 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubjective Portrait Region Cropping in Landscape Videos with Temporal Annotation Smoothing
Apr 27, 2026With the rise of mobile video consumption on diverse handheld display resolutions and orientation modes, altering videos to aspect ratios poses challenges. Static cropping and border padding often compromises visual quality, while warping may distort a video's intended meaning. Here we advocate for a more effective approach: cropping significant regions within video frames in a temporal manner, while minimizing distortion and preserving essential content. One barrier to solving this problem is the lack of sufficiently large-scale database devoted to informing these tasks. Towards filling this gap, we introduce the LIVE-YouTube Video Cropping (LIVE-YT VC) database, featuring 1800 videos, annotated by 90 human subjects. Using videos sourced from the YouTube-UGC and LSVQ Databases, this new resource is the largest publicly-available subjective video portrait region cropping database. We also introduce a post-processed version of the database, called LIVE-YT VC++, whereby a novel intra-frame temporal filter was deployed to smooth subjective annotations within each video. We demonstrate the usefulness of this new data resource using the SmartVidCrop algorithm and state-of-the-art video grounding models, in hopes of establishing our subjective dataset as a benchmark for future research. Our contributions offer a resource for advancing video aspect ratio transformation models towards ensuring that reshaped mobile-friendly video content retains its quality and meaning. Since our labels bear resemblances to video saliency annotations, we also conducted an additional analysis to explore the similarity between our labels and video saliency predictions. Finally, we repurposed state-of-the-art video grounding models for aspect ratio change tasks, and fine-tuned them on our dataset. As a service to the research community, we plan to open source the project.
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation
Jul 27, 2019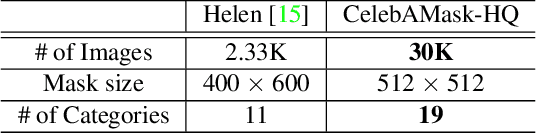
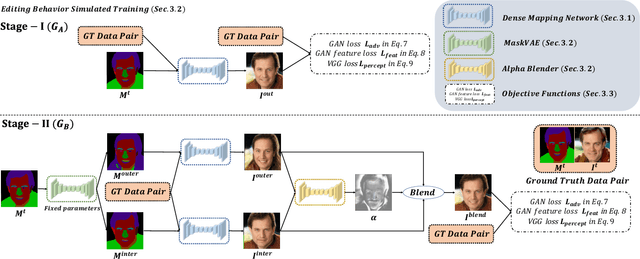
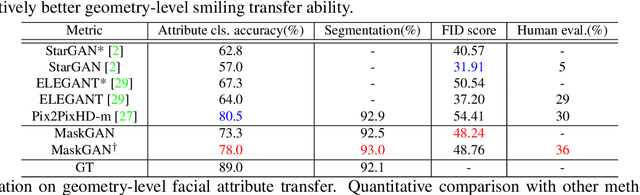
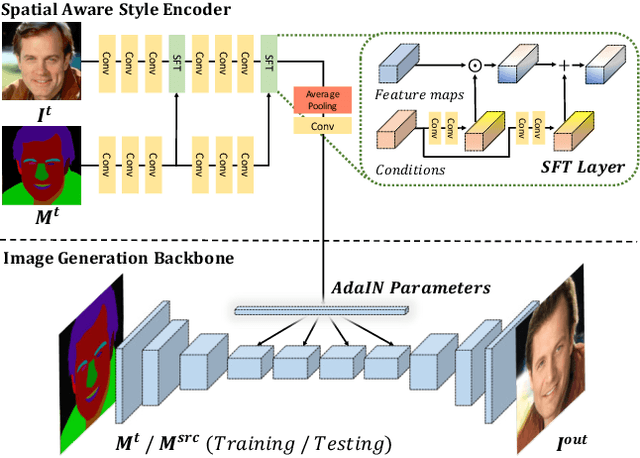
Facial image manipulation has achieved great progresses in recent years. However, previous methods either operate on a predefined set of face attributes or leave users little freedom to interactively manipulate images. To overcome these drawbacks, we propose a novel framework termed MaskGAN, enabling diverse and interactive face manipulation. Our key insight is that semantic masks serve as a suitable intermediate representation for flexible face manipulation with fidelity preservation. MaskGAN has two main components: 1) Dense Mapping Network, and 2) Editing Behavior Simulated Training. Specifically, Dense mapping network learns style mapping between a free-form user modified mask and a target image, enabling diverse generation results. Editing behavior simulated training models the user editing behavior on the source mask, making the overall framework more robust to various manipulated inputs. To facilitate extensive studies, we construct a large-scale high-resolution face dataset with fine-grained mask annotations named CelebAMask-HQ. MaskGAN is comprehensively evaluated on two challenging tasks: attribute transfer and style copy, demonstrating superior performance over other state-of-the-art methods. The code, models and dataset are available at \url{https://github.com/switchablenorms/CelebAMask-HQ}.