 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kernel-Free Image Deblurring with a Pair of Blurred/Noisy Images
Mar 27, 2019

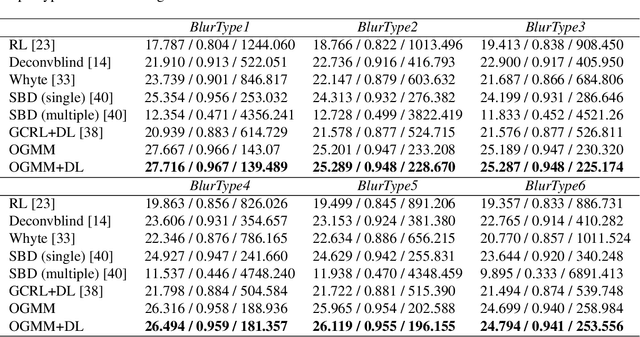
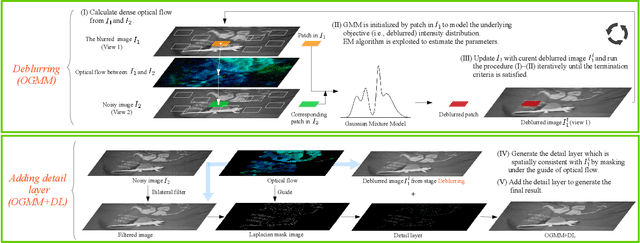

Complex blur like the mixup of space-variant and space-invariant blur, which is hard to be modeled mathematically, widely exists in real images. In the real world, a common type of blur occurs when capturing images in low-light environments. In this paper, we propose a novel image deblurring method that does not need to estimate blur kernels. We utilize a pair of images which can be easily acquired in low-light situations: (1) a blurred image taken with low shutter speed and low ISO noise, and (2) a noisy image captured with high shutter speed and high ISO noise. Specifically, the blurred image is first sliced into patches, and we extend the Gaussian mixture model (GMM) to model the underlying intensity distribution of each patch using the corresponding patches in the noisy image. We compute patch correspondences by analyzing the optical flow between the two images. The Expectation-Maximization (EM) algorithm is utilized to estimate the involved parameters in the GMM. To preserve sharp features, we add an additional bilateral term to the objective function in the M-step. We eventually add a detail layer to the deblurred image for refinement. Extensive experiments on both synthetic and real-world data demonstrate that our method outperforms state-of-the-art techniques, in terms of robustness, visual quality and quantitative metrics. We will make our dataset and source code publicly available.
Localized Adversarial Training for Increased Accuracy and Robustness in Image Classification
Sep 10, 2019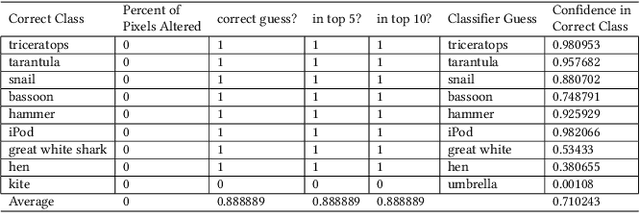

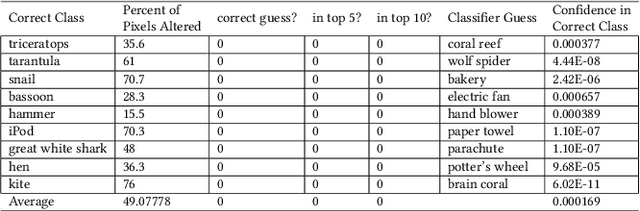
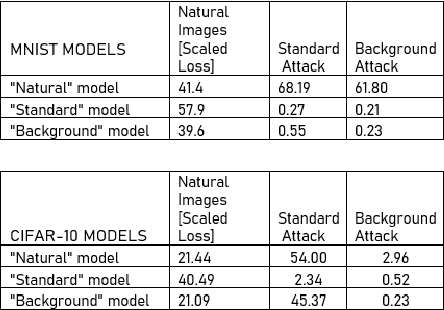
Today's state-of-the-art image classifiers fail to correctly classify carefully manipulated adversarial images. In this work, we develop a new, localized adversarial attack that generates adversarial examples by imperceptibly altering the backgrounds of normal images. We first use this attack to highlight the unnecessary sensitivity of neural networks to changes in the background of an image, then use it as part of a new training technique: localized adversarial training. By including locally adversarial images in the training set, we are able to create a classifier that suffers less loss than a non-adversarially trained counterpart model on both natural and adversarial inputs. The evaluation of our localized adversarial training algorithm on MNIST and CIFAR-10 datasets shows decreased accuracy loss on natural images, and increased robustness against adversarial inputs.
AI Based Waste classifier with Thermo-Rapid Composting
Aug 03, 2021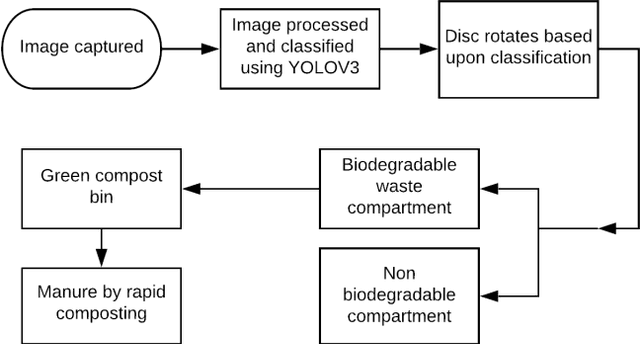
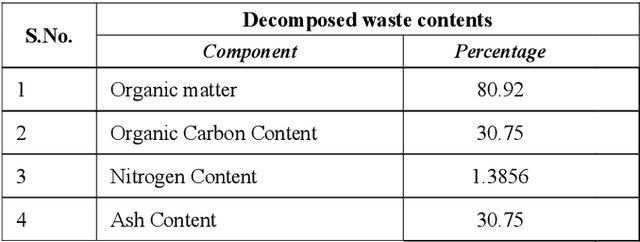
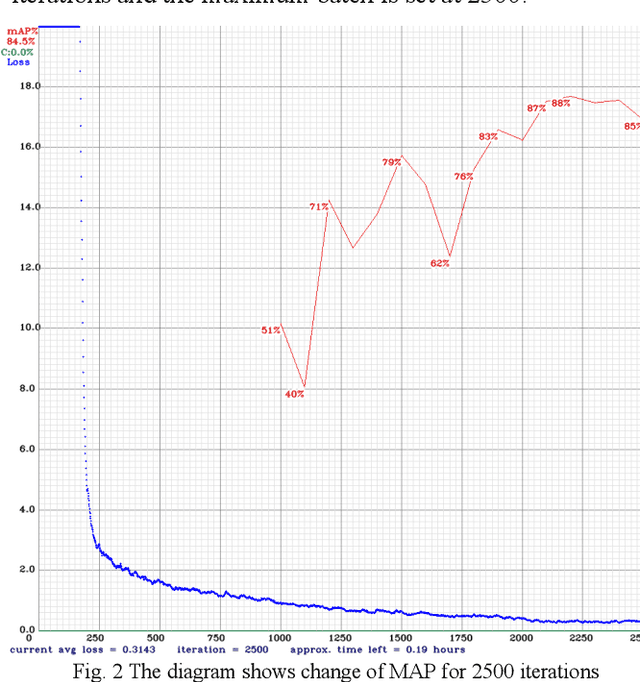

Waste management is a certainly a very complex and difficult process especially in very large cities. It needs immense man power and also uses up other resources such as electricity and fuel. This creates a need to use a novel method with help of latest technologies. Here in this article we present a new waste classification technique using Computer Vision (CV) and deep learning (DL). To further improve waste classification ability, support machine vectors (SVM) are used. We also decompose the degradable waste with help of rapid composting. In this article we have mainly worked on segregation of municipal solid waste (MSW). For this model, we use YOLOv3 (You Only Look Once) a computer vision-based algorithm popularly used to detect objects which is developed based on Convolution Neural Networks (CNNs) which is a machine learning (ML) based tool. They are extensively used to extract features from a data especially image-oriented data. In this article we propose a waste classification technique which will be faster and more efficient. And we decompose the biodegradable waste by Berkley Method of composting (BKC)
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Jul 27, 2019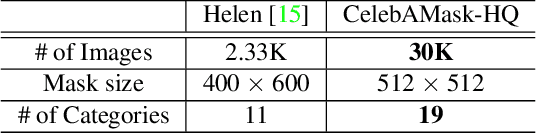
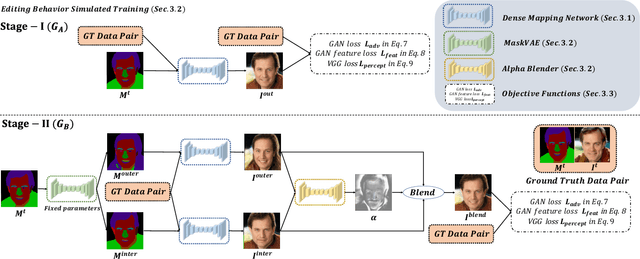
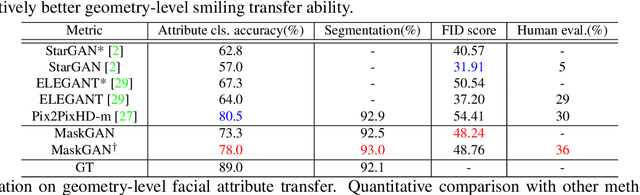
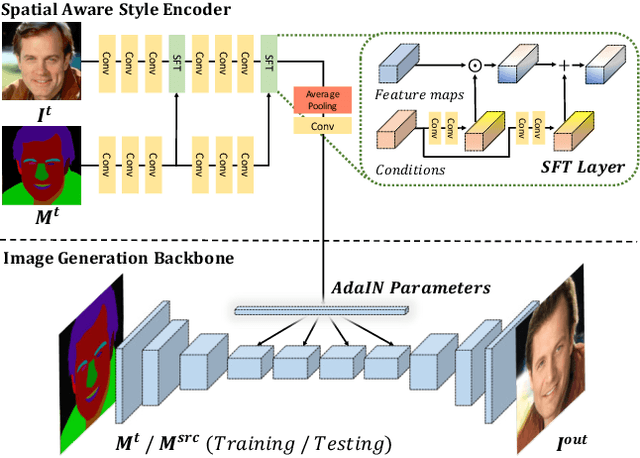
Facial image manipulation has achieved great progresses in recent years. However, previous methods either operate on a predefined set of face attributes or leave users little freedom to interactively manipulate images. To overcome these drawbacks, we propose a novel framework termed MaskGAN, enabling diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. MaskGAN has two main components: 1) Dense Mapping Network, and 2) Editing Behavior Simulated Training. Specifically, Dense mapping network learns style mapping between a free-form user modified mask and a target image, enabling diverse generation results. Editing behavior simulated training models the user editing behavior on the source mask, making the overall framework more robust to various manipulated inputs. To facilitate extensive studies, we construct a large-scale high-resolution face dataset with fine-grained mask annotations named CelebAMask-HQ. MaskGAN is comprehensively evaluated on two challenging tasks: attribute transfer and style copy, demonstrating superior performance over other state-of-the-art methods. The code, models and dataset are available at \url{https://github.com/switchablenorms/CelebAMask-HQ}.
SeqNet: Learning Descriptors for Sequence-based Hierarchical Place Recognition
Feb 24, 2021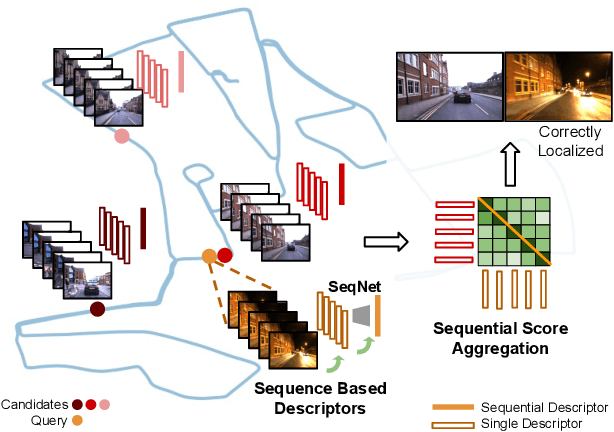
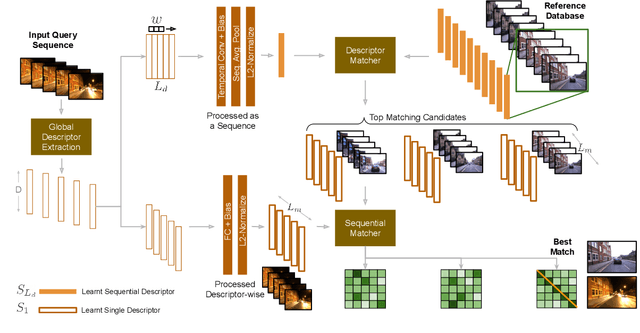
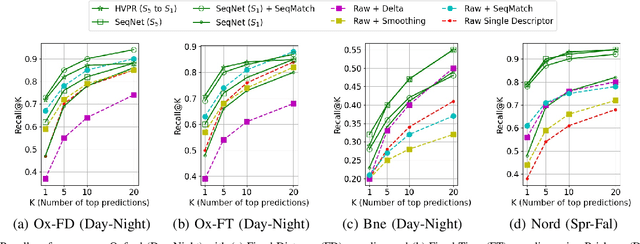
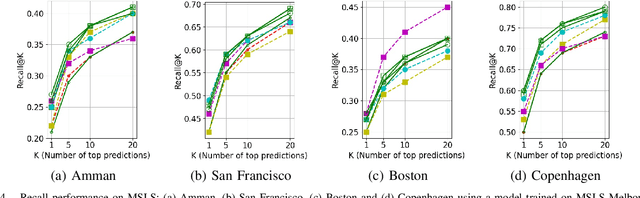
Visual Place Recognition (VPR) is the task of matching current visual imagery from a camera to images stored in a reference map of the environment. While initial VPR systems used simple direct image methods or hand-crafted visual features, recent work has focused on learning more powerful visual features and further improving performance through either some form of sequential matcher / filter or a hierarchical matching process. In both cases the performance of the initial single-image based system is still far from perfect, putting significant pressure on the sequence matching or (in the case of hierarchical systems) pose refinement stages. In this paper we present a novel hybrid system that creates a high performance initial match hypothesis generator using short learnt sequential descriptors, which enable selective control sequential score aggregation using single image learnt descriptors. Sequential descriptors are generated using a temporal convolutional network dubbed SeqNet, encoding short image sequences using 1-D convolutions, which are then matched against the corresponding temporal descriptors from the reference dataset to provide an ordered list of place match hypotheses. We then perform selective sequential score aggregation using shortlisted single image learnt descriptors from a separate pipeline to produce an overall place match hypothesis. Comprehensive experiments on challenging benchmark datasets demonstrate the proposed method outperforming recent state-of-the-art methods using the same amount of sequential information. Source code and supplementary material can be found at https://github.com/oravus/seqNet.
Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
Oct 09, 2019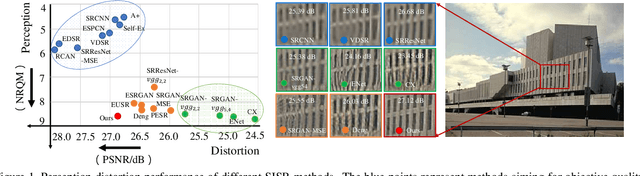
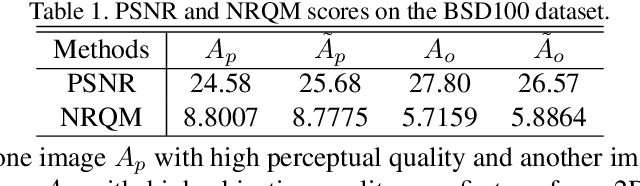
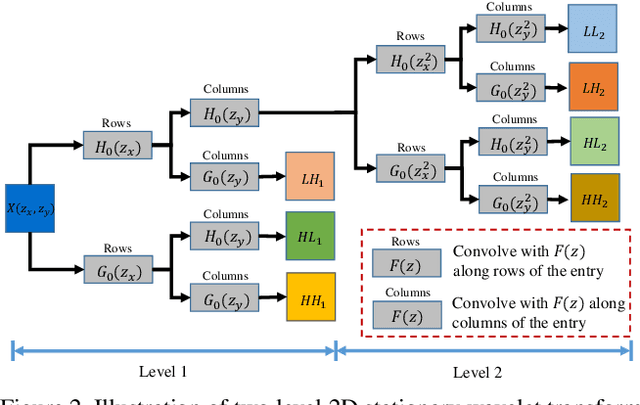
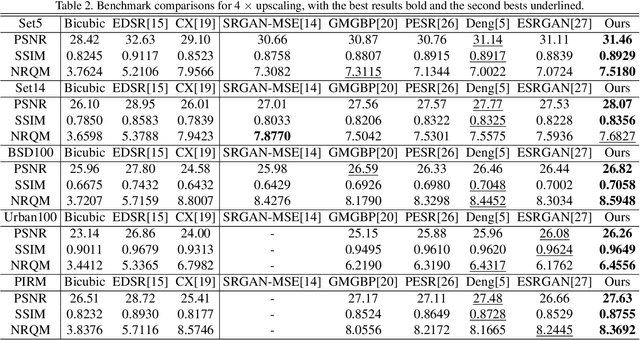
In single image super-resolution (SISR), given a low-resolution (LR) image, one wishes to find a high-resolution (HR) version of it which is both accurate and photo-realistic. Recently, it has been shown that there exists a fundamental tradeoff between low distortion and high perceptual quality, and the generative adversarial network (GAN) is demonstrated to approach the perception-distortion (PD) bound effectively. In this paper, we propose a novel method based on wavelet domain style transfer (WDST), which achieves a better PD tradeoff than the GAN based methods. Specifically, we propose to use 2D stationary wavelet transform (SWT) to decompose one image into low-frequency and high-frequency sub-bands. For the low-frequency sub-band, we improve its objective quality through an enhancement network. For the high-frequency sub-band, we propose to use WDST to effectively improve its perceptual quality. By feat of the perfect reconstruction property of wavelets, these sub-bands can be re-combined to obtain an image which has simultaneously high objective and perceptual quality. The numerical results on various datasets show that our method achieves the best trade-off between the distortion and perceptual quality among the existing state-of-the-art SISR methods.
BBAM: Bounding Box Attribution Map for Weakly Supervised Semantic and Instance Segmentation
Mar 16, 2021
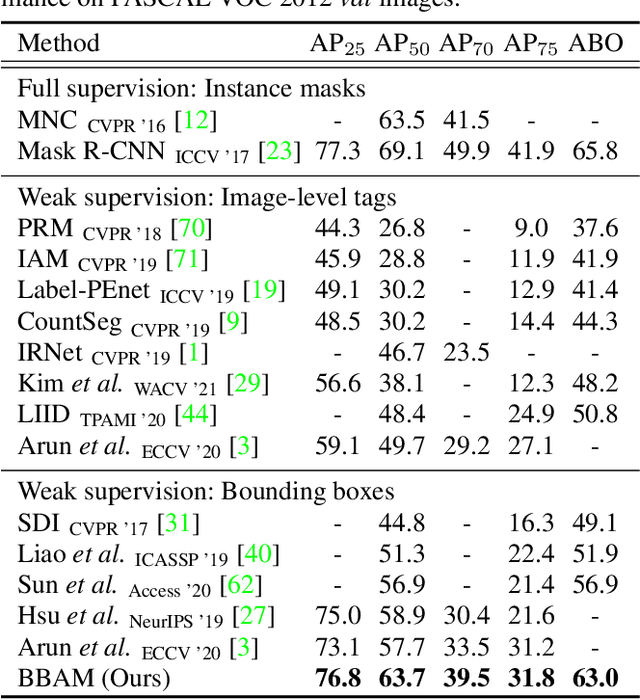
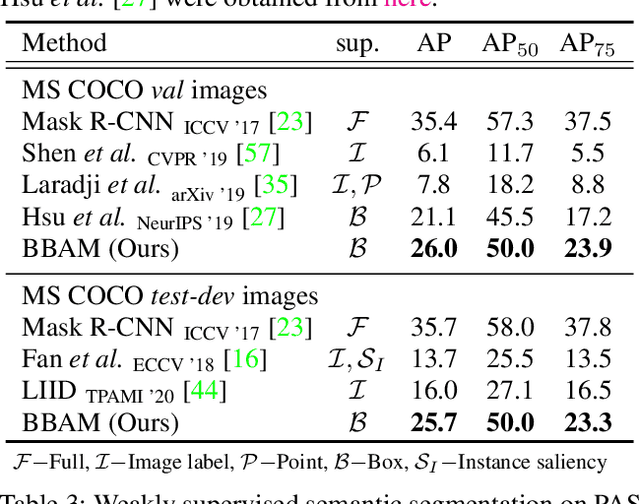

Weakly supervised segmentation methods using bounding box annotations focus on obtaining a pixel-level mask from each box containing an object. Existing methods typically depend on a class-agnostic mask generator, which operates on the low-level information intrinsic to an image. In this work, we utilize higher-level information from the behavior of a trained object detector, by seeking the smallest areas of the image from which the object detector produces almost the same result as it does from the whole image. These areas constitute a bounding-box attribution map (BBAM), which identifies the target object in its bounding box and thus serves as pseudo ground-truth for weakly supervised semantic and instance segmentation. This approach significantly outperforms recent comparable techniques on both the PASCAL VOC and MS COCO benchmarks in weakly supervised semantic and instance segmentation. In addition, we provide a detailed analysis of our method, offering deeper insight into the behavior of the BBAM.
Tasks Structure Regularization in Multi-Task Learning for Improving Facial Attribute Prediction
Aug 18, 2021
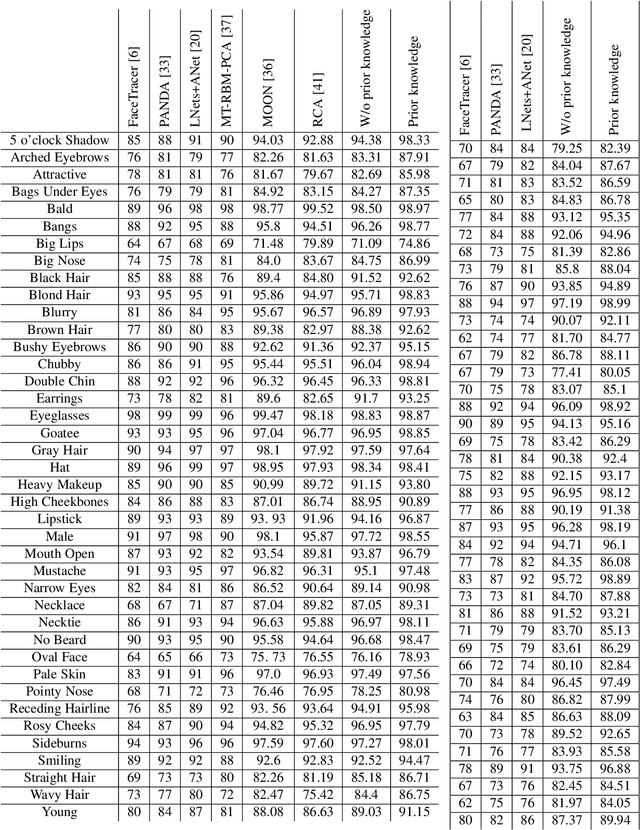
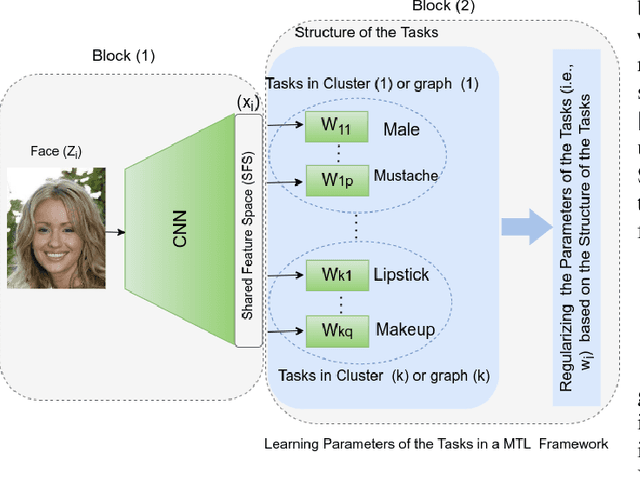
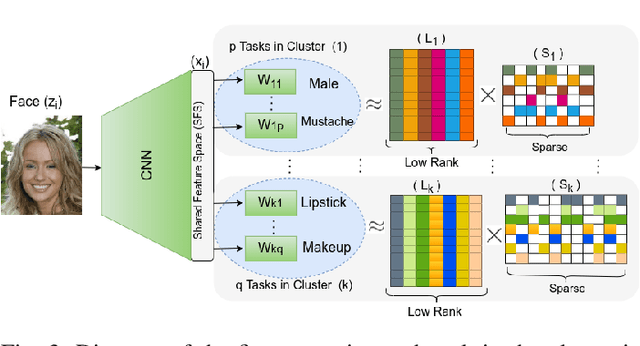
The great success of Convolutional Neural Networks (CNN) for facial attribute prediction relies on a large amount of labeled images. Facial image datasets are usually annotated by some commonly used attributes (e.g., gender), while labels for the other attributes (e.g., big nose) are limited which causes their prediction challenging. To address this problem, we use a new Multi-Task Learning (MTL) paradigm in which a facial attribute predictor uses the knowledge of other related attributes to obtain a better generalization performance. Here, we leverage MLT paradigm in two problem settings. First, it is assumed that the structure of the tasks (e.g., grouping pattern of facial attributes) is known as a prior knowledge, and parameters of the tasks (i.e., predictors) within the same group are represented by a linear combination of a limited number of underlying basis tasks. Here, a sparsity constraint on the coefficients of this linear combination is also considered such that each task is represented in a more structured and simpler manner. Second, it is assumed that the structure of the tasks is unknown, and then structure and parameters of the tasks are learned jointly by using a Laplacian regularization framework. Our MTL methods are compared with competing methods for facial attribute prediction to show its effectiveness.
X-GANs: Image Reconstruction Made Easy for Extreme Cases
Aug 06, 2018

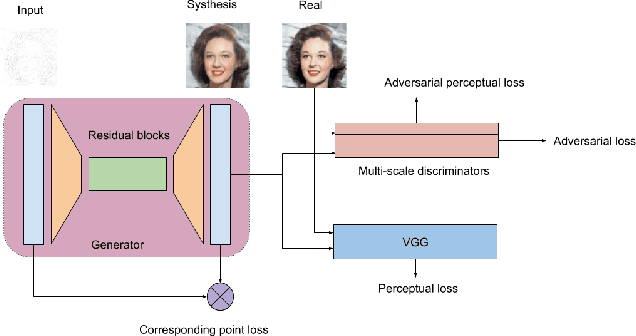

Image reconstruction including image restoration and denoising is a challenging problem in the field of image computing. We present a new method, called X-GANs, for reconstruction of arbitrary corrupted resource based on a variant of conditional generative adversarial networks (conditional GANs). In our method, a novel generator and multi-scale discriminators are proposed, as well as the combined adversarial losses, which integrate a VGG perceptual loss, an adversarial perceptual loss, and an elaborate corresponding point loss together based on the analysis of image feature. Our conditional GANs have enabled a variety of applications in image reconstruction, including image denoising, image restoration from quite a sparse sampling, image inpainting, image recovery from the severely polluted block or even color-noise dominated images, which are extreme cases and haven't been addressed in the status quo. We have significantly improved the accuracy and quality of image reconstruction. Extensive perceptual experiments on datasets ranging from human faces to natural scenes demonstrate that images reconstructed by the presented approach are considerably more realistic than alternative work. Our method can also be extended to handle high-ratio image compression.
Deep Rival Penalized Competitive Learning for Low-resolution Face Recognition
Aug 03, 2021
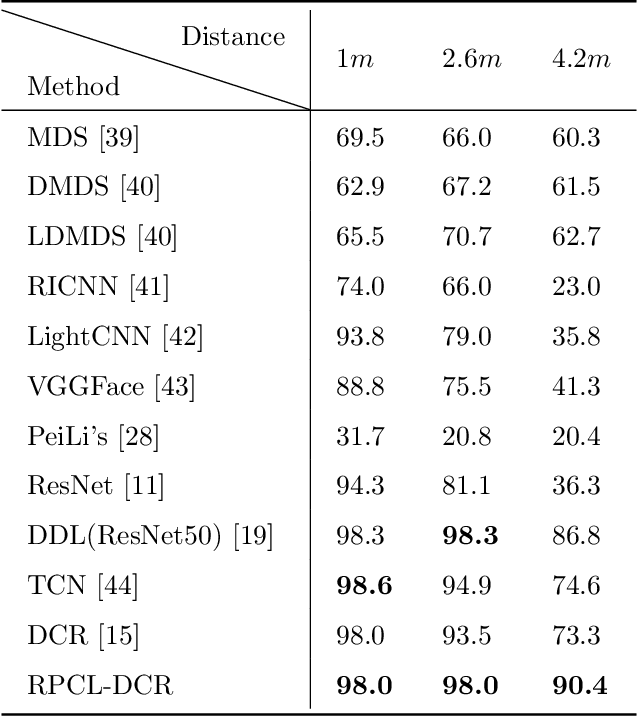

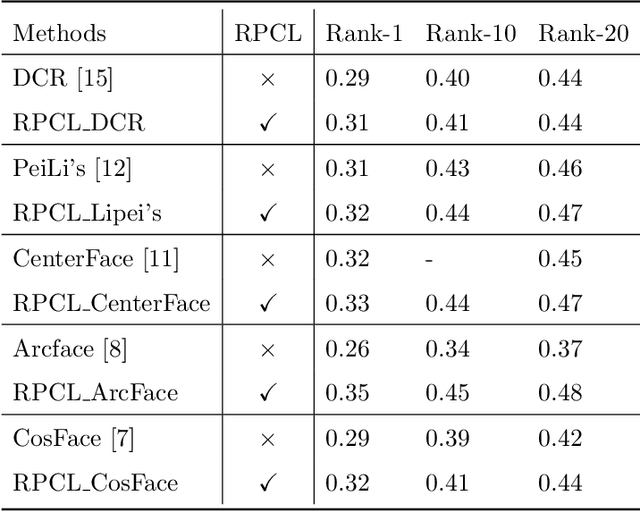
Current face recognition tasks are usually carried out on high-quality face images, but in reality, most face images are captured under unconstrained or poor conditions, e.g., by video surveillance. Existing methods are featured by learning data uncertainty to avoid overfitting the noise, or by adding margins to the angle or cosine space of the normalized softmax loss to penalize the target logit, which enforces intra-class compactness and inter-class discrepancy. In this paper, we propose a deep Rival Penalized Competitive Learning (RPCL) for deep face recognition in low-resolution (LR) images. Inspired by the idea of the RPCL, our method further enforces regulation on the rival logit, which is defined as the largest non-target logit for an input image. Different from existing methods that only consider penalization on the target logit, our method not only strengthens the learning towards the target label, but also enforces a reverse direction, i.e., becoming de-learning, away from the rival label. Comprehensive experiments demonstrate that our method improves the existing state-of-the-art methods to be very robust for LR face recognition.