 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Understanding the Generative Capability of Adversarially Robust Classifiers
Aug 20, 2021
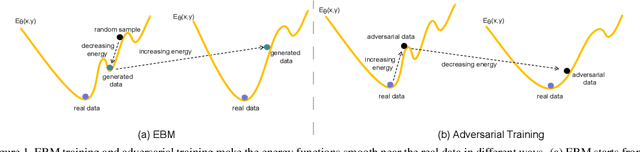
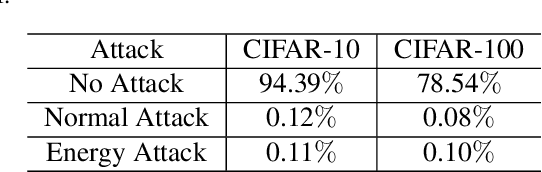
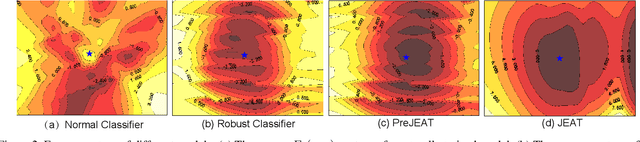
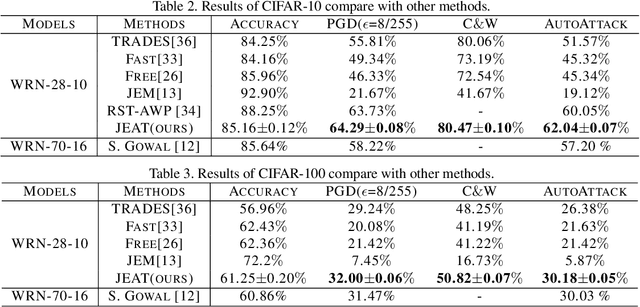
Recently, some works found an interesting phenomenon that adversarially robust classifiers can generate good images comparable to generative models. We investigate this phenomenon from an energy perspective and provide a novel explanation. We reformulate adversarial example generation, adversarial training, and image generation in terms of an energy function. We find that adversarial training contributes to obtaining an energy function that is flat and has low energy around the real data, which is the key for generative capability. Based on our new understanding, we further propose a better adversarial training method, Joint Energy Adversarial Training (JEAT), which can generate high-quality images and achieve new state-of-the-art robustness under a wide range of attacks. The Inception Score of the images (CIFAR-10) generated by JEAT is 8.80, much better than original robust classifiers (7.50). In particular, we achieve new state-of-the-art robustness on CIFAR-10 (from 57.20% to 62.04%) and CIFAR-100 (from 30.03% to 30.18%) without extra training data.
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021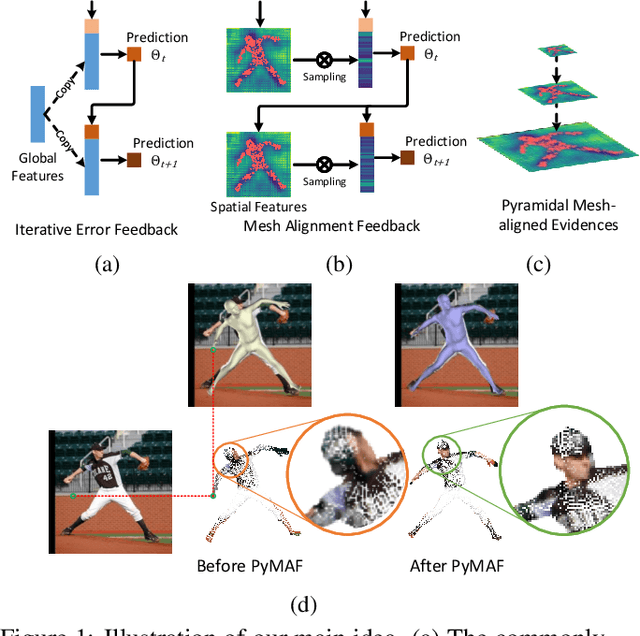
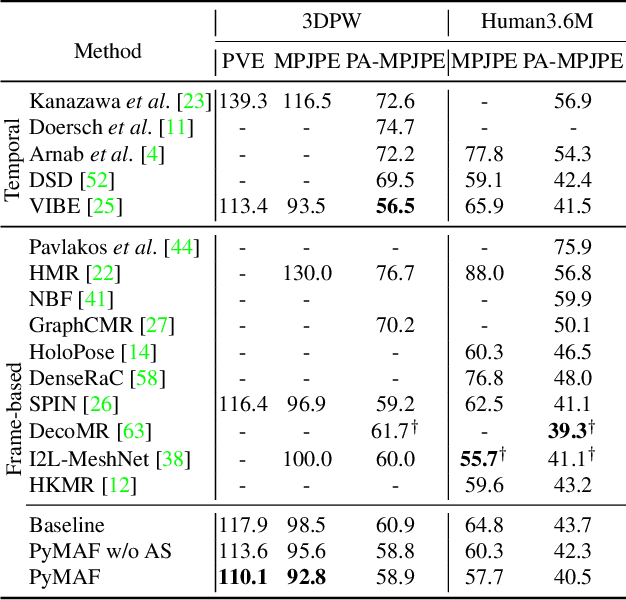
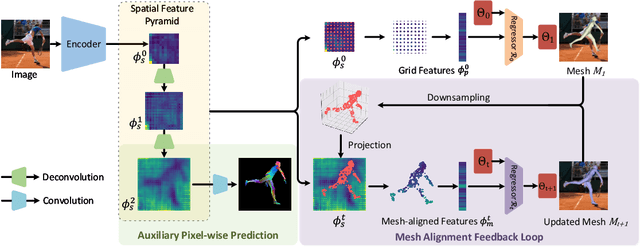
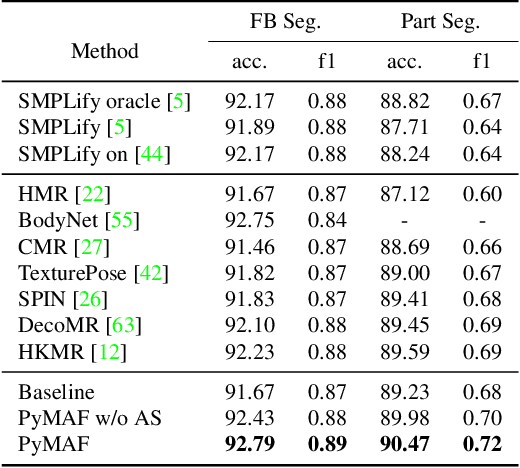
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .
Countering Adversarial Examples: Combining Input Transformation and Noisy Training
Jun 25, 2021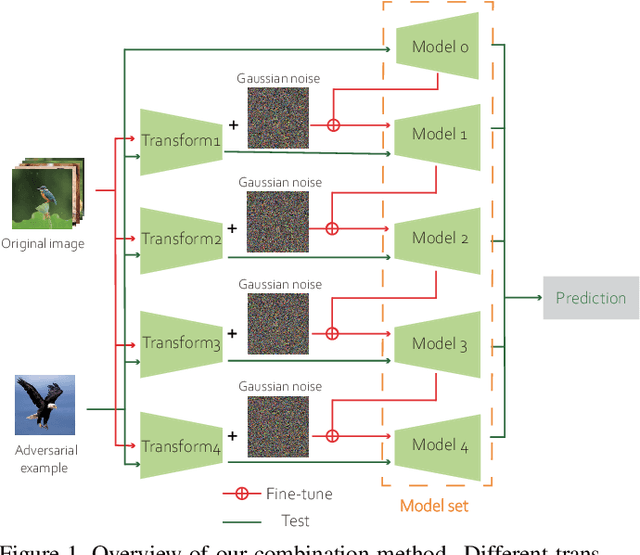
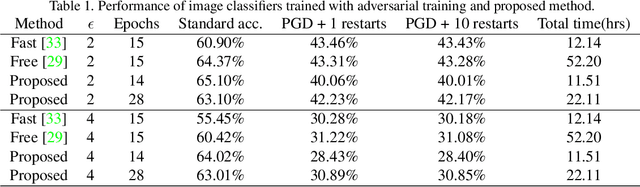
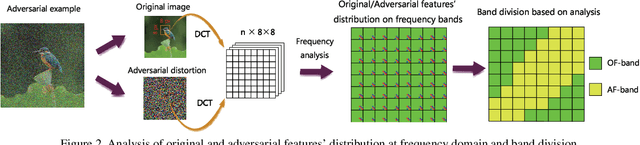
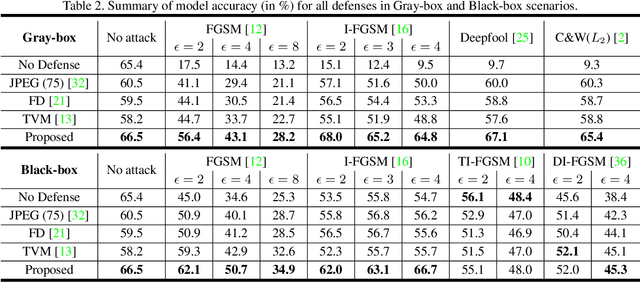
Recent studies have shown that neural network (NN) based image classifiers are highly vulnerable to adversarial examples, which poses a threat to security-sensitive image recognition task. Prior work has shown that JPEG compression can combat the drop in classification accuracy on adversarial examples to some extent. But, as the compression ratio increases, traditional JPEG compression is insufficient to defend those attacks but can cause an abrupt accuracy decline to the benign images. In this paper, with the aim of fully filtering the adversarial perturbations, we firstly make modifications to traditional JPEG compression algorithm which becomes more favorable for NN. Specifically, based on an analysis of the frequency coefficient, we design a NN-favored quantization table for compression. Considering compression as a data augmentation strategy, we then combine our model-agnostic preprocess with noisy training. We fine-tune the pre-trained model by training with images encoded at different compression levels, thus generating multiple classifiers. Finally, since lower (higher) compression ratio can remove both perturbations and original features slightly (aggressively), we use these trained multiple models for model ensemble. The majority vote of the ensemble of models is adopted as final predictions. Experiments results show our method can improve defense efficiency while maintaining original accuracy.
Deep HDR Hallucination for Inverse Tone Mapping
Jun 17, 2021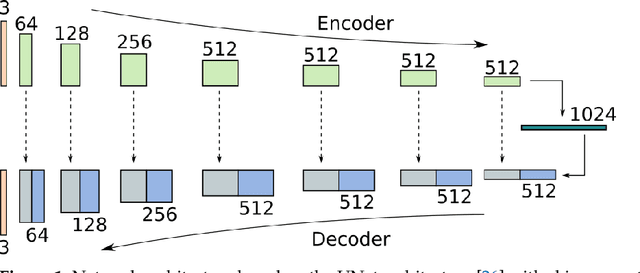
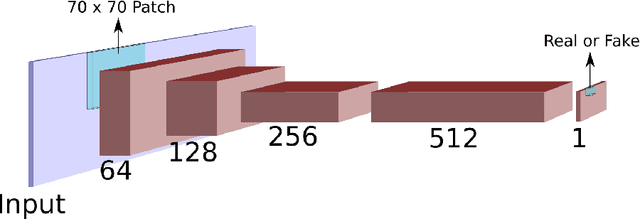
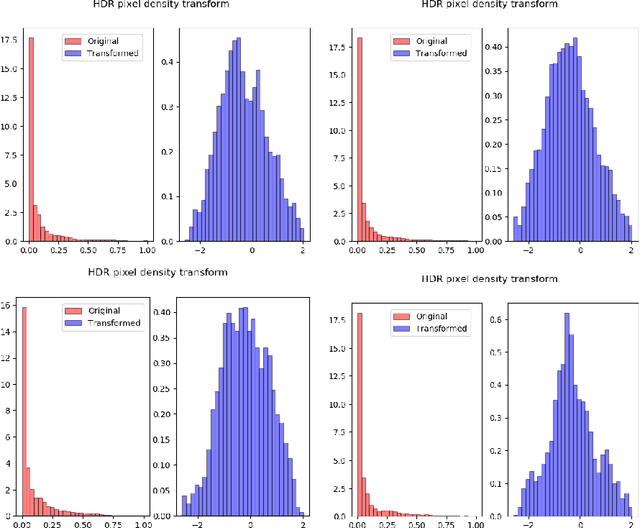

Inverse Tone Mapping (ITM) methods attempt to reconstruct High Dynamic Range (HDR) information from Low Dynamic Range (LDR) image content. The dynamic range of well-exposed areas must be expanded and any missing information due to over/under-exposure must be recovered (hallucinated). The majority of methods focus on the former and are relatively successful, while most attempts on the latter are not of sufficient quality, even ones based on Convolutional Neural Networks (CNNs). A major factor for the reduced inpainting quality in some works is the choice of loss function. Work based on Generative Adversarial Networks (GANs) shows promising results for image synthesis and LDR inpainting, suggesting that GAN losses can improve inverse tone mapping results. This work presents a GAN-based method that hallucinates missing information from badly exposed areas in LDR images and compares its efficacy with alternative variations. The proposed method is quantitatively competitive with state-of-the-art inverse tone mapping methods, providing good dynamic range expansion for well-exposed areas and plausible hallucinations for saturated and under-exposed areas. A density-based normalisation method, targeted for HDR content, is also proposed, as well as an HDR data augmentation method targeted for HDR hallucination.
Neural Style Transfer Improves 3D Cardiovascular MR Image Segmentation on Inconsistent Data
Sep 20, 2019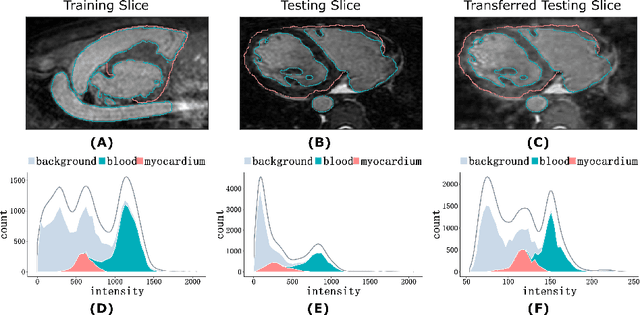
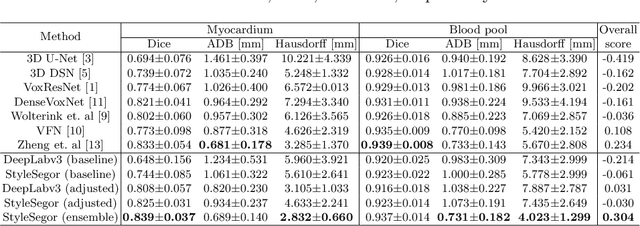
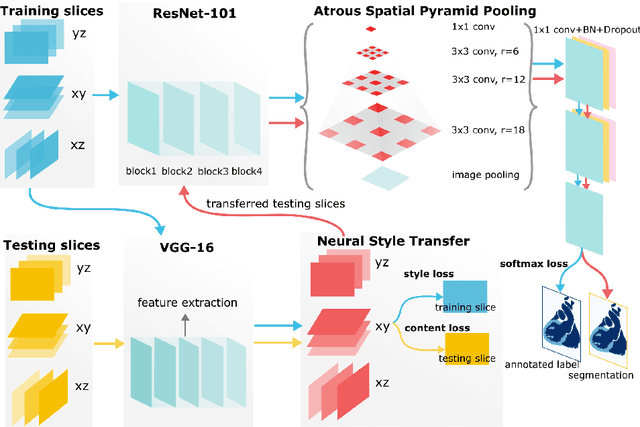
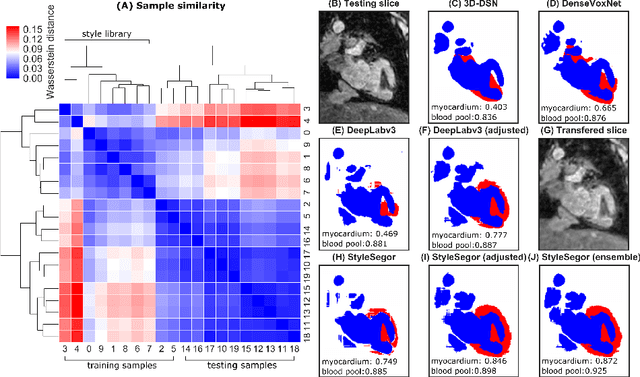
Three-dimensional medical image segmentation is one of the most important problems in medical image analysis and plays a key role in downstream diagnosis and treatment. Recent years, deep neural networks have made groundbreaking success in medical image segmentation problem. However, due to the high variance in instrumental parameters, experimental protocols, and subject appearances, the generalization of deep learning models is often hindered by the inconsistency in medical images generated by different machines and hospitals. In this work, we present StyleSegor, an efficient and easy-to-use strategy to alleviate this inconsistency issue. Specifically, neural style transfer algorithm is applied to unlabeled data in order to minimize the differences in image properties including brightness, contrast, texture, etc. between the labeled and unlabeled data. We also apply probabilistic adjustment on the network output and integrate multiple predictions through ensemble learning. On a publicly available whole heart segmentation benchmarking dataset from MICCAI HVSMR 2016 challenge, we have demonstrated an elevated dice accuracy surpassing current state-of-the-art method and notably, an improvement of the total score by 29.91\%. StyleSegor is thus corroborated to be an accurate tool for 3D whole heart segmentation especially on highly inconsistent data, and is available at https://github.com/horsepurve/StyleSegor.
Representation Memorization for Fast Learning New Knowledge without Forgetting
Aug 28, 2021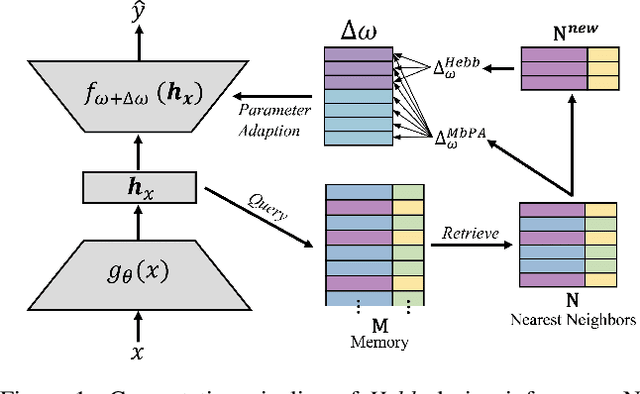
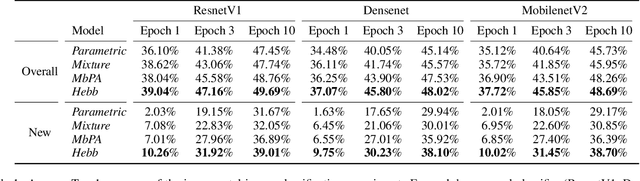
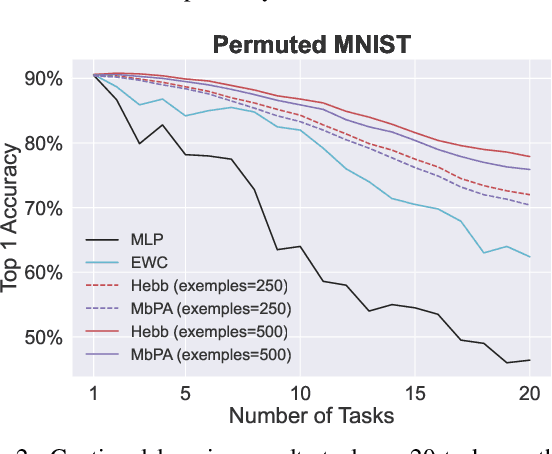
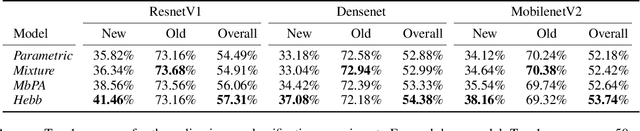
The ability to quickly learn new knowledge (e.g. new classes or data distributions) is a big step towards human-level intelligence. In this paper, we consider scenarios that require learning new classes or data distributions quickly and incrementally over time, as it often occurs in real-world dynamic environments. We propose "Memory-based Hebbian Parameter Adaptation" (Hebb) to tackle the two major challenges (i.e., catastrophic forgetting and sample efficiency) towards this goal in a unified framework. To mitigate catastrophic forgetting, Hebb augments a regular neural classifier with a continuously updated memory module to store representations of previous data. To improve sample efficiency, we propose a parameter adaptation method based on the well-known Hebbian theory, which directly "wires" the output network's parameters with similar representations retrieved from the memory. We empirically verify the superior performance of Hebb through extensive experiments on a wide range of learning tasks (image classification, language model) and learning scenarios (continual, incremental, online). We demonstrate that Hebb effectively mitigates catastrophic forgetting, and it indeed learns new knowledge better and faster than the current state-of-the-art.
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 01, 2021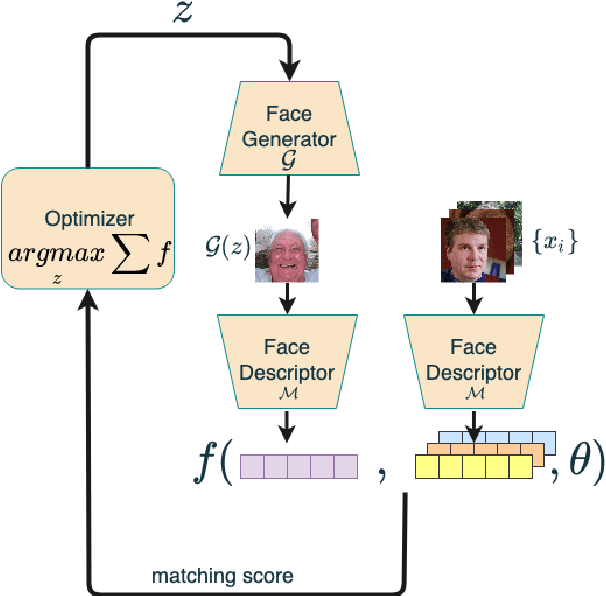


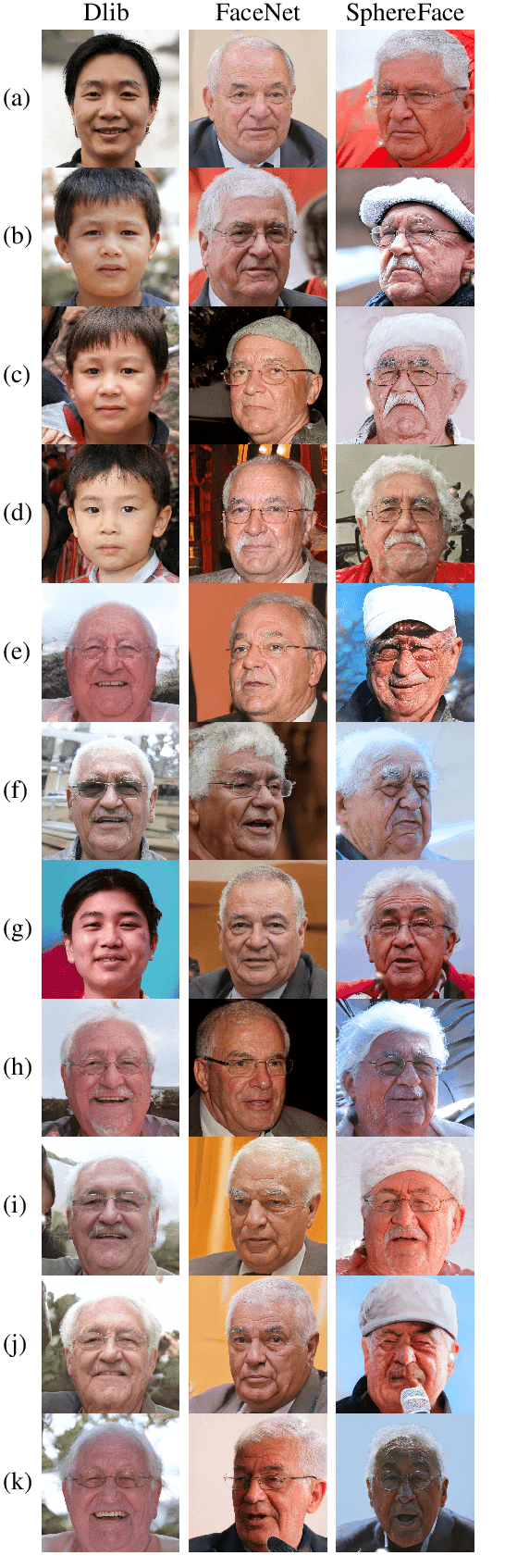
A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the population (over 40%) with less than 10 master faces, for three leading deep face recognition systems.
StyPath: Style-Transfer Data Augmentation For Robust Histology Image Classification
Jul 09, 2020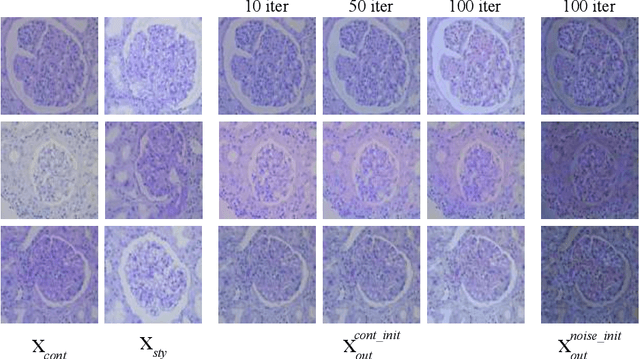
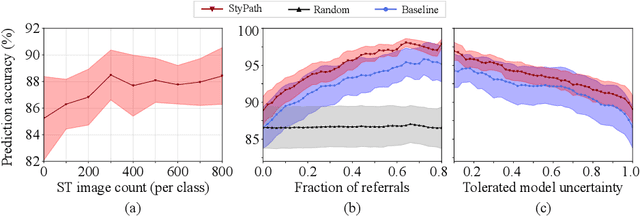
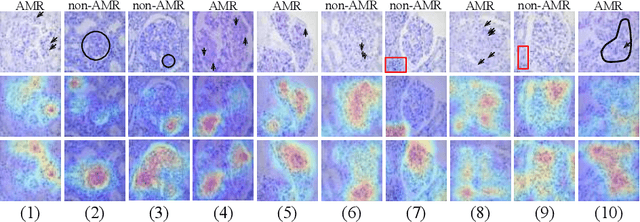
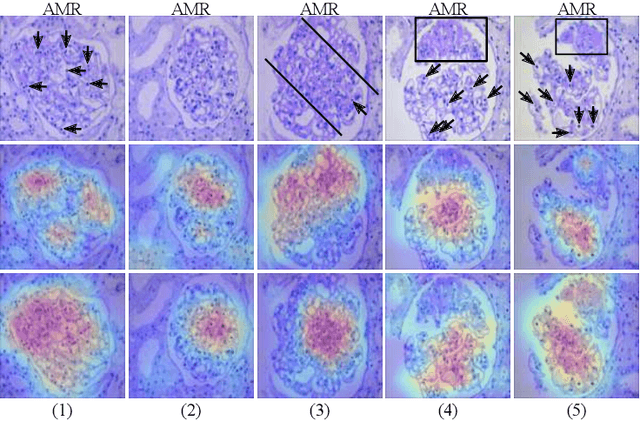
The classification of Antibody Mediated Rejection (AMR) in kidney transplant remains challenging even for experienced nephropathologists; this is partly because histological tissue stain analysis is often characterized by low inter-observer agreement and poor reproducibility. One of the implicated causes for inter-observer disagreement is the variability of tissue stain quality between (and within) pathology labs, coupled with the gradual fading of archival sections. Variations in stain colors and intensities can make tissue evaluation difficult for pathologists, ultimately affecting their ability to describe relevant morphological features. Being able to accurately predict the AMR status based on kidney histology images is crucial for improving patient treatment and care. We propose a novel pipeline to build robust deep neural networks for AMR classification based on StyPath, a histological data augmentation technique that leverages a light weight style-transfer algorithm as a means to reduce sample-specific bias. Each image was generated in 1.84 +- 0.03 seconds using a single GTX TITAN V gpu and pytorch, making it faster than other popular histological data augmentation techniques. We evaluated our model using a Monte Carlo (MC) estimate of Bayesian performance and generate an epistemic measure of uncertainty to compare both the baseline and StyPath augmented models. We also generated Grad-CAM representations of the results which were assessed by an experienced nephropathologist; we used this qualitative analysis to elucidate on the assumptions being made by each model. Our results imply that our style-transfer augmentation technique improves histological classification performance (reducing error from 14.8% to 11.5%) and generalization ability.
Efficient Deep Learning of Non-local Features for Hyperspectral Image Classification
Aug 02, 2020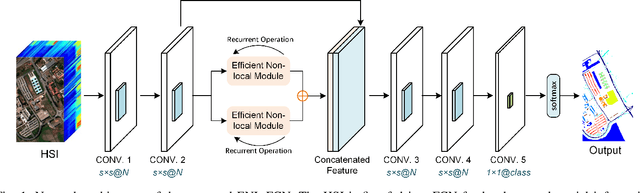
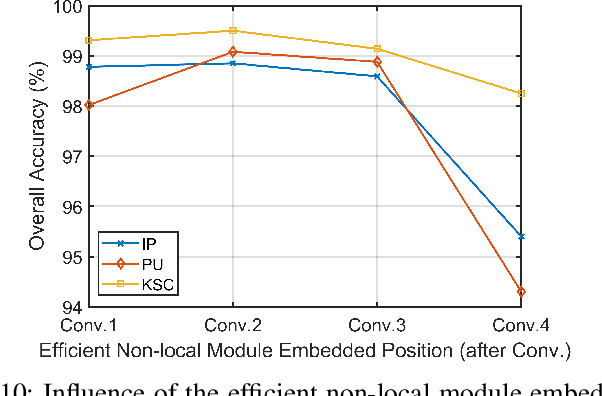
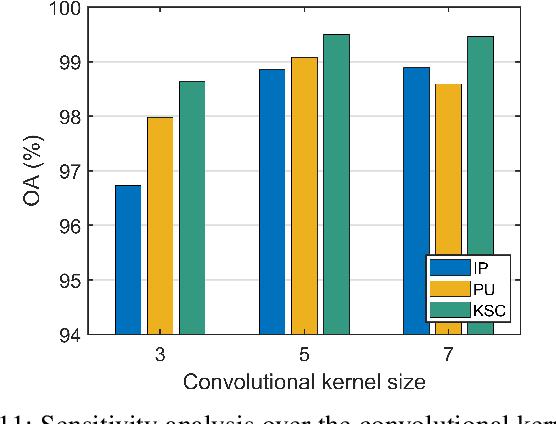
Deep learning based methods, such as Convolution Neural Network (CNN), have demonstrated their efficiency in hyperspectral image (HSI) classification. These methods can automatically learn spectral-spatial discriminative features within local patches. However, for each pixel in an HSI, it is not only related to its nearby pixels but also has connections to pixels far away from itself. Therefore, to incorporate the long-range contextual information, a deep fully convolutional network (FCN) with an efficient non-local module, named ENL-FCN, is proposed for HSI classification. In the proposed framework, a deep FCN considers an entire HSI as input and extracts spectral-spatial information in a local receptive field. The efficient non-local module is embedded in the network as a learning unit to capture the long-range contextual information. Different from the traditional non-local neural networks, the long-range contextual information is extracted in a specially designed criss-cross path for computation efficiency. Furthermore, by using a recurrent operation, each pixel's response is aggregated from all pixels of HSI. The benefits of our proposed ENL-FCN are threefold: 1) the long-range contextual information is incorporated effectively, 2) the efficient module can be freely embedded in a deep neural network in a plug-and-play fashion, and 3) it has much fewer learning parameters and requires less computational resources. The experiments conducted on three popular HSI datasets demonstrate that the proposed method achieves state-of-the-art classification performance with lower computational cost in comparison with several leading deep neural networks for HSI.
Deep ensembles based on Stochastic Activation Selection for Polyp Segmentation
Apr 07, 2021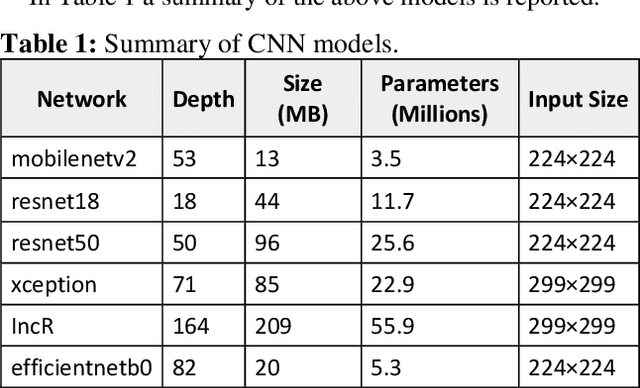
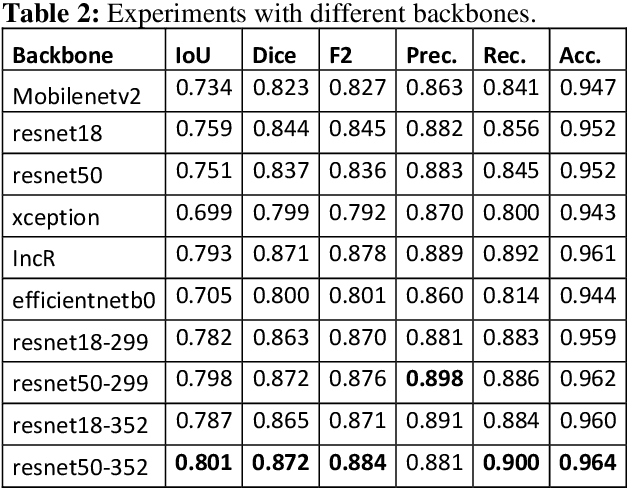
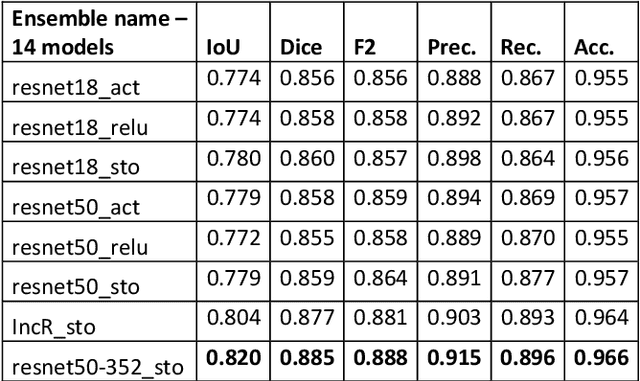
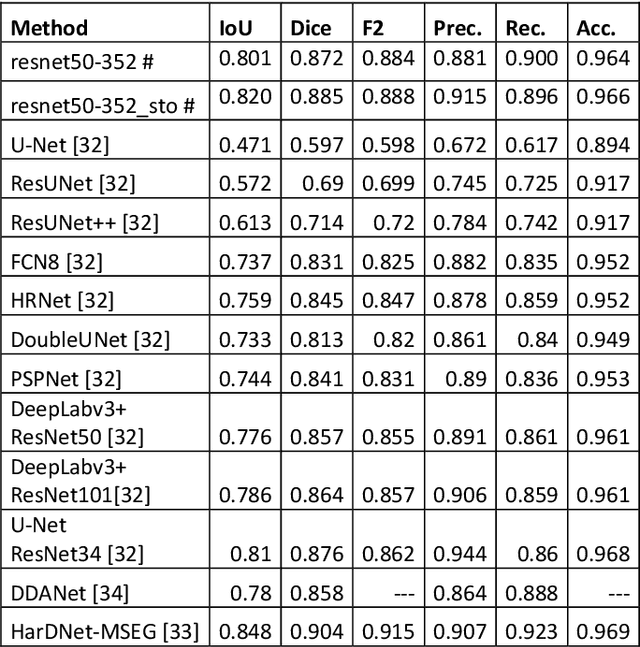
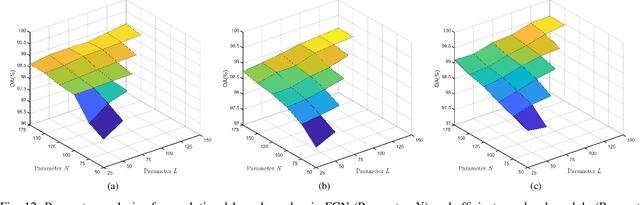
Semantic segmentation has a wide array of applications ranging from medical-image analysis, scene understanding, autonomous driving and robotic navigation. This work deals with medical image segmentation and in particular with accurate polyp detection and segmentation during colonoscopy examinations. Several convolutional neural network architectures have been proposed to effectively deal with this task and with the problem of segmenting objects at different scale input. The basic architecture in image segmentation consists of an encoder and a decoder: the first uses convolutional filters to extract features from the image, the second is responsible for generating the final output. In this work, we compare some variant of the DeepLab architecture obtained by varying the decoder backbone. We compare several decoder architectures, including ResNet, Xception, EfficentNet, MobileNet and we perturb their layers by substituting ReLU activation layers with other functions. The resulting methods are used to create deep ensembles which are shown to be very effective. Our experimental evaluations show that our best ensemble produces good segmentation results by achieving high evaluation scores with a dice coefficient of 0.884, and a mean Intersection over Union (mIoU) of 0.818 for the Kvasir-SEG dataset. To improve reproducibility and research efficiency the MATLAB source code used for this research is available at GitHub: https://github.com/LorisNanni.