 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AD-GAN: End-to-end Unsupervised Nuclei Segmentation with Aligned Disentangling Training
Jul 23, 2021

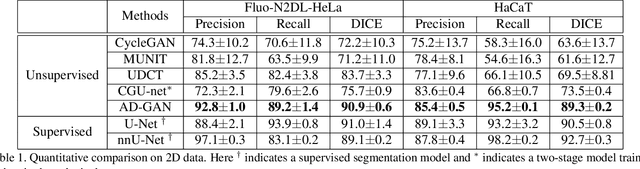
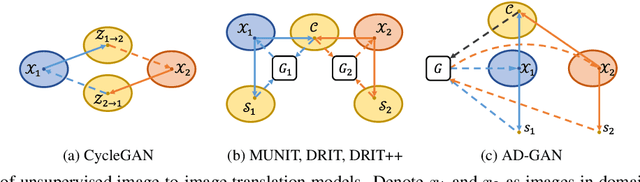
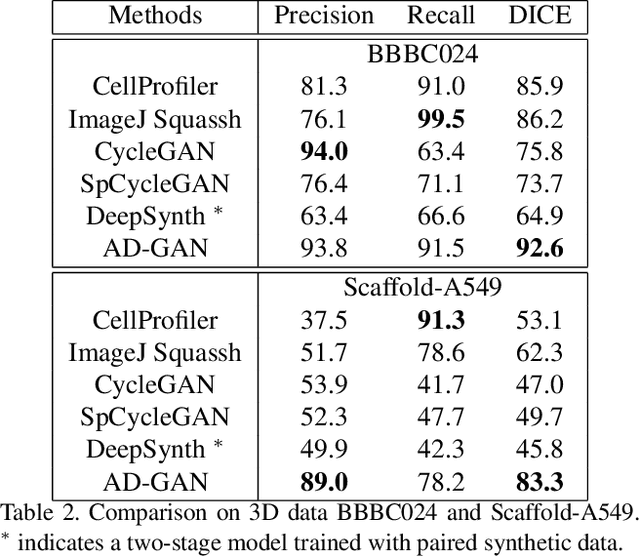
We consider unsupervised cell nuclei segmentation in this paper. Exploiting the recently-proposed unpaired image-to-image translation between cell nuclei images and randomly synthetic masks, existing approaches, e.g., CycleGAN, have achieved encouraging results. However, these methods usually take a two-stage pipeline and fail to learn end-to-end in cell nuclei images. More seriously, they could lead to the lossy transformation problem, i.e., the content inconsistency between the original images and the corresponding segmentation output. To address these limitations, we propose a novel end-to-end unsupervised framework called Aligned Disentangling Generative Adversarial Network (AD-GAN). Distinctively, AD-GAN introduces representation disentanglement to separate content representation (the underling spatial structure) from style representation (the rendering of the structure). With this framework, spatial structure can be preserved explicitly, enabling a significant reduction of macro-level lossy transformation. We also propose a novel training algorithm able to align the disentangled content in the latent space to reduce micro-level lossy transformation. Evaluations on real-world 2D and 3D datasets show that AD-GAN substantially outperforms the other comparison methods and the professional software both quantitatively and qualitatively. Specifically, the proposed AD-GAN leads to significant improvement over the current best unsupervised methods by an average 17.8% relatively (w.r.t. the metric DICE) on four cell nuclei datasets. As an unsupervised method, AD-GAN even performs competitive with the best supervised models, taking a further leap towards end-to-end unsupervised nuclei segmentation.
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
Jun 02, 2021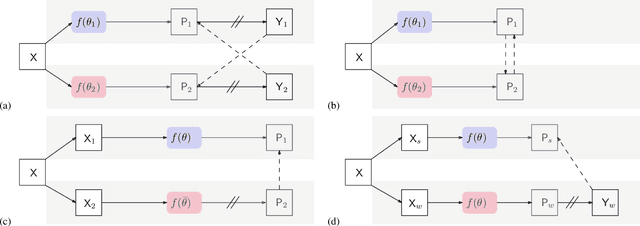
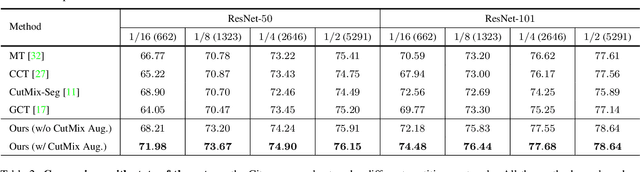
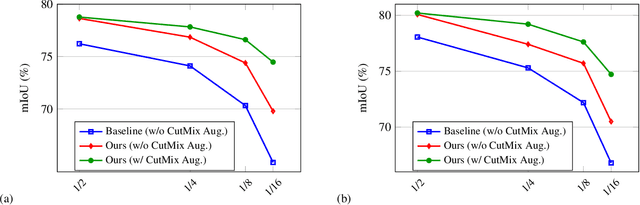
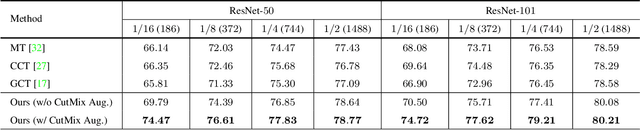
In this paper, we study the semi-supervised semantic segmentation problem via exploring both labeled data and extra unlabeled data. We propose a novel consistency regularization approach, called cross pseudo supervision (CPS). Our approach imposes the consistency on two segmentation networks perturbed with different initialization for the same input image. The pseudo one-hot label map, output from one perturbed segmentation network, is used to supervise the other segmentation network with the standard cross-entropy loss, and vice versa. The CPS consistency has two roles: encourage high similarity between the predictions of two perturbed networks for the same input image, and expand training data by using the unlabeled data with pseudo labels. Experiment results show that our approach achieves the state-of-the-art semi-supervised segmentation performance on Cityscapes and PASCAL VOC 2012.
Self-Supervised Learning for Gastritis Detection with Gastric X-Ray Images
Apr 07, 2021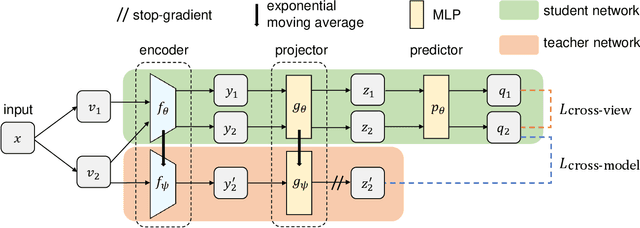
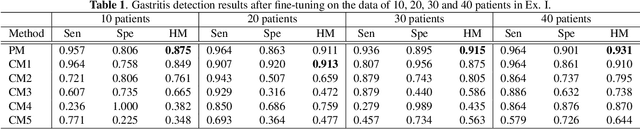
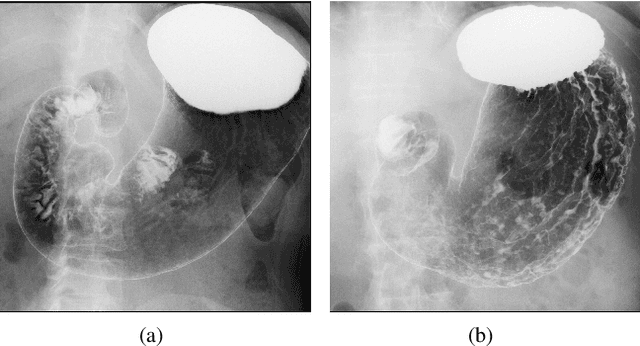
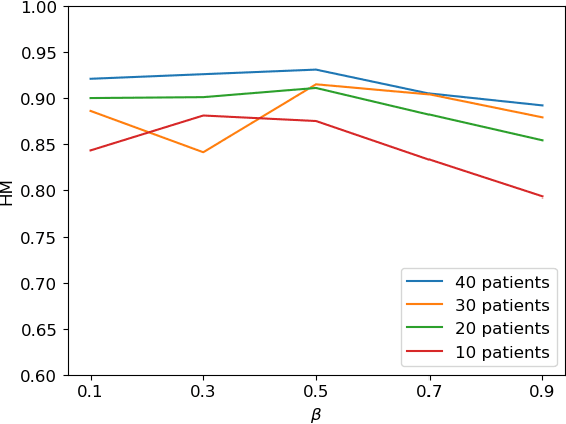
We propose a novel self-supervised learning method for medical image analysis. Great progress has been made in medical image analysis because of the development of supervised learning based on deep convolutional neural networks. However, annotating complex medical images usually requires expert knowledge, making it difficult for a wide range of real-world applications ($e.g.$, computer-aided diagnosis systems). Our self-supervised learning method introduces a cross-view loss and a cross-model loss to solve the insufficient available annotations in medical image analysis. Experimental results show that our method can achieve high detection performance for gastritis detection with only a small number of annotations.
Coherent Semantic Attention for Image Inpainting
May 29, 2019
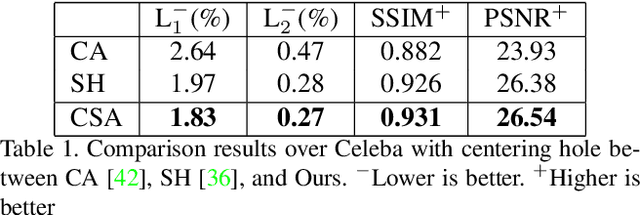
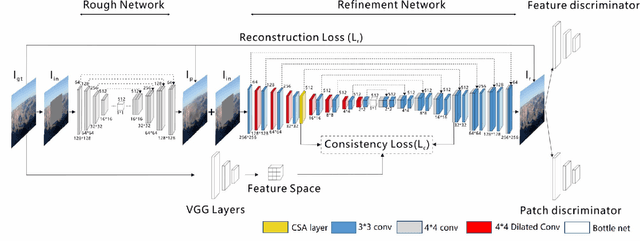
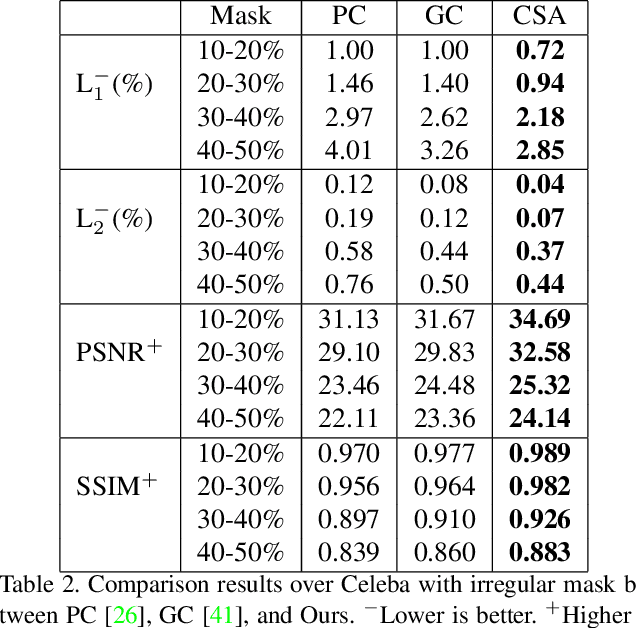
The latest deep learning-based approaches have shown promising results for the challenging task of inpainting missing regions of an image. However, the existing methods often generate contents with blurry textures and distorted structures due to the discontinuity of the local pixels. From a semantic-level perspective, the local pixel discontinuity is mainly because these methods ignore the semantic relevance and feature continuity of hole regions. To handle this problem, we investigate the human behavior in repairing pictures and propose a fined deep generative model-based approach with a novel coherent semantic attention (CSA) layer, which can not only preserve contextual structure but also make more effective predictions of missing parts by modeling the semantic relevance between the holes features. The task is divided into rough, refinement as two steps and model each step with a neural network under the U-Net architecture, where the CSA layer is embedded into the encoder of refinement step. To stabilize the network training process and promote the CSA layer to learn more effective parameters, we propose a consistency loss to enforce the both the CSA layer and the corresponding layer of the CSA in decoder to be close to the VGG feature layer of a ground truth image simultaneously. The experiments on CelebA, Places2, and Paris StreetView datasets have validated the effectiveness of our proposed methods in image inpainting tasks and can obtain images with a higher quality as compared with the existing state-of-the-art approaches.
Cascaded Parallel Filtering for Memory-Efficient Image-Based Localization
Aug 16, 2019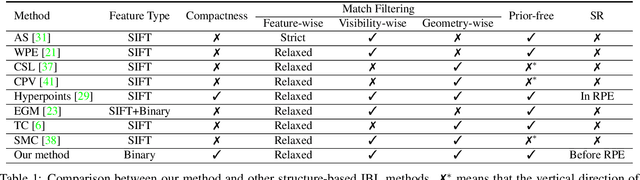
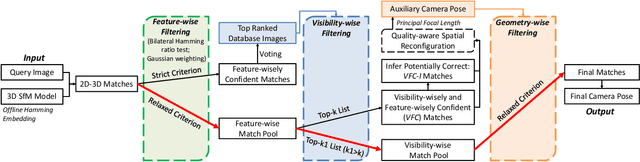
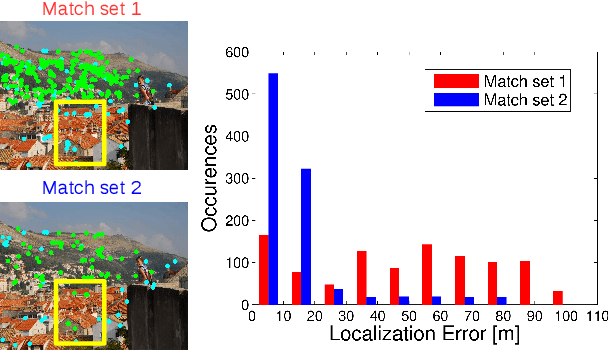
Image-based localization (IBL) aims to estimate the 6DOF camera pose for a given query image. The camera pose can be computed from 2D-3D matches between a query image and Structure-from-Motion (SfM) models. Despite recent advances in IBL, it remains difficult to simultaneously resolve the memory consumption and match ambiguity problems of large SfM models. In this work, we propose a cascaded parallel filtering method that leverages the feature, visibility and geometry information to filter wrong matches under binary feature representation. The core idea is that we divide the challenging filtering task into two parallel tasks before deriving an auxiliary camera pose for final filtering. One task focuses on preserving potentially correct matches, while another focuses on obtaining high quality matches to facilitate subsequent more powerful filtering. Moreover, our proposed method improves the localization accuracy by introducing a quality-aware spatial reconfiguration method and a principal focal length enhanced pose estimation method. Experimental results on real-world datasets demonstrate that our method achieves very competitive localization performances in a memory-efficient manner.
A Deep Learning Localization Method for Measuring Abdominal Muscle Dimensions in Ultrasound Images
Sep 30, 2021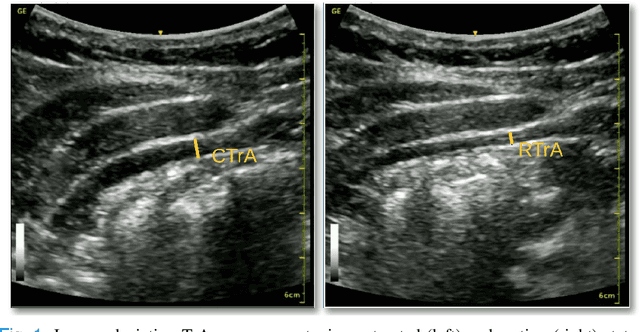
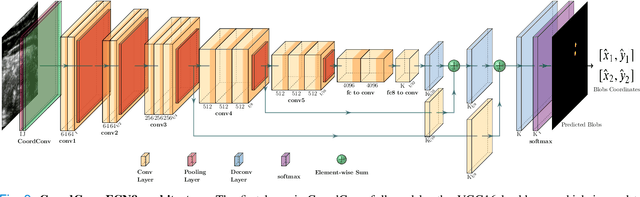

Health professionals extensively use Two- Dimensional (2D) Ultrasound (US) videos and images to visualize and measure internal organs for various purposes including evaluation of muscle architectural changes. US images can be used to measure abdominal muscles dimensions for the diagnosis and creation of customized treatment plans for patients with Low Back Pain (LBP), however, they are difficult to interpret. Due to high variability, skilled professionals with specialized training are required to take measurements to avoid low intra-observer reliability. This variability stems from the challenging nature of accurately finding the correct spatial location of measurement endpoints in abdominal US images. In this paper, we use a Deep Learning (DL) approach to automate the measurement of the abdominal muscle thickness in 2D US images. By treating the problem as a localization task, we develop a modified Fully Convolutional Network (FCN) architecture to generate blobs of coordinate locations of measurement endpoints, similar to what a human operator does. We demonstrate that using the TrA400 US image dataset, our network achieves a Mean Absolute Error (MAE) of 0.3125 on the test set, which almost matches the performance of skilled ultrasound technicians. Our approach can facilitate next steps for automating the process of measurements in 2D US images, while reducing inter-observer as well as intra-observer variability for more effective clinical outcomes.
A General Decoupled Learning Framework for Parameterized Image Operators
Jul 11, 2019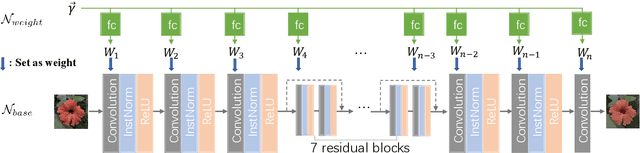
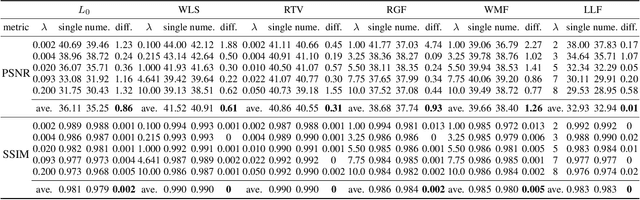
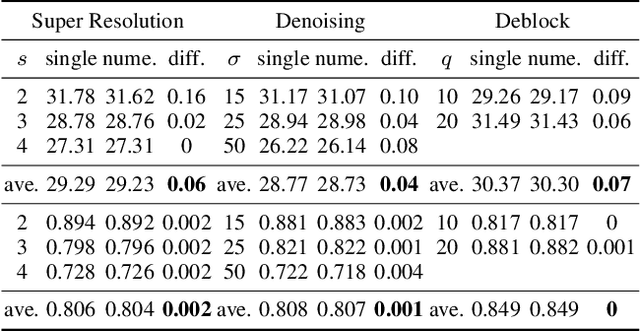

Many different deep networks have been used to approximate, accelerate or improve traditional image operators. Among these traditional operators, many contain parameters which need to be tweaked to obtain the satisfactory results, which we refer to as parameterized image operators. However, most existing deep networks trained for these operators are only designed for one specific parameter configuration, which does not meet the needs of real scenarios that usually require flexible parameters settings. To overcome this limitation, we propose a new decoupled learning algorithm to learn from the operator parameters to dynamically adjust the weights of a deep network for image operators, denoted as the base network. The learned algorithm is formed as another network, namely the weight learning network, which can be end-to-end jointly trained with the base network. Experiments demonstrate that the proposed framework can be successfully applied to many traditional parameterized image operators. To accelerate the parameter tuning for practical scenarios, the proposed framework can be further extended to dynamically change the weights of only one single layer of the base network while sharing most computation cost. We demonstrate that this cheap parameter-tuning extension of the proposed decoupled learning framework even outperforms the state-of-the-art alternative approaches.
Multi-Modal Association based Grouping for Form Structure Extraction
Jul 09, 2021
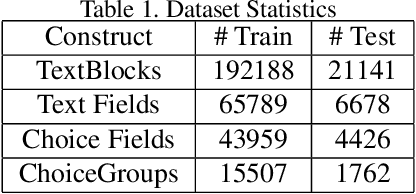

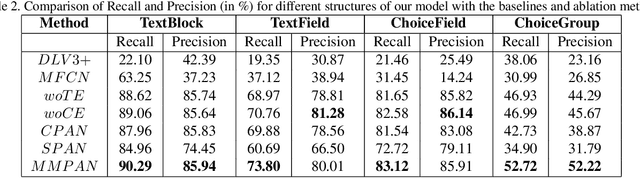
Document structure extraction has been a widely researched area for decades. Recent work in this direction has been deep learning-based, mostly focusing on extracting structure using fully convolution NN through semantic segmentation. In this work, we present a novel multi-modal approach for form structure extraction. Given simple elements such as textruns and widgets, we extract higher-order structures such as TextBlocks, Text Fields, Choice Fields, and Choice Groups, which are essential for information collection in forms. To achieve this, we obtain a local image patch around each low-level element (reference) by identifying candidate elements closest to it. We process textual and spatial representation of candidates sequentially through a BiLSTM to obtain context-aware representations and fuse them with image patch features obtained by processing it through a CNN. Subsequently, the sequential decoder takes this fused feature vector to predict the association type between reference and candidates. These predicted associations are utilized to determine larger structures through connected components analysis. Experimental results show the effectiveness of our approach achieving a recall of 90.29%, 73.80%, 83.12%, and 52.72% for the above structures, respectively, outperforming semantic segmentation baselines significantly. We show the efficacy of our method through ablations, comparing it against using individual modalities. We also introduce our new rich human-annotated Forms Dataset.
Attention Control with Metric Learning Alignment for Image Set-based Recognition
Aug 05, 2019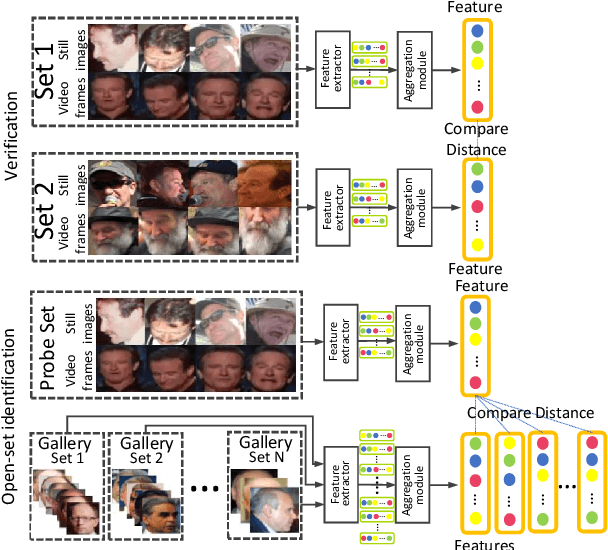
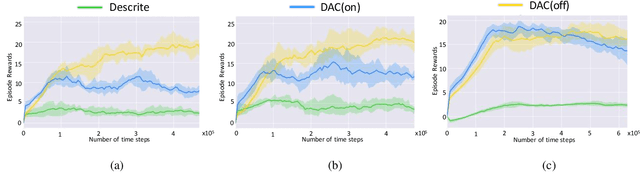

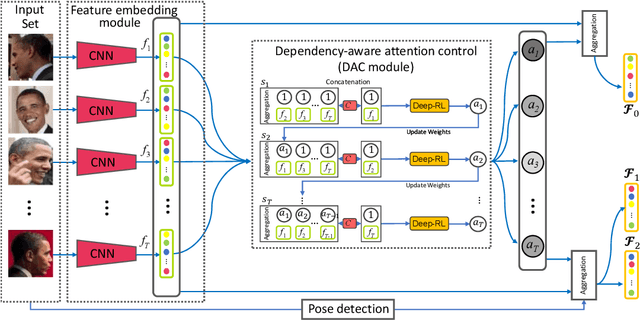
This paper considers the problem of image set-based face verification and identification. Unlike traditional single sample (an image or a video) setting, this situation assumes the availability of a set of heterogeneous collection of orderless images and videos. The samples can be taken at different check points, different identity documents $etc$. The importance of each image is usually considered either equal or based on a quality assessment of that image independent of other images and/or videos in that image set. How to model the relationship of orderless images within a set remains a challenge. We address this problem by formulating it as a Markov Decision Process (MDP) in a latent space. Specifically, we first propose a dependency-aware attention control (DAC) network, which uses actor-critic reinforcement learning for attention decision of each image to exploit the correlations among the unordered images. An off-policy experience replay is introduced to speed up the learning process. Moreover, the DAC is combined with a temporal model for videos using divide and conquer strategies. We also introduce a pose-guided representation (PGR) scheme that can further boost the performance at extreme poses. We propose a parameter-free PGR without the need for training as well as a novel metric learning-based PGR for pose alignment without the need for pose detection in testing stage. Extensive evaluations on IJB-A/B/C, YTF, Celebrity-1000 datasets demonstrate that our method outperforms many state-of-art approaches on the set-based as well as video-based face recognition databases.
Image processing in DNA
Oct 22, 2019
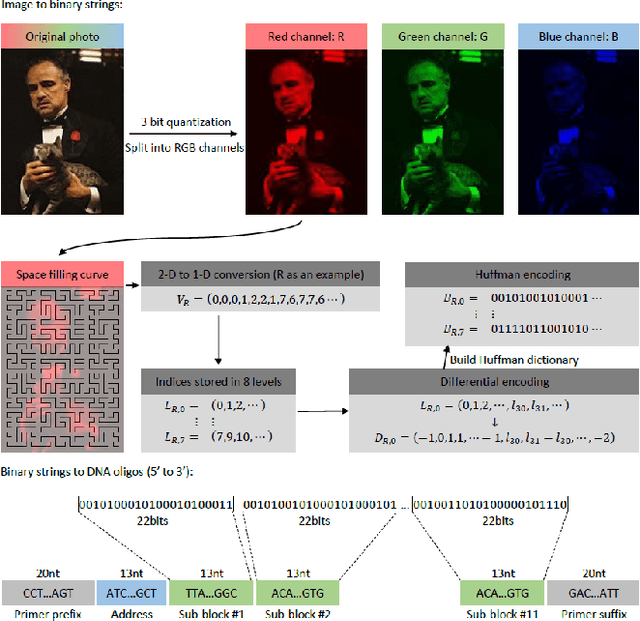


The main obstacles for the practical deployment of DNA-based data storage platforms are the prohibitively high cost of synthetic DNA and the large number of errors introduced during synthesis. In particular, synthetic DNA products contain both individual oligo (fragment) symbol errors as well as missing DNA oligo errors, with rates that exceed those of modern storage systems by orders of magnitude. These errors can be corrected either through the use of a large number of redundant oligos or through cycles of writing, reading, and rewriting of information that eliminate the errors. Both approaches add to the overall storage cost and are hence undesirable. Here we propose the first method for storing quantized images in DNA that uses signal processing and machine learning techniques to deal with error and cost issues without resorting to the use of redundant oligos or rewriting. Our methods rely on decoupling the RGB channels of images, performing specialized quantization and compression on the individual color channels, and using new discoloration detection and image inpainting techniques. We demonstrate the performance of our approach experimentally on a collection of movie posters stored in DNA.