 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveCtrl: Conditioned Sim-to-Real Driving Video Generation
May 14, 2026Large-scale labelled driving video data is essential for training autonomous driving systems. Although simulation offers scalable and fully annotated data, the domain gap between synthetic and real-world driving videos significantly limits its utility for downstream deployment. Existing video generation methods are not well-suited for this task, as they fail to simultaneously preserve scene structure, object dynamics, temporal consistency, and visual realism, all of which are critical for maintaining annotation validity in generated data. In this paper, we present DriveCtrl, a depth-conditioned controllable sim-to-real video generation framework for realistic driving video synthesis. Built upon a pretrained video foundation model, DriveCtrl introduces a structure-aware adapter that enables depth-guided generation while preserving the scene layout and motion patterns of the source simulation, producing temporally coherent driving videos that remain aligned with the original simulated sequences. We further introduce a scalable data generation pipeline that transforms simulator videos into realistic driving footage matching the visual style of a target real-world dataset. The pipeline supports three conditioning signals: structural depth, reference-dataset style, and text prompts, while preserving frame-level annotations for downstream perception tasks. To better assess this task, we propose a driving-domain-specific knowledge-informed evaluation metric called Driving Video Realism Score (DVRS) that assesses the realism of generated videos. Experiments demonstrate that DriveCtrl consistently outperforms the base model and competing alternatives in realism, temporal quality, and perception task performance, substantially narrowing the sim-to-real gap for driving video generation.
AURORA-KITTI: Any-Weather Depth Completion and Denoising in the Wild
Mar 16, 2026Robust depth completion is fundamental to real-world 3D scene understanding, yet existing RGB-LiDAR fusion methods degrade significantly under adverse weather, where both camera images and LiDAR measurements suffer from weather-induced corruption. In this paper, we introduce AURORA-KITTI, the first large-scale multi-modal, multi-weather benchmark for robust depth completion in the wild. We further formulate Depth Completion and Denoising (DCD) as a unified task that jointly reconstructs a dense depth map from corrupted sparse inputs while suppressing weather-induced noise. AURORA-KITTI contains over \textit{82K} weather-consistent RGBL pairs with metric depth ground truth, spanning diverse weather types, three severity levels, day and night scenes, paired clean references, lens occlusion conditions, and textual descriptions. Moreover, we introduce DDCD, an efficient distillation-based baseline that leverages depth foundation models to inject clean structural priors into in-the-wild DCD training. DDCD achieves state-of-the-art performance on AURORA-KITTI and the real-world DENSE dataset while maintaining efficiency. Notably, our results further show that weather-aware, physically consistent data contributes more to robustness than architectural modifications alone. Data and code will be released upon publication.
CapHDR2IR: Caption-Driven Transfer from Visible Light to Infrared Domain
Nov 25, 2024



Infrared (IR) imaging offers advantages in several fields due to its unique ability of capturing content in extreme light conditions. However, the demanding hardware requirements of high-resolution IR sensors limit its widespread application. As an alternative, visible light can be used to synthesize IR images but this causes a loss of fidelity in image details and introduces inconsistencies due to lack of contextual awareness of the scene. This stems from a combination of using visible light with a standard dynamic range, especially under extreme lighting, and a lack of contextual awareness can result in pseudo-thermal-crossover artifacts. This occurs when multiple objects with similar temperatures appear indistinguishable in the training data, further exacerbating the loss of fidelity. To solve this challenge, this paper proposes CapHDR2IR, a novel framework incorporating vision-language models using high dynamic range (HDR) images as inputs to generate IR images. HDR images capture a wider range of luminance variations, ensuring reliable IR image generation in different light conditions. Additionally, a dense caption branch integrates semantic understanding, resulting in more meaningful and discernible IR outputs. Extensive experiments on the HDRT dataset show that the proposed CapHDR2IR achieves state-of-the-art performance compared with existing general domain transfer methods and those tailored for visible-to-infrared image translation.
Luminance Component Analysis for Exposure Correction
Nov 25, 2024



Exposure correction methods aim to adjust the luminance while maintaining other luminance-unrelated information. However, current exposure correction methods have difficulty in fully separating luminance-related and luminance-unrelated components, leading to distortions in color, loss of detail, and requiring extra restoration procedures. Inspired by principal component analysis (PCA), this paper proposes an exposure correction method called luminance component analysis (LCA). LCA applies the orthogonal constraint to a U-Net structure to decouple luminance-related and luminance-unrelated features. With decoupled luminance-related features, LCA adjusts only the luminance-related components while keeping the luminance-unrelated components unchanged. To optimize the orthogonal constraint problem, LCA employs a geometric optimization algorithm, which converts the constrained problem in Euclidean space to an unconstrained problem in orthogonal Stiefel manifolds. Extensive experiments show that LCA can decouple the luminance feature from the RGB color space. Moreover, LCA achieves the best PSNR (21.33) and SSIM (0.88) in the exposure correction dataset with 28.72 FPS.
Good Data Is All Imitation Learning Needs
Sep 26, 2024



In this paper, we address the limitations of traditional teacher-student models, imitation learning, and behaviour cloning in the context of Autonomous/Automated Driving Systems (ADS), where these methods often struggle with incomplete coverage of real-world scenarios. To enhance the robustness of such models, we introduce the use of Counterfactual Explanations (CFEs) as a novel data augmentation technique for end-to-end ADS. CFEs, by generating training samples near decision boundaries through minimal input modifications, lead to a more comprehensive representation of expert driver strategies, particularly in safety-critical scenarios. This approach can therefore help improve the model's ability to handle rare and challenging driving events, such as anticipating darting out pedestrians, ultimately leading to safer and more trustworthy decision-making for ADS. Our experiments in the CARLA simulator demonstrate that CF-Driver outperforms the current state-of-the-art method, achieving a higher driving score and lower infraction rates. Specifically, CF-Driver attains a driving score of 84.2, surpassing the previous best model by 15.02 percentage points. These results highlight the effectiveness of incorporating CFEs in training end-to-end ADS. To foster further research, the CF-Driver code is made publicly available.
HDRT: Infrared Capture for HDR Imaging
Jun 08, 2024
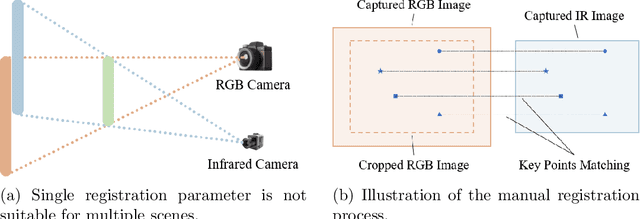
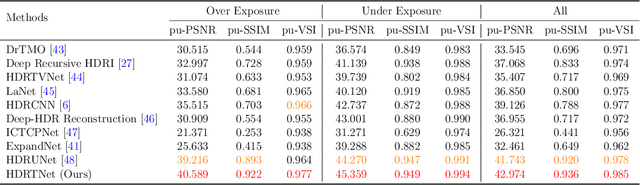
Capturing real world lighting is a long standing challenge in imaging and most practical methods acquire High Dynamic Range (HDR) images by either fusing multiple exposures, or boosting the dynamic range of Standard Dynamic Range (SDR) images. Multiple exposure capture is problematic as it requires longer capture times which can often lead to ghosting problems. The main alternative, inverse tone mapping is an ill-defined problem that is especially challenging as single captured exposures usually contain clipped and quantized values, and are therefore missing substantial amounts of content. To alleviate this, we propose a new approach, High Dynamic Range Thermal (HDRT), for HDR acquisition using a separate, commonly available, thermal infrared (IR) sensor. We propose a novel deep neural method (HDRTNet) which combines IR and SDR content to generate HDR images. HDRTNet learns to exploit IR features linked to the RGB image and the IR-specific parameters are subsequently used in a dual branch method that fuses features at shallow layers. This produces an HDR image that is significantly superior to that generated using naive fusion approaches. To validate our method, we have created the first HDR and thermal dataset, and performed extensive experiments comparing HDRTNet with the state-of-the-art. We show substantial quantitative and qualitative quality improvements on both over- and under-exposed images, showing that our approach is robust to capturing in multiple different lighting conditions.
Semantic Aware Diffusion Inverse Tone Mapping
May 24, 2024



The range of real-world scene luminance is larger than the capture capability of many digital camera sensors which leads to details being lost in captured images, most typically in bright regions. Inverse tone mapping attempts to boost these captured Standard Dynamic Range (SDR) images back to High Dynamic Range (HDR) by creating a mapping that linearizes the well exposed values from the SDR image, and provides a luminance boost to the clipped content. However, in most cases, the details in the clipped regions cannot be recovered or estimated. In this paper, we present a novel inverse tone mapping approach for mapping SDR images to HDR that generates lost details in clipped regions through a semantic-aware diffusion based inpainting approach. Our method proposes two major contributions - first, we propose to use a semantic graph to guide SDR diffusion based inpainting in masked regions in a saturated image. Second, drawing inspiration from traditional HDR imaging and bracketing methods, we propose a principled formulation to lift the SDR inpainted regions to HDR that is compatible with generative inpainting methods. Results show that our method demonstrates superior performance across different datasets on objective metrics, and subjective experiments show that the proposed method matches (and in most cases outperforms) state-of-art inverse tone mapping operators in terms of objective metrics and outperforms them for visual fidelity.
SAFE-RL: Saliency-Aware Counterfactual Explainer for Deep Reinforcement Learning Policies
Apr 28, 2024



While Deep Reinforcement Learning (DRL) has emerged as a promising solution for intricate control tasks, the lack of explainability of the learned policies impedes its uptake in safety-critical applications, such as automated driving systems (ADS). Counterfactual (CF) explanations have recently gained prominence for their ability to interpret black-box Deep Learning (DL) models. CF examples are associated with minimal changes in the input, resulting in a complementary output by the DL model. Finding such alternations, particularly for high-dimensional visual inputs, poses significant challenges. Besides, the temporal dependency introduced by the reliance of the DRL agent action on a history of past state observations further complicates the generation of CF examples. To address these challenges, we propose using a saliency map to identify the most influential input pixels across the sequence of past observed states by the agent. Then, we feed this map to a deep generative model, enabling the generation of plausible CFs with constrained modifications centred on the salient regions. We evaluate the effectiveness of our framework in diverse domains, including ADS, Atari Pong, Pacman and space-invaders games, using traditional performance metrics such as validity, proximity and sparsity. Experimental results demonstrate that this framework generates more informative and plausible CFs than the state-of-the-art for a wide range of environments and DRL agents. In order to foster research in this area, we have made our datasets and codes publicly available at https://github.com/Amir-Samadi/SAFE-RL.
Exploring Generative AI for Sim2Real in Driving Data Synthesis
Apr 14, 2024



Datasets are essential for training and testing vehicle perception algorithms. However, the collection and annotation of real-world images is time-consuming and expensive. Driving simulators offer a solution by automatically generating various driving scenarios with corresponding annotations, but the simulation-to-reality (Sim2Real) domain gap remains a challenge. While most of the Generative Artificial Intelligence (AI) follows the de facto Generative Adversarial Nets (GANs)-based methods, the recent emerging diffusion probabilistic models have not been fully explored in mitigating Sim2Real challenges for driving data synthesis. To explore the performance, this paper applied three different generative AI methods to leverage semantic label maps from a driving simulator as a bridge for the creation of realistic datasets. A comparative analysis of these methods is presented from the perspective of image quality and perception. New synthetic datasets, which include driving images and auto-generated high-quality annotations, are produced with low costs and high scene variability. The experimental results show that although GAN-based methods are adept at generating high-quality images when provided with manually annotated labels, ControlNet produces synthetic datasets with fewer artefacts and more structural fidelity when using simulator-generated labels. This suggests that the diffusion-based approach may provide improved stability and an alternative method for addressing Sim2Real challenges.
Taming Transformers for Realistic Lidar Point Cloud Generation
Apr 08, 2024



Diffusion Models (DMs) have achieved State-Of-The-Art (SOTA) results in the Lidar point cloud generation task, benefiting from their stable training and iterative refinement during sampling. However, DMs often fail to realistically model Lidar raydrop noise due to their inherent denoising process. To retain the strength of iterative sampling while enhancing the generation of raydrop noise, we introduce LidarGRIT, a generative model that uses auto-regressive transformers to iteratively sample the range images in the latent space rather than image space. Furthermore, LidarGRIT utilises VQ-VAE to separately decode range images and raydrop masks. Our results show that LidarGRIT achieves superior performance compared to SOTA models on KITTI-360 and KITTI odometry datasets. Code available at:https://github.com/hamedhaghighi/LidarGRIT.