inevitability of watermark removal. Instead, practical barriers -- slow mixing and imperfect quality control -- reveal watermarking to be far more robust than theoretical models suggest. The gap between idealized attacks and real-world feasibility underscores the need for stronger watermarking methods and more realistic attack models.
Relational Programming with Foundation Models
Dec 19, 2024Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
Dolphin: A Programmable Framework for Scalable Neurosymbolic Learning
Oct 04, 2024



Neurosymbolic learning has emerged as a promising paradigm to incorporate symbolic reasoning into deep learning models. However, existing frameworks are limited in scalability with respect to both the training data and the complexity of symbolic programs. We propose Dolphin, a framework to scale neurosymbolic learning at a fundamental level by mapping both forward chaining and backward gradient propagation in symbolic programs to vectorized computations. For this purpose, Dolphin introduces a set of abstractions and primitives built directly on top of a high-performance deep learning framework like PyTorch, effectively enabling symbolic programs to be written as PyTorch modules. It thereby enables neurosymbolic programs to be written in a language like Python that is familiar to developers and compile them to computation graphs that are amenable to end-to-end differentiation on GPUs. We evaluate Dolphin on a suite of 13 benchmarks across 5 neurosymbolic tasks that combine deep learning models for text, image, or video processing with symbolic programs that involve multi-hop reasoning, recursion, and even black-box functions like Python eval(). Dolphin only takes 0.33%-37.17% of the time (and 2.77% on average) to train these models on the largest input per task compared to baselines Scallop, ISED, and IndeCateR+, which time out on most of these inputs. Models written in Dolphin also achieve state-of-the-art accuracies even on the largest benchmarks.
Self-supervised Activity Representation Learning with Incremental Data: An Empirical Study
May 01, 2023



In the context of mobile sensing environments, various sensors on mobile devices continually generate a vast amount of data. Analyzing this ever-increasing data presents several challenges, including limited access to annotated data and a constantly changing environment. Recent advancements in self-supervised learning have been utilized as a pre-training step to enhance the performance of conventional supervised models to address the absence of labelled datasets. This research examines the impact of using a self-supervised representation learning model for time series classification tasks in which data is incrementally available. We proposed and evaluated a workflow in which a model learns to extract informative features using a corpus of unlabeled time series data and then conducts classification on labelled data using features extracted by the model. We analyzed the effect of varying the size, distribution, and source of the unlabeled data on the final classification performance across four public datasets, including various types of sensors in diverse applications.
Dialogue Object Search
Jul 22, 2021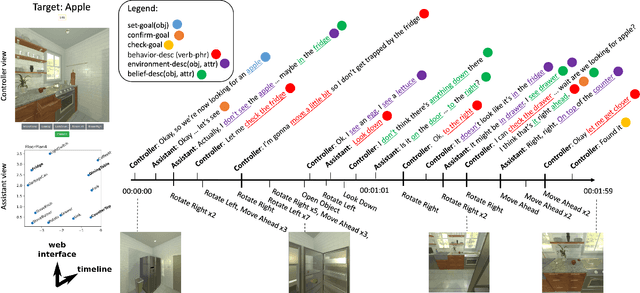
We envision robots that can collaborate and communicate seamlessly with humans. It is necessary for such robots to decide both what to say and how to act, while interacting with humans. To this end, we introduce a new task, dialogue object search: A robot is tasked to search for a target object (e.g. fork) in a human environment (e.g., kitchen), while engaging in a "video call" with a remote human who has additional but inexact knowledge about the target's location. That is, the robot conducts speech-based dialogue with the human, while sharing the image from its mounted camera. This task is challenging at multiple levels, from data collection, algorithm and system development,to evaluation. Despite these challenges, we believe such a task blocks the path towards more intelligent and collaborative robots. In this extended abstract, we motivate and introduce the dialogue object search task and analyze examples collected from a pilot study. We then discuss our next steps and conclude with several challenges on which we hope to receive feedback.